物联网大数据存储利器IoTDB介绍
非物联网场景下的大数据应用通常是从业务库比如关系数据库同步数据到数仓,然后进行离线分析处理和展示。而在实时场景中,实时数据通常借助中间件消息系统如Kafka等转储,然后通过实时处理引擎如Spark,Flink等处理和展示。目前的技术之所以能够胜任上述场景,一是传统的关系数据库系统足够强大,能够支撑高并发读写操作,二是网络、硬件等基础设施足够实惠且软件系统集群化足够便利,然而在物联网场景下,上述便利并不是那么理所当然,比如风力发电机,一个风机有120-510个传感器,采集频率高达50Hz,就是每个传感器1秒50个数据点采集峰值,假设一个风电公司有2万个风机,那么每秒就是5亿个时序指标点的数据。再比如一台智能汽车按照每台300颗传感器,假设一个城市有100万台运行中的智能汽车,按照平均1Hz的采集频率,每秒就有3亿的时序数据记录!实际中的传感器采集频率远高于1Hz。
这跟非物联网场景下的大数据应用的区别可以总结为以下几点:
1. 数据高速写入,属于写远大于读的场景,基于B+树索引结构的关系数据库系统会导致随机读写的情况,限制了系统读写吞吐量。
2. 数据量大,而且相同传感器产生的数据类型一样,这自然需要基于列存储,并且支持不同列适用不同压缩格式的系统。基于行存储的系统无法优化存储,降低存储空间。
3. 物联网场景下的数据通过弱网发送数据,网络带宽本身有限,这会造成数据的延迟、乱序以及因为设备环境异常造成的空数据等异常数据发生。
4. 为减轻数据传输延迟和数据中心的计算压力,物联网设备通常支持边缘计算,但边缘设备的硬件资源有限,这就要求本地存储系统足够轻量。
5. 物联网数据量大,转移到数据中心要求便捷高效,能够对接现有的大数据处理技术生态。
6. 数据查询支持多维度聚合,降采样,时序分割等。
放眼望去,IoTDB是目前最佳选项,不仅能够满足上述要求,而且针对物联网模型做了定制化,提供 JDBC 访问方式,支持边云一体化部署,实现了开放的 TsFile 存储格式,设备模型简单易理解。存储支持本地存储和Hadoop File system,并提供多种 Connector,与现有大数据生态无缝打通。
Apache IoTDB是一个开源物联网原生数据库,旨在满足大规模物联网和工业物联网(IoT和IIoT)应用对数据、存储和分析的严苛要求。该项目最早是由清华大学大数据系统软件团队研发,并于2018年11月进入捐赠给Apache,进行了为期1年10个月的孵化,2020年9月16日,经Apache董事会表决,Apache IoTDB正式晋升为顶级项目。
IoTDB 功能特点
(1)开放的架构:IoTDB 架构图如下所示,采用存储和查询分离的架构,将底层存储开放给上层应用,一份数据既支持实时查询,也支持大数据分析,避免了数据迁移代价。
(2)新型文件存储格式:底层存储采用针对时间序列优化的文件格式 TsFile,采用灵活的元数据管理和写入控制,支持各时间序列独立写入,采用时间序列原生的列式存储与序列编码、压缩方式。
(3)高速数据写入:IoTDB 提供数千万点每秒的写入吞吐,同时具有低延迟。支持单节点每秒数千万点的写入速度,可处理乱序、重复数据,有效管理万亿数据点。
(4)高效的索引结构:如聚合索引PISA支持高效的聚合查询、多分辨率数据查询。KV-index支持复杂的子序列匹配等高级查询。
(5)与大数据系统充分集成,支持MapReduce、Spark、Grafana、Zeppelin、Flink、RocketMQ、Kafka、Pulsar等。
IoTDB应用架构
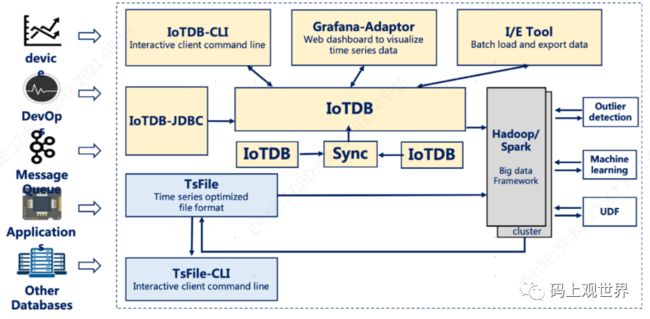
上图中间部分是IoTDB引擎,也就是我们通常说的IoTDB,是整个IoTDB的核心。围绕着核心,是一系列工具套件,组成IoTDB完整的功能服务,这些组件包括IoTDB-JDBC、IoTDB-CLI、I/E Tool和TsFileSync 、TsFile、Hadoop/Spark Connector、Grafana-Adaptor,它们一起涉及到IoTDB的数据生命周期全过程,包括数据的收集、存储、查询、分析和可视化。
用户可以通过IoTDB-JDBC将传感器设备收集的数据写入IoTDB,同样也可以从IoTDB查询数据,该组件是用户跟系统交互的常用方式。底层数据存储基于TsFile(本地或者HDFS)。
本地的TsFile可以借助TsFileSync 工具迁移到HDFS,通过Hadoop或者Spark做进一步处理,如复杂分析和计算。
写入本地或者HDFS的TsFile,可以通过Hadoop/Spark Connector利用Hadoop或者Spark的处理能力。处理后的结果可以同样的方式写回TsFile。
另外,IoTDB 和TsFile也提供了IoTDB-CLI客户端工具以比如通过SQL、脚本或者图形化方式满足用户各种各样的数据写入和查看需要。
IoTDB采用Client/Server架构模式:
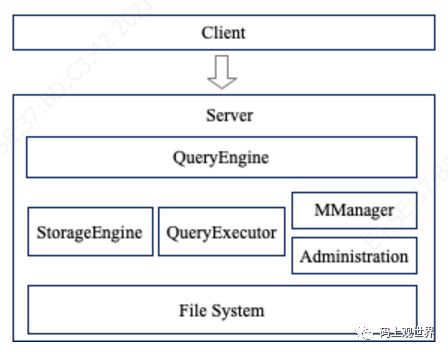
这里的Server包括:
查询引擎QueryEngine:负责解析用户通过JDBC方式提交的SQL命令的解析、生成计划、交给对应的执行器、返回结果集。
存储引擎StorageEngine:IoTDB 存储引擎基于 LSM Tree 结构设计,IoTDB 存储引擎负责将写入的数据先记录 WAL,再写到内存 memtable,在后台逐步刷到磁盘 TsFile。为保证查询效率,磁盘上的 TsFile 通过一定的规则进行 Compaction。
数据查询QueryExecutor:执行查询引擎解析后分派的查询任务,分为原始数据查询、聚合查询、降采样查询、最新数据查询、分组填充查询、按设备对其查询等。
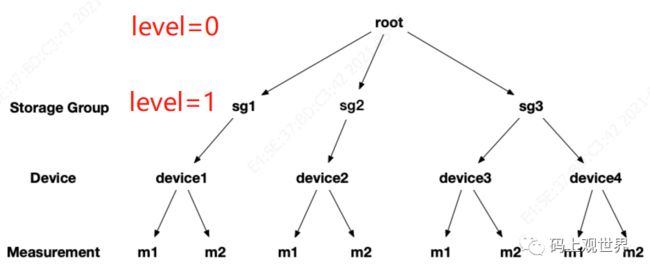
元数据管理:IoTDB的元数据通过MManger来管理,数据结构采用目录树状结构MTree维护,树节点类型分为存储组节点和内部非叶子节点和叶子节点。叶子节点指的是传感器元数据,倒数第二层为设备元数据,根节点固定为ROOT,根节点到倒数第二层之间为存储组元数据,存储组元数据路径可以跨越多个节点。元数据包括MLog,如创建、删除时序,创建、删除存储组等操作日志,以及TLog,这是时序的tag/attribute信息。
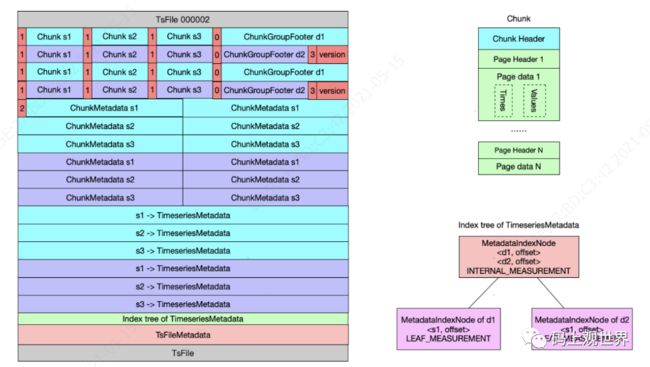
文件存储TsFile:TsFile 是为物联网设备时序数据存储定制的文件格式,整体以树状目录结构组织,一个 TsFile 里可存储多个设备的数据,每个设备包含多个 measurment(指标)。TsFile 整体是一个多级映射表:TsFileMetaData ==> TimeSeriesMetadata ==> ChunkMetadata ==> Chunk。TsFileMetadata 描述整个 TsFile ,包含格式版本信息, MetadataIndexNode 的位置,总的 chunk 数等元数据信息。MetadataIndexNode 包含多个 TimeSeriesMetadata ,每个 TimeSeriesMetadata 指向一个设备的元数据信息 ChunkMetadata 列表;ChunkMetadata 指向 ChunkHeader 位置,并对应最终的 Chunk Data。假设TsFile 里包含两个设备数据,标识分别为 d1、d2,每个设备包含 s1、s2、s3 三个监测指标,TsFile存储结构示意图如下图所示:
Server除了上述模块还包括管理员相关的管理模块。
使用场景
场景1 :使用表面贴焊技术(surface mount technology ,简称:SMT)制造芯片的自动生产线公司为了保证芯片连接处的锡膏印刷(solder paste printing)质量,往往需要三维光学设备检测连接处锡膏的高度、水平和垂直偏移量等指标,这些指标数据可以通过SDK的形式写入TsFile文件,然后按照一定规则(比如每天),通过TsFileSync 工具同步到数据中心做进一步分析。此时,本地设备需要部署TsFile和TsFileSync,远程数据中心部署Hadoop或者Spark集群。
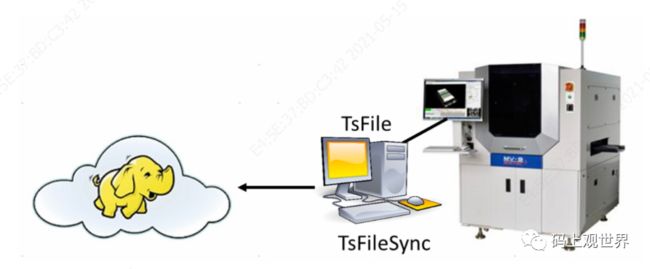
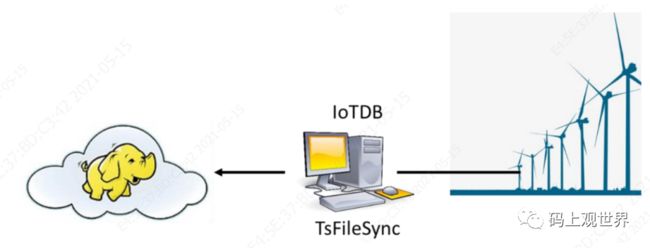
场景2:风力发电公司为了能够即使获取分机的工作状态和风速等数据,风电公司往往需要在本地进行部分计算,然后再将原始数据传回数据中心。这种情况下,需要在风机PC中部署IoTDB和TsFileSync ,以进行读写数据和本地分析计算,远程数据中心部署Hadoop或者Spark集群。
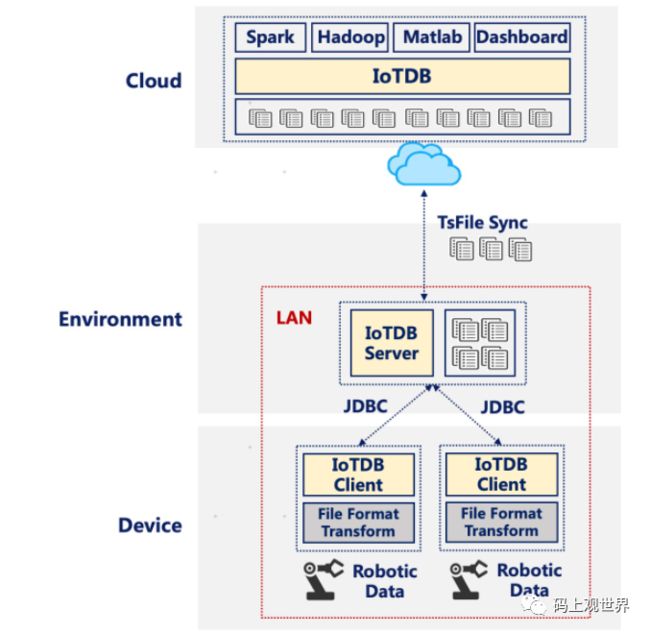
场景3:为了监控工厂机器人的工作状况,往往需要采集多种传感器数据,但是这些机器人本身硬件能力有限,而且处于封闭的局域网内,无法跟外界联系,但是可以连接工厂内指定的能跟外界连接的中心服务器,此时可以将IoTDB-Client部署到机器人设备上,IoTDB和TsFileSync部署到工厂中心服务器,Hadoop/Spark部署到远程数据中心,中心服务器的数据通过TsFileSync同步到数据中心。
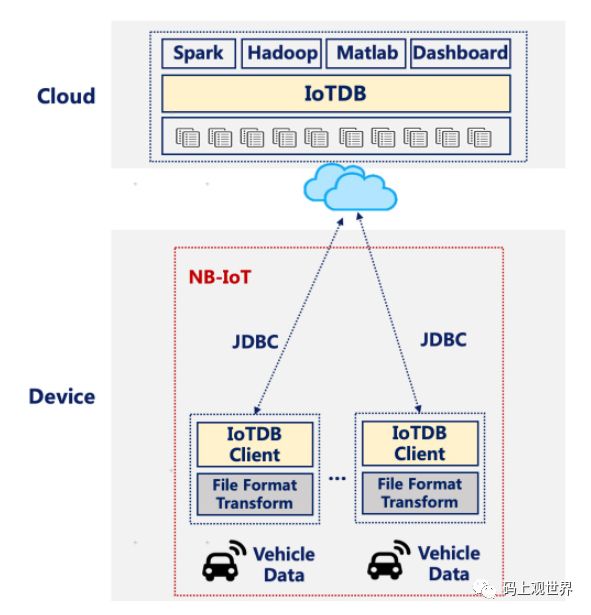
场景4:汽车公司为了监控车辆运行状况数据,需要将传感器采集的实时数据传回数据中心,进行复杂分析和计算,不同于场景3中工厂机器人,汽车之间以及汽车和数据中心可以借助窄带物联网(Narrow Band Internet of Things, 简称:NB-IoT)互相通信。但是汽车硬件设备能力有限,可以部署轻量的IoTDB-Client 工具,通过IoTDB-JDBC传回数据到数据中心。
常用操作
操作基于控制台JDBC,使用SQL类似语法。
#创建存储组
set storage group to root.turbine
# 查询存储组
SHOW STORAGE GROUP
# 删除存储组
delete storage group root.turbine
#创建默认时序
create timeseries root.turbine.d1.s1
#创建时序,制定别名、数据类型、压缩格式,制定tag和attributes
create timeseries root.turbine.d1.s1(temperature) with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY tags(unit=degree, owner=user1) attributes(description=mysensor1, location=BeiJing)
#自动创建d1设备下两个时序:status,temperature,时间戳为相对值
INSERT INTO root.turbine.d1(timestamp,status,temperature) values(200,false,20.71)
#显示指定路径下的所有时序
Show Timeseries root.turbine
#根据tag过滤查询
show timeseries root.turbine.d1 where unit=degree
#统计指定路径下的时序数量
count Timeseries root.turbine
#删除指定路径下的时序
delete timeseries root.turbine.d1.s1
# 查询设备下指定时序的采集记录点数
select count(temperature) root.turbine.d1
# 根据level聚合查询采集点数量,level从0开始,0表示ROOT
select count(status) from root.turbine.* group by level=2
除了上述基本查询语法外,还有更高级和实用的查询语法,比如滑动窗口降采样查询,限于篇幅,本文不再介绍,感兴趣的读者可以参考官方文档。
读写性能
关于性能,官方介绍每秒千万级的写入量,感兴趣的读者也可以自己测试,不过值得一提的是,IoTDB对于维护元数据的开销较大,而且比较耗内存。为了提高读写效率,写入数据最好保证数据按照顺序写入,避免乱序排序造成性能降低。经过测试发现,常用的count等查询操作跟记录条数几乎无关,不论是千万级别还是10亿级别,时间基本保持在10毫秒内。这点已经颠覆常用的数据库系统,因为IoTDB将这些常用的统计信息维护进了元数据。
在写入方面,IoTDB提供了多种写入方式,包括批量,比如基于批量写入的API用法关键代码:
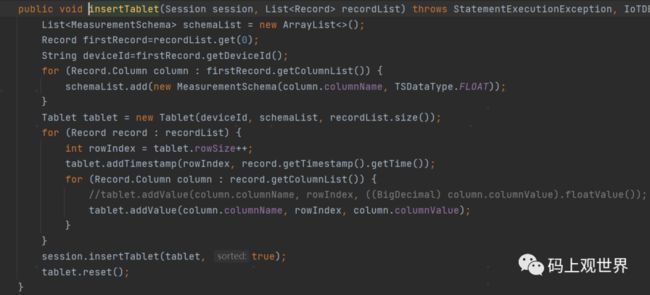
感兴趣的读者公众号回复“IoTDB测试代码”获取完整的测试程序。
参考资料
https://iotdb.apache.org/UserGuide/V0.10.x/Overview/Scenario.html
http://iotdb.apache.org/SystemDesign/TsFile/Format.html
https://iotdb.apache.org/UserGuide/V0.12.x/IoTDB-SQL-Language/DDL-Data-Definition-Language.html