学习记录——Transformer、ViT、Swin-Transformer、SegFormer、TopFormer、Seaformer
Transformer
2017 Computation and Language Google
Self-Attention、Multi-Head Attention

位置编码

原理参考链接
ransformer网络结构:

ViT
2020 ICLR
将transformer引入到cv领域

将输入图片224x224x3按照16x16x3大小的Patch进行划分,接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patch数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]。
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
Transformer Encoder
Layer Norm,这种Normalization方法主要是针对NLP领域提出的。
MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]。


Hybrid混合模型
Hybrid混合模型,就是将传统CNN特征提取和Transformer进行结合。这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。后面的部分和前面的ViT网络一样。

SETR
2021 CVPR 由复旦和腾讯优图联合提出的一个基于ViT的新型架构的语义分割模型。
现有的语义分割模型大多都是基于FCN的Encoder-Decoder结构:Encoder用于学习图像特征,Decoder则基于Encoder学到的特征对图片中的每一个像素进行分类。其中,Encoder通常以卷积分类网络作为Backbone,将输入图片不断下采样以增加感受野,学习更加抽象的图像特征。但是,通过不断堆叠卷积层来增加感受野无法有效地学习图像信息中的远距离依赖关系。而这一点对于提升语义分割的效果十分重要。
为了解决这个问题,SETR完全舍弃卷积操作,Encoder将输入图像看作图像patch序列,通过全局注意力建模学习图像特征;Decoder利用从Transformer Encoder中学到的特征,将图像恢复到原始大小,完成分割任务。整个过程没有使用卷积操作,没有对图片进行下采样,而是在Encoder Transformer的每一层进行全局上下文建模,从而为语义分割问题的解决提供了新思路。

SETR编码器流程跟作为backbone的ViT模型较为一致。先对输入图像做分块处理,然后对每个图像分块做块嵌入并加上位置编码,这个过程就将图像转换为向量序列。之后就是Transformer block,里面包括24个Transformer层,每个Transformer层都是由MSA+MLP+Layer Norm+残差连接组成。
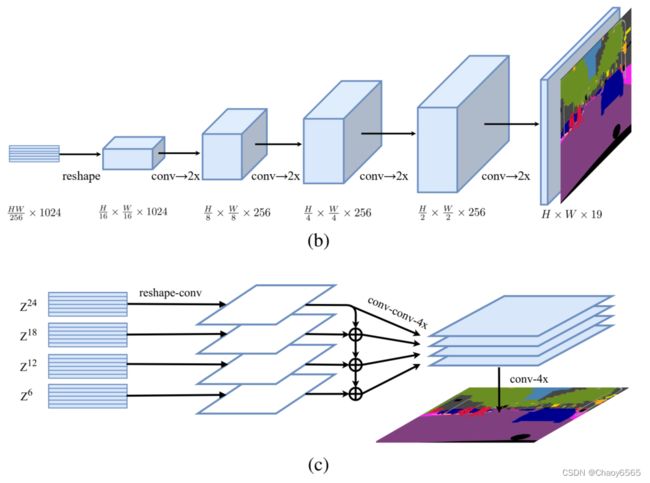
解码器
SETR设计了三种解码器上采样方法。第一种就是最原始的上采样,论文中叫Naive upsampling,通过简单的1x1卷积加上双线性插值来实现图像像素恢复。这种上采样方法简称为SETR-Naive。
重点是第二种和第三种解码器设计。第二种解码器设计叫渐进式上采样 (Progressive UPsampling),作者认为一步到位式的上采样可能会产生大量的噪声,采样渐进式的上采样则可以最大程度上缓解这种问题。渐进式的上采样在于,每一次上采样只恢复上一步图像的2倍,这样经过4次操作就可以回复原始图像。这种解码设计简称为SETR-PUP,如图1中的(b)图所示。第三种解码设计为多层次特征加总 (Multi-Level feature Aggregation, MLA),这种设计跟特征金字塔网络类似,如图1中©图所示。
Swin-Transformer
2021 微软 CVPR
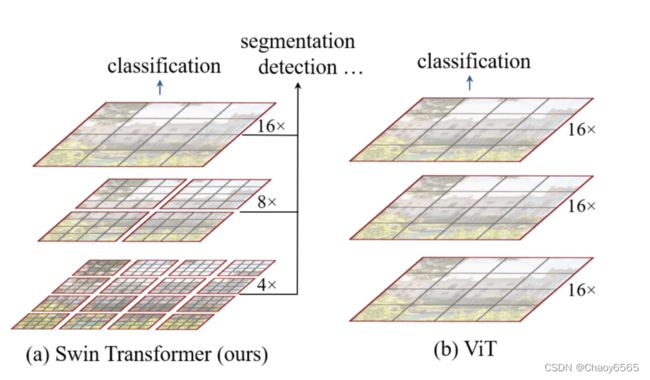
Swin Transformer 引入了两个关键的概念来解决原始 ViT 所面临的问题——分层特征图(hierarchical feature maps)和转移窗口注意力(shifted window attention)。
Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。

首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了[H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠SwinTransformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。
W-MSA
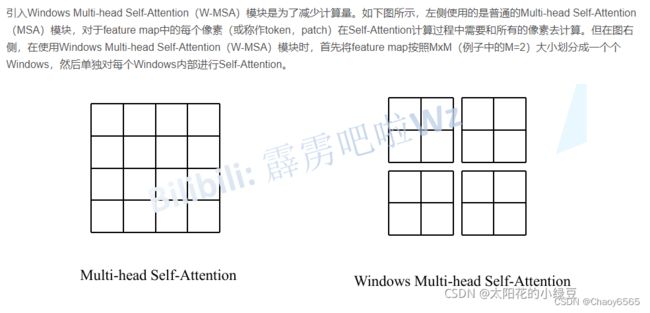
SW-MSA
W-MSA为了减少计算量,只会在每个窗口内进行自注意力计算,窗口与窗口之间是无法进行信息传递的。


SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
SegFormer:简单高效的变压器语义分割设计 2021 CVPR
提出了一种简单、高效、功能强大的语义分割框架SegFormer,它将transformer与轻量级多层感知器(MLP)解码器结合在一起。SegFormer有两个吸引人的特点:
1)SegFormer包括一个新颖的分层结构的变压器编码器,输出多尺度特征。它不需要位置编码,从而避免了当测试分辨率与训练分辨率不同时插入位置编码导致性能下降的问题。
2) SegFormer避免复杂的解码器。所提出的MLP解码器聚合了来自不同层的信息,从而结合了局部注意和全局注意来呈现强大的表示。我们表明,这种简单和轻量级的设计是有效分割变压器的关键。
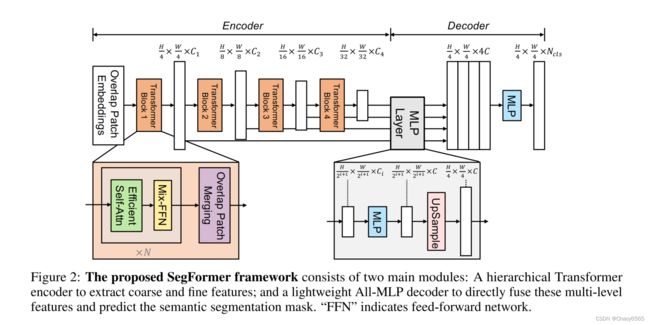
SegFormer由两个主要模块组成:
一个分层的Transformer编码器,用于生成高分辨率的粗特征和低分辨率的细特征。一种新颖的无位置编码和分层变压器编码器。
一个轻量级的All-MLP解码器,融合这些多级特征,产生最终的语义分割掩码。
——编码器在对与训练图像分辨率不同的图像进行推理时避免了插入位置码。因此,编码器可以很容易地适应任意的测试分辨率,而不会影响性能。分层部分使编码器能够同时生成高分辨率的精细特征和低分辨率的粗特征,这与ViT只能生成单个固定分辨率的低分辨率特征图形成了鲜明对比。
——轻量级的MLP解码器,其关键思想是利用变压器诱导的特征,其中低层的注意力往往停留在局部,而最高层的注意力则高度非局部。通过聚合来自不同层的信息,MLP解码器结合了本地和全局关注。
Overlapped Patch Merging
ViT的Patch Embedding是无重叠的(non-overlapping),但是non-overlapping对语义分割任务来说,会导致patch边缘不连续。MiT使用overlapped patch embedding,保证patch边缘连续。
自注意力 Efficient Self-Attention
减少K,减少计算量

混合前馈网络 Mix-FFN(Feed-forward Network)
ViT使用位置编码(PE)来引入位置信息。但是PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,位置代码需要插值,这通常会导致精度下降。作者认为位置编码对于语义分割实际上是不必要的。因此SegFormer引入Mix-FFN,它考虑了零填充对泄漏位置信息的影响,直接在前馈网络(FFN)中使用3×3 Conv。Mix-FFN公式为:

实验证明3x3的卷积可以提供给transformer充分的位置信息。
ALL-MLP解码结构 Lightweight All-MLP Decoder
SegFormer集成了一个轻量级解码器,只包含MLP层。实现这种简单解码器的关键是,SegFormer的分级Transformer编码器比传统CNN编码器具有更大的有效接受域(ERF)。


对于不同分辨率的特征图Fi,将其上采样至1/4,然后将多个特征图concat后,送入后续网络,得到分割结果。
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
TopFormer:移动语义分割的令牌金字塔转换器 2022 CVPR
尽管视觉变压器(vision transformer, ViTs)在计算机视觉领域取得了巨大的成功,但沉重的计算成本阻碍了其在移动设备语义分割等密集预测任务中的应用。在本文中,我们提出了一个移动友好的架构,名为令牌金字塔视觉变压器(TopFormer)。所提出的TopFormer将来自各种尺度的token作为输入,以产生可感知尺度的语义特征,然后将这些特征注入到相应的token中以增强表示。实验结果表明,我们的方法在多个语义分割数据集上明显优于基于CNN和vit的网络,并在准确率和延迟之间取得了很好的平衡。
topfomer吸收了CNN与transfomer结构上的优势,通过CNN常用的金字塔结构来把高分辨率图像快速生成特征,金字塔分为4层,使用下采样来构建金字塔,代码里面是用1x1Conv,步长取2来逐步实现H,W的成倍减小。再使用减小后融合的token作为trnasfomer模块的输入,这样计算量就大大减小了。transfomer模块负责提取出丰富的语义特征。
贡献:
1.将不同尺度的token作为输入,并将它们融合到非常小的scale,以极低的成本来获得语义。
2.Semantics Injection Module可以把语义注入token,实现局部特征和全局特征的融合
3.topformer的 base model 在 ARM移动设备上测试ADE20K 数据集,比MobileNetV3高 5% mIoU, tiny模型可以实现实时分割,分割效果也是比较有竞争力的。
Token Pyramid Module
金字塔部分用的是MobileNets块的堆叠,特点就是一步stride=1,一步stride=2这样叠了4块相当于H,W下降16倍。因为之前conv_stem将H,W降为1/2,维度从3升到16,所以在融合前H,W降为1/32,通过平均池化融合后再降1/2,所以输入transfomer的时候H,W是1/64.因为H,W实在太小了,所以通道数即使拼接起来计算成本也很小。
Scale-aware Semantics Extractor
本部分是transfomer编码器部分,本文没有对attention结构进行修改,attention计算的时间复杂度也是平方。所谓语义提取器就是将数个transfomer块堆叠在一块,图上数量为L。q,k的shapeNxC维度C取16,v取32。attention计算中shape是这样变化的:N * C @ C * N -> N * N,N * N @ N * 2C->N * 2C(文中指定C=16)
本文transfomer模块中另外几个改变是1x1卷积代替linear,ReLU6代替GELU,每个卷积后跟 batch normalization而不是Layer normalization 。
Semantics Injection Module
从transfomer块里面出来的全局语义要与金字塔中的局部语义融合,但是它们存在着明显的语义差距,本文使用Semantics Injection Module来缓解它们之间的语义差距。
语义注入模块 (SIM) 将token金字塔模块的局部特征token和transfomer的全局特征图作为输入。 局部token我们把它暂时叫T,transfomer的全局特征图我们暂时叫F。
1.T通过 1×1 卷积层,BN以生成特征。
2.F通过一边 1×1 卷积层,BN, sigmoid 层,
3.F通过 1×1 卷积层,BN。
总共三个输出,具有相同的大小。
这三个输出怎么融合呢,先是1和2做Hadamard 积,文中把他叫做把全局语义注入局部特征。。。然后是在注入之后将积与3相加。 文中也说语义注入减轻了token之间的语义差距。
Segmentation Head
经过处理后局部语义和全局语义相乘再加上全局语义。这就是局部语义和全局语义融合的方法。这样我们获得了4张特征图。
将多尺度特征图转化为分割结果也很简单。将4张特征图上采样到统一规格后相加,在经过1x1conv通道取物体class种类的数量即可。实际上就是将不同分辨率的token通过bilinear插值到与高分辨率token相同的大小,然后对所有特征图求和。
SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
Seaformer:用于移动语义分割的挤压增强轴向变压器 ICLR 2023
自从引入视觉变形器以来,许多计算机视觉任务(例如,语义分割)的前景一直由cnn压倒性地主导,最近发生了重大变革。然而,计算成本和内存需求使得这些方法不适合移动设备,特别是对于高分辨率的逐像素语义分割任务。本文介绍了一种新的用于移动语义分割的挤压增强轴向变压器(SeaFormer)方法。具体来说,我们**设计了一个通用的注意力块,其特点是挤压轴和细节增强的配方。**它可以进一步用于创建一系列具有卓越成本效益的骨干体系结构。再加上一个轻分割头,我们在基于arm的移动设备上在ADE20K和cityscape数据集上实现了分割精度和延迟之间的最佳权衡。关键的是,我们以更好的性能和更低的延迟击败了移动友好型竞争对手和基于transformer的对手,而且没有花哨的东西。除了语义分割之外,我们进一步将提出的SeaFormer架构应用于图像分类问题,展示了作为多功能移动友好骨干网的潜力。
Transformer在服务器端的多类别语义分割数据集上均获得了碾压的效果,Topformer第一次在移动端上使用了Transformer的注意力机制增强了特征,但是使用的注意力还是不够高效,因此只能在下采样64倍的分辨率上进行特征增强。现有的高效注意力机制包含基于窗口的注意力机制和轴线注意力等,但是这些注意力在高分辨率上的延时对于移动端来说还是损失了全局信息/不够高效。为此这篇文章设计 增加了位置信息的轴线压缩增强注意力,一方面将QKV特征进行轴线压缩后再注意力增强,另一方面将QKV特征使用卷积网络提升局部信息,最后将二者融合,输出增强特征。

网络结构
如上面的框架图所示,该网络先对图像进行1/2、1/4和1/8的下采样,再分别用两个分支进行处理,红色的是上下文分支,蓝色的是空间分支。上下文分支交替使用了MobileNetV2 Block(MV2)和SeaFormer Layers,中间使用Fusion block对两个分支进行融合,使用卷积和Sigmoid提取权重信息,再将权重信息与空间分支相乘,连续迭代三次后使用Light segmentation head进行处理。
SeaFormer Layer的结构
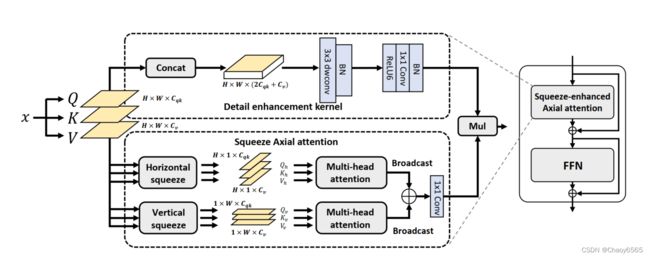
SeaFormer采用了轴向注意力机制,先对Q,K,V分别进行池化,再转换维度,分别使用横向压缩和纵向压缩得到Hx1xCp和1xWxCp的两个向量,对这两个向量分别计算多头自注意力,再将得到的结果进行广播,将两个结果扩大为相同的维度再进行相加。为了增强细节信息,SeaFormer中使用了Detail enhancement kernel,通过该kernel得到的结果与压缩的轴向注意力的计算结果进行相乘,得到最终的注意力。