kubernetes flannel 网络
docker网络基础
flannel通信
首先拥有一个k8s集群,安装了flannel网络.
此处使用一个三节点的集群作为测试使用.接下来准备基础环境
apiVersion: apps/v1 kind: Deployment metadata: labels: app: network-tools name: network-tools namespace: default spec: replicas: 3 selector: matchLabels: app: network-tools template: metadata: creationTimestamp: null labels: app: network-tools spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - network-tools topologyKey: kubenetes.io/hostname weight: 1 containers: - env: - name: SYSTEM_INFORMATION value: centos # 镜像内默认安装了部分网络相关命令 image: 528909316/check:debian_11 imagePullPolicy: Always name: network-tools ports: - containerPort: 9000 protocol: TCP resources: limits: cpu: 100m memory: 100Mi requests: cpu: 10m memory: 30Mi restartPolicy: Always创建了一个deployment资源,然后运行三个副本,同时让它们尽量避免在已运行一个pod的节点上运行,检查等待容器创建完成
[root@master ~]# kubectl get pod NAME READY STATUS RESTARTS AGE network-tools-66b6674fd9-pjpz6 1/1 Running 0 12m network-tools-66b6674fd9-tmgcs 1/1 Running 0 10m network-tools-66b6674fd9-zk58f 1/1 Running 0 11m接下来开始测试
XVLAN模式
XVLAN是Kubernetes导入flannel网络后默认采用的模式,VXLAN模式的设计思想是: 在现有的三层网络上覆盖一层虚拟的二层网络.使连接在这个二层网络中的设备可以向在一个局域网内的物理机那样使用mac地址来进行通信,尽管这些节点可能不在一个物理主机.
首先查看下每个pod的IP地址:
[root@master ~]# kubectl get pod -o wide |grep "network"
network-tools-66b6674fd9-pjpz6 1/1 Running 0 14m 10.244.0.5 master <none> <none>
network-tools-66b6674fd9-tmgcs 1/1 Running 0 13m 10.244.2.13 worker2 <none> <none>
network-tools-66b6674fd9-zk58f 1/1 Running 0 13m 10.244.1.17 worker1 <none> <none>
三个IP分别为:10.244.0.5,10.244.2.13,10.244.1.17.
接下来,查看一下每个pod的路由表:
[root@master ~]# for i in `kubectl get pod |grep "network"|awk '{print $1}'`;do echo "--- $i ---";kubectl exec -it $i -- route -n;done
--- network-tools-66b6674fd9-pjpz6 ---
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.0.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
10.244.0.0 10.244.0.1 255.255.0.0 UG 0 0 0 eth0
--- network-tools-66b6674fd9-tmgcs ---
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.2.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.2.1 255.255.0.0 UG 0 0 0 eth0
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
--- network-tools-66b6674fd9-zk58f ---
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
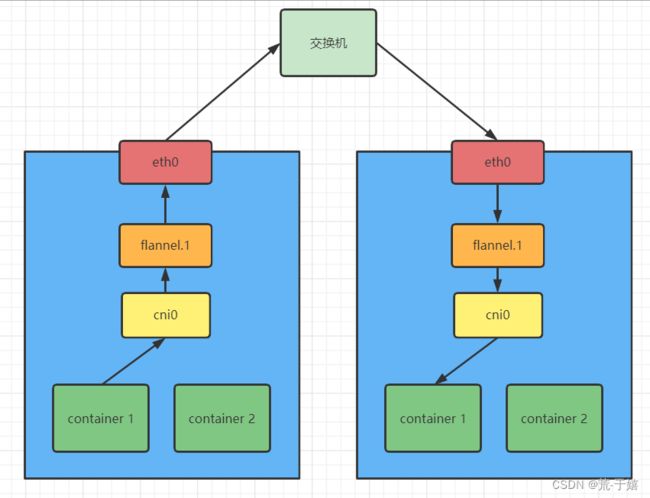
预备知识: 在Kubernetes网络模型中,Kubernetes使用一个叫做cni的组件替换掉了docker0网桥,而cni实际也是一个网桥,在主机上可以通过命令ifconfig来查找对应的cni网桥.
接下来现在master节点主机执行命令,查看一个叫做cni0的网卡设备的信息:
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255
inet6 fe80::f03d:adff:fea2:563e prefixlen 64 scopeid 0x20<link>
ether f2:3d:ad:a2:56:3e txqueuelen 1000 (Ethernet)
RX packets 1495391 bytes 200119046 (190.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
同时找到运行在对应节点上的pod里的路由表:
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.0.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
10.244.0.0 10.244.0.1 255.255.0.0 UG 0 0 0 eth0
首先来看第一条路由,匹配IP为0.0.0.0,掩码也是0.0.0.0,这是一条默认路由.也就是说如果pod要访问公网的话就会匹配这一条路由发送出去了,而他的网关IP是:10.244.0.1,也就位于上面所查询到的cni0的这个设备(这不和docker0作用完全一样嘛).
也就是如果一个数据包要发往公网的话,会匹配第一条路由,然后通过eth0网卡发送出去,目的MAC地址自然就是cni0的,然后cni0负责将其转发出去.
flannel使用了"子网"的方式来实现跨主机的容器通信,所谓的"子网"就是给每个加入节点的主机分配一个"网段",比如第一个主机分配的是
10.244.0.0/24这个网段,这个节点运行的容器就只能使用这个网段内的IP,然后第二个节点分配的就是10.244.1.0/24网段,第三个节点就是10.244.2.0/24,以此类推…
假设位于master节点的pod,对worker1节点的pod发起了通信即从10.244.0.5前往10.244.1.17,容器自己打好一个 “IP包”,即包含自己的IP地址和对端的IP地址.
数据包匹配路由表后命中第三条路由,通过eth0网卡发出前往IP10.244.0.1的 cni0网桥.从cni0的网桥流出后来到主机节点,至于下一步要去哪,就要取决于主机的路由表了.
[root@master ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.88.8.254 0.0.0.0 UG 100 0 0 ens192
10.88.8.0 0.0.0.0 255.255.252.0 U 100 0 0 ens192
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
IP10.244.1.17和第四条路由明显更加匹配,他的网关是10.244.1.0,所以根据此条路由发出数据包.
但是数据包并没有从主机的eth0网卡发出,因为路由表最后一列表示这条路由要从一个flannel.1的设备发出.
就这样数据包被丢给了flannel.1的虚拟设备.接下来flannel.1就会对这个数据包进行封装,以便于将他发往另一个主机的flannel.1设备.
因为flannel VXLAN是在三层网络上覆盖了一个二层网络(可以把每个flannel.1想象成一个物理网络中的一个物理机),所以如果想在一个二层网络发送出去让对端的flannel.1接收到这个数据包,那么就需要两个条件:自己具有一个mac地址,同时知道对方的mac地址.
但是如何知道对方flannel.1的mac地址?flannel在启动后注册到集群的时候,自动在其他节点上添加一个自己的IP网段和对应的mac地址关系.查看地址:
[root@master ~]# ip neigh show dev flannel.1
10.244.2.0 lladdr 3a:52:50:cc:04:78 PERMANENT
10.244.1.0 lladdr 4e:96:27:73:dd:86 PERMANENT
里面有两条规则,分别是两个worker节点的网段和mac地址,因为如果是自己主机的话直接走直连规则即可所以每个节点都只有其他节点的对应关系而没有自己的.
知道了对端的mac地址,flannel.1会对pod发出的IP包在进行一次二层mac地址数据帧封装.
接下来,数据包会被传递给主机,主机接收到这个特殊的包会给他添加一个表示,增加一个VIN号码,表示这是一个VTEP设备所发出的.
但是flannel.1只添加了对端的flannel设备的mac地址,并没有对方主机的IP和mac地址,所以主机要对这个包进行发出前的最后一次处理 即根据已知的对方flannel.1的mac地址查询对端宿主机的IP地址.
flannel使用了一个fdb的数据库来存储这些对应关系,查看命令如下:
[root@master ~]# bridge fdb show flannel.1|grep "flannel.1"
3a:52:50:cc:04:78 dev flannel.1 dst 10.88.10.183 self permanent
4e:96:27:73:dd:86 dev flannel.1 dst 10.88.10.182 self permanent
随后查到10.88.10.182这个IP地址,接下来就是一个主机之间正常通信发送数据包的封装,根据IP地址进行arp获取对方主机的mac地址,系统在原有的flannel封装的二层数据帧上 再套一层实际物理网络传输的二层数据帧,不过这次填写的是对端宿主机的mac地址,这个地址就是给交换机看的了,然后数据包就像一个正常的网络包一样发出.
对端宿主机接收到这个包后拆包,根据VIN号码他知道这是一个虚拟设备,然后丢给flannel.1,flannel.1在拆包后通过cni0转发进pod中.
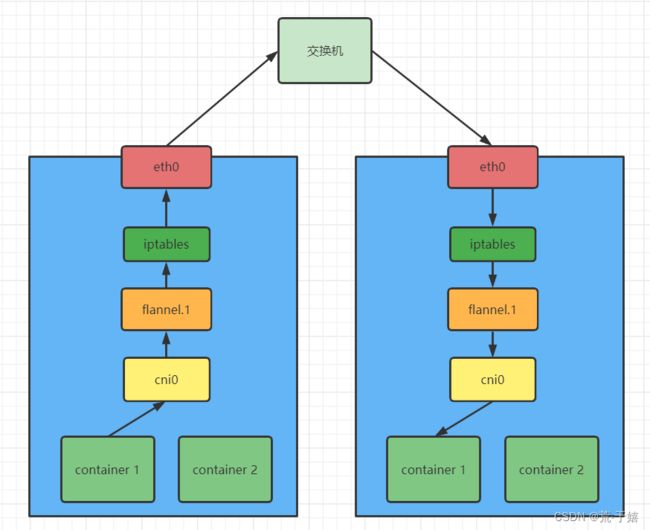
数据包对方确实接收到了,但是Kubernetes网络中还缺少两个重要组件: kube-proxy和iptables(或ipvs).
Kube-proxy
先来介绍kube-proxy,它实际上就是一个负载均衡的管理器,并不负责转发什么流量.他接受Kubernetes集群的网络策略(如新增了一个Service或者新增了一个networkpolicies,他就在自己对应的节点添加iptables或者ipvs的规则.所以实际起作用的是iptables.)
iptables(ipvs)
两者都是Linux中自带的网络相关的服务.iptables实际是一个防火墙,不过他能添加对应的转发规则.而ipvs则完全是一个转发服务,所以在大规模集群中ipvs的性能会比iptables要好很多.
而iptables位置是在网卡之后,用户态进程之前的一组策略规则.换算到上面的流程,就是在数据包进入宿主机的eth0网卡后,这时候iptables会针对于规则进行对应的处理,如果使用了networkpolicies屏蔽次包那么则丢弃,如果都允许放行了,那么则继续虚拟网络交由flannel.1转发到pod.
同样,Service也是依靠他实现的.Service会对应endpoints,而endpoints才是实际的pod的IP,所以如果master节点的pod对一个Service发起了请求,他的请求同样来到对应节点,从网卡进入后开始iptables匹配,负载均衡就是在此处实现的,iptables就可以开始匹配目标IP(Service本身也会具有一个IP),发现这个包是发送给service的就会匹配到对应的service的规则.
而service的规则无非就是接收service自己IP的数据包,然后转发到pod的IP上面,所以iptables会进行一个DNAT,也就是修改目标IP地址为pod的IP地址,然后重新发出.
但是如果数据包是pod发送给service的话,service会修改每个node节点的iptables规则.也就是数据包离开了cni设备后,会被对应节点的iptables修改掉目标IP,然后重新发出去.
所以Kubernetes中endpoints的IP池实际是添加在每个节点的iptables上的,实际的负载均衡和网络拦截等规则都是iptables来处理的.
参考文章:
《深入剖析Kubernetes》-张磊