Mysql之窗口函数学习
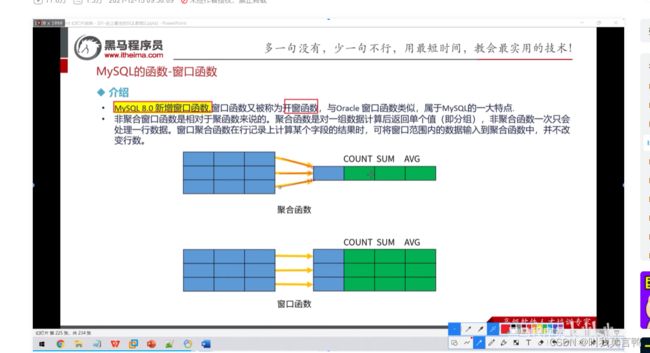
聚合是分组后,聚合到一行
而窗口函数,既可以聚合到一行,也可以不聚合


1.序号函数
分组排序并添加序号
row_number
rank
dense_rank
1.row_number()

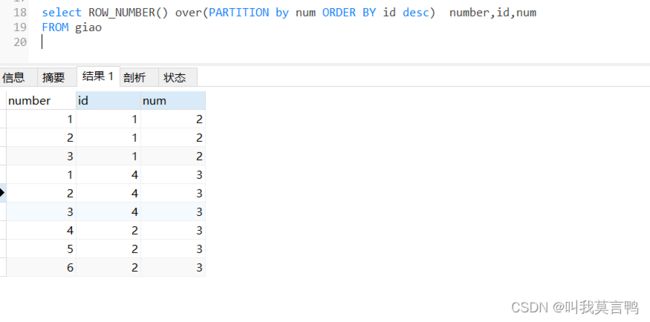
按照部门名称进行分组,然后按照薪资进行排序,但是,我们要注意
1.这里分组,但是并没有进行聚合
2.序号排序,是根据num的组进行排序的,也就是,组内排序
2.rank()
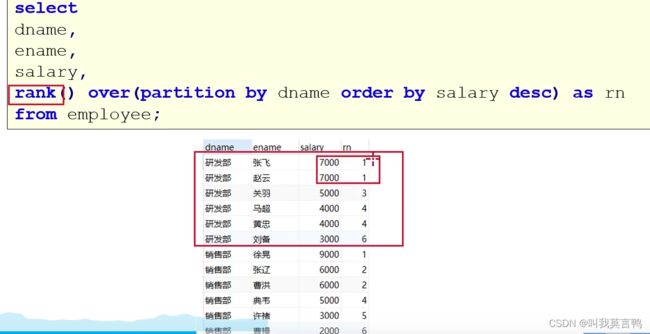
注意看 序号是 1 1 3 4 4 6 也就是说不连续,并且相同序号也相同
3.dense_rank()

序号 1 1 2 3
重复且连续
4.总结
row_rank 不重复
rank 重复但不连续
dense_rank 重复且连续
如果是要求名次 可以选择rank
如果是要求个数 使用row_rank
2.开窗聚合
1. sum
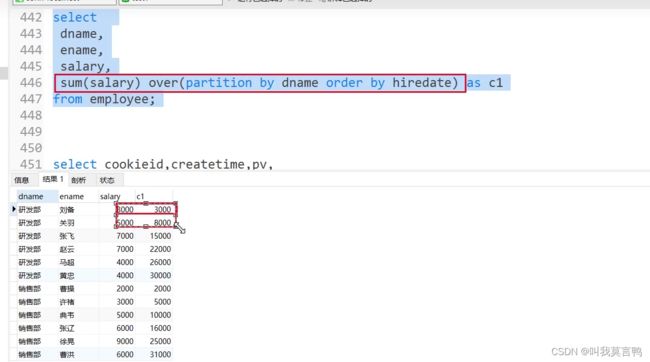
select id,num, rank_n,sum(num) over(partition by id ORDER by num DESC) as ss
from giao
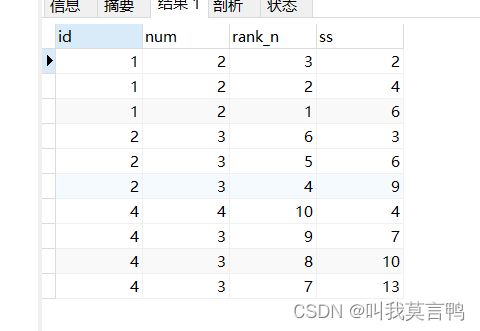
select id,num,rank_n,sum(num) over(partition by id ORDER by rank_n DESC) as ss
from giao
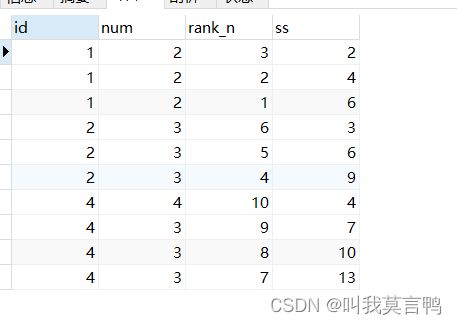
对比一下2个查询,由于排序方式不同,一个按照num排序,一个按照rank_n排序,
结果大不相同,当使用sum(num)同时按照num排序,会直接将相同num的sum相加,并且每个num对应的相应sum相同,可以分析出来.默认排序值相同的是一行,直接相加了,不同才会进行累加
1.rows between 行 preceding and 行
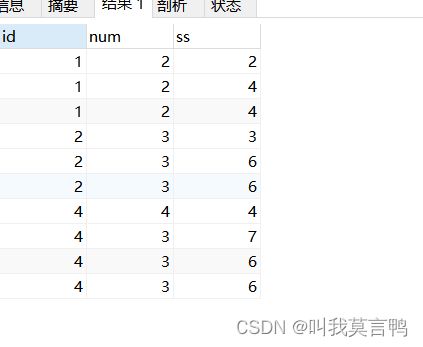
select id,num,sum(num) over(partition by id ORDER by rank_n DESC rows BETWEEN unbounded preceding and current row) as ss
from giao
select id,num,sum(num) over(partition by id ORDER by rank_n DESC rows BETWEEN 1 preceding and current row) as ss
from giao
注意这个行是分组后的行,
unbounded preceding默认就是这个,
n preceding 从向上几行到当前行
current row and unbounded following 从当前行加到最后
current row and 1 following 从当前行加到后一行
3.分布函数
1.cume_dist
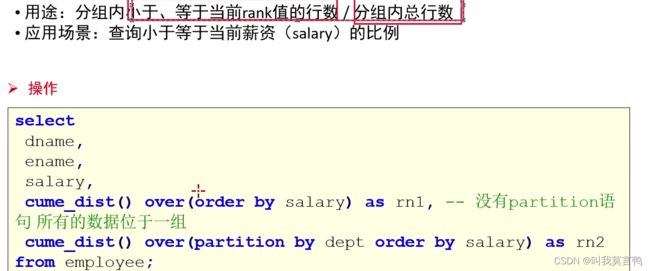
将上面的个数相加并转换为了小数
其实也就是,序号/组内总数
select id,num,CUME_DIST() over(PARTITION by id order by rank_n) as n1 from giao;

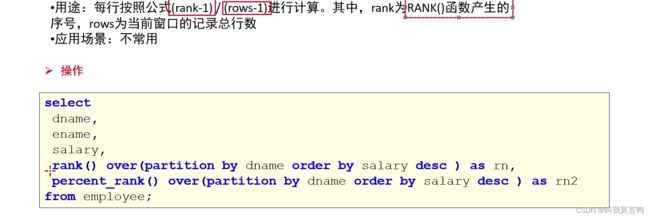
2.percent_rank 感觉没啥用


4.前后函数
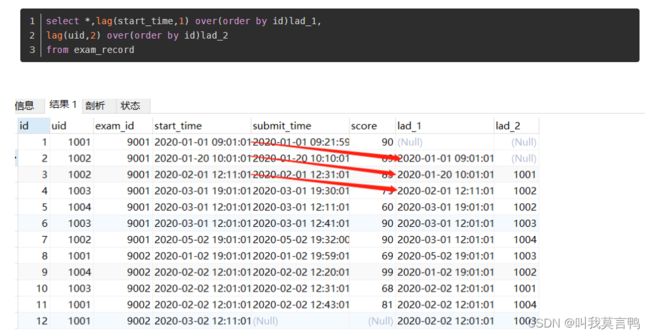
LAG LEAD
lag(expr,N,default)
expr:它可以是列或任何内置函数。
N:它是一个正值,它确定当前行之前的行数。如果在查询中将其省略,则其默认值为1
default:如果在当前行之前没有行N行的情况下,它是函数返回的默认值。如果缺少,则默认为NULL。
LAG N就是从这行开始到上面的偏移量
LEAD 就是向下的偏移量

5.头尾函数
FIRST_VALUE LAST_VALUE

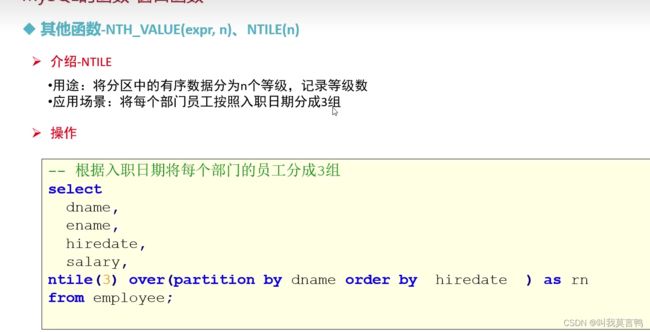
其他函数
NTH_VALUE(expr,n) NTILE(n)