第九章(2):长短期记忆网络(Long short-term memory, LSTM)与pytorch示例(简单字符级语言模型训练器)
第九章(2):长短期记忆网络(Long short-term memory, LSTM)与pytorch示例(简单字符级语言模型训练器)
作者:安静到无声 个人主页
作者简介:人工智能和硬件设计博士生、CSDN与阿里云开发者博客专家,多项比赛获奖者,发表SCI论文多篇。
Thanks♪(・ω・)ノ 如果觉得文章不错或能帮助到你学习,可以点赞收藏评论+关注哦! o( ̄▽ ̄)d
欢迎大家来到安静到无声的 《基于pytorch的自然语言处理入门与实践》,如果对所写内容感兴趣请看《基于pytorch的自然语言处理入门与实践》系列讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,请多多支持!
目录标题
- 第九章(2):长短期记忆网络(Long short-term memory, LSTM)与pytorch示例(简单字符级语言模型训练器)
- 1. 概述
- 2. 计算流程
- 3. Pytorch实现示例
-
- 3.1 简单字符级语言模型训练器
- 3.2 代码详解
- 3.3 结果输出
- 4. 总结
- 参考
1. 概述
长短期记忆网络(Long Short-Term Memory, LSTM)是一种递归神经网络(Recurrent Neural Network, RNN)的变体,专门用于处理和预测序列数据。它通过引入门控机制和记忆细胞,能够更好地捕捉序列中的长期依赖关系,并解决传统RNN中的梯度消失或爆炸问题。
2. 计算流程
LSTM 网络引入一个新的内部状态(internal state) c t ∈ R D c_t\in\mathbb{R}^D ct∈RD专门进行线性的循环信息传递,同时(非线性地)输出信息给隐藏层的外部状态 h t ∈ R D h_t\in\mathbb{R}^D ht∈RD。 内部状态 c t c_t ct 通过下面公式计算:
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t , h t = o t ⊙ tanh ( c t ) , \begin{aligned}\boldsymbol{c}_{t}&=\boldsymbol{f}_{t}\odot\boldsymbol{c}_{t-1}+\boldsymbol{i}_{t}\odot\widetilde{\boldsymbol{c}}_{t},\\\boldsymbol{h}_{t}&=\boldsymbol{o}_{t}\odot\tanh(\boldsymbol{c}_{t}),\end{aligned} ctht=ft⊙ct−1+it⊙c t,=ot⊙tanh(ct),
其中, f t ∈ [ 0 , 1 ] D f_{t}\in[0,1]^{D} ft∈[0,1]D, i t ∈ [ 0 , 1 ] D i_{t}\in[0,1]^{D} it∈[0,1]D, o t ∈ [ 0 , 1 ] D o_{t}\in[0,1]^{D} ot∈[0,1]D
为三个门( gate ) 来控制信息传递的路径;⊙为向量元素乘积; c t − 1 c_{t-1} ct−1为上一时刻的记忆单元; c ~ t ∈ R D \tilde{c}_t\in\mathbb{R}^D c~t∈RD是通过非线性函数得到的候选状态。
c ~ t = tanh ( W c x t + U c h t − 1 + b c ) . \tilde{c}_{t}=\tanh(\boldsymbol{W}_{c}\boldsymbol{x}_{t}+\boldsymbol{U}_{c}\boldsymbol{h}_{t-1}+\boldsymbol{b}_{c}). c~t=tanh(Wcxt+Ucht−1+bc).
在每个时刻 t t t,LSTM网络的内部状态 c t c_t ct 记录了到当前时刻为止的历史信息。
门控机制在数字电路中,门( gate ) 为一个二值变量 0 , 1 {0,1} 0,1,0代表关闭状态,不许任何信息通过;1代表开放状态,允许所有信息通过。
f t ∈ [ 0 , 1 ] D f_{t}\in[0,1]^{D} ft∈[0,1]D, i t ∈ [ 0 , 1 ] D i_{t}\in[0,1]^{D} it∈[0,1]D, o t ∈ [ 0 , 1 ] D o_{t}\in[0,1]^{D} ot∈[0,1]D分别是遗忘门,输入门和输出门,他们的作用总结如下:
遗忘门:遗忘门决定了前一时刻记忆细胞中的哪些信息应该被遗忘,通过对输入的隐藏状态和上一时刻的记忆细胞进行运算,输出一个介于0和1之间的值。接近0的权重表示要遗忘的信息,接近1的权重表示要保留的信息。
输入门:输入门决定了当前时刻输入的哪些信息应该被存储到记忆细胞中。它通过对输入的隐藏状态和上一时刻的记忆细胞进行运算,输出一个介于0和1之间的值。接近0的权重表示忽略的输入,接近1的权重表示重要的输入。
输出门:输出门决定了记忆细胞中的哪些信息应该被传递给下一层或生成最终的输出。它通过对当前时刻的隐藏状态和记忆细胞进行运算,输出一个介于0和1之间的值,用于控制记忆细胞的输出。输出门还可以过滤掉不必要的或无关的信息,提取重要的信息进行传递。
当 f t = 0 , i t = 1 f_t=0,i_t=1 ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量 c c c写入但此时记忆单元 c c c依然和上一时刻的历史信息相关。当 f t = 1 , i t = 0 f_t=1,i_t=0 ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
LSTM网络中的“门”是一种“软”门,取值在 ( 0 , 1 ) (0, 1) (0,1)之间,表示以一定的比例允许信息通过,三个门的计算方式为:
it = σ ( W i x t + U i h t − 1 + b i ) , f t = σ ( W f x t + U f h t − 1 + b f ) , o t = σ ( W o x t + U o h t − 1 + b o ) , \begin{gathered} \text{it} =\sigma(W_{i}\boldsymbol{x}_{t}+\boldsymbol{U}_{i}\boldsymbol{h}_{t-1}+\boldsymbol{b}_{i}), \\ f_{t} =\sigma(W_{f}\boldsymbol{x}_{t}+\boldsymbol{U}_{f}\boldsymbol{h}_{t-1}+\boldsymbol{b}_{f}), \\ \mathbf{o}_{t} =\sigma(\boldsymbol{W}_{o}\boldsymbol{x}_{t}+\boldsymbol{U}_{o}\boldsymbol{h}_{t-1}+\boldsymbol{b}_{o}), \end{gathered} it=σ(Wixt+Uiht−1+bi),ft=σ(Wfxt+Ufht−1+bf),ot=σ(Woxt+Uoht−1+bo),
其中 (⋅) 为 Logistic 函数,其输出区间为 (0, 1) , x t x_t xt为当前时刻的输入, h t − 1 h_{t-1} ht−1为上一时刻的外部状态。
下图给出了LSTM网络的循环单元结构,其计算过程为:
(1)首先利用上一时刻的外部状态 h t − 1 \boldsymbol{h}_{t-1} ht−1 和当前时刻的输人 x t x_t xt,计算出三个门,以及候选状态 c t c_t ct。
(2)结合遗忘门 f t f_{t} ft 和输入门i,来更新记忆单元 c t c_t ct
(3)结合输出门 o t o_{t} ot将内部状态的信息传递给外部状态 h t h_{t} ht
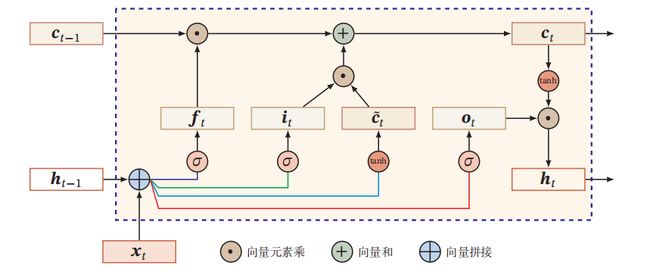
通过 LSTM 循环单元,整个网络可以建立较长距离的时序依赖关系。 可以简洁地描述为:
[ c ~ t o t i t f t ] = [ tanh σ σ ] ( w [ x t h t − 1 ] + b ) , c t = f t ⊙ c t − 1 + i t ⊙ c ~ t , h t = o t ⊙ tanh ( c t ) , \begin{aligned} \begin{bmatrix}\tilde{c}_t\\\\o_t\\\\i_t\\f_t\end{bmatrix}& =\left[\begin{array}{c}\tanh\\\\\sigma\\\sigma\\\end{array}\right]\left(\boldsymbol{w}\left[\begin{array}{c}x_{t}\\\\\boldsymbol{h}_{t-1}\\\end{array}\right]+\boldsymbol{b}\right), \\ c_{t}& =\boldsymbol{f}_{t}\odot\boldsymbol{c}_{t-1}+\boldsymbol{i}_{t}\odot\widetilde{\boldsymbol{c}}_{t}, \\ h_{t}& =\mathbf{o}_{t}\odot\tanh\left(\mathbf{c}_{t}\right), \end{aligned} c~totitft ctht= tanhσσ w xtht−1 +b ,=ft⊙ct−1+it⊙c t,=ot⊙tanh(ct),
其中 x t ∈ R M 为当前时刻的输入 , W ∈ R 4 D × ( D + M ) 和 b ∈ R 4 D 为网络参数 \text{其中}x_t\in\mathbb{R}^M\text{为当前时刻的输入},W\in\mathbb{R}^{4D\times(D+M)}\text{和 b}\in\mathbb{R}^{4D}\text{为网络参数} 其中xt∈RM为当前时刻的输入,W∈R4D×(D+M)和 b∈R4D为网络参数。
3. Pytorch实现示例
3.1 简单字符级语言模型训练器
import torch
from torch import nn
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # hello
y_data = [3, 1, 2, 3, 2] # ohlol
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.num_directions = 1
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.lstm=torch.nn.LSTM(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
h_0 = torch.zeros(self.num_directions * num_layers, x.size(0), hidden_size)
c_0 = torch.zeros(self.num_directions * num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.lstm(x, (h_0, c_0))
x = self.fc(x)
print(x.shape)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(20):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/20] loss=%.3f ' % (epoch + 1, loss.item()))
3.2 代码详解
以上代码是一个简单的字符级语言模型,使用了 LSTM(长短期记忆)网络进行训练。下面是对代码的详细解释:
-
首先,导入了
torch和torch.nn模块,torch.nn模块提供了用于构建神经网络模型的类和函数。 -
定义了一些模型的超参数:
num_class:输出类别的数量,即字符的种类数。input_size:输入序列中每个字符的特征维度。hidden_size:LSTM隐藏层的大小,也是输出特征的维度。embedding_size:字符嵌入(embedding)的维度。num_layers:LSTM的层数。batch_size:输入数据的批量大小。seq_len:输入序列的长度。
-
定义了一个包含了字符索引到字符的映射列表
idx2char,以及输入和输出数据x_data和y_data。其中,x_data表示输入序列的字符索引,y_data表示对应的目标序列的字符索引。 -
创建了输入和标签的张量
inputs和labels,使用torch.LongTensor将数据转换为长整型张量。 -
定义了一个字符级语言模型的类
Model,继承自torch.nn.Module。该类包含三个主要部分:
- 一个嵌入层(
self.emb):将输入序列中的字符索引转换为嵌入向量,嵌入向量的维度为embedding_size。 - LSTM层(
self.lstm):使用LSTM对嵌入向量进行处理,获取序列中每个字符的表示。 - 全连接线性层(
self.fc):将LSTM的输出转换为最终的预测结果,输出维度为num_class。
-
在forward方法中,首先初始化LSTM的隐藏状态
h_0和细胞状态c_0,这里使用torch.zeros创建全零张量作为初始状态。 然后,通过嵌入层将输入x转换为嵌入向量。 接着,将嵌入向量x传入LSTM层,获取输出特征x和最终隐藏状态。 最后,将LSTM的输出特征x传入全连接层fc,得到预测结果,并通过view方法将形状调整为(batch_size * seq_len, num_class)。 -
创建了模型实例
net。 -
定义了损失函数
criterion,这里使用交叉熵损失函数(CrossEntropyLoss)。 -
定义了优化器
optimizer,这里使用Adam优化器,用于更新模型的参数。 -
进行训练循环,共进行20个epoch的训练:
- 在每个
epoch开始前,将优化器的梯度清零。 - 将输入数据
inputs传入模型net,得到模型的输出outputs。 - 计算输出
outputs和标签labels之间的损失值loss。 - 调用
backward方法计算梯度。 - 调用
optimizer的step方法进行参数更新。 - 使用
max方法找到outputs中每行最大值的索引,即预测的字符索引。 - 将预测的字符索引转换为对应的字符,并打印出来。
- 打印出当前
epoch的序号和损失值。
3.3 结果输出
torch.Size([1, 5, 4])
Predicted: lllll, Epoch [1/20] loss=1.399
torch.Size([1, 5, 4])
Predicted: lllll, Epoch [2/20] loss=1.285
torch.Size([1, 5, 4])
Predicted: lllll, Epoch [3/20] loss=1.197
torch.Size([1, 5, 4])
Predicted: lllll, Epoch [4/20] loss=1.133
torch.Size([1, 5, 4])
Predicted: lllll, Epoch [5/20] loss=1.063
torch.Size([1, 5, 4])
Predicted: oolll, Epoch [6/20] loss=0.994
torch.Size([1, 5, 4])
Predicted: ooool, Epoch [7/20] loss=0.924
torch.Size([1, 5, 4])
Predicted: ooool, Epoch [8/20] loss=0.844
torch.Size([1, 5, 4])
Predicted: ohool, Epoch [9/20] loss=0.761
torch.Size([1, 5, 4])
Predicted: ohlll, Epoch [10/20] loss=0.676
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [11/20] loss=0.580
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [12/20] loss=0.476
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [13/20] loss=0.380
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [14/20] loss=0.300
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [15/20] loss=0.236
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [16/20] loss=0.184
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [17/20] loss=0.142
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [18/20] loss=0.110
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [19/20] loss=0.085
torch.Size([1, 5, 4])
Predicted: ohlol, Epoch [20/20] loss=0.067
进程已结束,退出代码0
4. 总结
长短时记忆网络(LSTM)是一种强大的循环神经网络变体,通过引入记忆细胞和门控机制来处理长期依赖关系。它在自然语言处理、时间序列预测等领域取得了巨大成功,并成为深度学习中的重要组成部分。本文介绍了LSTM的原理、结构和应用,并提供了实践指导。通过对LSTM的深入理解,我们可以更好地利用它来解决各种序列数据分析的问题。
--------推荐专栏--------
手把手实现Image captioning
CNN模型压缩
模式识别与人工智能(程序与算法)
FPGA—Verilog与Hls学习与实践
基于Pytorch的自然语言处理入门与实践
参考
邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.