【Python】可视化案例一——折线图的开发
目录
前言
步骤一——数据处理
1.读取文件中的数据
2.修正给出的JSON数据类型
3.JSON数据格式转Python字典操作
4.从数据容器中取出你想要的数据
步骤二——绘制图表
整体代码以及运行示例
总结
前言
Python语言在处理大数据方面具有很强悍的能力。面对海量的数据,我们根本无法通过去阅读一条一条的数据来进行分析,很多时候我们需要将海量的数据处理成我们肉眼可以进行分析的形式。对于肉眼来说,通过图表的形式来进行数据的分析往往是效率比较高的。因此,利用Python处理大数据的能力与将数据进行可视化相结合无疑是相得益彰的。
对于数据的可视化,可以分为两个步骤:
- 数据处理:包括对文件的读取、检查是否符合JSON规范以及规范化、JSON格式的转化等;
- 绘制图表:对于本案例来说就是,设置图像的x,y轴、设置全局选项(标题、工具箱等)。
注:本篇文章针对的读者是入门级的Python选手,如果是小白的话呢,推荐b站先进行入门级的学习再来阅读哦。
步骤一——数据处理
本案例的数据百度网盘链接如下:
https://pan.baidu.com/s/1SSBzsJ2wukNTuO1XcU-MQQ
提取码:qpdt
1.读取文件中的数据
首先第一步就是要从文件中把数据读取出来,Python内置的库函数有open函数(打开文件)以及read函数(读取文件内容),读取文件之后,读者可自行用print函数验证一下是否读取成功。代码示例如下:
# 处理数据,将JSON数据用python进行处理
f_us=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\美国.txt","r",encoding="UTF-8")
us_data=f_us.read() # 美国的疫情数据
f_jp=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\日本.txt","r",encoding="UTF-8")
jp_data=f_jp.read() # 日本的疫情数据
f_in=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\印度.txt","r",encoding="UTF-8")
in_data=f_in.read() # 印度的疫情数据2.修正给出的JSON数据类型
注意到,我们给出的数据实际上是JSON类型的数据。回顾一下,JSON类型的数据格式就相当于Python中的字典(格式为:{"key":data})。我们首先就要验证一下给出的数据是否符合JSON数据类型的规范,如果不符合则要通过代码来进行修正。我们选择美国的数据作为示例:

我们可以看到,数据的开头和末尾都出现了不符合规范的地方。因此,我们需要将开头和末尾不合规范的地方删除才能成为符合规范的JSON数据,才能被Python使用。要实现如上操作,只需要调用repalce函数以及利用数据容器的切片功能。代码如下:
# 去掉不合规范的JSON的开头和结尾
us_data=us_data.replace("jsonp_1629344292311_69436(","") # 去除开头,将不规范处用空来replace
us_data=us_data[:-2] # 去除结尾,-2代表倒数第二个
jp_data=jp_data.replace("jsonp_1629350871167_29498(","")
jp_data=jp_data[:-2]
in_data=in_data.replace("jsonp_1629350745930_63180(","")
in_data=in_data[:-2]3.JSON数据格式转Python字典操作
下一步就是将JSON数据格式转化为我们Python能识别的数据格式,代码如下:
# JSON转python字典操作
us_dict=json.loads(us_data) # 美国
jp_dict=json.loads(jp_data) # 日本
in_dict=json.loads(in_data) # 印度4.从数据容器中取出你想要的数据
下面,就来到本案例的关键之处了,我们很多时候并不是需要所有的数据,对于给出的数据我们往往只需要一部分。那么,当你打开数据文件你会发现,你根本无法看出数据的逻辑,更谈不上从数据容器中取出你想要的数据。所以,我们需要借助一些工具来辅助我们处理这些数据。这里给出一个网站:JSON在线视图查看器(Online JSON Viewer)
具体操作流程为(以美国的数据为例):
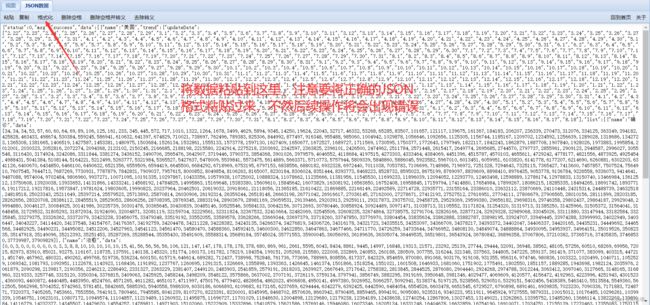


在本案例中,我们需要绘制一个简单的疫情折线图,要求是显示出三个国家的确诊病例数和日期的关系。也就是在2020年中,确诊人数随每日的变化。因此,我们需要取出2020年的日期以及三个国家在2020年中每天的确诊人数。我们还是需要通过JSON在线视图查看器来帮助我们找到数据。
同样以美国为例,代码如下:
# 获取Trend key
us_trend_data=us_dict['data'][0]['trend']
jp_trend_data=jp_dict['data'][0]['trend']
in_trend_data=in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data=us_trend_data['updateDate'][:314]
jp_x_data=jp_trend_data['updateDate'][:314]
in_x_data=in_trend_data['updateDate'][:314]
# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data=us_trend_data['list'][0]['data'][:314]
jp_y_data=jp_trend_data['list'][0]['data'][:314]
in_y_data=in_trend_data['list'][0]['data'][:314]至此,数据处理步骤完成了。
步骤二——绘制图表
关于绘制图表操作,就简单了许多。稍加复习一下Python的绘制折线图的操作,包括一些库函数 的调用就能很轻松的完成。
注:本案例绘制折线图所引用的包是pyechart(Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。)
该包的官方网址是:pyecharts - A Python Echarts Plotting Library built with love.
有兴趣的同学可以在网址中研究研究吧
代码示例如下:
#生成图表
line=Line() # 创建折线图对象
# 创建x轴数据
line.add_xaxis(us_x_data) # x轴是日期的,所以只需要一个国家的数据即可
#创建y轴数据
line.add_yaxis("美国确诊人数",us_y_data,label_opts=LabelOpts(is_show=False)) # 添加美国的数据
line.add_yaxis("日本确诊人数",jp_y_data,label_opts=LabelOpts(is_show=False)) # 添加日本的数据
line.add_yaxis("印度确诊人数",in_y_data,label_opts=LabelOpts(is_show=False)) # 添加印度的数据
# 设置全局选项
line.set_global_opts(
# 添加标题
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图",pos_left="center",pos_bottom="1%")
)
# 调用render方法,生成图表
line.render()最后别忘了关闭文件哦:
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()整体代码以及运行示例
注:代码的开头引用了一系列的包,如果未安装则程序无法运行。如果对代码中所引用的包的功能不清楚,请自行百度。
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LabelOpts
# 处理数据,将JSON数据用python进行处理
f_us=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\美国.txt","r",encoding="UTF-8")
us_data=f_us.read() # 美国的疫情数据
f_jp=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\日本.txt","r",encoding="UTF-8")
jp_data=f_jp.read() # 日本的疫情数据
f_in=open("D:\学习资料\pythan\资料\可视化案例数据\折线图数据\印度.txt","r",encoding="UTF-8")
in_data=f_in.read() # 印度的疫情数据
# 去掉不合规范的JSON的开头和结尾
us_data=us_data.replace("jsonp_1629344292311_69436(","") # 去除开头
us_data=us_data[:-2] # 去除结尾
jp_data=jp_data.replace("jsonp_1629350871167_29498(","")
jp_data=jp_data[:-2]
in_data=in_data.replace("jsonp_1629350745930_63180(","")
in_data=in_data[:-2]
# JSON转python字典操作
us_dict=json.loads(us_data)
jp_dict=json.loads(jp_data)
in_dict=json.loads(in_data)
# 获取Trend key
us_trend_data=us_dict['data'][0]['trend']
jp_trend_data=jp_dict['data'][0]['trend']
in_trend_data=in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data=us_trend_data['updateDate'][:314]
jp_x_data=jp_trend_data['updateDate'][:314]
in_x_data=in_trend_data['updateDate'][:314]
# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data=us_trend_data['list'][0]['data'][:314]
jp_y_data=jp_trend_data['list'][0]['data'][:314]
in_y_data=in_trend_data['list'][0]['data'][:314]
#生成图表
line=Line() # 创建折线图对象
# 创建x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
#创建y轴数据
line.add_yaxis("美国确诊人数",us_y_data,label_opts=LabelOpts(is_show=False)) # 添加美国的数据
line.add_yaxis("日本确诊人数",jp_y_data,label_opts=LabelOpts(is_show=False)) # 添加日本的数据
line.add_yaxis("印度确诊人数",in_y_data,label_opts=LabelOpts(is_show=False)) # 添加印度的数据
# 设置全局选项
line.set_global_opts(
# 添加标题
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图",pos_left="center",pos_bottom="1%")
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()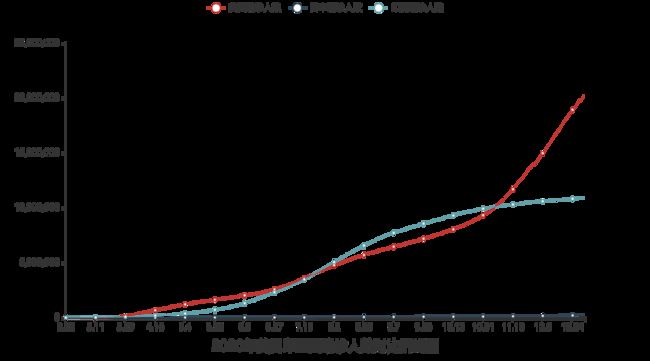
总结
通过本案例,我们可以对Python一系列操作进行巩固,包括:
- 包的引入以及应用
- 文件的打开以及读取
- JSON数据类型的处理异常(replace和切片操作)以及转化为Python字典
- Python的字典内容的读取操作以及字典的切片
- 折线图的生成的相关操作
- 处理JSON数据的网站以及pyechart的官方网址