R语言实现SMOTE与SMOGN算法解决不平衡数据的回归问题
本文介绍基于R语言中的UBL包,读取.csv格式的Excel表格文件,实现SMOTE算法与SMOGN算法,对机器学习、深度学习回归中,训练数据集不平衡的情况加以解决的具体方法。
在之前的文章Python实现SMOGN算法解决不平衡数据的回归问题(https://blog.csdn.net/zhebushibiaoshifu/article/details/131680333)中,我们介绍了基于Python语言中的smogn包,实现SMOGN算法,对机器学习、深度学习回归中训练数据集不平衡的情况加以解决的具体方法;而我们也在上述这一篇文章中提到了,SMOGN算法的Python实现实在是太慢了,且Python还无法较为方便地实现回归数据的SMOTE算法。因此,我们就在本文中介绍一下基于R语言中的UBL包,实现SMOTE算法与SMOGN算法的方法。对于这两种算法的具体介绍与对比,大家参考上述提到的这一篇文章即可,这里就不再赘述了。
首先,我们配置一下所需用到的R语言UBL包。包的下载方法也非常简单,我们输入如下的代码即可。
install.packages("UBL")
输入代码后,按下回车键,运行代码;如下图所示。

接下来,我们即可开始代码的撰写。在这里,我们最好通过如下的方式新建一个R语言脚本(我这里是用的RStudio);因为后期执行算法的时候,我们往往需要对比多种不同的参数搭配效果,通过脚本来运行代码会比较方便。
其中,我们需要的代码如下所示。
library(UBL)
csv_path <- r"(E:\01_Reflectivity\99_Model_Training\00_Data\02_Extract_Data\26_Train_Model_New\Train_Model_0710.csv)"
result_path <- r"(E:\01_Reflectivity\99_Model_Training\00_Data\02_Extract_Data\26_Train_Model_New\Train_Model_0710_smote_nir.csv)"
data <- read.csv(csv_path)
data_nona <- na.omit(data)
data_nona$PointType <- as.factor(data_nona$PointType)
data_nona$days <- as.factor(data_nona$days)
data_smote <- SmoteRegress(inf_dif~., data_nona, dist = "HEOM", C.perc = "balance")
data_smogn <- SMOGNRegress(inf_dif~., data_nona, thr.rel = 0.6, dist = "HEOM", C.perc = "extreme")
hist(data_nona$inf_dif, breaks = 50)
hist(data_smote$inf_dif, breaks = 50)
hist(data_smogn$inf_dif, breaks = 50)
write.csv(data_smogn, file = result_path, row.names = FALSE)
write.csv(data_smote, file = result_path, row.names = FALSE)
其中,上述代码的具体含义如下。
首先,通过library(UBL)将我们刚刚配置好的UBL包加以加载,该包提供了处理不平衡数据的函数和算法;随后,我们可以设置输入的.csv格式文件的路径,这一文件中存储了我们需要加以处理的数据;随后,我们设置输出的.csv格式文件的路径,这一文件就是我们加以处理后的结果数据。
接下来,我们使用read.csv函数读取输入的.csv格式文件,并将其存储在变量data中。其后的data_nona <- na.omit(data)代码表示,去除数据中的缺失值,将处理后的数据保存在data_nona中。随后,这里需要注意,由于我们的输入数据中含有数值型的类别变量,因此需要将其转换为因子(factor)类型,这样才可以被UBL包识别为类别变量。
接下来,第一个函数SmoteRegress()就是使用SMOTE算法对data_nona进行回归任务的不平衡处理——其中inf_dif是目标变量(因变量),~.表示使用所有其他列作为特征(自变量),dist = "HEOM"表示使用HEOM(Heterogeneous Euclidean-Overlap Metric)距离度量(注意,只要我们的输入数据中有类别变量,那么就需要用这一种距离表示方式),最后的C.perc = "balance"表示平衡类别比例。
随后的SMOGNRegress()函数,则是使用SMOGN算法对 data_nona 进行回归任务的不平衡处理——其中thr.rel = 0.6表示设置相对阈值为0.6,这个参数设置的越大,算法执行的程度越深;其他参数则和前一个函数类似。这里如果大家需要对两个函数的参数加以更进一步的理解,可以直接访问其官方网站。
最后,为了比较一下我们执行SMOTE算法与SMOGN算法的结果,可以绘制一下data_nona中,目标变量inf_dif的直方图,breaks = 50表示将直方图分成50个条块。
如果通过直方图确定我们算法处理后的数据可以接受,那么就可以将处理结果数据写入到输出的.csv格式文件,row.names = FALSE表示不保存行索引。
执行上述代码后,我们可以实际看一下三个直方图的结果情况。首先,是处理前的数据,如下图所示。

其次,是SMOTE算法处理后的数据,如下图所示。

最后,是SMOGN算法处理后的数据,如下图所示。
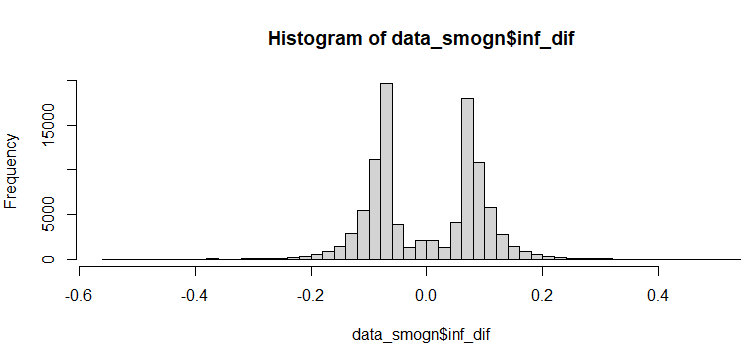
基于以上图片可以很清楚地看出,SMOTE算法与SMOGN算法确实对于原始的数据分布而言,有着明显的改变作用。
至此,大功告成。
欢迎关注:疯狂学习GIS