【算法基础】KMP算法解析与实现
一,前言
字符串的模式匹配,即找寻字符串p第一次出现在字符t中的起始位置。计算机科学研究最广泛,最古老的问题之一就是字符串匹配。关于字符串的模式匹配,《数据结构》教材中一般介绍两种方法:一是“朴素的模式匹配算法”,另外一个是“快速模式匹配算法”,也就是KMP算法。
二,朴素匹配算法
朴素的模式匹配算法的基本思想是:逐个使用p中的字符去与t中的字符进行比较。
其中正文t的长度用n表示,模式字符串p的长度用m表示。如果t1=p1,t2=p2,…,tm=pm,则模式匹配成功,p1p2…pm即为所要寻找的子串,此时返回其起始位置1即可;否则,将p向右移动一个字符,然后用p中的字符从头开始与t里面对应的字符一一比较[2]。
重复此操作直到匹配成功,或p已移动到这样一个位置:t中剩余字符数小于p长度,那么就表明模式匹配不成功,t中没有子串与p相等,我们约定返回-1。朴素模式匹配算法理解起来简单,算法也易于实现,但因其执行效率低,最坏情况下时间复杂度为O(nm)。分析该算法我们知道,效率低的原因在于,寻求匹配时,没有充分利用部分匹配的结果,每次比较不匹配时,模式p总是只能向右移动一个字符的位置,存在大量回溯。
三,KMP算法
在进行字符串比较时,能否在匹配不成功时不从头开始匹配?部分匹配的信息可否记录下来加以使用?要求不回溯,模式就需要向右滑动一段距离,那么又如何确定滑动多远的距离呢?
KMP算法解决了上述问题。
1.next数组
next[ j]指p[ j]字符前有多少个字符与p开头的字符相同。KMP算法中,模式p部分匹配的信息记录在next数组
中,因此next数组确定了模式p向右滑动的距离。next数组的定义、作用、数组元素的获取和使用方法是字符串模式匹配章节讲述的关键。
先看如下式子。
模式串p存在某个k(0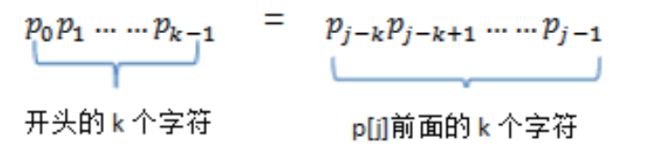
那么next[j] = k ;
举个例子:
模式p=abcabcd,j=6时,p0p1p2=p3p4p5,说明p[6]前面有3个字符与模式开头的3个字符相同,所以有next[6]=3。
归纳一下,next[j]数组定义如下:

例子说明:
p=ababaaabab,next[j]数组为 下图所示:
 我们规定,next[0]=-1,next[1]=0(因p[1]前只有一个字符)。p[2]前的字符b和p开头的字符a不同,故next[2]=0。p[3]前的字符a和p开头的字符a相同,故next[3]=1。p[4]前的字符ab和p开头的字符ab相同,故next[4]=2。p[5]前的字符aba和p开头的字符aba相同,故next[5]=3。p[6]前只有一个字符a和p开头的字符a相同,故next[6]=1。以此类推。
我们规定,next[0]=-1,next[1]=0(因p[1]前只有一个字符)。p[2]前的字符b和p开头的字符a不同,故next[2]=0。p[3]前的字符a和p开头的字符a相同,故next[3]=1。p[4]前的字符ab和p开头的字符ab相同,故next[4]=2。p[5]前的字符aba和p开头的字符aba相同,故next[5]=3。p[6]前只有一个字符a和p开头的字符a相同,故next[6]=1。以此类推。
明白了next数组的含义,再来讲解根据模式p求数组next值的程序,就容易理解了。求next数组的程序如下:
public static int[] getIndexArray(char[] str2){
if(str2.length == 1){
return new int[]{-1};
}
int[] next = new int[str2.length];
next[0] = -1 ;
next[1] = 0 ;
int i = 2 ;
int cu = 0 ; // 原来最长匹配中的后面一个字符数字
while(i < str2.length){
if(str2[ i - 1] == str2[cu]){
next[i++] = ++cu ; // 需要注意的是上次所匹配的最长字串的长度所对因的值 /
} else if(cu > 0){
cu = next[cu]; // 一直在不断的减少
} else {
next[i++] = 0 ;
}
}
return next;
}
2.next数组的作用
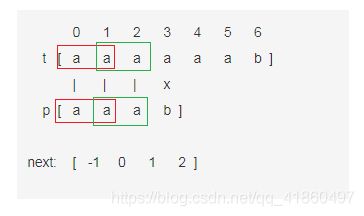
设正文t=aaaaaab,模式p=aaab,求出模式p的next数组为{-1,0,1,2},开始字符匹配,如所示:
0 1 2 3 4 5 6
t [ a a a a a a b ]
| | | x
p [ a a a b ]
next: [ -1 0 1 2 ]
到p[3]时,字符匹配失败。使用朴素模式匹配算法,模式p向右移动一个字符,下一次匹配的字符为t[1]与p[0]、t[2]与p[1].
0 1 2 3 4 5 6
t [ a a a a a a b ]
| | | x
p [ a a a b ]
next: [ -1 0 1 2 ]
而且,经过上一次的匹配,我们发现t[1]与p[1]相同,t[2]与p[2]相同,在next数组中我们知道p[3]=2,由求最长匹配的规律知,p[0]p[1]与p[1]p[2]相同,所以原本t[1]与p[0],t[2]与p[1]的匹配就可以转化为求t[1]与p[1],t[2]与p[2]的匹配。也就是可以进行最长子串的重叠操作 。
于是,第二次的匹配就可以直接从t[3]与p[2]开始.
0 1 2 3 4 5 6
t [ a a a a a a b ]
|
p [ a a a b ]
next: [ -1 0 1 2 ]
为什么我一定会确信,在t[3]和p[3]比较不匹配之后 ,就可以直接使用t[3]和p[2] ,而不是接着从 t[1]和p[0]开始比较。加速匹配的这个过程 。
假设,在第一次匹配失败 之后 ,在进行t[3]和p[2]比较的过程中途,存在匹配成功的案例 , 由于在原来字符串中aaab中已经求出来的next数组的值,就是除去自己当前所指的字符之前的所有字符串最长前缀长度,如下图
所以,在图上这次匹配中,t[3] 和p[3]不匹配之后, 就可以将原来p字符串中的前缀 ,和t已经匹配的后缀进行对齐,也就是图中p中的红框和 t中的绿框进行对齐,也就是直接由上述过程加速到下图过程:

假设 ,在加速的中途中还存在匹配成功的情况,但这是不可能的,因为 , next数据中的数据已经是最长的前缀了,除了前缀和字符串的后缀匹配之外,中间过程的一切结果前缀不可能匹配成功。可以在纸上推演一下。
总结
- kmp加速中串的匹配过程
- 在一次匹配串和被匹配串不进行匹配的时候,就使用next 数组中的索引和 被匹配的串上次的索引进行对齐。
- 必须先求出next数组 ,这是kmp的精髓所在。
代码
/*
[email protected]
*/
public static int getIndex(String str1 , String str2){
char[] so = str1.toCharArray();
char[] de = str2.toCharArray();
int[] next = getIndexArray(de);
int p1 = 0 ;
int p2 = 0 ;
while( p1 < str1.length() && p2 < str2.length()){
if(so[p1] == de[p2]){
p1++;
p2++;
} else if(next[p2] == -1){
p1 ++ ; // 代表一开始都是不相等的 。
} else {
p2 = next[p2] ; // 直接跳到next数组中的值
}
}
return p2 == str2.length() ? p1 - str2.length() : -1 ;
}