用于语义图像分割的弱监督和半监督学习:弱监督期望最大化方法
这时一篇2015年的论文,但是他却是最早提出在语义分割中使用弱监督和半监督的方法,SAM的火爆证明了弱监督和半监督的学习方法也可以用在分割上。
这篇论文只有图像级标签或边界框标签作为弱/半监督学习的输入。使用期望最大化(EM)方法,用于弱/半监督下的语义分割模型训练。
背景知识
1、符号定义
X是图像。Y是分割映射。其中,ym∈{0,…,L}是位置m∈{1,…,m}处的像素标签,假设我们有背景和L个可能的前景标签,m是像素个数。
2、 有监督学习的流程
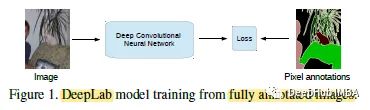
在上述完全监督情况下,目标函数为:
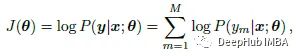
这里的θ为模型参数向量。每个像素的标签分布计算如下:
![]()
其中fm(ym|x,θ)为模型在像素m处的输出。J(θ)采用小批量SGD优化。
弱监督方法(图像级标注)
当只有图像级标注时,可以观察到的是图像值x和图像级标签z,但像素级分割y是潜在变量。那么我们有如下的概率图形模型:
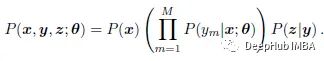
给定之前的参数估计θ ',期望的完整数据对数似然为:
![]()
其中可以采用em近似,在算法的e步中估计潜在分割:
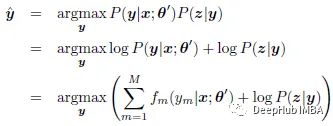
论文对EM进行了修改,增加了偏差Bias

在这种变体中,假设log P(z|y)对像素位置进行因式分解为:
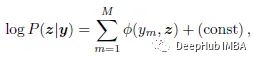
这样可以在每个像素上分别估计e步分割:
![]()
参数bl=bfg,如果l > 0, b0=bbg,且bfg > bbg > 0。
可以简单的解释为:鼓励将一个像素分配给图像级标签之一。bfg > bbg比背景更能增强当前景类,鼓励完整的对象覆盖并避免退化的解决方案。
论文的参数是:BFG = 5, BBG = 3,除此以外,论文还使用了自适应的值:
EM-Adapt没有在EM-Fixed中使用固定值,而是鼓励至少将图像区域的ρl部分分配给类l(如果zl = 1),并强制不将像素分配给类l(如果zl = 0),这样EM-Adapt可以自适应地设置图像和类相关的偏差bl。ρfg = 20%, ρbg = 40%。
弱监督方法(边界框标注)
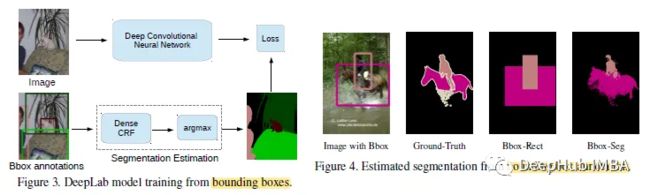
Bbox-Rect方法相当于简单地将边界框内的每个像素视为各自对象类的正面示例。通过将属于多个边界框的像素分配给具有最小面积的边界框来解决歧义。虽然边界框完全包围了对象,但也包含背景像素,这些像素是假阳性示例污染训练集。
为了过滤掉这些背景,论文还使用了DeepLab中使用的CRF。边界框的中心区域(框内像素的%)被约束为前景。用hold -out集估计CRF参数。
论文的方法Bbox-EM-Fixed:该方法是前面提到的EM-Fixed算法的一种变体,其中仅提升当前前景目标在边界框区域内的分数。
半监督方法(混合标注)
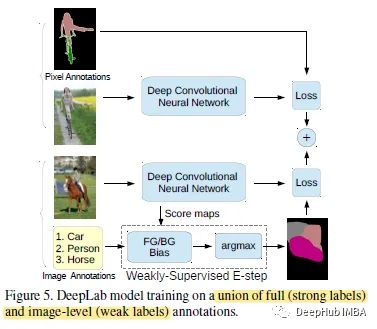
在混合标注的情况下,就变成了一种半监督的情况。在深度CNN模型的SGD训练中,每个mini-batch具有固定比例的强/弱标注图像,并使用论文提出的EM算法在每次迭代中估计弱标注图像的潜在语义分割。
结果

在EM-Fixed半监督设置中使用1464个像素级和9118个图像级注释,性能显著提高了,达到64.6%,接近完全监督67.6%。
在半监督设置中使用2.9k像素级注释和9k图像级注释,得到68.5%,接近完全监督70.3%。
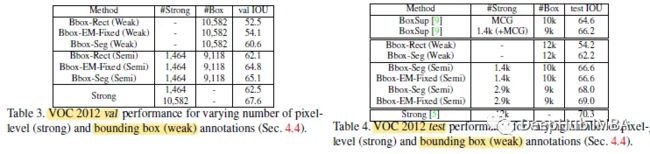
Bbox-Seg比Bbox-Rect提高了8.1%,并且在像素级标注结果的7.0%以内。1464个像素级标注与弱边界框标注相结合,得到的结果为65.1%,仅比像素级标注差2.5%。
Bbox-EM-Fixed在添加更多标注时比Bbox-Seg有所改进,当在添加2.9k标注时,它的性能提高了1.0% (69.0% vs 68.0%)。
可以说的EM算法的e步比前景-背景分割预处理步骤能更好地估计目标掩模。
总结
这虽然是一篇很老的论文,但是它提出的思想到现在还是可用的,这对于我们了解现在的弱监督和半监督的学习方法也是非常有帮助的,所以推荐对于研究SAM方向的小伙伴都阅读一下,论文地址:
https://avoid.overfit.cn/post/36b0fbd642d640ceab41d0dfb885a95d