MySQL学习笔记之索引优化与查询优化
文章目录
- 前言
- 数据准备
-
- 建表
- 创建函数
- 插入数据
- 创建删除索引函数
- 索引失效案例
-
- 全值匹配
- 最佳左前缀法则
- 主键插入顺序
- 计算、函数导致列索引失效
-
- 函数导致索引失效
- 计算导致索引失效
- 类型转换导致列索引失效
- 范围条件右边的列索引失效
- 不等于导致列索引失效
- is not null不能使用索引
- like以通配符%开头导致列索引失效
- or前后存在非索引的列导致列索引失效
- 数据库和表的字符集应统一使用utf8mb4
- 关联查询优化
-
- 数据准备
- 左外连接
- 内连接
- 小结
- 子查询优化
- 排序优化
-
- 优化建议
- 举例
-
- 方案1:创建联合索引(age, name)
- 方案2:直接创建一个三字段索引
- filesort调优策略
- 分组优化
- 分页查询优化
-
- 优化思路一
- 优化思路二
- 优先考虑覆盖索引
-
- 覆盖索引的定义
- 覆盖索引的利弊
- 给字符串添加索引
-
- 前缀索引
- 前缀索引对覆盖索引的影响
- 索引下推
-
- 使用前后的扫描过程
-
- 使用ICP前的扫描过程
- 使用ICP扫描的过程
- 使用前后的成本差别
- ICP的使用条件
- ICP使用案例
- 普通索引和唯一索引
-
- 查询过程
- 更新过程
- change buffer的使用场景
- 其他查询优化策略
-
- exists和in的区分
- count(*)、count(1)和count(字段)的效率
- 关于select(*)
- limit 1对优化的影响
- 多使用commit
前言
MySQL查询优化有两种方法:物理查询优化和逻辑查询优化。
- 物理查询优化是通过索引或表连接等方式来进行优化;
- 逻辑查询优化是通过SQL等价变化来提升查询效率(即换一种SQL写法)。
本文记录的是物理查询优化方法。
数据准备
学生表50万条数据,班级表1万条数据。
建表
mysql> CREATE TABLE `class` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `className` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, `monitor` INT NULL , PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.09 sec)
mysql> CREATE TABLE `student` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `stuno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `classId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.01 sec)
创建函数
创建用来插入随机数据的函数:
mysql> set global log_bin_trust_function_creators=1;
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER //
mysql> CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END //
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11) BEGIN DECLARE i INT DEFAULT 0; SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ; RETURN i; END //
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE PROCEDURE insert_stu2( START INT , max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO student (stuno, name ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000)); UNTIL i = max_num END REPEAT; COMMIT; END //
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE PROCEDURE `insert_class`( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO class ( classname,address,monitor ) VALUES (rand_string(8),rand_string(10),rand_num(1,100000)); UNTIL i = max_num END REPEAT; COMMIT; END //
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
插入数据
mysql> call insert_class(10000);
Query OK, 0 rows affected (1.11 sec)
mysql> call insert_stu2(100000, 500000);
Query OK, 0 rows affected (33.24 sec)
创建删除索引函数
mysql> delimiter //
mysql> CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200)) BEGIN DECLARE done INT DEFAULT 0; DECLARE ct INT DEFAULT 0; DECLARE _index VARCHAR(200) DEFAULT ''; DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ; DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ; OPEN _cur; FETCH _cur INTO _index; WHILE _index<>'' DO SET @str = CONCAT("drop index " , _index , " on " , tablename ); PREPARE sql_str FROM @str ; EXECUTE sql_str; DEALLOCATE PREPARE sql_str; SET _index=''; FETCH _cur INTO _index; END WHILE; CLOSE _cur; END //
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
索引失效案例
全值匹配
首先,针对student表的age、name和classId分别建立索引(age)、(age, name)和(age, name, classId):
create index idx_age on student(age);
create index idx_age_name on student(age, name);
create index idx_age_name_classid on student(age,name,classId);
如果where中有对多个索引列进行的等值匹配,且由and连接,则会尽量使用覆盖面最大的联合索引:
mysql> explain select * from student where age = 20 and name = 'a' and classid = 1;
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_age_name_classid,idx_name,idx_age,idx_age_name | idx_age_name_classid | 73 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
可以看到key列中,使用的索引是覆盖面最大的(age, name, classId)。
最佳左前缀法则
一个联合索引最多可以包含16个字段。
- 如果
where的等值匹配中,多个索引列是按照定义对应的联合索引列时的顺序书写的,则会使用该联合索引的所有字段; - 如果联合索引中某个字段被跳过,则后面的索引字段都不会被使用:
mysql> explain select * from student where age = 20 and name = 'a' and classid = 1;
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_age_name_classid,idx_name,idx_age,idx_age_name | idx_age_name_classid | 73 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+----------------------------------------------------+----------------------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select * from student where age = 20 and classId = 1;
+----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+-------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | ref | idx_age_name_classid,idx_age_name | idx_age_name_classid | 5 | const | 18480 | 10.00 | Using index condition |
+----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
执行select * from student where age = 20 and classId = 1;时,因为跳过了联合索引中的name字段,导致只有最前面的age使用到了联合索引,因此用到的索引长度为5(4(int) + 1(null))。
主键插入顺序
假设有如下的聚簇索引B+树叶子结点:
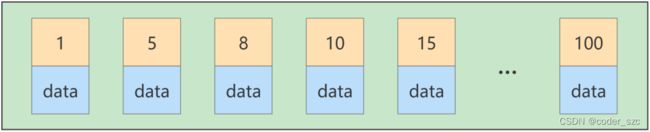
此时如果再插入一条主键为9的记录,该记录的位置就会在8和10之间:

如果插入前,该页面已经满了,就需要通过页分裂将该页面分裂成两个页面,将本页中的一些数据移动到新创建的页中,这样会带来无味的性能损耗。因此,建议让主键按插入的顺序依次递增,或者拥有auto_increment属性,让存储引擎自己为记录生成主键,而不是我们手动插入。
计算、函数导致列索引失效
函数导致索引失效
先给student表的name字段创建索引:
CREATE INDEX idx_name ON student(NAME);
当我们使用like关键字对索引列执行右模糊查询时,会使用到刚创建的索引:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name LIKE 'abc%';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_name | idx_name | 63 | NULL | 32 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 2 warnings (0.01 sec)
但如果对索引列使用函数,就不能使用索引了:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE left(name, 3) = 'abc';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 499086 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
计算导致索引失效
给student表的stuno设置索引:
CREATE INDEX idx_sno ON student(stuno);
如果在where语句中对索引列进行计算,那么索引失效:
mysql> EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 499086 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
把对应的计算去掉,就可以使用索引:
mysql> EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
+----+-------------+---------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_sno | idx_sno | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 2 warnings (0.00 sec)
类型转换导致列索引失效
student表的name字段是varchar类型,因此下面的查询不会用到索引:
mysql> EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE name = 123;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 499086 | 10.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 4 warnings (0.00 sec)
若把where中索引列的匹配值改成索引列对应的类型,即可使用索引:
mysql> EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE name = "123";
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_name | idx_name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 2 warnings (0.00 sec)
范围条件右边的列索引失效
先给student表删除原有的name索引,再创建一个(age, name, classid)联合索引:
drop index idx_name on student;
create index idx_age_name_classid on student(age,name,classid);
那么,以下查询会用到新创建的联合索引,因为联合索引(age, name, classId)中的列从左往右依次为等值匹配、等值匹配、范围匹配:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20 ;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_name_classid | idx_age_name_classid | 73 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
1 row in set, 2 warnings (0.00 sec)
但如果把联合索引中最前面的age从等值匹配改成不等值匹配,就不能用到索引(age, name, classId)了:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age > 30 AND student.classId = 20 AND student.name = 'abc' ;
+----+-------------+---------+------------+------+-----------------------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_age_name_classid,idx_age_name | NULL | NULL | NULL | 499086 | 0.50 | Using where |
+----+-------------+---------+------------+------+-----------------------------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
where中的顺序是无所谓的,比如把中间的student.classId改成范围匹配,还是会用到联合索引:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.classId > 20 AND student.name = 'abc' ;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_name_classid | idx_age_name_classid | 73 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
1 row in set, 2 warnings (0.00 sec)
结论就是,创建联合索引时,要把范围匹配的列写到最后。
不等于导致列索引失效
给student.name字段加上索引:
create index idx_name on student(name);
对索引列进行不等于判断,会导致列索引失效;对索引列进行等值判断,则不会导致索引失效:
mysql> explain select * from student where name = 'abc';
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_name | idx_name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from student where name != 'abc';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 499086 | 50.16 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
is not null不能使用索引
给student.name字段加上索引:
create index idx_name on student(name);
- 如果
where中对索引列进行了is not null判断,则对应的索引失效; - 如果是
is null判断,就不会失效:
mysql> explain select * from student where name is not null;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 499086 | 50.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select * from student where name is null;
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | ref | idx_name | idx_name | 63 | const | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
like以通配符%开头导致列索引失效
左模糊会导致索引失效,右模糊不会:
mysql> explain select * from student where name like '%abc';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 499086 | 11.11 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from student where name like 'abc%';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_name | idx_name | 63 | NULL | 32 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
or前后存在非索引的列导致列索引失效
我们再给student.age字段创建索引:
mysql> create index idx_age on student(age);
如果where子句中的or判断中,不存在非索引列,则索引生效:
mysql> explain select * from student where age = 10 or name = 'a';
+----+-------------+---------+------------+-------------+---------------------------------------+------------------+---------+------+-------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------------+---------------------------------------+------------------+---------+------+-------+----------+--------------------------------------------+
| 1 | SIMPLE | student | NULL | index_merge | idx_age_name_classid,idx_name,idx_age | idx_age,idx_name | 5,63 | NULL | 10007 | 100.00 | Using union(idx_age,idx_name); Using where |
+----+-------------+---------+------------+-------------+---------------------------------------+------------------+---------+------+-------+----------+--------------------------------------------+
1 row in set, 1 warning (0.01 sec)
如果存在非索引列,则索引失效:
mysql> explain select * from student where classid = 10 or name = 'a';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 499086 | 19.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
数据库和表的字符集应统一使用utf8mb4
统一使用utf8mb4会拥有更好的兼容性,从而避免字符集转换成生乱码,而且不同字符集进行比较前进行的转换会导致列索引失效。
关联查询优化
本章对左外连接优化和内连接优化的学习笔记进行整理。
数据准备
mysql> create table type(id int(10) unsigned not null auto_increment, card int(10) unsigned not null, primary key(id)) ;
Query OK, 0 rows affected (0.02 sec)
mysql> create table book_card(bookId int(10) unsigned not null auto_increment, card int(10) unsigned not null, primary key(bookId)) ;
Query OK, 0 rows affected (0.01 sec)
然后向两张表插入20条随机数据:
mysql> insert into type(card) values(floor(1 + rand() * 20));
mysql> insert into book_card(card) values(floor(1 + rand() * 20));
左外连接
左外连接的主要优化点在于提升被连接表的扫描效率,写一条简单的左外连接,查看执行计划;
mysql> explain SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book_card ON type.card = book_card.card;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book_card | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
会发现连接表和被连接表的类型都是all,即全表扫描。为了避免这种情况,我们应该对被连接表的连接键创建索引:
mysql> create index idx_y on book_card(card);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book_card ON type.card = book_card.card;
+----+-------------+-----------+------------+------+---------------+-------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+-------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book_card | NULL | ref | idx_y | idx_y | 4 | review_mysql.type.card | 1 | 100.00 | Using index |
+----+-------------+-----------+------------+------+---------------+-------+---------+------------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
这样一来,就避免了被连接表的全表扫描(类型变成了ref)。
如果我们仅对连接表的连接键建立了索引,那就不能避免被连接表的全表扫描:
mysql> drop index idx_y on book_card;
Query OK, 0 rows affected (0.01 sec)
mysql> create index idx_x on type(card);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book_card ON type.card = book_card.card;
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | index | NULL | idx_x | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book_card | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-----------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
内连接
先把book_card和type中的索引删掉:
mysql> drop index idx_x on type;
mysql> drop index idx_y on book_card;
然后查看两表内连接的执行计划:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type JOIN book_card ON type.card=book_card.card;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book_card | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
先后给type表和book_card表的连接键加上索引,然后再看执行计划:
mysql> create index idx_x on type(card);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type JOIN book_card ON type.card=book_card.card;
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
| 1 | SIMPLE | book_card | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | type | NULL | ref | idx_x | idx_x | 4 | review_mysql.book_card.card | 1 | 100.00 | Using index |
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
mysql> create index idx_y on book_card(card);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book_card ON type.card = book_card.card;
+----+-------------+-----------+------------+-------+---------------+-------+---------+------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+-------+---------+------------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | NULL | idx_x | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book_card | NULL | ref | idx_y | idx_y | 4 | review_mysql.type.card | 1 | 100.00 | Using index |
+----+-------------+-----------+------------+-------+---------------+-------+---------+------------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
发现加上索引后,对应的表均避免了全表扫描。此时执行计划中,type表在上面,是驱动表,book_card在下面,是被驱动表,如果我们删除book_card的索引,它就会成为驱动表:
mysql> drop index idx_y on book_card;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain SELECT SQL_NO_CACHE * FROM `type` JOIN book_card ON type.card = book_card.card;
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
| 1 | SIMPLE | book_card | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | type | NULL | ref | idx_x | idx_x | 4 | review_mysql.book_card.card | 1 | 100.00 | Using index |
+----+-------------+-----------+------------+------+---------------+-------+---------+-----------------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
这时SQL优化器帮我们选择了最优的被驱动表,因为type表的连接键有索引,查询效率高,索引它成为了被驱动表。
小结
- 保证驱动表的连接键已经有了索引,且能被使用;
- 连接键的类型在多个表中要保持绝对一致;
- 左连接时,小表为左表,驱动右表(大表);
- 内连接时,MySQL会自动将查询效率最高的表作为驱动表;
- 能够关联的表就直接关联,不用子查询,从而避免查询的趟数;
- 不建议使用子查询,建议将子查询SQL拆成多次查询,或使用多表连接代替;
- 衍生表不能建立索引。
子查询优化
子查询效率不高,因为:
- 执行子查询时,MySQL需要为内存查询语句的查询结果建立一张临时表,而后外查询语句从临时表中查询记录,查询完后再撤销这些临时表。这个过程会消耗过多的CPU和IO资源,产生大量的慢查询;
- 临时表不能建立索引,因此查询性能较差;
- 如果子查询返回的结果越多,对其的查询性能就越差。
建议使用多表连接代替子查询,因为多表连接不会建立临时表,也可以通过给被连接表的连接键建立索引来提升查询效率。也不建议使用not in或not exists,尽量用left join xx on xx where xx is null替代。
排序优化
优化建议
- SQL中使用索引是为了在
where中避免全表扫描,在order by中避免FileSort排序。尽管某些情况下全表扫描或文件排序不比索引慢,但总的来说我们还是要避免,以提高查询效率; - 尽量使用索引完成排序,如果
where和order by是相同的列,则使用单列索引,否则使用联合索引; - 如果不能使用索引,则需要对文件排序进行调优。
举例
若有联合索引(a, b, c),则:
order by a/order by a, b/order by a, b, c/order by a desc, b desc, c desc均可以使用该联合索引(最长左前缀原则);where a = const order by b, c/where a = const and b = const order by c/where a = const and b > const order by b, c均可以使用该索引,因为where子句中符合最左前缀等值匹配原则;order by a asc, b desc, c desc/where g = const order by b, c/where a = const order by c/where a = const order by a, d/where a in (...) order by b,c均不能使用该索引,原因分别是:排序不一致 / 丢失a索引 / 丢失b索引 / 丢失索引b和c/ 对于排序来说,多个相等条件也是范围查询
对于student表,我们先删除其上的所有索引,只保留主键:
call proc_drop_index('review_mysql', "student");
场景:查询年龄为30岁、学生编号小于101000的学生,并按照用户名排序。
在没有任何索引的情况下,执行计划如下所示:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno < 101000 ORDER BY NAME ;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 499086 | 3.33 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------------------+
1 row in set, 2 warnings (0.00 sec)
执行计划中出现了全表扫描+文件排序,我们应该进行优化。
方案1:创建联合索引(age, name)
此时where子句中的stuno < 101000会被优化器提前,我们看一下执行计划:
mysql> create index idx_age_name on student(age, name);
Query OK, 0 rows affected (1.28 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+------------------------------------+
| 1 | SIMPLE | student | NULL | ref | idx_age_name | idx_age_name | 5 | const | 19108 | 33.33 | Using index condition; Using where |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+------------------------------------+
1 row in set, 2 warnings (0.00 sec)
该SQL执行时间为1.32s:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 596 | 100596 | AAdQVd | 30 | 744 |
| 403 | 100403 | bHhNsB | 30 | 378 |
| 475 | 100475 | cJXVKM | 30 | 750 |
| 542 | 100542 | CwAoSw | 30 | 691 |
| 983 | 100983 | dZOUgZ | 30 | 923 |
| 792 | 100792 | gAggmT | 30 | 334 |
| 251 | 100251 | KLBzSR | 30 | 422 |
| 292 | 100292 | MiEzJK | 30 | 856 |
| 65 | 100065 | MTktop | 30 | 97 |
| 382 | 100382 | PgoZfE | 30 | 242 |
| 689 | 100689 | qAFBPu | 30 | 744 |
| 691 | 100691 | QNsBDn | 30 | 139 |
| 81 | 100081 | qntend | 30 | 703 |
| 588 | 100588 | rSlDjm | 30 | 249 |
| 187 | 100187 | xCshJV | 30 | 147 |
| 653 | 100653 | zXsTsg | 30 | 520 |
+-----+--------+--------+------+---------+
16 rows in set, 1 warning (1.32 sec)
方案2:直接创建一个三字段索引
mysql> create index idx_age_stuno_name on student(age, stuno, name);
此时,我们看一下执行计划:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_stuno_name | idx_age_stuno_name | 9 | NULL | 16 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+--------------------+--------------------+---------+------+------+----------+---------------------------------------+
1 row in set, 2 warnings (0.00 sec)
出现了文件排序,但该SQL的执行时间比方案一的要短:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 596 | 100596 | AAdQVd | 30 | 744 |
| 403 | 100403 | bHhNsB | 30 | 378 |
| 475 | 100475 | cJXVKM | 30 | 750 |
| 542 | 100542 | CwAoSw | 30 | 691 |
| 983 | 100983 | dZOUgZ | 30 | 923 |
| 792 | 100792 | gAggmT | 30 | 334 |
| 251 | 100251 | KLBzSR | 30 | 422 |
| 292 | 100292 | MiEzJK | 30 | 856 |
| 65 | 100065 | MTktop | 30 | 97 |
| 382 | 100382 | PgoZfE | 30 | 242 |
| 689 | 100689 | qAFBPu | 30 | 744 |
| 691 | 100691 | QNsBDn | 30 | 139 |
| 81 | 100081 | qntend | 30 | 703 |
| 588 | 100588 | rSlDjm | 30 | 249 |
| 187 | 100187 | xCshJV | 30 | 147 |
| 653 | 100653 | zXsTsg | 30 | 520 |
+-----+--------+--------+------+---------+
16 rows in set, 1 warning (0.00 sec)
结论:
- 若两个索引同时存在,MySQL会自动选择最优方案,该选择会随着数据量的变化而变化;
- 如果
where和group by/order by的字段出现了二选一情况,优先观察where字段的过滤量:如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在where字段上;反之亦然。
上面案例中,也可以建立联合索引(age, stuno):
mysql> create index idx_age_stuno on student(age, stuno);
Query OK, 0 rows affected (0.93 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_stuno | idx_age_stuno | 9 | NULL | 16 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+---------------+---------------+---------+------+------+----------+---------------------------------------+
1 row in set, 2 warnings (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 596 | 100596 | AAdQVd | 30 | 744 |
| 403 | 100403 | bHhNsB | 30 | 378 |
| 475 | 100475 | cJXVKM | 30 | 750 |
| 542 | 100542 | CwAoSw | 30 | 691 |
| 983 | 100983 | dZOUgZ | 30 | 923 |
| 792 | 100792 | gAggmT | 30 | 334 |
| 251 | 100251 | KLBzSR | 30 | 422 |
| 292 | 100292 | MiEzJK | 30 | 856 |
| 65 | 100065 | MTktop | 30 | 97 |
| 382 | 100382 | PgoZfE | 30 | 242 |
| 689 | 100689 | qAFBPu | 30 | 744 |
| 691 | 100691 | QNsBDn | 30 | 139 |
| 81 | 100081 | qntend | 30 | 703 |
| 588 | 100588 | rSlDjm | 30 | 249 |
| 187 | 100187 | xCshJV | 30 | 147 |
| 653 | 100653 | zXsTsg | 30 | 520 |
+-----+--------+--------+------+---------+
16 rows in set, 1 warning (0.00 sec)
filesort调优策略
- 尝试提高
sort_buffer_size; - 尝试提高
max_length_for_sort_data(在1024字节和8192字节之间调整); order by时不要select *,最好只查询需要的字段。
分组优化
- 分组使用索引的原则跟
order b几乎一致,即使分组没有过滤条件用到索引,也可以直接使用索引; group by先排序再分组,遵照索引的最佳左前缀法则;- 如果无法使用索引列,增大
sort_buffer_size和max_length_for_sort_data值; where效率高于having,能在where中限定的条件就不要限定在having中;- 减少使用
order by,order by、group by、distinct这些语句比较消耗CPU; - 如果包含了
order by、group by、distinct这些查询语句,尽量保持where过滤出来的数据在1000行以内。
分页查询优化
针对以下SQL:SELECT * FROM student LIMIT 2000000, 10;有两种优化方式:
优化思路一
在索引上完成排序分页操作,最后通过主键关联到主查询,查询所需要的其他列的内容:
mysql> EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id = a.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 499086 | 100.00 | NULL |
| 1 | PRIMARY | t | NULL | eq_ref | PRIMARY | PRIMARY | 4 | a.id | 1 | 100.00 | NULL |
| 2 | DERIVED | student | NULL | index | NULL | PRIMARY | 4 | NULL | 499086 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
优化思路二
把limit转换成某个位置的查询,此方案适用于主键自增的表,从而避免回表:
mysql> EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
优先考虑覆盖索引
覆盖索引的定义
在非聚簇索引B+树中,叶子结点存储了它们索引的数据。如果能通过读取索引就可以得到想要的数据,就不用回表读取行了。因此,如果一个索引包含了满足查询结果的数据,该索引就是覆盖索引。
覆盖索引的利弊
好处:避免回表;把随机IO变成顺序IO,提高了查询效率。
坏处:维护索引需要代价。
覆盖索引的出现,可能会导致索引失效案例中一些情况被颠覆(如不等于、左模糊等),特别是select字段中的字段被索引列覆盖时:
mysql> create index idx_age_name on student(age, name);
Query OK, 0 rows affected (1.46 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select age from student where age != 10;
+----+-------------+---------+------------+-------+------------------------------+-----------------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+------------------------------+-----------------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_classId,idx_age_name | idx_age_classId | 5 | NULL | 432453 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+------------------------------+-----------------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select name, id from student where name like '%a';
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | index | NULL | idx_age_name | 68 | NULL | 499086 | 11.11 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
给字符串添加索引
前缀索引
如果要给某个字符串字段添加索引,则最好使用前缀索引,比如:
alter table teacher add index index2(email(6))
上例就是取email字段前6个字符作为索引,这样既可以节省空间,又不用增加太多的额外查询成本。
前缀索引对覆盖索引的影响
使用前缀索引就不用覆盖索引去优化查询性能了。
索引下推
索引下推(Index Condition Pushdown, ICP)是一种在存储引擎层使用索引过滤数据的优化方式,可以减少存储引擎访问基表的次数,以及MySQL服务器访问存储引擎的次数。
使用前后的扫描过程
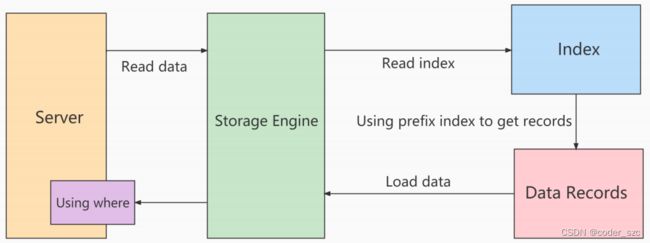
使用ICP前的扫描过程
storage层:只将满足索引键条件的索引记录对应的整行数据取出,返回给server层;
server层:对返回的数据,使用where条件过滤。

使用ICP扫描的过程
storage层:首先将索引键条件满足的索引记录区间确定,然后在索引上使用索引过滤器进行过滤。根据满足的索引过滤条件的索引记录去回表,取出整行记录返回给server层。不满足者直接丢弃。
server层:对返回的数据,使用where条件进行最后的过滤。


使用前后的成本差别
- 使用前,存储层多返回了需要被索引过滤器过滤掉的整行记录;
- 使用后,只返回满足索引过滤条件的记录,省去了不满足者的回表和传给server层的成本。
ICP的加速效果取决于存储引擎内通过ICP筛选掉的数据比例。
ICP的使用条件
- 只能用于非主键索引;
explain显示的执行计划中type值为range、ref、eq_ref或ref_or_null;where条件必须在索引列中;- 存储引擎为
MyISAM或InnoDB; - 5.7版本开始支持分区表的ICP;
- 若SQL使用覆盖索引,则不支持ICP。
ICP使用案例
对于以下SQL:
SELECT * FROM tuser WHERE NAME LIKE '张%' AND age = 10 AND ismale = 1;
且age是索引列,那么ICP过程如下图所示:
 如果不使用ICP,那么那两条age不为10的记录,也会参与回表:
如果不使用ICP,那么那两条age不为10的记录,也会参与回表:
普通索引和唯一索引
以下表为例:
create table test(id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB;
表中五条数据(R1~R5)的(id, k)值分别为(100, 1)、(200, 2)、(300, 3)、(500, 5)和(600, 6)。
查询过程
假设查询语句为select id from test where k = 5;。那么:
- 对于普通索引来说,查找到满足条件的第一个记录
(5, 500)后,需要查找下一条记录,直到找到第一个不满足k = 5条件的记录; - 对于唯一索引来说,因为索引定义了唯一性,查到第一个满足条件的记录后,就会停止检索。
不过实际上,这两种方法带来的性能差距是微乎其微的。
更新过程
先介绍一下change buffer(更新缓存)。当需要更新一个数据页时,如果数据页在内存中就直接更新,否则,在不影响数据一致性的前提下,InnoDB会把更新操作缓存在更新缓存中,从而避免从磁盘中读入该数据页。如果以后的某次查询需要访问这个数据页,InnoDB会将该数据页读入内存,然后执行更新缓存中和这个页有关的操作,从而保证数据逻辑的正确性。
将更新缓存中的操作应用到原始数据页得到最新结果的过程称之为merge,除了访问该数据页会触发merge外,系统的后台线程也会定期merge。在数据库正常关闭的过程中,也会执行merge。
如果能够将更新操作先记录在更新缓存中,可以减少对磁盘的IO,从而明显提升语句的执行速度,并且还可以避免占用过多内存,以提高内存利用率。
更新缓存只能用在普通索引中,唯一索引的更新不能使用更新缓存。
change buffer的使用场景
- 普通索引和唯一索引应该怎么选择?其实,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。所以,建议尽量选择普通索引 ;
- 在实际使用中会发现, 普通索引和更新缓存的配合使用,对于数据量大的表的更新优化还是很明显的;
- 如果所有的更新后面,都马上伴随着对这个记录的查询 ,那么你应该关闭更新缓存 。而在其他情况下,更新缓存都能提升更新性能;
- 由于唯一索引用不上
change buffer的优化机制,因此如果 业务可以接受 ,从性能角度出发建议优先考虑非唯一索引。但是如果"业务可能无法确保"的情况下,怎么处理呢?
首先, 业务正确性优先 。我们的前提是“业务代码已经保证不会写入重复数据”的情况下,讨论性能问题。如果业务不能保证,或者业务就是要求数据库来做约束,那么没得选,必须创建唯一索引。这种情况下,本节的意义在于,如果碰上了大量插入数据慢、内存命中率低的时候,给你多提供一个排查思路。
然后,在一些“ 归档库 ”的场景,你是可以考虑使用唯一索引的。比如,线上数据只需要保留半年,然后历史数据保存在归档库。这时候,归档数据已经是确保没有唯一键冲突了。要提高归档效率,可以考虑把表里面的唯一索引改成普通索引。
其他查询优化策略
exists和in的区分
针对以下语句:
select * from a where cc in (select cc from b); # 1
select * from a where exists (select cc from b where b.cc = a.cc); # 2
结论:
如果a < b,则用exists,因为exists相当于外表驱动内表;
如果a > b,则用in,因为in相当于内表驱动外表。
count(*)、count(1)和count(字段)的效率
-
count(*)和count(1)没有本质区别,都是对符合条件的所有结果进行统计; -
效率对比:
- 如果是
MyISAM引擎,count(*)和count(1)都是O(1)时间复杂度,因为每张MyISAM表的meta信息中都存储了row_count值,数据一致性则由表级锁来保证; - 如果是
InnoDB引擎,由于InnoDB支持事务,采用了行级锁和MVCC机制,因此需要扫描全表,采用循环+计数的方式完成统计;
- 如果是
-
在
InnoDB中,若采用count(字段)统计行数,要尽量采用非主键索引。因为主键采用的是聚簇索引,包含的信息量明显大于非主键索引。对于count(*)和count(1),因为它们只要统计行数,所以系统会自动采用占用空间更小的非主键索引进行统计。如果有多个非主键索引,会使用key_len小的非主键索引进行扫描。如果没有非主键索引,才会通过主键索引进行统计。
关于select(*)
建议明确查询字段,MySQL在解析的过程中,会通过查询数据字典将*按序转换沉所有列名,这会大大耗费资源和时间,而且无法使用覆盖索引。
limit 1对优化的影响
针对进行全表扫描的语句,如果确定结果集只有一条,则加上limit 1会导致找到一条结果后就不会继续扫描,从而加快查询速率。
如果数据表已经对字段建立了唯一索引,那么可以通过该唯一索引进行查询,不会全表扫描,也不用加limit 1。
多使用commit
只要有可能,程序中就尽量多使用commit,这样可以释放以下资源:
- 回滚段上用于恢复数据的信息;
- 程序语句获得的锁;
- 重做日志缓存或撤销日志缓存中的空间;
- 管理上述资源的开销。