分布式计算模型详解:MapReduce、数据流、P2P、RPC、Agent
前言
本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据理论体系
思维导图

MapReduce
MapReduce 是一种分布式计算模型,用于处理大规模数据集的计算问题。
该模型在 Google 发布的论文中首次提出,其主要目的是简化并行计算和分布式计算的编程模型。MapReduce 模型可以概括为两个基本阶段:Map 和 Reduce。
关于 MapReduce 的更多细节请参考我的博客
- MapReduce 编程模型到底是怎样的?
- 图文详解 MapReduce 工作流程
下面是 MapReduce 的详细解释:
Map 阶段
Map 阶段的目的是将输入数据集映射到一系列键值对上。这个映射函数由开发者定义,并且将输入数据集分割成一些小的数据片段,每个数据片段由一个 Map 函数单独处理。Map 函数的输出结果是一系列键值对,这些键值对将成为 Reduce 阶段的输入。Map 阶段通常是并行处理的,这样可以利用分布式计算资源加速处理速度。
Reduce 阶段
Reduce 阶段的目的是将 Map 阶段输出的键值对按照键进行归并。这个归并函数也是由开发者定义的,并且将所有具有相同键的值合并为一组。Reduce 函数的输出结果可以是一个或多个键值对。Reduce 阶段的输出通常被写入到持久性存储系统中,以便进一步的分析和查询。
MapReduce 模型的主要特点是可以在大规模计算集群中并行处理数据,并且具有自动故障恢复和容错机制。开发者只需要编写 Map 和 Reduce 函数,就可以利用 MapReduce 模型处理海量数据集,而不必担心底层的分布式计算细节。除了 Google 的 MapReduce,目前有许多开源实现,如 Apache Hadoop 和 Apache Spark 等。
数据流
数据流计算模型是一种并行计算模型,用于处理数据流的计算问题。该模型将计算任务看作是一系列数据流的处理过程,即将数据流从一个处理单元传递到另一个处理单元,每个处理单元执行一些操作并产生输出。这个模型适用于需要实时处理大量数据的场景,例如实时数据分析和流媒体处理等。

下面是数据流计算模型的详细解释:
1. 数据流模型
数据流模型将数据看作是流,即数据不是存储在内存中,而是通过处理单元之间的通道传递。每个处理单元称为一个操作符,它可以执行一些操作并产生输出。操作符接收输入数据流,处理数据并将结果输出到下一个操作符。数据流模型通常由一个流图表示,它是一个由操作符组成的有向无环图(DAG)。
2. 时序语义
数据流模型引入了时序语义,即数据流的顺序非常重要。每个操作符必须按照数据流的顺序执行,并且只有在输入数据准备好时才能执行。因此,时序语义非常重要,它确保了数据流的正确性和一致性。
3. 流控制
数据流模型还包括流控制机制,以确保操作符之间的数据流量合理。流控制可以控制数据流的速率,使得不同操作符之间的数据流量匹配。这样可以避免数据积压和资源浪费。
数据流计算模型的主要特点是可以实现低延迟和高吞吐量的数据处理,适用于需要实时处理大量数据的场景。该模型还可以通过并行处理来提高计算效率,并且具有容错机制,即在处理单元发生故障时可以进行自动故障恢复。常见的数据流计算模型包括 Apache Flink、Apache Storm 和 Apache Spark Streaming 等。
P2P
P2P 计算模型是一种分布式计算模型,其中计算任务由多个节点协同完成,而不是依赖于一个中心节点或服务器。每个节点都可以提供计算资源和存储资源,并且可以与其他节点进行直接通信,从而形成一个点对点(P2P)网络。这种模型通常用于处理分布式计算问题,例如分布式存储和分布式计算等。

下面是 P2P 计算模型的详细解释:
1. 节点
P2P 计算模型由许多节点组成,每个节点都可以提供计算和存储资源。这些节点可以是物理设备或虚拟设备,它们通过网络连接在一起,形成一个点对点网络。
2. 任务分配
在 P2P 计算模型中,计算任务通常被分配给网络中的多个节点,每个节点执行一部分计算任务。任务分配通常由一个中心协调器或分布式系统管理器完成,这个管理器可以根据节点的可用性和计算资源来分配任务。
3. 通信协议
在 P2P 计算模型中,节点之间的通信通常使用一些特定的协议,例如 BitTorrent 协议、Kademlia 协议等。这些协议可以帮助节点快速发现和连接到其他节点,以便共同完成计算任务。此外,这些协议还可以帮助节点共享和传输数据。
4. 安全性
P2P 计算模型需要一些安全机制来保护节点和数据的安全。例如,可以使用加密算法来保护数据的传输和存储,也可以使用身份验证机制来保护节点的身份。
P2P 计算模型的主要特点是具有高度的可扩展性和弹性,可以容忍节点的故障和离线。此外,P2P 计算模型可以利用分布式计算资源来加速计算任务,从而提高计算效率。然而,P2P 计算模型也存在一些挑战,例如通信延迟、安全性问题和任务分配等。
RPC
RPC(Remote Procedure Call)计算模型是一种远程计算模型,用于在分布式系统中实现进程之间的通信。通过 RPC 模型,进程可以调用远程服务器上的方法,就像调用本地方法一样,从而实现分布式计算和服务。RPC 模型通常用于构建分布式应用程序、服务和系统等。
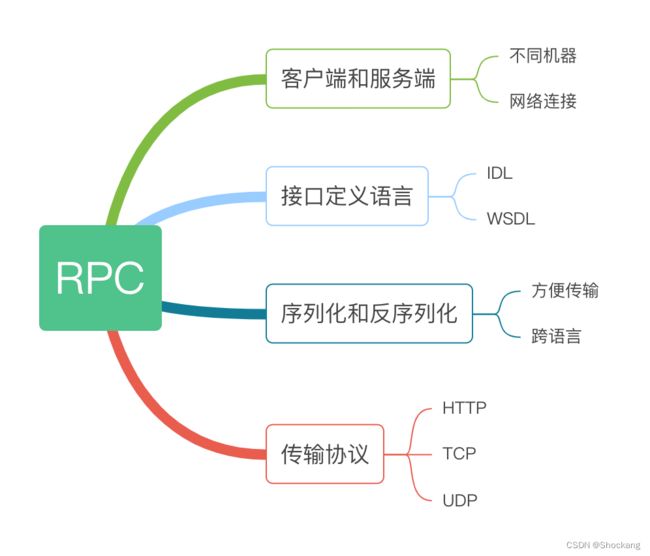
下面是 RPC 计算模型的详细解释:
1. 客户端和服务端
RPC 计算模型由客户端和服务端组成,客户端可以调用远程服务器上的方法,服务端提供实现这些方法的代码和逻辑。客户端和服务端可以运行在不同的机器上,通过网络连接在一起。
2. 接口定义语言
RPC 计算模型需要一种接口定义语言来描述可以调用的方法和参数。常见的接口定义语言包括 IDL(Interface Definition Language)和 WSDL(Web Service Definition Language)等。这种语言可以帮助客户端和服务端之间定义共同的接口,从而使它们能够进行通信。
3. 序列化和反序列化
RPC 模型需要一种序列化和反序列化机制,将数据从一种格式转换为另一种格式。这种机制通常用于将数据转换为二进制格式或 XML 格式,以便在客户端和服务端之间进行传输。序列化和反序列化机制还可以处理不同机器上的不同编程语言之间的数据转换。
关于序列化请参考我的博客
- 为什么要将数据序列化?
- 分布式系统中序列化框架该如何选择?
4. 传输协议
RPC 模型需要一种传输协议,用于在客户端和服务端之间传输数据。常见的传输协议包括 HTTP、TCP 和 UDP 等。这些协议可以保证数据的传输效率和安全性。
RPC 计算模型的主要特点是可以通过网络连接实现进程之间的通信,从而实现分布式计算和服务。RPC 模型可以提高系统的可扩展性和性能,并且可以实现跨平台和跨语言的通信。常见的 RPC 框架包括 gRPC、Apache Dubbo、Thrift 等。
Agent
Agent 计算模型是一种基于智能体(Agent)的分布式计算模型,其主要思想是将计算过程分解为多个智能体之间的协作和通信,从而实现分布式计算和服务。Agent 计算模型常用于构建分布式人工智能、机器学习、物联网等应用程序和系统。
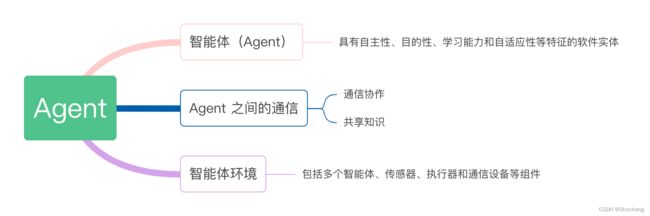
下面是 Agent 计算模型的详细解释:
智能体(Agent)
Agent 是 Agent 计算模型的核心组件,它是具有自主性、目的性、学习能力和自适应性等特征的软件实体。每个 Agent 都可以执行一些计算任务,与其他 Agent 进行通信和协作,并从中获得信息和知识。
Agent 之间的通信
Agent 计算模型通过 Agent 之间的通信和协作来实现分布式计算和服务。Agent 可以通过消息传递、远程调用、事件通知等方式与其他 Agent 进行通信和协作,从而完成任务并共享知识。
智能体环境
智能体环境是 Agent 计算模型的运行环境,它是一个包含多个 Agent 的分布式系统。智能体环境可以包括多个智能体、传感器、执行器和通信设备等组件,用于管理和协调 Agent 的运行和交互。
Agent 计算模型的主要特点是可以实现分布式计算和服务,每个 Agent 都可以具有自主性、目的性、学习能力和自适应性等特征,从而提高系统的可扩展性和性能。Agent 计算模型可以用于构建分布式人工智能、机器学习、物联网等应用程序和系统。常见的 Agent 框架包括 JADE、MASON、NetLogo 等。
总结
本文主要介绍了以下五种分布式计算模型的详细解释:
- MapReduce:介绍了Google提出的MapReduce模型,包括Map阶段和Reduce阶段的功能和特点,以及在处理大规模数据集中的应用。
- 数据流:介绍了数据流计算模型,将计算任务看作是一系列数据流的处理过程,适用于实时处理大量数据的场景,具有时序语义和流控制等特点。
- P2P:介绍了P2P计算模型,其中计算任务由多个节点协同完成,节点之间可以直接通信,具有高度的可扩展性和弹性,常用于分布式存储和分布式计算等。
- RPC:介绍了RPC计算模型,用于实现分布式系统中进程之间的通信,客户端可以调用远程服务器上的方法,具有可扩展性、跨平台和跨语言等特点。
- Agent:介绍了Agent计算模型,基于智能体的分布式计算模型,计算过程分解为多个智能体之间的协作和通信,常用于分布式人工智能、机器学习和物联网等应用。
每个计算模型都有其特点和适用场景,可以根据具体需求选择合适的模型进行分布式计算和服务。