Spark Core:RDD编程
文章目录
-
- Spark Core:RDD编程
- 1、实验描述
- 2、实验环境
- 3、相关技能
- 4、知识点
- 5、 实现效果
- 6、实验步骤
- 7、总结
Spark Core:RDD编程
1、实验描述
- 本实验是在spark local 模式下,利用spark-shell 完成RDD的基本操作相关实验。
- 实验时长:
- 45分钟
- 主要步骤:
- 启动spark-shell
- spark-shell的使用
- RDD 的基本操作
2、实验环境
- 虚拟机数量:1
- 系统版本:Centos 7.5
- JDK 版本:1.8.0_131
- Spark版本:Apache Spark 2.1.1
3、相关技能
- Spark-shell的使用
4、知识点
- 常见Linux命令
- RDD
- Spark-shell
5、 实现效果
spark RDD reduce 操作最终效果如下图:
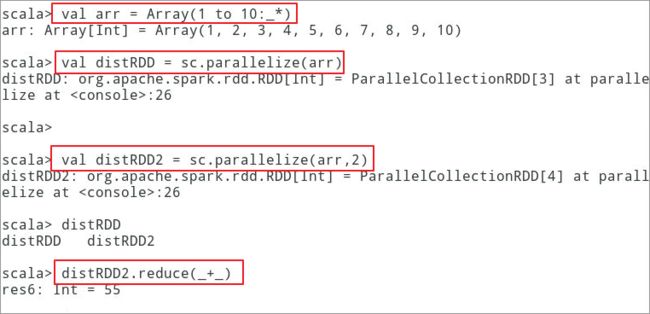
6、实验步骤
注:本实验是在spark local模式下执行.
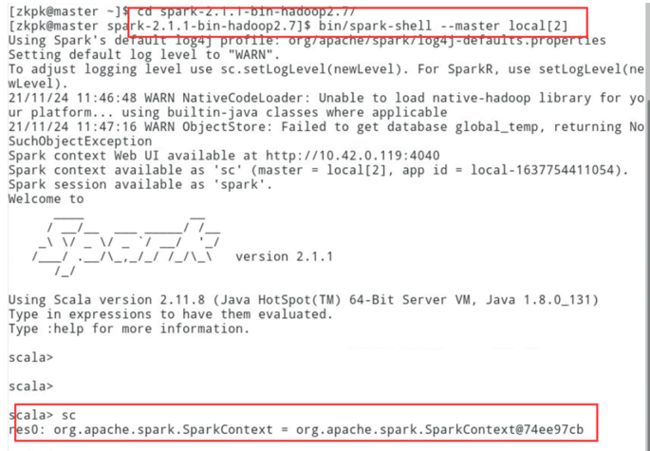
6.1启动spark-shell,启动时指定启动模式为local
[zkpk@master ~]$cd [zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/[zkpk@master spark-2.1.1-bin-hadoop2.7]$ bin/spark-shell --master local[2]
6.1.1因为Spark Shell相当于一个 name 为“spark shell”Spark
application,启动时可以用过spark-shell —master
local[2]来指定以2个本地线程启动.
可以通过如下命令查看spark-shell启动后为我们创建好的SparkContext
scala> sc
6.2RDD 的创建使用
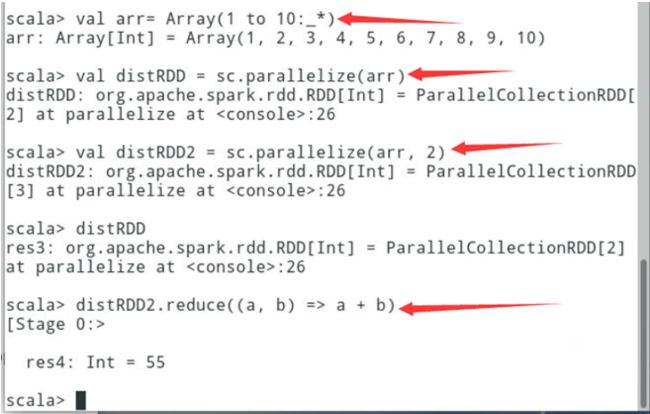
6.2.1创建RDD,依次完成如下操作
// 创建1-10的数组val arr= Array(1 to 10:_*)// 从并行化的集合创建RDDval distRDD = sc.parallelize(arr)// 创建并行度为2的RDDval distRDD2 = sc.parallelize(arr, 2)// 对RDD进行执行reduce操作,完成对RDD内的元素值的累加distRDD2.reduce((a, b) => a + b)
6.2.2可以通过外部数据集创建RDD,spark默认支持HDFS,FileSystem,Cassandra,redis,MySQL等外部数据源创建RDD。同时spark默认支持,SequenceFiles,textFile等文本格式。
6.2.2.1需要注意(如果使用本地存储上的文本文件,该文件需要在每个节点都有)
6.2.2.2同时支持目录,通配符,压缩文件等
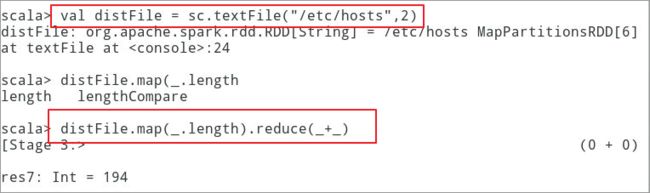
6.2.2.3如下所示,使用textFile读取本地的系统文件,
并计算整个文件中的字符总长度。
scala> val distFile = sc.textFile("/etc/hosts",2)scala> distFile.map(s => s.length).reduce((a, b) => a + b)
6.3RDD操作, RDD目前主要的两类算子:
6.3.1转换(transformation):转换操作只会产生新的RDD,transformation是lazy操作,会记录一系列的RDD转换操作作为lineage,然后在遇到action操作的时候,才会触发一系列的执行。
6.3.2动作(action):
动作则会产生相应的结果集,遇到action会触发一个job,按照lineage进行执行。
6.3.2.1默认lineage中的每个转换算子生成的子RDD,都会在执行action算子时开始真正的计算。过长的lineage应该给已经缓存了的RDD添加checkpoint,切断lineage,以减少容错带来的开销。
6.3.2.2具体命令如下。
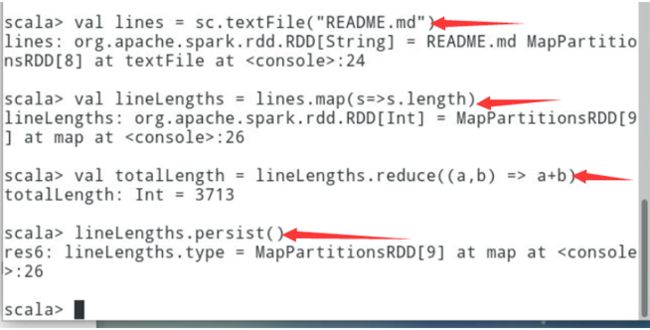
// 从本地spark按照目录下的README.md文件创建RDDval lines = sc.textFile("README.md") // 读取文件val lineLengths = lines.map(s=>s.length)//使用map操作计算每一行的长度val totalLength = lineLengths.reduce((a,b) => a+b)// 使用reduce 累计所有行的长度lineLengths.persist()//将计算结果持久化的内存中
6.4函数的使用,Spark API里将函数传给集群运行有两种方式:
6.4.1匿名函数
6.4.2Object中的函数。如,定义一个object
functionApp,然后将functionApp.f1作为RDD算子的参数传入
6.4.3具体命令如下:
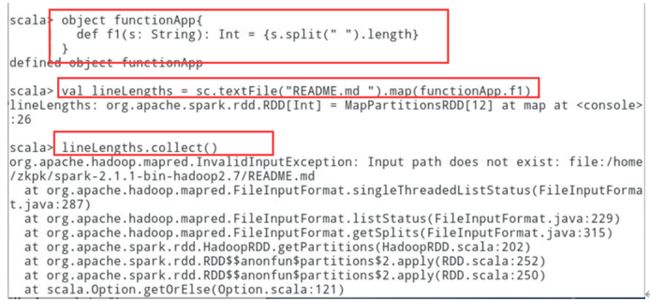
//创建一个单例对象functionAppobject functionApp{ def f1(s: String): Int = {s.split(" ").length}}//将函数传入map中作用于每一行val lineLengths = sc.textFile("README.md ").map(functionApp.f1)lineLengths.collect()
6.5用于操作k-v对的RDD操作:大多数的spark operation
可以作用于包含任意类型对象的RDD,有一部分操作只能作用于类型为k-v对的RDD,例如常见的shuffle操作,像reduceByKey,groupByKey,通过key将元素聚合起来。
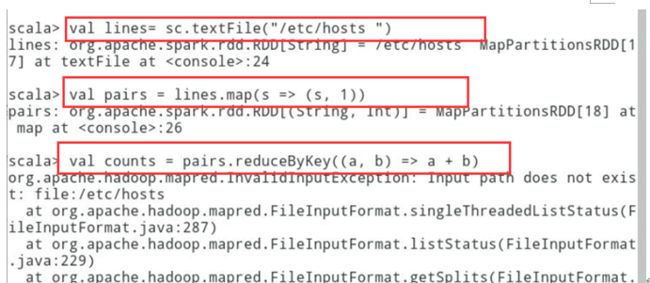
val lines= sc.textFile("/etc/hosts ") // 转换RDD成键值对val pairs = lines.map(s => (s, 1))// reduceByKey操作获得结果val counts = pairs.reduceByKey((a, b) => a + b)//查看结果counts.foreach(println)
6.6共享变量的使用:默认情况下,当spark的一个函数作用于多个分区上时,需要将每一个变量的副本引用到每一个任务的函数中。有时候,一个变量需要在整个任务中或者在任务和driver端之间来共享,这时候就需要共享变量。Spark目前支持两种:
6.6.1广播变量:通过在一个变量v上调用SparkContext.broadcast(v)方法来进行创建。广播变量是v的一个包装,可以通过调用
.value方法来访问它的值。
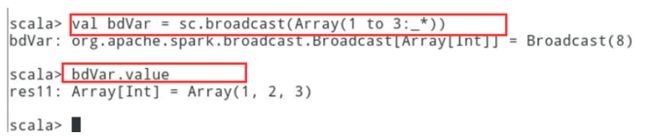
// 创建广播变量val bdVar = sc.broadcast(Array(1 to 3:_*))// 查看广播变量的值bdVar.value
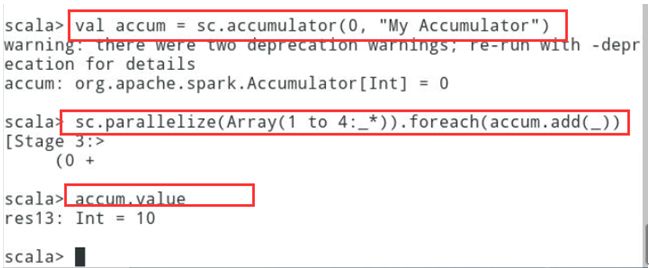
6.6.2累加器:是一个仅可以添加的变量,可以高效的支持并行。累加器可以用于实现计数。具体示例如下:
// 创建累加器val accum = sc.accumulator(0, "My Accumulator")// 对RDD数据集的数值进行累加sc.parallelize(Array(1 to 4:_*)).foreach(accum.add(_))// 查看累加器的结果accum.value
7、总结
本次实验我们基础性的学习了RDD 的相关概念以及RDD常用的操作。