《python数据分析》心得体会
首先,本书围绕三个库进行讨论——numpy,pandas和matplotlib。Numpy是个模仿R的库,对python的独特的数组进行向量操作——将数组作为矩阵进行切片,换行,变换,转置,计算等一系列操作。Numpy的强大之处建立在python的天生优势——一切皆对象的基础之上,这也正是numpy的强大——一切皆数组(矩阵)。所以numpy是未来python做SVD,SVM等机械学习的基础——变量矩阵化。
第二大库——pandas,pandas是基于numpy的一个超级库,这个库不仅完成了numpy的所有基本功能,并且更进一步,矩阵数据框化(DataFrame)。相信熟悉R语言和SAS的朋友对这个概念并不陌生,因为我们几乎所有的数据都是经过数据框进行处理的。数据框的最大特点就是——index(索引)和columns(字段)。也就是pandas所有的操作都是围绕这两个东西进行的。包括增删改,补充,添加等等。也就是利用pandas你能干所有excel可以干的事情,真正意义上的数据管理和数据处理。
第三大库——matplotlib,python的标志性画图库,然而这个库并没有什么真正意义上的价值,笔者发现,通过python处理过的数据直接经过R作出图像反而更快,更有可视感。另外,真正画图的库使seaborn(因为可变化多)。
第二,是python做数据分析的环境和编辑器。我知道很多python开发的朋友喜欢用pycharm,但是不好意思,笔者实际操作和阅读,以及真实案例来看,anaconda才是真正意义上的python数据分析和挖掘的操作器(可以分段提交代码)。
书的环境是2.3版本,所以该书并没有对中文文本进行描述,因为逼人要清理大量的企业信息,这些数据都是中文,在一开始,我被这个问题很困惑,但是后来随着研究,我也找到了解决方法:
1. 数据挖掘,建议用3,不要用2!3对中文支持更好,并且更加聪明!
2. 用spyber,尽量不要用jupyter!因为spyber可以帮你保存你缓存的数据!!
3. 请阅读pandas的最新文档,该书成书时间在2013年,所以很多信息都过时了。
如果你喜欢用python2,那么你在操作数据库时候,所有输出数据都是元组格式,不过不要紧,你将格式改为数据框就可以避免,第二,请你保证你的编辑器的格式和数据库或者对象一致。
最后,是本书的问题。本书由于成书年代久,所以很多操作已经过时,笔者发现了以下几个小错误。
1. 对数据库的操作现在直接用pd.read_sql就可以,不需要再入库
2. oi类在pandas已经被转移成一个新库——pandas-dataread,请自行下载。
3. 本书没有对描述性统计分析进行跟深入叙述,你要学更多,请阅读scipy文档。
以上就是笔者对这本书的概述和心得,总的来说,此书的确值得一读。
实战案例
如何安装pandas库:1.电脑WIN+R,输入cmd,输入 pip install pandas回车就行了

安装
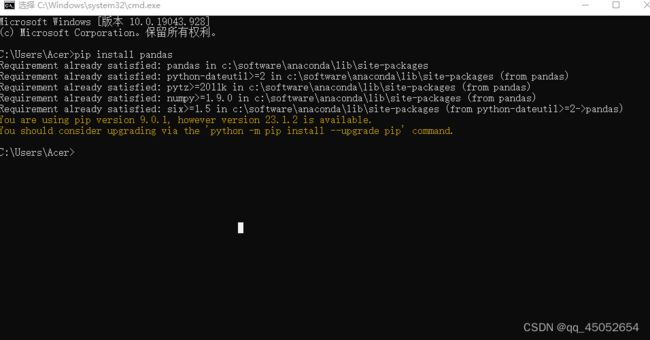
安装成功后,检查是否安装完成。输入
python -m pip list
安装成功后会有个pandas

检查安装是否成功 输入python,,进入python解释器,输入import pandas,看是否报错,如果不报错,说明安装成功。

知识干货
1.列表本身是有顺序的,而且非常非常非常重要的一点,列表中的第一个数的顺序是“0”,索引是从0开始的,切记!
2.修改列表时可以用,insert(位置,内容)来修改。
3.删除列表的内容时,用del可以直接锁定列表的位置来删除,用remove(内容),会将列表了第一次出现的内容删除,pop方法是直接删除末尾的内容,也可以看做是一种变相的提取,加上位置,比如pop(位置),就可以提取任何一个位置上的内容。
4.在写for循环时,要非常注意首行缩进,一般是缩进4个空格字符串,因为当嵌套的循环过多时,非常容易出错,系统无法识别出谁是谁的循环体。for我建议理解为遍历,就是指从头到尾看完整个数据。
5.8.range的左闭右开特性,举例子,range(1,5),以为是生成1到5折五个数字,但是根据python左闭右开的特性,实际是生成1到4这四个数字,切记,在切片,索引中非常重要。
6.del可删除key-value对。
7.16.导入模块后,如果调用了模块内的函数或者方法,一定要在前面制定模块名。
8.定义父类:
class Employee:
def _init_(self, name, age):#抽象员工共性(名字,年龄)self.name = name
self.age = agedef signON(self):
print(self.name+" sign on.")#抽象签到的动作def work(self);
print(self.name + " on work.") #抽象工作的动作
9.继承出子类:
class MEmployee(Employee):#继承父类的共性def _init_(self, name, age):
super)._init_(name, age)
def work(self): #重写子类的方法(抽象出从事管理岗位工作的动作)print(self.name + " on manager_work.")
10.继承出第二个子类:
class TEmployee(Employee):
def _init_(self, name, age, devLanguage):#继承父类的共性,增加语言的属性
super0._init_(name, age)g
self.devLanguage = devLanguage
def work(self): #重写子类的方法(抽象出从事技术岗位工作的动作)print(self.name + " on technology_work.")
def showLanguage(self): #增加子类的方法(抽象出会某种编程语言的动作)print("use " +self.devLanguage+" language.")
jupyter notebook目录

推荐书籍
《python数据分析》
操作案例
进入jupyter notebook页面
