HDFS相关内容
HDFS
一、文件系统的定义
文件系统是一种存储和组织数据的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户对文件访问
和查找变得容易;
文件系统使用树形目录的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘
哪里,只需要记住这个文件的所属目录和文件名即可;
文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。
二、数据、元数据概念
数据
指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,
只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
元数据
元数据(metadata)又称之为解释性数据,记录数据的数据;
文件系统元数据一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
三、HDFS简介
HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非
常适于存储大型数据 (比如 TB 和 PB)。
HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。

四、HDFS重要特性
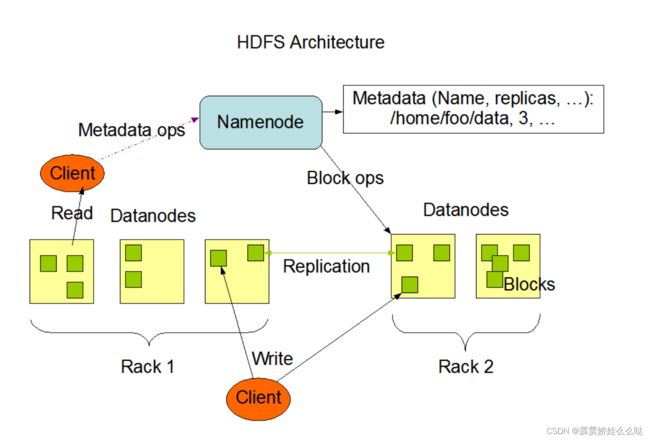
A、主从架构
-
HDFS集群是标准的master/slave主从架构集群。
-
一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
-
Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服
务。
-
官方架构图中是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上。
B、分块存储
- HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。
- 块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。

C、副本机制
- 文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
- 副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本。

D、元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
- 文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
- 文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
E、namespace
- HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
- Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
- HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
F、数据块存储
- 文件的各个block的具体存储管理由DataNode节点承担。
- 每一个block都可以在多个DataNode上存储。

五、HDFS shell命令行
1、解释说明
命令行界面(英语:command-line interface,缩写:CLI),是指用户通过键盘输入指令,计算机接收到指令后
,予以执行一种人际交互方式。
Hadoop提供了文件系统的shell命令行客户端: hadoop fs [generic options]

2、文件系统协议
HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file:///)、分布式文件系统(hdfs://nn:8020)等
具体操作的是什么文件系统取决于命令中文件路径URL中的前缀协议。
如果没有指定前缀,则将会读取环境变量中的fs.defaultFS属性,以该属性值作为默认文件系统。
hadoop fs -ls file:/// #操作本地文件系统
hadoop fs -ls hdfs://node1:8020/ #操作HDFS分布式文件系统
hadoop fs -ls / #直接根目录,没有指定协议 将加载读取fs.defaultFS值
3、区别
hadoop从1发展到至今,有很多命令:
hadoop dfs 只能操作HDFS文件系统(包括与Local FS间的操作),不过已经Deprecated;
hdfs dfs 只能操作HDFS文件系统相关(包括与Local FS间的操作),常用;
hadoop fs 可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广;
目前版本来看,官方最终推荐使用的是hadoop fs。当然hdfs dfs在市面上的使用也比较多。

六、HDFS shell常用命令
官方命令指导:https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
1、创建文件夹
hadoop fs -mkdir [-p] …
path为待创建的目录
-p可选参数,会沿着路径创建父目录,即及联创建
hadoop fs -mkdir /wxb
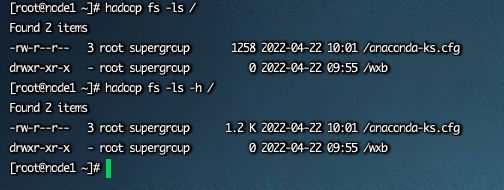
2、查看指定目录下内容
hadoop fs -ls [-h] [-R]
path指定目录路径
-h人性化显示文件size
-R递归查看指定目录及其子目录
3、上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] …
-f 覆盖目标文件(已经存在情况下)
-p 保留访问和修改时间,所有权和权限
localsrc 本地文件系统(即客户端所在机器,即当前在哪个机器上操作)
dst 目标文件系统
hadoop fs -put 1.txt / #简写
hadoop fs -put file:///root/2.txt hdfs://node1:8020/wxb #规范写法

4、查看HDFS文件内容
hadoop fs -cat
读取指定文件全部内容,显示在标准输出控制台
注意:对于大文件内容读取,慎重
hadoop fs -cat /wxb/2.txt
![]()
5、下载HDFS文件
hadoop fs -get [-f] [-p] …
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已经存在情况下)
-p 保留访问和修改时间,所有权和权限
hadoop fs -get /1.txt ./ #简写,把hafs文件系统上的1.txt下载到本地
hadoop fs -get hdfs://node1:8020/1.txt file:///root/2.txt #正规写发,下载到本地并改名为2.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NhkqIG2A-1650610419253)(img/34.png)]](http://img.e-com-net.com/image/info8/72b4796b8e7c4bb28275bc2904ad0c40.jpg)
6、拷贝HDFS文件
hadoop fs -cp [-f] …
-f 覆盖目标文件(已经存在的情况下)
hadoop fs -cp /1.txt /wxb

7、追加数据到HDFS文件中(应用场景:小文件合并)
hadoop fs -appendToFile …
将所有给定的本地文件的内容,追加到dst目标文件中
dst如果文件不存在,将创建该文件
如果为- ,则输入为从标准输入中读取。
hadoop fs -appendToFile 2.txt 3.txt /1.txt

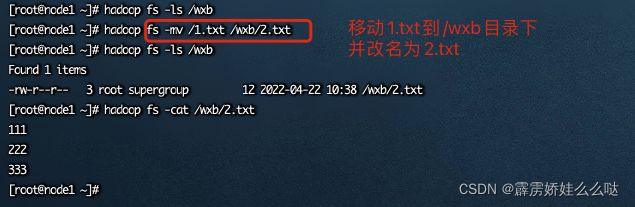
8、HDFS数据移动操作
hadoop fs -mv …
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
hadoop fs -mv /1.txt /wxb/2.txt
七、HDFS集群角色与职责
官方架构图:

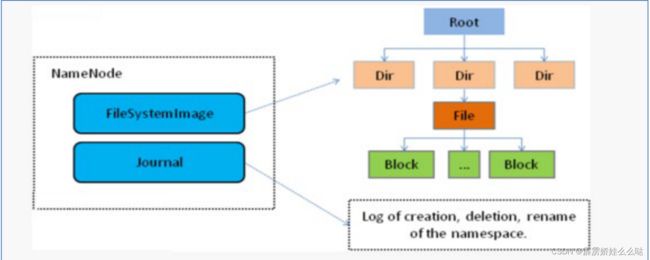
1、主角色:namenode
-
NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
-
NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
-
基于此,NameNode成为了访问HDFS的唯一入口。
-
NameNode内部通过内存和磁盘文件两种方式管理元数据。
-
其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log(Journal)编辑日志。
2、职责:主角色NameNode
-
NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
-
NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
-
NameNode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从DataNode重建。
-
NameNode是Hadoop集群中的单点故障。
-
NameNode所在机器通常会配置有大量内存(RAM)。
3、从角色:DataNode
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
- DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。

4、职责:从角色DataNode
-
DataNode负责最终数据块block的存储。是集群的从角色,也称为Slave。
-
DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
-
当某个DataNode关闭时,不会影响数据的可用性。 NameNode将安排由其他DataNode管理的块进行副本复制。
-
DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中。
5、主角色辅助角色:SecondaryNameNode
-
Secondary NameNode充当NameNode的辅助节点,但不能替代NameNode。
-
主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。

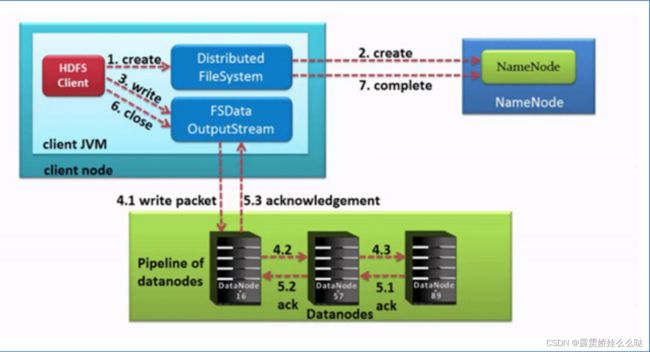
八、写数据
A、流程图

B、核心概念
1、Pipeline管道
-
Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
-
客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
-
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
-
在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带

2、ACK应答响应
-
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
-
在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。

3、默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定。
-
第一块副本:优先客户端本地,否则随机
-
第二块副本:不同于第一块副本的不同机架。
-
第三块副本:第二块副本相同机架不同机器。
C、整体流程
1、HDFS客户端创建对象实例DistributedFileSystem, 该对象中封装了与HDFS文件系统操作的相关方法。
2、调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通 过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。
3、客户端通过FSDataOutputStream输出流开始写入数据。
4、客户端写入数据时,将数据分成一个个数据包(packet 默认64k), 内部组件DataStreamer请求NameNode挑
选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二
个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
5、传输的反方向上,会通过ACK机制校验数据包传输是否成功;
6、客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
7、DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返 回。
最小复制是由参数dfs.namenode.replication.min指定,默认是1.
通过黑马视频学习总结,附黑马视频链接:
https://www.bilibili.com/video/BV1CU4y1N7Sh?p=26&spm_id_from=pageDriver