KMP 算法示例和解析(1)
按:笔者非科班出身,计算机系的课程基本都没系统学过,准备系统地看看数据结构和编译原理,先从简单的来吧。看了几日,看到了串的模式匹配,进而看到了KMP算法,以为很轻松,没想到看了三天,才算弄明白。上网一查,发现这的确是个难点。笔者想从我自身的理解来谈谈怎么看懂和解释这个算法。
第一点: 这是个普通的算法,没有数学知识点,诸如矩阵啊,变换啊,没有,因此不要有什么压力。换言之,只要老老实实的一步步推演,自然就懂了。
第二点:为啥看不懂,或者费劲。 就笔者的感受而言,是没有一环扣一坏的看下去,有点儿想当然;还有就是课本呢都是精炼过的语句,每个字都很重要,但是自己看的时候往往会忽略,导致后面分析的时候就 乱套了。
笔者看的书是一本老书,也不知道新的书怎么讲的,所以我举例子还是书上的例子。这是上世纪86年清华出版的计算机系教材,作者是严蔚敏和吴伟民。
下面从笔者体会出发,试着讲一下KMP算法的理解和难点。
要想看懂这个算法,要从一般字符串查找入手,才能有感性认识。
KMP算法的直白解释
一个笼统的认识如下:
第一:它是针对某种类型查找的速查方法;
第二:该算法对这些类型的查找进行了预处理;
第三:对于不符合这些类型的字符串的查找,该算法可能会慢一点儿;
第四:该算法的统计效率比普通算法高的, 在特殊场景下,要高很多。
下面解释这种类型的数据特点:
分两方面,主串和模式串(需要查找的字符串);
先说模式串:
如果模式串中的左面开始的字符串子集在后面又出现过,那么这种串就有可能使用MKP算法提高匹配效率
再说主串;
如果主串的子串恰好和上述模式串的子串相同,那么可以确定KMP算法会提高效率。
举例如下:
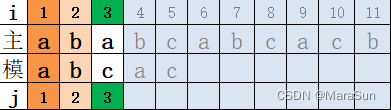
注意到模式串中p1=p4 , 这就意味着 p1 和p2,p3 不相同,由此可以推断,如果出现上图的匹配,即 模式串和主串分别在 j=3和 i=3时出现适配,则模式串可以直接右移两位,将i=1 与j=3 对齐再进行下一轮的比较。如图示,普通匹配,模式串右移一位时,这个比较肯定不成功(原因上面已述):
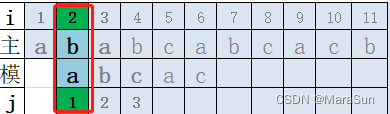
改进的方法,直接移动两位(i=3 与j=1 对齐匹配),这样的比较才有意义。(KMP算法)
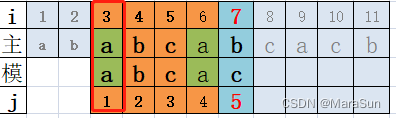
那么问题是:失配后,主串失配位置上的字符对应模式串中的第几个字符?这就引出来KMP的位置函数 Next(K)。(可以看出,这个位置函数和主串没有关系。)
位置函数定义和解释
教材上位置函数的定义如下:
令next[j]=k, 则next[j] 表明模式串中的第 j 个字符与主串中相应字符失配时,在模式串中需要重新和主串中该字符进行比较的字符的位置。(这个位置指的是:模式串中该字符到左边界的位置,其中第一个字符的位置是1,不是0——笔者注)
并给出定义如下:

我们先分析一下定义表达是个什么意思。
第一:next[j] 是一个数,该值表示的是模式串中到左边界的长度;
第二:0 当j=1 时
根据定义,它的物理意义是:主串指针不变时,模式串没有课用的匹配串;而实际操作就是此时需要主串指针i+1,而模式串从1 开始对应主串i+1 这个字符进行匹配;
第三:Max{k| 1
2)若有 从 模式串j 的位置向左k-1个字符构成的串 = 模式串前k-1个字符,则K 是其中最长的那个串的长度 +1;
3) 集合如果为空,属于其他情况或者j=1的情况
4)注意: k!=1, k!=j,k 在1 和 j 之间, 即 j 必须大于等于3 才不是其他情况;
第四:1 其他情况,不符合 第二和第三的情况,例如 模式串 abc,j=2 和3 的情况就是其他情况;
位置函数值的计算
首先按照定义,手工计算一套next 的值。如图

下面我们逐个根据定义计算:
j=1,根据定义 next(1)=0;
j=2,由于K不能等于2, 因此属于其他情况,next(2)=1;
j=3,j 的前面不存在子串相等的情况,顾 属于情况3 , next(3)=1;
j=4, j 的前面存在 子串相等的情况,而且符合 next 函数的第二个条件,如图, 根据定义 k-1是子串的长度,即k-1=1, 所以k=2, 即 next(4)=2;

j=5, 跟4 情况相同,如图, 所以next(5)=2;

j=6 , 如图示:

此时6 前面的最大符合条件的子串是 ab,所以 k-1=2, 即 k=3,所以 next(6)=3;
j=7, 7 的前面没有符合条件的子串,所以 next(7)=1;
j=8,8 的前面 有 a=a, 如图, 所以 next(8)=2;

手工根据定义推导的过程并不复杂,但是如何把这个过程进行规范化呢?这就是来到了,KMP 算法的难点之处,就是利用程序(递归思想)计算next(j)的值。
next函数的规范计算有点儿绕,拟再下文介绍。
maraSun BJFWDQ
2022-05-20
520 is a romantic number in China for its pronunciation in Chinese is very similar to wo ai nin which means I love you in English.
北京疫情防控慢慢抓紧,个别地方已经迫近上海模式。这不是一个好的兆头。清零的愿望固然丰腴,但是现实不但骨感而且残酷。希望科学对待,科学对待啊。无论上海还是北京都折腾不起,中国更折腾不起。