Linux多虚拟机集群化配置详解(Zookeeper集群、Kafka集群、Hadoop集群、HBase集群、Spark集群、Flink集群、Zabbix、Grafana部署)
Linxu集群化环境前置
前面安装的软件,都是以单机模式运行的,学习大数据相关的软件部署,后续安装软件服务,大多数都是以集群化(多台服务器共同工作)模式运行的。所以,需要完成集群化环境的前置准备,包括创建多台虚拟机,配置主机名映射,SSH免密登录等等。
配置多台Linux虚拟机
我们可以使用VMware提供的克隆功能,将我们的虚拟机额外克隆出3台来使用。
- 首先,关机当前CentOS系统虚拟机(可以使用root用户执行
init 0来快速关机) - 新建文件夹
- 克隆
- 同样的操作克隆出:node2和node3
- 开启node1,修改主机名为node1,并修改固定ip为:192.168.88.111
# 修改主机名
hostnamectl set-hostname node1
# 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.88.131"
# 重启网卡
systemctl restart network
- 同样的操作启动node2和node3,
修改node2主机名为node2,设置ip为192.168.88.123
修改node2主机名为node3,设置ip为192.168.88.113 - 配置XShell,配置连接到node1、node2、node3的连接
为了简单起见,建议配置root用户登录
准备主机名映射
- 在Windows系统中修改hosts文件,填入如下内容:
修改/etc/hosts文件
192.168.88.111 node1
192.168.88.112 node2
192.168.88.113 node3 - 在3台Linux的/etc/hosts文件中,填入如下内容(3台都要添加)
192.168.88.111 node1
192.168.88.112 node2
192.168.88.113 node3
配置SSH免密登录
SSH服务是一种用于远程登录的安全认证协议。SSH服务支持:
- 通过账户+密码的认证方式来做用户认证
- 通过账户+秘钥文件的方式做用户认证
SSH可以让我们通过SSH命令,远程的登陆到其它的主机上,比如:
在node1执行:ssh root@node2,将以root用户登录node2服务器,输入密码即可成功登陆。
SSH免密配置
后续安装的集群化软件,多数需要远程登录以及远程执行命令,我们可以简单起见,配置三台Linux服务器之间的免密码互相SSH登陆
- 在每一台机器都执行:
ssh-keygen -t rsa -b 4096,一路回车到底即可 - 在每一台机器都执行:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3 - 执行完毕后,node1、node2、node3之间将 完成root用户之间的免密互通
关闭防火墙和SELinux
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,需要关闭防火墙和SELinux
systemctl stop firewalld
systemctl disable firewalld
Linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
vim /etc/sysconfig/selinux
#7 SELINUX=disabled 千万要注意disabled单词不要写错,不然无法启动系统
添加快照
为了避免后续出现问题,在完成上述设置后,为每一台虚拟机都制作快照,留待使用。
补充命令 - scp
后续的安装部署操作,会频繁的在多台服务器之间相互传输数据。为了更加方面的互相传输,需要命令:scp。即:ssh cp
scp [-r] 参数1 参数2
- -r选项用于复制文件夹使用,如果复制文件夹,必须使用-r
- 参数1:本机路径 或 远程目标路径
- 参数2:远程目标路径 或 本机路径
如:
scp -r /export/server/jdk root@node2:/export/server/
将本机上的jdk文件夹, 以root的身份复制到node2的/export/server/内
同SSH登陆一样,账户名可以省略(使用本机当前的同名账户登陆)
如:
scp -r node2:/export/server/jdk /export/server/
将远程node2的jdk文件夹,复制到本机的/export/server/内
# scp命令的高级用法
cd /export/server
scp -r jdk node2:`pwd`/ # 将本机当前路径的jdk文件夹,复制到node2服务器的同名路径下
scp -r jdk node2:$PWD # 将本机当前路径的jdk文件夹,复制到node2服务器的同名路径下
Zookeeper集群安装部署
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Zookeeper也被其它许多软件采用作为其分布式状态一致性的依赖,比如Kafka,又或者一些软件项目中,也经常能见到Zookeeper作为一致性协调服务存在。
Zookeeper不论是大数据领域亦或是其它服务器开发领域,涉及到分布式状态一致性的场景,总有它的身影存在。
安装
- node1上操作下载Zookeeper安装包,并解压。
# 下载
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
# 确保如下目录存在,不存在就创建
mkdir -p /export/server
# 解压
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /export/server
- node1上操作创建软链接
ln -s /export/server/apache-zookeeper-3.5.9-bin /export/server/zookeeper
- 【node1上操作】修改配置文件
vim /export/server/zookeeper/conf/zoo.cfg
tickTime=2000
# zookeeper数据存储目录
dataDir=/export/server/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
- node1上操作配置
myid
# 1. 创建Zookeeper的数据目录
mkdir /export/server/zookeeper/data
# 2. 创建文件,并填入1
vim /export/server/zookeeper/data/myid
# 在文件内填入1即可
- 在node2和node3上操作,创建文件夹
mkdir -p /export/server
- 【node1上操作】将Zookeeper 复制到node2和node3
cd /export/server
scp -r apache-zookeeper-3.5.9-bin node2:`pwd`/
scp -r apache-zookeeper-3.5.9-bin node3:`pwd`/
- 【在node2上操作】
# 1. 创建软链接
ln -s /export/server/apache-zookeeper-3.5.9-bin /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为2
- 【在node3上操作】
# 1. 创建软链接
ln -s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为3
- 【在node1、node2、node3上分别执行】启动Zookeeper
# 启动命令
/export/server/zookeeper/bin/zkServer.sh start # 启动Zookeeper
- 【在node1、node2、node3上分别执行】检查Zookeeper进程是否启动
jps
# 结果中找到有:QuorumPeerMain 进程即可
- 【node1上操作】验证Zookeeper
/export/server/zookeeper/zkCli.sh
# 进入到Zookeeper控制台中后,执行
ls /
# 如无报错即配置成功
Kafka集群安装部署
Kafka是一款分布式的、去中心化的、高吞吐低延迟、订阅模式的消息队列系统。RabbitMQ多用于后端系统,因其更加专注于消息的延迟和容错。
Kafka多用于大数据体系,因其更加专注于数据的吞吐能力。Kafka多数都是运行在分布式(集群化)模式下.
安装
- 确保已经安装并部署了JDK和Zookeeper服务。
- 【在node1操作】下载并上传Kafka的安装包
# 下载安装包
wget http://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz
- 【在node1操作】解压
mkdir -p /export/server # 此文件夹如果不存在需先创建
# 解压
tar -zxvf kafka_2.12-2.4.1.tgz -C /export/server/
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka
- 【在node1操作】修改Kafka目录内的config目录内的
server.properties文件
cd /export/server/kafka/config
# 指定broker的id
broker.id=1
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node1:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181
- 【在node1操作】将node1的kafka复制到node2和node3
cd /export/server
# 复制到node2同名文件夹
scp -r kafka_2.12-2.4.1 node2:`pwd`/
# 复制到node3同名文件夹
scp -r kafka_2.12-2.4.1 node3:$PWD
- 【在node2操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=2
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node2:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181
- 【在node3操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=3
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node3:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181
- 启动kafka
# 请先确保Zookeeper已经启动了
# 方式1:【前台启动】分别在node1、2、3上执行如下语句
/export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties
# 方式2:【后台启动】分别在node1、2、3上执行如下语句
nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties 2>&1 >> /export/server/kafka/kafka-server.log &
- 验证Kafka启动
# 在每一台服务器执行
jps
测试Kafka能否正常使用
- 创建测试主题
# 在node1执行,创建一个主题
/export/server/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic test
- 运行测试,请在FinalShell中打开2个node1的终端页面
# 打开一个终端页面,启动一个模拟的数据生产者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list node1:9092 --topic test
# 再打开一个新的终端页面,在启动一个模拟的数据消费者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic test --from-beginning
大数据集群(Hadoop生态)安装部署
Hadoop是一个由Apache开发的分布式系统基础架构。主要解决海量数据的存储和海量数据的分析计算问题。
Hadoop HDFS 提供分布式海量数据存储能力
Hadoop YARN 提供分布式集群资源管理能力
Hadoop MapReduce 提供分布式海量数据计算能力
Hadoop集群角色
- Hadoop HDFS的管理角色:Namenode进程(
仅需1个即可(管理者一个就够)) - Hadoop HDFS的工作角色:Datanode进程(
需要多个(工人,越多越好,一个机器启动一个)) - Hadoop YARN的管理角色:ResourceManager进程(
仅需1个即可(管理者一个就够)) - Hadoop YARN的工作角色:NodeManager进程(
需要多个(工人,越多越好,一个机器启动一个)) - Hadoop 历史记录服务器角色:HistoryServer进程(
仅需1个即可(功能进程无需太多1个足够)) - Hadoop 代理服务器角色:WebProxyServer进程(
仅需1个即可(功能进程无需太多1个足够)) - Zookeeper的进程:QuorumPeerMain进程(
仅需1个即可(Zookeeper的工作者,越多越好))
角色和节点分配
角色分配如下:
- node1:Namenode、Datanode、ResourceManager、NodeManager、HistoryServer、WebProxyServer、QuorumPeerMain
- node2:Datanode、NodeManager、QuorumPeerMain
- node3:Datanode、NodeManager、QuorumPeerMain
前置
JDK、SSH免密、关闭防火墙、配置主机名映射等前置操作
安装
node1承载了太多的压力。同时node2和node3也同时运行了不少程序,为了确保集群的稳定,需要对虚拟机进行内存设置。
node1设置4GB或以上内存,node2和node3设置2GB或以上内存
- 下载Hadoop安装包、解压、配置软链接
# 1. 下载
wget http://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
# 2. 解压
# 请确保目录/export/server存在
tar -zxvf hadoop-3.3.0.tar.gz -C /export/server/
# 3. 构建软链接
ln -s /export/server/hadoop-3.3.0 /export/server/hadoop
- 修改配置文件:
hadoop-env.shHadoop的配置文件要修改的地方很多,请细心
cd 进入到/export/server/hadoop/etc/hadoop,文件夹中,配置文件都在这里
修改hadoop-env.sh文件
此文件是配置一些Hadoop用到的环境变量
这些是临时变量,在Hadoop运行时有用
如果要永久生效,需要写到/etc/profile中
# 在文件开头加入:
# 配置Java安装路径
export JAVA_HOME=/export/server/jdk
# 配置Hadoop安装路径
export HADOOP_HOME=/export/server/hadoop
# Hadoop hdfs配置文件路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN配置文件路径
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN 日志文件夹
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# Hadoop hdfs 日志文件夹
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
# Hadoop的使用启动用户配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
- 修改配置文件:
core-site.xml清空文件,填入如下内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node1:8020value>
<description>description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
<description>description>
property>
configuration>
- 配置:
hdfs-site.xml文件
<configuration>
<property>
<name>dfs.datanode.data.dir.permname>
<value>700value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/data/nnvalue>
<description>Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently.description>
property>
<property>
<name>dfs.namenode.hostsname>
<value>node1,node2,node3value>
<description>List of permitted DataNodes.description>
property>
<property>
<name>dfs.blocksizename>
<value>268435456value>
<description>description>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
<description>description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/data/dnvalue>
property>
configuration>
- 配置:
mapred-env.sh文件
# 在文件的开头加入如下环境变量设置
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
- 配置:
mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node1:10020value>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node1:19888value>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dirname>
<value>/data/mr-history/tmpvalue>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.done-dirname>
<value>/data/mr-history/donevalue>
<description>description>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
configuration>
- 配置:
yarn-env.sh文件
# 在文件的开头加入如下环境变量设置
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
- 配置:
yarn-site.xml文件
<configuration>
<property>
<name>yarn.log.server.urlname>
<value>http://node1:19888/jobhistory/logsvalue>
<description>description>
property>
<property>
<name>yarn.web-proxy.addressname>
<value>node1:8089value>
<description>proxy server hostname and portdescription>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
<description>Configuration to enable or disable log aggregationdescription>
property>
<property>
<name>yarn.nodemanager.remote-app-log-dirname>
<value>/tmp/logsvalue>
<description>Configuration to enable or disable log aggregationdescription>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node1value>
<description>description>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedulervalue>
<description>description>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/data/nm-localvalue>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.description>
property>
<property>
<name>yarn.nodemanager.log-dirsname>
<value>/data/nm-logvalue>
<description>Comma-separated list of paths on the local filesystem where logs are written.description>
property>
<property>
<name>yarn.nodemanager.log.retain-secondsname>
<value>10800value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.description>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>Shuffle service that needs to be set for Map Reduce applications.description>
property>
configuration>
- 修改workers文件
node1
node2
node3
- 分发hadoop到其它机器
# 在node1执行
cd /export/server
scp -r hadoop-3.3.0 node2:`pwd`/
scp -r hadoop-3.3.0 node2:`pwd`/
- 在node2、node3执行
# 创建软链接
ln -s /export/server/hadoop-3.3.0 /export/server/hadoop
- 创建所需目录
- 在node1执行:
mkdir -p /data/nn
mkdir -p /data/dn
mkdir -p /data/nm-log
mkdir -p /data/nm-local
- 在node2执行:
mkdir -p /data/dn
mkdir -p /data/nm-log
mkdir -p /data/nm-local
- 在node3执行:
mkdir -p /data/dn
mkdir -p /data/nm-log
mkdir -p /data/nm-local
- 配置环境变量
在node1、node2、node3修改/etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile生效
14. 格式化NameNode,在node1执行
hadoop namenode -format
hadoop这个命令来自于:$HADOOP_HOME/bin中的程序
由于配置了环境变量PATH,所以可以在任意位置执行hadoop命令哦
- 启动hadoop的hdfs集群,在node1执行即可
start-dfs.sh
# 如需停止可以执行
stop-dfs.sh
start-dfs.sh这个命令来自于:$HADOOP_HOME/sbin中的程序
由于配置了环境变量PATH,所以可以在任意位置执行start-dfs.sh命令哦
- 启动hadoop的yarn集群,在node1执行即可
start-yarn.sh
# 如需停止可以执行
stop-yarn.sh
- 启动历史服务器
mapred --daemon start historyserver
# 如需停止将start更换为stop
- 启动web代理服务器
yarn-daemon.sh start proxyserver
# 如需停止将start更换为stop
验证Hadoop集群运行情况
- 在node1、node2、node3上通过jps验证进程是否都启动成功
- 验证HDFS,浏览器打开:http://node1:9870
创建文件test.txt,随意填入内容,并执行:
hadoop fs -put test.txt /test.txt
hadoop fs -cat /test.txt
- 验证YARN,浏览器打开:http://node1:8088
执行:
# 创建文件words.txt,填入如下内容
itheima itcast hadoop
itheima hadoop hadoop
itheima itcast
# 将文件上传到HDFS中
hadoop fs -put words.txt /words.txt
# 执行如下命令验证YARN是否正常
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount -Dmapred.job.queue.name=root.root /words.txt /output
大数据NoSQL数据库HBase集群部署
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。Redis设计为少量数据,超快检索,HBase设计为海量数据,快速检索。HBase在大数据领域应用十分广泛。
安装
- HBase依赖Zookeeper、JDK、Hadoop(HDFS)
- 【node1执行】下载HBase安装包
# 下载
wget http://archive.apache.org/dist/hbase/2.1.0/hbase-2.1.0-bin.tar.gz
# 解压
tar -zxvf hbase-2.1.0-bin.tar.gz -C /export/server
# 配置软链接
ln -s /export/server/hbase-2.1.0 /export/server/hbase
- 【node1执行】,修改配置文件,修改
conf/hbase-env.sh文件
# 在28行配置JAVA_HOME
export JAVA_HOME=/export/server/jdk
# 在126行配置:
# 意思表示,不使用HBase自带的Zookeeper,而是用独立Zookeeper
export HBASE_MANAGES_ZK=false
# 在任意行,比如26行,添加如下内容:
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
- 【node1执行】,修改配置文件,修改
conf/hbase-site.xml文件
# 将文件的全部内容替换成如下内容:
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:8020/hbase</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/server/apache-zookeeper-3.6.0-bin/data</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
- 【node1执行】,修改配置文件,修改
conf/regionservers文件
node1
node2
node3
- 【node1执行】,分发hbase到其它机器
scp -r /export/server/hbase-2.1.0 node2:/export/server/
scp -r /export/server/hbase-2.1.0 node3:/export/server/
- 【node2、node3执行】,配置软链接
ln -s /export/server/hbase-2.1.0 /export/server/hbase
- 【node1、node2、node3执行】,配置环境变量
# 配置在/etc/profile内,追加如下两行
export HBASE_HOME=/export/server/hbase
export PATH=$HBASE_HOME/bin:$PATH
source /etc/profile
- 【node1执行】启动HBase
请确保:Hadoop HDFS、Zookeeper是已经启动了的
start-hbase.sh
stop-hbase.sh
由于我们配置了环境变量export PATH= P A T H : PATH: PATH:HBASE_HOME/bin
start-hbase.sh即在$HBASE_HOME/bin内,所以可以无论当前目录在哪,均可直接执行
- 验证HBase
浏览器打开:http://node1:16010,即可看到HBase的WEB UI页面 - 简单测试使用HBase【node1执行】
hbase shell
# 创建表
create 'test', 'cf'
# 插入数据
put 'test', 'rk001', 'cf:info', 'itheima'
# 查询数据
get 'test', 'rk001'
# 扫描表数据
scan 'test'
分布式内存计算Spark环境部署
Spark是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。支持离线计算和实时计算。在大数据领域广泛应用,是目前世界上使用最多的大数据分布式计算引擎。
前置
基于前面构建的Hadoop集群,部署Spark Standalone集群。
安装
- 【node1执行】下载并解压
wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
# 解压
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/
# 软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark
- 【node1执行】修改配置文件名称
# 改名
cd /export/server/spark/conf
mv spark-env.sh.template spark-env.sh
mv slaves.template slaves
- 【node1执行】修改配置文件,
spark-env.sh
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
- 【node1执行】修改配置文件,
slaves
node1
node2
node3
- 【node1执行】分发
scp -r spark-2.4.5-bin-hadoop2.7 node2:$PWD
scp -r spark-2.4.5-bin-hadoop2.7 node3:$PWD
- 【node2、node3执行】设置软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark
- 【node1执行】启动Spark集群
/export/server/spark/sbin/start-all.sh
/export/server/spark/sbin/stop-all.sh
- 打开Spark监控页面,浏览器打开:http://node1:8081
- 【node1执行】提交测试任务
/export/server/spark/bin/spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi /export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar
分布式内存计算Flink环境部署
Flink同Spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。支持离线计算和实时计算。Spark更加偏向于离线计算而Flink更加偏向于实时计算。
前置
基于前面构建的Hadoop集群,部署Flink Standalone集群
安装
- 【node1操作】下载安装包
wget https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz
# 解压
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /export/server/
# 软链接
ln -s /export/server/flink-1.10.0 /export/server/flink
- 【node1操作】修改配置文件,
conf/flink-conf.yaml
# jobManager 的IP地址
jobmanager.rpc.address: node1
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 2
#是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 程序默认并行计算的个数
parallelism.default: 1
#JobManager的Web界面的端口(默认:8081)
jobmanager.web.port: 8081
- 【node1操作】,修改配置文件,
conf/slaves
node1
node2
node3
- 【node1操作】分发Flink安装包到其它机器
cd /export/server
scp -r flink-1.10.0 node2:`pwd`/
scp -r flink-1.10.0 node3:`pwd`/
- 【node2、node3操作】
# 配置软链接
ln -s /export/server/flink-1.10.0 /export/server/flink
- 【node1操作】,启动Flink
/export/server/flink/bin/start-cluster.sh
- 验证Flink启动
# 浏览器打开
http://node1:8081
- 提交测试任务【node1执行】
/export/server/flink/bin/flink run /export/server/flink-1.10.0/examples/batch/WordCount.jar
运维监控Zabbix部署
Zabbix 由 Alexei Vladishev 创建,目前由其成立的公司—— Zabbix SIA 积极的持续开发更新维护, 并为用户提供技术支持服务。
Zabbix 是一个企业级分布式开源监控解决方案。
Zabbix 软件能够监控众多网络参数和服务器的健康度、完整性。Zabbix 使用灵活的告警机制,允许用户为几乎任何事件配置基于邮件的告警。这样用户可以快速响应服务器问题。Zabbix 基于存储的数据提供出色的报表和数据可视化功能。这些功能使得 Zabbix 成为容量规划的理想选择。
前置
准备Linux 服务器(虚拟机)、安装Mysql、安装zabbix( 包含 server agent web)
配置 mysql, 为zabbix创建表结构
配置zabbix server
安装Zabbix Server 和 Zabbix Agent
初始安装,我们先安装ZabbixServer以及在Server本机安装Agent。
打开官网下载页面:https://www.zabbix.com/download?zabbix=4.0&os_distribution=centos&os_version=7&db=mysql
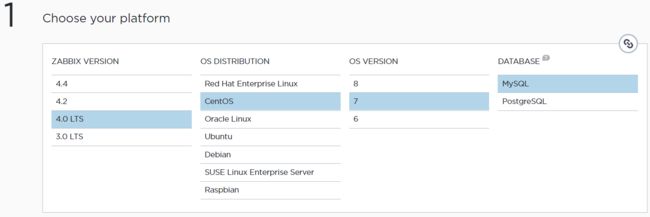
选择对应的版本,然后再下面官网给出了具体的安装命令,使用rpm和yum来进行安装。
以下内容来自官方页面
a. 安装Zabbix yum库
rpm -Uvh https://repo.zabbix.com/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-2.el7.noarch.rpm
yum clean all
b. 安装Zabbix Server、前端、Agent
yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-agent
# 如果只需要安装Agent的话
yum -y install zabbix-agent
c. 初始化Mysql数据库
在Mysql中操作
# 登录Mysql 数据库
mysql -uroot -pYourPassword
mysql> create database zabbix character set utf8 collate utf8_bin;
mysql> grant all privileges on zabbix.* to zabbix@localhost identified by 'zabbix';
# 或者: grant all privileges on zabbix.* to zabbix@'%' identified by 'zabbix';
mysql> quit;
测试在Zabbix Server服务器上能否远程登录Mysql,如果可以登录继续向下走。
Import initial schema and data. You will be prompted to enter your newly created password.
# zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -p zabbix
d. 为Zabbix Server配置数据库
Edit file /etc/zabbix/zabbix_server.conf
DBPassword=password
DBHost=mysql-host-ip-or-hostname
e. 配置Zabbix的PHP前端
Edit file /etc/httpd/conf.d/zabbix.conf, uncomment and set the right timezone for you.# php_value date.timezone Asia/Shanghai
Start Zabbix server and agent processes and make it start at system boot:
systemctl restart zabbix-server zabbix-agent httpd # 启动、重启
systemctl enable zabbix-server zabbix-agent httpd # 开机自启
配置zabbix 前端(WEB UI)
打开:http://192.168.88.131/zabbix
即可进入Zabbix页面,在首次打开的时候,会进入设置页面。
点击下一步,会检查相应的设置是否都正常
如果一切正常,点击下一步。
配置DB连接
按具体情况填写即可
配置Server细节
具体配置即可,Name表示这个Zabbix服务的名字,这里起名叫ITHEIMA-TEST
安装前总结预览
检查确认没有问题就下一
配置完成
初始管理员账户Admin密码zabbix
输入账户密码后,就能进入zabbix页面了。
运维监控Grafana部署
Grafana支持两种部署形式
- 自行部署, 可以部署在操作系统之上. 自行提供服务器, 域名等.
Grafana官方托管. 无需安装, 在线注册即可得到一个专属于自己的Grafana, 但是要花钱的. 是一种SaaS服务
安装
# 创建一个文件
vim /etc/yum.repos.d/grafana.repo
# 将下面的内容复制进去
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
# 最后安装
yum install grafana
配置说明
grafana-server具有许多配置选项,这些选项可以在.ini配置文件中指定,也可以使用环境变量指定。
Note.
Grafananeeds to be restarted for any configuration changes to take effect.
配置文件注释
;符号在.ini文件中全局表示注释 ()
配置文件路径
如果是自己解压安装, 或者自行编译的方式安装, 配置文件在:
- 默认:
$WORKING_DIR/conf/defaults.ini - 自定义:
$WORKING_DIR/conf/custom.ini - 自定义配置文件路径可以被参数
--config覆盖
对于
YUMRPM安装的方式, 配置文件在:/etc/grafana/grafana.ini
使用环境变量
可以使用以下语法使用环境变量来覆盖配置文件中的所有选项:
GF_<SectionName>_<KeyName>
其中SectionName是方括号内的文本。一切都应为大写,.应替换为_ 例如,给定以下配置设置:
# default section
instance_name = ${HOSTNAME}
[security]
admin_user = admin
[auth.google]
client_secret = 0ldS3cretKey
Then you can override them using:
export GF_DEFAULT_INSTANCE_NAME=my-instance
export GF_SECURITY_ADMIN_USER=true # GF_ 固定 SECURITY 是SectionName ADMIN_USER 是配置的key 转大写 . 转 _
export GF_AUTH_GOOGLE_CLIENT_SECRET=newS3cretKey
开始配置
Grafana支持使用Sqlite3 Postgresql Mysql这三种数据库作为其元数据的存储.
我们使用Mysql. 和zabbix的元数据mysql共用一个实例,只需要配置如下内容即可:
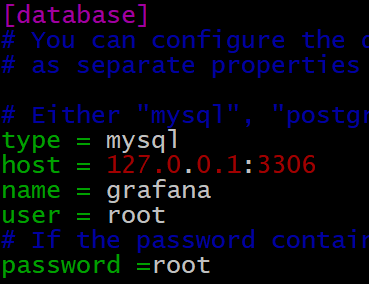
并登陆mysql, 执行:
create database grafana CHARACTER SET utf8 COLLATE utf8_general_ci;
创建Grafana使用的数据库作为元数据存储.
启动
systemctl daemon-reload
systemctl start grafana-server
systemctl enable grafana-server
浏览器打开:http://node1:3000
默认账户密码:admin/admin