【AI 充电】KServe + Fluid 加速大模型推理
作者:黄驰琳、露营、车漾
背景
KServe 是 Kubernetes 上的标准模型推理平台,专为高度可扩展的场景而构建,支持现代 Serverless 推理工作负载,用于在任意框架上提供机器学习(ML)模型服务。它提供高性能、高度抽象的接口,以支持常见的 ML 框架(如Tensorflow、XGBoost、Scikit-Learn、PyTorch 和 ONNX)来解决生产模型服务场景。此外,KServe 封装了自动缩放、网络、健康检查和服务配置的复杂性,支持GPU 自动缩放、归零缩放和金丝雀发布等。为生产级别机器学习服务提供了一个简单、可插拔且完整的支持,包括预测、预处理、后处理和可解释性的能力。
人工智能生成内容(AIGC)和大型语言模型(LLM)在近一年内方兴未艾,进一步提升了了大众对 AI 的期望值。为了能够产生新的业务价值,越来越多的公司开始使用 KServe 来部署它们,主要原因是:
- 分布式处理: 大型语言模型(LLMs)的参数量庞大,需要极高的计算资源,而KServe平台提供了分布式处理能力,可以将计算任务分布到多个节点上进行并行计算,从而加速计算过程。
- Serverless: KServe 平台是无服务器算法的典型代表,可以在需求变化时自动进行扩缩容。这种特性使得部署大型语言模型变得更加灵活和高效,并能够显著提升模型的响应速度。
- 统一化部署: KServe 平台为用户提供了一种更加简便和统一的方式来部署和管理大型语言模型。这样一来,用户无需自行设置和配置算法环境,即可开始进行模型的训练和预测工作。
- 监控和管理: KServe 平台具备完备的监控和管理功能,用户可以清晰地了解到模型的运行状况和性能表现,并能够及时调整参数和处理问题,从而保证模型的高效和可靠。
但是在生产实践中,KServe 对于大型语言模型(LLMs)的支持依然有不小的挑战。主要问题在于:
- 模型启动时间长: 大型语言模型(LLMs)的参数规模相当巨大,体积通常很大甚至达到几百 GB,导致拉取到 GPU 显存的耗时巨大,启动时间非常慢。此外,KServe 通过存储初始化器(Storage Initializer)从远程存储中拉取模型到本地,这也需要很长时间,对根据流量进行 KServe 无服务器自动扩缩容功能产生不利影响。
- 容器镜像拉取时间长: 大型语言模型(LLMs)的运行时环境依赖 GPU 基础环境,相应的容器镜像通常很大,这会导致拉取时间长,拖慢应用启动速度。
- 模型更新效率低、复杂度高: 大型语言模型(LLMs)由多个文件组成,模型更新时只需部分更新或添加部分文件,但 KServe 需要重启容器和重新拉取模型,无法支持模型的热升级,这带来效率低和复杂度高的问题。
KServe 在 Kubecon 2023 就提到了 Fluid 有可能帮助解决其在弹性上遇到的问题。Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI 应用等。参见数据加速 Fluid 概述 [ 1] 。
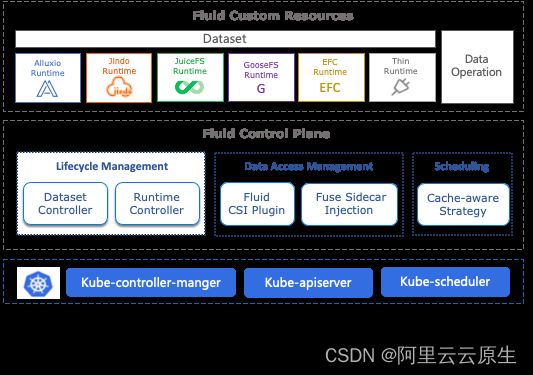
阿里云容器服务团队和 KServe,Fluid 社区的小伙伴一起探索在阿里云 Serverless Kubernetes 平台上简单,方便,高性能,生产级别的支持大型语言模型(LLMs):
- 服务托管,产品支持: 阿里云服务网格(简称 ASM)对于 KServe 提供了原生支持,要知道 KServe 依赖于底层Istio的稳定性对于 KServe 来说非常重要,使用托管的服务网格后,高可用、免运维、内建安全最佳实践;用户可以更专注于大语言模型相关的工作。除此之外 KServe 和 Fluid 也可以一键安装。
- 协同社区优化使用模式: 在 KServe 最新版支持除了存储初始化器(Storage Initializer)外,也支持标准的 PVC 模式,通过避免从远程存储中拉取模型到本地,减少存储不足的风险和提升启动速度;也可以支持模型热升级。
- 通过弹性分布式缓存加速模型加载流程: Fluid 与 KServe 相结合,通过数据预热到分布式缓存,缩短 Pod 启动时间 80% 同时支持模型热升级,无容器重启。
- 以上能力完全通过运行阿里云无服务器 Kubernetes 容器服务(ASK)上,在业务没有运行按需弹性、按秒计费,同时基于请求量的 GPU 无服务器自动扩展,缩放至零。

一切就绪,我们一起开启阿里云 Kubernetes(ACK) 中 KServe 推理大模型之旅:
实践步骤
前提条件
- 已创建 ACK 集群,集群的 Kubernetes 版本 ≥1.18,具体操作,请参见创建 Kubernetes 托管版集群 [ 2] 。
本演示使用的 ACK 集群包含 3 个 ecs.g7.xlarge 规格的 ecs 和 1 个 ecs.g7.2xlarge 规格的 ecs。您可以在创建时选择添加 3 个 ecs.g7.xlarge 规格的 ecs,待集群创建完成后新建一个节点池以增加一个 1 个 ecs.g7.2xlarge 规格的 ecs,关于创建节点池的具体操作请参考创建节点池 [ 3] 。
- 已创建 v1.17 及以上版本的 ASM 实例,并已将上述 ACK 集群添加到该实例中。具体操作,请参见创建 ASM 实例 [ 4] 和添加集群到 ASM 实例 [ 5] 。
您可以使用上述配置来创建阿里云服务网格 ASM 实例,其中:
- 实例规格需要选择企业版(以启用数据面集群 KubeAPI 访问 Istio 资源能力)
- Istio 版本需要选择 v1.17 及以上
- 网格的地域、专有网络需要与创建的 Kubernetes 集群保持一致,以保证网络畅通
- 可以视需求选择是否勾选 “使用 EIP 暴露 API Server”,开启后将为内网 SLB 实例创建并绑定一个 EIP,您将可以从公网访问 ASM 实例的 API Server,并操作 Istio CR
- 可观测性及网格审计部分依赖日志服务和阿里云 Prometheus 监控服务,若依赖服务尚未开通,在创建时您可以不勾选
- 【重要】必须勾选启用数据面集群 KubeAPI 访问 Istio 资源。
- 集群本地域名需要与您的 Kubernetes 集群的本地域名保持一致。
- ASM 实例已经开启通过数据面集群 KubeAPI 访问 Istio 资源能力。具体操作,参考:通过数据面集群 KubeAPI 访问 Istio 资源 [ 6] 。
- 已为集群添加入口网关。本实例使用 ASM 入口网关作为集群网关,ASM 入口网关名称为默认的 ingressgateway,开放端口 80 和 443。具体操作,请参见创建入口网关服务 [ 7] 。
- 已在 ACK 或 ASK 集群中部署 Knative Serving 组件,并开启 Knative on ASM 功能。具体操作,参考:使用 Knative on ASM 部署 Serveless 应用 [ 8] 中的前提及步骤一。
步骤一:开启 KServe on ASM 功能
- 登录 ASM 控制台 [ 9] ,在左侧导航栏,选择服务网格 > 网格管理。
- 在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择生态集成中心 > KServe on ASM。
- 在 KServe on ASM 页面,单击启用 KServe on ASM。
说明:KServe on ASM 功能依赖 cert-manager 组件的部署与使用。cert-manager 是一个证书生命周期管理系统,支持证书的申请、部署等功能。如果您没有在集群中安装 cert-manager,您需要在 KServe on ASM 页面开启 在集群中自动安装 CertManager 组件,以自动为您安装 cert-manager;否则您需要关闭此项,再单击启用 KServe on ASM。
步骤二:安装 ACK-Fluid 并开启 AI 模型缓存加速
- 为您的 ACK 或 ASK 集群部署 ack-fluid 组件,并保证 ack-fluid 组件的版本在 0.9.10 及以上。
说明:如果您的数据面集群为 ACK 集群,您需要在 ACK 集群中安装云原生AI套件并部署 ack-fluid 组件。参考:加速在线应用数据访问 [ 10] 。
如果您的数据面集群为 ASK 集群,您需要在 ASK 集群中部署 ack-fluid 组件。参考:加速 Job 应用数据访问 [1****1] 。
- 准备AI模型并上传至 OSS Bucket。
a. 准备训练好的 AI 模型保存数据。本文以基于 pytorch 的开源 transformer 大语言模型 bloom 为例,可以在 hugging face 社区中获取模型数据:https://huggingface.co/bigscience/bloom-560m/tree/main
b. 将下载的模型数据文件上传至 OSS Bucket,并记录模型数据文件的保存位置。模型数据文件的保存位置格式为 oss://{bucket}/{path}。例如,如果您创建了名为 fluid-demo 的 bucket,并在 bucket 中的 models/bloom 目录中上传了所有的模型数据文件,则模型数据文件的保存位置为 oss://fluid-demo/models/bloom
说明:您可以通过 OSS 提供的客户端工具 ossutil 上传数据。具体操作,请参见安装 ossutil [ 12] 。
- 创建部署 Fluid 及 AI 服务的命名空间,并配置 OSS 访问权限。
a. 使用 kubectl 连接到数据面 ACK/ASK 集群。具体操作,参考:通过 kubectl 连接 Kubernetes 集群 [ 13] 。
b. 使用 kubectl 创建命名空间,以部署 Fluid 及 KServe AI 服务。本文以 kserve-fluid-demo 命名空间为例。
kubectl create ns kserve-fluid-demo
c. 使用 kubectl 为命名空间添加 eci 标签,以将命名空间中的 Pod 调度到虚拟节点上。
kubectl label namespace kserve-fluid-demo alibabacloud.com/eci=true
d. 使用以下内容,创建 oss-secret.yaml 文件。其中 fs.oss.accessKeyId 和 fs.oss.accessKeySecret 分别代表可以访问 OSS 的 accessKeyId 和 accessKeySecret。
apiVersion: v1
kind: Secret
metadata:
name: access-key
stringData:
fs.oss.accessKeyId: xxx #替换为可以访问OSS的阿里云accessKeyId
fs.oss.accessKeySecret: xxx #替换为可以访问OSSd的阿里云accessKeySecret
e. 执行以下命令,部署 Secret,配置 OSS 访问秘钥。
kubectl apply -f oss-secret.yaml -n kserve-fluid-demo
- 在 Fluid 中声明待访问的 AI 模型数据。您需要提交一个 Dataset CR 和一个 Runtime CR。其中,Dataset CR 描述数据在外部存储系统中的 URL 位置,JindoRuntime CR:描述缓存系统及其具体配置。
a. 使用以下内容,保存为 oss-jindo.yaml 文件。
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: oss-data
spec:
mounts:
- mountPoint: "oss://{bucket}/{path}" # 需要替换为模型数据文件的保存位置
name: bloom-560m
path: /bloom-560m
options:
fs.oss.endpoint: "{endpoint}" # 需要替换为实际的OSS endpoint地址
encryptOptions:
- name: fs.oss.accessKeyId
valueFrom:
secretKeyRef:
name: access-key
key: fs.oss.accessKeyId
- name: fs.oss.accessKeySecret
valueFrom:
secretKeyRef:
name: access-key
key: fs.oss.accessKeySecret
accessModes:
- ReadOnlyMany
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: oss-data
spec:
replicas: 2
tieredstore:
levels:
- mediumtype: SSD
volumeType: emptyDir
path: /mnt/ssd0/cache
quota: 50Gi
high: "0.95"
low: "0.7"
fuse:
args:
- -ometrics_port=-1
master:
nodeSelector:
node.kubernetes.io/instance-type: ecs.g7.xlarge
worker:
nodeSelector:
node.kubernetes.io/instance-type: ecs.g7.xlarge
说明:您需要将 Dataset CR 中的 oss://{bucket}/{path} 替换为上文中记录的模型数据文件的保存位置。将 Dataset CR 中的 {endpoint}替换为 OSS 的访问域名。如何获取不同地域 OSS 的访问域名,参考:访问域名和数据中心 [ 14] 。
a. 执行以下命令,部署 Dataset 和 JindoRuntime CR。
kubectl create -f oss-jindo.yaml -n kserve-fluid-demo
b. 执行以下命令,查看 Dataset 和 JindoRuntime 的部署情况。
kubectl get jindoruntime,dataset -n kserve-fluid-demo
预期输出:
NAME MASTER PHASE WORKER PHASE FUSE PHASE AGE
jindoruntime.data.fluid.io/oss-data Ready Ready Ready 3m
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
dataset.data.fluid.io/oss-data 3.14GiB 0.00B 100.00GiB 0.0% Bound 3m
由预期输出中得到,Dataset 的 PHASE为Bound,JindoRuntime 的 FUSE PHASE 为 Ready,代表 Dataset 和 JindoRuntime 都部署成功。
- 在 Fluid 中进行数据预热,提升数据访问性能。
a. 使用以下内容,保存为 oss-dataload.yaml。
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: oss-dataload
spec:
dataset:
name: oss-data
namespace: kserve-fluid-demo
target:
- path: /bloom-560m
replicas: 2
b. 执行以下命令,部署 Dataload 以预热数据。
kubectl create -f oss-dataload.yaml -n kserve-fluid-demo
c. 执行以下命令,查看数据预热的进度。
kubectl get dataload -n kserve-fluid-demo
预期输出:
NAME DATASET PHASE AGE DURATIONoss-dataload
oss-data Complete 1m 45s
由预期输出得到,数据预热耗时约 45s。需要等待一段时间才能使得数据预热完成。
步骤三:部署 AI 模型推理服务
- 将以下内容保存为 oss-fluid-isvc.yaml
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "fluid-bloom"
spec:
predictor:
timeout: 600
minReplicas: 0
nodeSelector:
node.kubernetes.io/instance-type: ecs.g7.2xlarge
containers:
- name: kserve-container
image: cheyang/kserve-fluid:bloom-gpu
resources:
limits:
cpu: "3"
memory: 8Gi
requests:
cpu: "3"
memory: 8Gi
env:
- name: STORAGE_URI
value: "pvc://oss-data/bloom-560m"
- name: MODEL_NAME
value: "bloom"
# 如果使用GPU则设置成True,否则设置为False
- name: GPU_ENABLED
value: "False"
说明:本例中的 InferenceService 配置中在 image 字段使用了 cheyang/kserve-fluid:bloom-gpu 示例镜像,该镜像提供加载模型及推理服务的接口,您可以在 KServe 开源社区中找到此示例镜像的代码,并进行镜像自定义:https://github.com/kserve/kserve/tree/master/docs/samples/fluid/docker
- 执行以下命令,部署 InferenceService AI 模型推理服务。
kubectl create -f oss-fluid-isvc.yaml -n kserve-fluid-demo
- 执行以下命令,查看 AI 模型推理服务的部署状态。
kubectl get inferenceservice -n kserve-fluid-demo
预期输出:
NAME URL
READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGEfluid-bloom http://fluid-bloom.kserve-fluid-demo.example.com True 100 fluid-bloom-predictor-00001 2d
由预期输出可以看到 READY 字段为 True,证明 AI 模型推理服务已经部署成功。
步骤四:访问 AI 模型推理服务
- 获取 ASM 入口网关地址
a. 登录 ASM 控制台,在左侧导航栏,选择服务网格 > 网格管理。
b. 在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择 ASM 网关 > 入口网关。
c. 在入口网关页面找到名为 ingressgateway 的 ASM 入口网关,在服务地址区域,查看并获取 ASM 网关服务地址。
- 访问示例 AI 模型推理服务
执行以下命令,访问示例 AI 模型推理服务 bloom,将其中的 ASM 网关服务地址替换为上文中获取的 ASM 入口网关地址。
curl -v -H "Content-Type: application/json" -H "Host: fluid-bloom.kserve-fluid-demo.example.com" "http://{ASM网关服务地址}:80/v1/models/bloom:predict" -d '{"prompt": "It was a dark and stormy night", "result_length": 50}'
预期输出:
* Trying xxx.xx.xx.xx :80...
* Connected to xxx.xx.xx.xx (xxx.xx.xx.xx ) port 80 (#0)
> POST /v1/models/bloom:predict HTTP/1.1
> Host: fluid-bloom-predictor.kserve-fluid-demo.example.com
> User-Agent: curl/7.84.0
> Accept: */*
> Content-Type: application/json
> Content-Length: 65
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< content-length: 227
< content-type: application/json
< date: Thu, 20 Apr 2023 09:49:00 GMT
< server: istio-envoy
< x-envoy-upstream-service-time: 1142
<
{
"result": "It was a dark and stormy night, and the wind was blowing in the\ndirection of the west. The wind was blowing in the direction of the\nwest, and the wind was blowing in the direction of the west. The\nwind was"
}
* Connection #0 to host xxx.xx.xx.xx left intact
从预期输出中看到,AI 模型推理服务成功对示例输入进行了续写并返回推理结果。
性能基准测试
我们的性能基准测试将比较 KServe 使用自身存储初始化器(OSS Storage Initializer)和 Fluid 的推理服务的扩容时间,测试不同规格模型情况下的扩容时间,即衡量服务从 0 扩展到 1 所需的时间。
我们所选的测试机型为:
- Fluid 机型:ecs.g7.xlarge
- 推理机型:ecs.g7.2xlarge
使用的 Fluid Runtime 为:
- JindoFS
其他前提:
- OSS 的数据桶和 ACK 集群在同一个区域
- 数据预热提前完成
- ACK 集群节点上已经缓存了容器镜像
性能测试命令:
# Total time includes: pod initialization and running + download model (storage initializer) + load model + inference + network
curl --connect-timeout 3600 --max-time 3600 -o /dev/null -s -w 'Total: %{time_total}s\n' -H "Content-Type: application/json" -H "Host: ${SERVICE_HOSTNAME}" "http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/bloom:predict" -d '{"prompt": "It was a dark and stormy night", "result_length": 50}'
# Total time:
| Model Name | Model Size (Snapshot) | Machine Type | KServe + Storage Initializer | KServe + Fluid |
|---|---|---|---|---|
| bigscience/bloom-560m [ 15] | 3.14GB | ecs.g7.2xlarge(cpu: 8, memory: 32G) | total: 58.031551s(download:33.866s, load: 5.016s) | total: 8.488353s(load: 2.349s)(2 workers) |
| bigscience/bloom-7b1 [ 16] | 26.35GB | ecs.g7.4xlarge(cpu: 16, memory: 64G) | total: 329.019987s(download: 228.440s, load: 71.964s) | total: 27.800123s(load: 12.084s)(3 workers) |
Total:无服务情况下的推理响应时间(从 0 开始扩容),包括容器调度,启动,模型下载,模型加载到显存,模型推理和网络延迟时间。
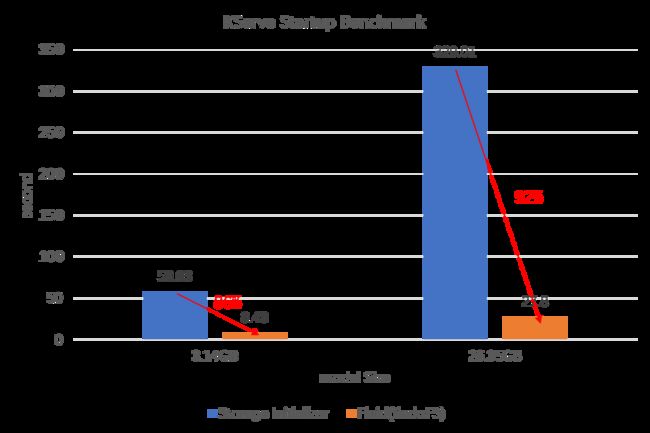
我们可以观察到 Fluid 在大语言模型(LLM)的场景下,
- 大幅提升 KServe 的冷启动速度,模型越大启动时间优化越明显
- 不但大幅度节省模型下载到云盘(Storage Initializer初始化)的时间,另外也可以通过增加缓存 worker 带宽的方式突破云盘的带宽限制(本例子中从云盘读取模型到内存的耗时也可以节省一半甚至三分之二)
这样恰恰可以大幅提升 KServe 在容器场景下的弹性扩缩容能力。
总结和展望
通过现有的云原生 AI 框架支持大模型这种新物种还需要不断地改善和优化,但是道阻且长,行则将至。阿里云容器服务团队愿意和社区的小伙伴一起探索如何能够用更低的成本支持更好的 LLM 推理场景,提供标准开放的方案,产品化的能力。我们后续会提供通过计算弹性扩缩容的规律触发数据缓存的弹性扩缩容来控制成本,以及大模型的热更新方法。
相关链接:
[1] 数据加速 Fluid 概述
https://help.aliyun.com/document_detail/208335.html
[2] 创建 Kubernetes 托管版集群
https://help.aliyun.com/document_detail/95108.html?spm=a2c4g.118970.0.0.1c6953c8tAGxmn
[3] 创建节点池
https://help.aliyun.com/document_detail/160490.html?spm=a2c4g.476586.0.0.d23b4180G64qLH
[4] 创建 ASM 实例
https://help.aliyun.com/document_detail/147793.htm#task-2370657
[5] 添加集群到 ASM 实例
https://help.aliyun.com/document_detail/148231.htm#task-2372122
[6] 通过数据面集群 KubeAPI 访问 Istio 资源
https://help.aliyun.com/document_detail/431215.html
[7] 创建入口网关服务
https://help.aliyun.com/document_detail/149546.htm#task-2372970
[8] 使用 Knative on ASM 部署 Serveless 应用
https://help.aliyun.com/document_detail/611862.html
[9] ASM 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fservicemesh.console.aliyun.com%2F&lang=zh
[10] 加速在线应用数据访问
https://help.aliyun.com/document_detail/440265.html
[11] 加速 Job 应用数据访问
https://help.aliyun.com/document_detail/456858.html
[12] 安装 ossutil
https://help.aliyun.com/document_detail/120075.htm#concept-303829
[13] 通过 kubectl 连接 Kubernetes 集群
https://help.aliyun.com/document_detail/86378.html
[14] 访问域名和数据中心
https://help.aliyun.com/document_detail/31837.html
[15] bigscience/bloom-560m
https://huggingface.co/bigscience/bloom-560m
[16] bigscience/bloom-7b1
https://huggingface.co/bigscience/bloom-7b1