Flink UDF函数
Flink Table & SQL中的用户[自定义函数]
概述
自定义函数(UDF)是一种扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑。
自定义函数可以用 JVM 语言(例如 Java 或 Scala)或 Python 实现,实现者可以在 UDF 中使用任意第三方库。
当前 Flink 有如下几种函数
-
UDF:自定义标量函数(User Defined Scalar Function)。一行输入一行输出。 (一对一关系)
自定义函数需要继承(extends) ScalarFunction类,并实现eval()方法。
-
UDAF:自定义聚合函数。多行输入一行输出。 (多对一关系)
自定义函数需要继承(extends) AggregateFunction
createAccumulator(),getValue(),accumulate()方法。
createAccumulator() : 初始化累加器
getValue():获取最后的结果值
accumulate():聚合计算的核心方法,每来一行数据都会调用。它的第一个参数是确定的,就是当前的累加
器,类型为 ACC,表示当前聚合的中间状态;后面的参数则是聚合函数调用时传入的参数,可以有多个,类型
也可以不同。这个方法主要是更新聚合状态,所以没有返回类型
-
UDTF:自定义表函数。一行输入多行输出或一列输入多列输出。 (一对多关系)
自定义函数需要继承(extends) TableFunction类,T:输出类型,并实现eval()方法。
-
UDTAGG:表聚合函数(Table Aggregate Functions) (多对多关系)
自定义函数需要继承(extends) TableAggregateFunction
类,T:输出类型,ACC:累加器,并实 现createAccumulator(),accumulate(ACC, value), emitValue(ACC,Collector)
createAccumulator():创建累加器的方法
accumulate(ACC, value):聚合计算的核心方法,每来一行数据都会调用。它的第一个参数是确定的,就是当
前的累加器,类型为 ACC,表示当前聚合的中间状态;后面的参数则是聚合函数调用时传入的参数
emitValue(ACC,Collector):输出最终计算结果,第一个参数是 ACC类型的累加器,第二个参数则是用于输
出数据的“收集器”out,它的类型为 Collect
注意 标量和表值函数已经使用了新的基于数据类型的类型系统,聚合函数仍然使用基于 TypeInformation 的旧类型系统。
以下示例展示了如何创建一个基本的标量函数,以及如何在 Table API 和 SQL 里调用这个函数。
函数用于 SQL 查询前要先经过注册;而在用于 Table API 时,函数可以先注册后调用,也可以 内联 后直接使用。
案例
UDF函数
自定义标量函数可以把 0 到多个标量值映射成 1 个标量值,数据类型里列出的任何数据类型都可作为求值方
法的参数和返回值类型。
想要实现自定义标量函数,你需要扩展 org.apache.flink.table.functions 里面的 ScalarFunction 并
且实现一个或者多个求值方法。标量函数的行为取决于你写的求值方法。求值方法必须是 public 的,而且
名字必须是 eval。
下面的例子展示了如何实现一个求哈希值的函数并在查询里调用它
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// 定义函数逻辑
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");
UDAF函数
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的
createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate()
方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
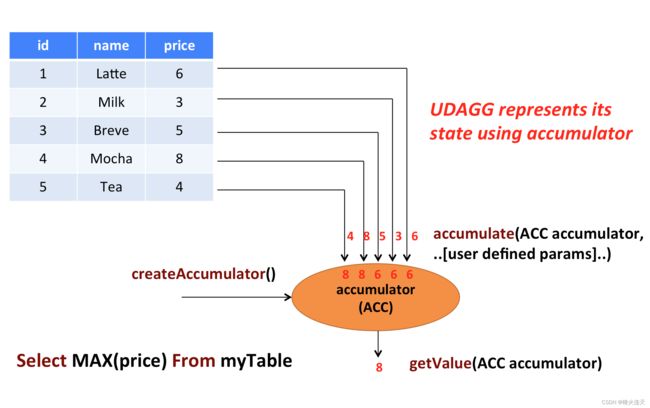
上面的图片展示了一个聚合的例子。假设你有一个关于饮料的表。表里面有三个字段,分别是 id、name、
price,表里有 5 行数据。假设你需要找到所有饮料里最贵的饮料的价格,即执行一个 max() 聚合。你需要遍历
所有 5 行数据,而结果就只有一个数值。
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需
要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的
createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate()
方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
下面几个方法是每个 AggregateFunction 必须要实现的:
createAccumulator()accumulate()getValue()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复杂类型。所以跟 ScalarFunction 和 TableFunction 一样,AggregateFunction 也提供了
AggregateFunction#getResultType() 和 AggregateFunction#getAccumulatorType() 来分别指定返回
值类型和 accumulator 的类型,两个函数的返回值类型也都是 TypeInformation。
除了上面的方法,还有几个方法可以选择实现。这些方法有些可以让查询更加高效,而有些是在某些特定场景下必
须要实现的。例如,如果聚合函数用在会话窗口(当两个会话窗口合并的时候需要 merge 他们的 accumulator)
的话,merge() 方法就是必须要实现的。
AggregateFunction 的以下方法在某些场景下是必须实现的:
retract()在 boundedOVER窗口中是必须实现的。merge()在许多批式聚合和会话以及滚动窗口聚合中是必须实现的。除此之外,这个方法对于优化也很多帮助。例如,两阶段聚合优化就需要所有的AggregateFunction都实现merge方法。resetAccumulator()在许多批式聚合中是必须实现的。
AggregateFunction 的所有方法都必须是 public 的,不能是 static 的,而且名字必须跟上面写的一样。
createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个函数是在抽象类
AggregateFunction 中定义的,而其他函数都是约定的方法。如果要定义一个聚合函数,你需要扩展
org.apache.flink.table.functions.AggregateFunction,并且实现一个(或者多个)accumulate 方法。
accumulate 方法可以重载,每个方法的参数类型不同,并且支持变长参数。
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("wAvg", new WeightedAvg());
// 使用函数
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user");
UDTF函数
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的
createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate()
方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
下面几个方法是每个 AggregateFunction 必须要实现的:
createAccumulator()accumulate()getValue()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复
杂类型。所以跟 ScalarFunction 和 TableFunction 一样,AggregateFunction 也提供了
AggregateFunction#getResultType() 和 AggregateFunction#getAccumulatorType() 来分别指定返回
值类型和 accumulator 的类型,两个函数的返回值类型也都是 TypeInformation。
除了上面的方法,还有几个方法可以选择实现。这些方法有些可以让查询更加高效,而有些是在某些特定场景下必
须要实现的。例如,如果聚合函数用在会话窗口(当两个会话窗口合并的时候需要 merge 他们的 accumulator)
的话,merge() 方法就是必须要实现的。
AggregateFunction 的以下方法在某些场景下是必须实现的:
-
retract()在 boundedOVER窗口中是必须实现的。 -
merge()在许多批式聚合和会话以及滚动窗口聚合中是必须实现的。除此之外,这个方法对于优化也很多帮助。例如,两阶段聚合优化就需要所有的
AggregateFunction都实现merge方法。 -
resetAccumulator()在许多批式聚合中是必须实现的。
AggregateFunction 的所有方法都必须是 public 的,不能是 static 的,而且名字必须跟上面写的一样。
createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个函数是在抽象类
AggregateFunction 中定义的,而其他函数都是约定的方法。如果要定义一个聚合函数,你需要扩展
org.apache.flink.table.functions.AggregateFunction,并且实现一个(或者多个)accumulate 方
法。accumulate 方法可以重载,每个方法的参数类型不同,并且支持变长参数。
下面的例子展示了如何:
- 定义一个聚合函数来计算某一列的加权平均,
- 在
TableEnvironment中注册函数, - 在查询中使用函数。
为了计算加权平均值,accumulator 需要存储加权总和以及数据的条数。在我们的例子里,我们定义了一个类
WeightedAvgAccum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,在失败时进行
恢复,以此来保证精确一次的语义。
我们的 WeightedAvg(聚合函数)的 accumulate 方法有三个输入参数。第一个是 WeightedAvgAccum
accumulator,另外两个是用户自定义的输入:输入的值 ivalue 和 输入的权重 iweight。尽管 retract()、
merge()、resetAccumulator() 这几个方法在大多数聚合类型中都不是必须实现的,我们也在样例中提供了
他们的实现。请注意我们在 Scala 样例中也是用的是 Java 的基础类型,并且定义了 getResultType() 和
getAccumulatorType(),因为 Flink 的类型推导对于 Scala 的类型推导做的不是很好。
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("wAvg", new WeightedAvg());
// 使用函数
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user");
表聚合函数
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
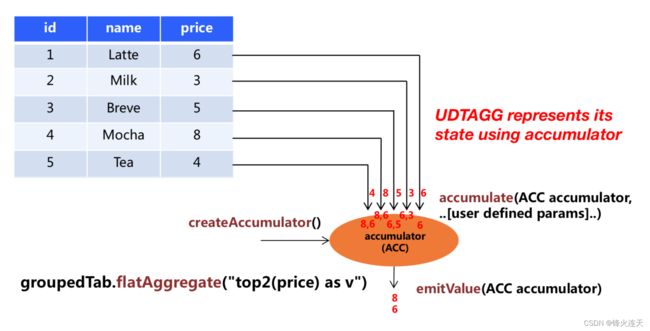
上图展示了一个表值聚合函数的例子。假设你有一个饮料的表,这个表有 3 列,分别是 id、name 和 price,一
共有 5 行。假设你需要找到价格最高的两个饮料,类似于 top2() 表值聚合函数。你需要遍历所有 5 行数据,结
果是有 2 行数据的一个表。
用户自定义表值聚合函数是通过扩展 TableAggregateFunction 类来实现的。一个 TableAggregateFunction
的工作过程如下。首先,它需要一个 accumulator,这个 accumulator 负责存储聚合的中间结果。 通过调用
TableAggregateFunction 的 createAccumulator 方法来构造一个空的 accumulator。接下来,对于每一行
数据,会调用 accumulate 方法来更新 accumulator。当所有数据都处理完之后,调用 emitValue 方法来计算
和返回最终的结果。
下面几个 TableAggregateFunction 的方法是必须要实现的:
createAccumulator()accumulate()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复
杂类型。所以类似于 ScalarFunction 和 TableFunction,TableAggregateFunction 也提供了
TableAggregateFunction#getResultType() 和 TableAggregateFunction#getAccumulatorType() 方法
来指定返回值类型和 accumulator 的类型,这两个方法都需要返回 TypeInformation。
除了上面的方法,还有几个其他的方法可以选择性的实现。有些方法可以让查询更加高效,而有些方法对于某些特
定场景是必须要实现的。比如,在会话窗口(当两个会话窗口合并时会合并两个 accumulator)中使用聚合函数
时,必须要实现merge() 方法。
下面几个 TableAggregateFunction 的方法在某些特定场景下是必须要实现的:
retract()在 boundedOVER窗口中的聚合函数必须要实现。merge()在许多批式聚合和以及流式会话和滑动窗口聚合中是必须要实现的。resetAccumulator()在许多批式聚合中是必须要实现的。emitValue()在批式聚合以及窗口聚合中是必须要实现的。
下面的 TableAggregateFunction 的方法可以提升流式任务的效率:
emitUpdateWithRetract()在 retract 模式下,该方法负责发送被更新的值。
emitValue 方法会发送所有 accumulator 给出的结果。拿 TopN 来说,emitValue 每次都会发送所有的最大的
n 个值。这在流式任务中可能会有一些性能问题。为了提升性能,用户可以实现 emitUpdateWithRetract 方
法。这个方法在 retract 模式下会增量的输出结果,比如有数据更新了,我们必须要撤回老的数据,然后再发送新
的数据。如果定义了 emitUpdateWithRetract 方法,那它会优先于 emitValue 方法被使用,因为一般认为
emitUpdateWithRetract 会更加高效,因为它的输出是增量的。
TableAggregateFunction 的所有方法都必须是 public 的、非 static 的,而且名字必须跟上面提到的一
样。createAccumulator、getResultType 和 getAccumulatorType 这三个方法是在抽象父类
TableAggregateFunction 中定义的,而其他的方法都是约定的方法。要实现一个表值聚合函数,你必须扩展
org.apache.flink.table.functions.TableAggregateFunction,并且实现一个(或者多个)accumulate
方法。accumulate 方法可以有多个重载的方法,也可以支持变长参数。
下面的例子展示了如何
- 定义一个
TableAggregateFunction来计算给定列的最大的 2 个值, - 在
TableEnvironment中注册函数, - 在 Table API 查询中使用函数(当前只在 Table API 中支持 TableAggregateFunction)。
为了计算最大的 2 个值,accumulator 需要保存当前看到的最大的 2 个值。在我们的例子中,我们定义了类 Top2Accum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,并且在失败时进行恢复,来保证精确一次的语义。
我们的 Top2 表值聚合函数(TableAggregateFunction)的 accumulate() 方法有两个输入,第一个是 Top2Accum accumulator,另一个是用户定义的输入:输入的值 v。尽管 merge() 方法在大多数聚合类型中不是必须的,我们也在样例中提供了它的实现。请注意,我们在 Scala 样例中也使用的是 Java 的基础类型,并且定义了 getResultType() 和 getAccumulatorType() 方法,因为 Flink 的类型推导对于 Scala 的类型推导支持的不是很好。
/**
* Accumulator for Top2.
*/
public class Top2Accum {
public Integer first;
public Integer second;
}
/**
* The top2 user-defined table aggregate function.
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {
for (Top2Accum otherAcc : iterable) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("top2", new Top2());
// 初始化表
Table tab = ...;
// 使用函数
tab.groupBy("key")
.flatAggregate("top2(a) as (v, rank)")
.select("key, v, rank");
疯
所有打不死你的,都会使你变得更强大!