kubernetes节点NotReady,服务报错Unable to update cni config: no networks found in /etc/cni/net.d
补充内容:
如果节点存在还原重搭(如执行kubeadm reset,那么则还原集群后,删除对应目录
rm -rf /etc/cni/net.d
然后重新初始化集群,导入网络尝试
集群搭建后,一直都是 NotReady状态.
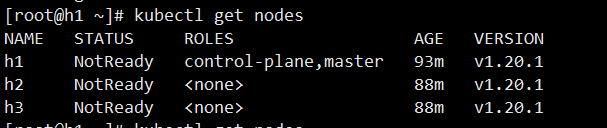
查看服务运行日志
systemctl status kubelet
发现报错
[root@h1 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Mon 2020-12-28 03:32:38 CST; 58min ago
Docs: https://kubernetes.io/docs/
Main PID: 4853 (kubelet)
CGroup: /system.slice/kubelet.service
└─4853 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/...
Dec 28 04:30:22 h1 kubelet[4853]: E1228 04:30:22.182069 4853 pod_workers.go:191] Error syncing pod f545cf52-cdc8-40c7-ae2f-a17ac7f9ee5e ("kube-flannel-ds-amd64-w6...
Dec 28 04:30:24 h1 kubelet[4853]: W1228 04:30:24.204378 4853 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 28 04:30:24 h1 kubelet[4853]: E1228 04:30:24.815311 4853 kubelet.go:2160] Container runtime network not ready: NetworkReady=false reason:NetworkPlu...initialized
Dec 28 04:30:29 h1 kubelet[4853]: W1228 04:30:29.205071 4853 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 28 04:30:29 h1 kubelet[4853]: E1228 04:30:29.823756 4853 kubelet.go:2160] Container runtime network not ready: NetworkReady=false reason:NetworkPlu...initialized
Dec 28 04:30:34 h1 kubelet[4853]: E1228 04:30:34.181219 4853 pod_workers.go:191] Error syncing pod f545cf52-cdc8-40c7-ae2f-a17ac7f9ee5e ("kube-flannel-ds-amd64-w6...
Dec 28 04:30:34 h1 kubelet[4853]: W1228 04:30:34.205888 4853 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 28 04:30:34 h1 kubelet[4853]: E1228 04:30:34.832340 4853 kubelet.go:2160] Container runtime network not ready: NetworkReady=false reason:NetworkPlu...initialized
Dec 28 04:30:39 h1 kubelet[4853]: W1228 04:30:39.206556 4853 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 28 04:30:39 h1 kubelet[4853]: E1228 04:30:39.840652 4853 kubelet.go:2160] Container runtime network not ready: NetworkReady=false reason:NetworkPlu...initialized
百度说错误是slave节点不能连接到Master节点.需要添加Flannel网络.
而我是先添加了nodes节点后添加的Flannel网络.
查看了下服务状态
[root@h1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7f89b7bc75-5bfcv 0/1 Pending 0 82m
coredns-7f89b7bc75-pxdrn 0/1 Pending 0 82m
etcd-h1 1/1 Running 2 82m
kube-apiserver-h1 1/1 Running 2 82m
kube-controller-manager-h1 1/1 Running 2 82m
kube-flannel-ds-amd64-7cqfv 0/1 Init:ErrImagePull 0 36m
kube-flannel-ds-amd64-rkjv2 0/1 Init:ErrImagePull 0 36m
kube-flannel-ds-amd64-w6s5n 0/1 Init:ErrImagePull 0 36m
kube-proxy-4tlp4 1/1 Running 2 77m
kube-proxy-rl7ft 1/1 Running 1 77m
kube-proxy-rm9r7 1/1 Running 2 82m
kube-scheduler-h1 1/1 Running 2 82m
发现flannel报错拉取镜像失败了
查看详细信息
kubectl describe pods kube-flannel-ds-amd64-w6s5n -n kube-system
部分错误截取
Normal Pulling 7m56s (x4 over 11m) kubelet Pulling image "quay.io/coreos/flannel:v0.12.0-amd64"
Warning Failed 7m16s (x4 over 10m) kubelet Error: ErrImagePull
Warning Failed 7m16s kubelet Failed to pull image "quay.io/coreos/flannel:v0.12.0-amd64": rpc error: code = Unknown desc = Error response from daemon: Get https://quay.io/v2/: dial tcp: lookup quay.io on 222.222.222.222:53: read udp 10.0.0.20:60768->222.222.222.222:53: i/o timeout
Normal BackOff 6m39s (x7 over 10m) kubelet Back-off pulling image "quay.io/coreos/flannel:v0.12.0-amd64"
Warning Failed 72s (x24 over 10m) kubelet Error: ImagePullBackOff
Warning Failed 19s kubelet Failed to pull image "quay.io/coreos/flannel:v0.12.0-amd64": rpc error: code = Unknown desc = Error response from daemon: Get https://quay.io/v2/: dial tcp: lookup quay.io on 222.222.222.222:53: read udp 10.0.0.20:44277->222.222.222.222:53: i/o timeout
Warning Failed 19s kubelet Error: ErrImagePull
Normal BackOff 19s kubelet Back-off pulling image "quay.io/coreos/flannel:v0.12.0-amd64"
Warning Failed 19s kubelet Error: ImagePullBackOff
Normal Pulling 7s (x2 over 59s) kubelet Pulling image "quay.io/coreos/flannel:v0.12.0-amd64"
下载quay.io/coreos/flannel:v0.12.0-amd64时候出错了.
讲道理说他会自动重新拉取,但是我等了一会也没有.决定手动下载
docker pull quay.io/coreos/flannel:v0.13.0-amd64
下载成功后可以删掉之前的pod,他会自动创建新的,再次创建的时候只要确保每个节点都存在镜像,就可以很快的启动了.
kubectl delete pods kube-flannel-ds-amd64-rkjv2 -n kube-system
如下,三个节点每个节点都会有一个Flannel的pod,等待pod启动成功后节点就正常了.
[root@h1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7f89b7bc75-5bfcv 1/1 Running 0 117m
coredns-7f89b7bc75-pxdrn 1/1 Running 0 117m
etcd-h1 1/1 Running 2 117m
kube-apiserver-h1 1/1 Running 2 117m
kube-controller-manager-h1 1/1 Running 2 117m
kube-flannel-ds-amd64-brwxn 1/1 Running 0 2m12s
kube-flannel-ds-amd64-w6s5n 1/1 Running 0 71m
kube-flannel-ds-amd64-wcnhf 0/1 Init:0/1 0 75s
kube-proxy-4tlp4 1/1 Running 2 112m
kube-proxy-rl7ft 1/1 Running 1 113m
kube-proxy-rm9r7 1/1 Running 2 117m
kube-scheduler-h1 1/1 Running 2 117m
[root@h1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
h1 Ready control-plane,master 117m v1.20.1
h2 Ready 113m v1.20.1
h3 NotReady 112m v1.20.1
因为我是三个节点,网络不佳下载太慢,是在一个节点下载完成后将镜像导出,复制到其他节点导入.
# 导出命令
docker save e708f4bb69e3 >flannel.tar.gz
然后将压缩文件复制到其他节点.
导入
docker load