深度复杂空间结构运算的逻辑
一,空间地址的逻辑使用
地址在C/C++程序中每次是以系统开辟空间的首个地址来表现的,而数据的类型决定了地址的一次性跳转,系统在输出时也就是根据其一次性跳转的地址来解用其数据的。例如以下:
#include
int main()
{
int a = 5;
fprintf(stdout, "%p\n", &a);//输出0099FC78地址
fprintf(stdout, "%p\n", &a + 1);//输出0099FC7C地址
}
从以上代码可得出,当数据开辟一块空间时,地址是先指向开辟内存开始位置的地址,而输出或引用时,系统都是从空间的开始地址找起,然后根据类型所申请的空间大小进行一次性的输出,例如:int一次性输出4个字节,char一次性输出1个字节;int型地址一次性直接跳过4字节,char型地址一次性跳过1字节。注意,地址在内存中表现为一个地址表示一个字节的大小。一次跳过n个字节,也就是一次性跳过4个地址。代码如下:
#include
int main()
{
int a = 0x02040608;//以十六进制来赋值方便后面的查看
char* c = (char*)&a;//将转换成char类型输出,一次将从跳动4字节转成跳动1字节
fprintf(stdout, "%x\n", a);//输出2040608
fprintf(stdout, "%d %d %d", *c, *(c + 1), *(c + 2));//输出8 6 4
return 0;
}
代码分析如图:
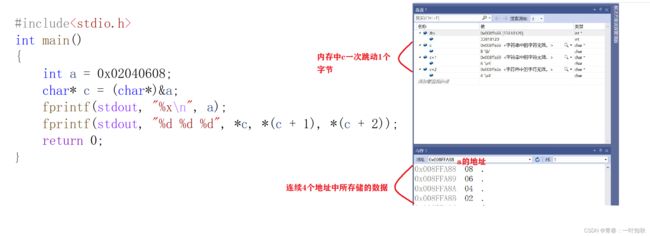
其它数据类型也都是同样道理,无论是在栈区还是堆区抑或是静态区,都是同理使用。在以后的跟为复杂的空间使用,一般都会用以上跟为复杂的空间转换,而要想炉火纯青的运用,必须要把指针的知识点深入掌握,之前的讲解已经详细说明,在这里我就不做过多讲解了。
二,函数的地址使用
1,函数栈帧的原理
当我们调用函数时,系统会在内存划分中的栈区里划分一块函数栈帧,这块函数栈帧就是存储函数整个框架以及函数里的参数,当函数传参的时候,形参只是在函数栈区中对实参的临时拷贝,两者占用两块不同的内存空间。
在此,要提醒的是,既然是在栈区里开辟空间,即一但函数结束后,函数栈帧就会被系统自动销毁,在进行使用函数时一定要考虑此因素。下面的代码将会说明这一点:
#include
char* GetMemory(void)
{
char p[] = "hello world";
return p;
}
void Test(void)
{
char* str = NULL;
str = GetMemory(void);
printf(str);//将会错误输出
}
int main()
{
Test();
return 0;
}
输出图:
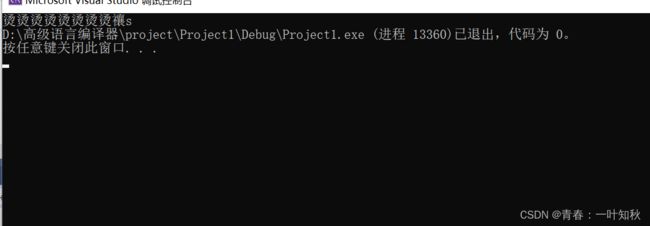
出现以上这种莫名其妙的输出问题在于GetMemory()函数。GetMemory()函数返回类型是一个char指针型,但是当开始调用此函数时,系统先会在栈区中开辟一块函数栈帧,以便存方函数中的给中数据,一但出了函数,系统将自动销毁这块函数栈帧,里面的数据也就随之销毁了。GetMemory()函数返回数组p的首元素地址时,Test()函数中的str接受地址,但要注意的是,GetMemory()函数的栈帧及数据已被销毁,此地址中已没有了原先的数据,将会错误输出。如图:
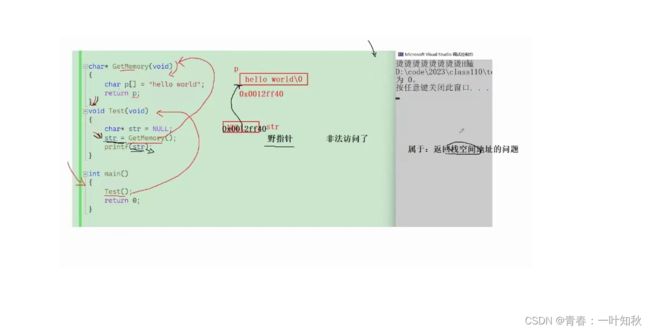
所以,在栈区存放函数的数据不可在另一函数中调用,然而,若我们要想利用函数中的数据,就不能在栈区中存放,首先要考虑的就是如何把要利用的数据放入其他内存区域中。static关键字可把数据放入堆区中,可能有些学者已经听说过此名称,static运用的数据之所以不会销毁数据正是因为放入堆区的数据只有自己操作或整个程序结束时才得以释放。因此,以上代码经修改后如下:
#include
char* GetMemory(void)
{
static char p[] = "hello world";//系统将会在堆区中存放,数据不会被销毁
return p;
}
void Test(void)
{
char* str = NULL;
str = GetMemory();
printf(str);
}
int main()
{
Test();
return 0;
}
运行图:
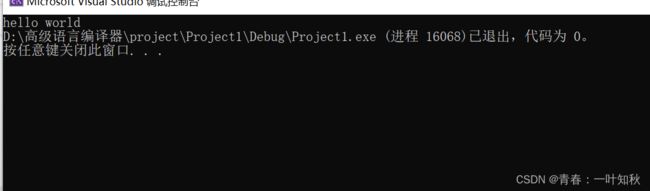
2,动态内存的运用
动态内存在系统内存中是存储在堆区的,但需提醒的是,在当下学习中到慎重利用堆区,利用完堆区的数据之后要记得用free函数来释放,虽然在当下的练习中可能不会有太大影响,但在以后的程序设计中,我们可能会利用较大的系统空间,如若每次调用堆区空间不及时释放,则将会浪费很大内存空间。
开辟动态内存空间,通常使用一级指针变量并运用函数malloc,calloc,realloc三个函数。而此时的一级指针直接指向开辟空间的首个地址。接下来请观察以下代码:
#include
#include
void GetMemory(char* p)
{
p = (char*)malloc(100);
}
void Test(void)
{
char* str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
int main()
{
Test();
return 0;
}
首先,要说明问题的是,上面的代码会出现系统崩溃,GetMemory函数返回后,str仍为NULL,即无法GetMemory函数无法将p开辟的100个字节从中带出来。我们先来观察Test函数,当str向GetMemory函数传参时,形参p将会重新开辟一块空间以进行临时拷贝,此时的p与str一样,都存放NULL。当p动态开辟完空间时,将会退出函数GetMemory,此时虽然函数栈帧将随之销毁,但动态空间依然存在,即p指向开辟空间的首个地址,而此时形参没有影响到实参,虽说两者都是指针类型,但都是指向不同空间,str指向NULL。
这一关系可能有一点难度,但其实可以这样理解,p刚开始的时候是NULL,后来指针变量p有赋予了新的地址,这个地址就是新开辟的动态内存空间的起始地址。如图所示:
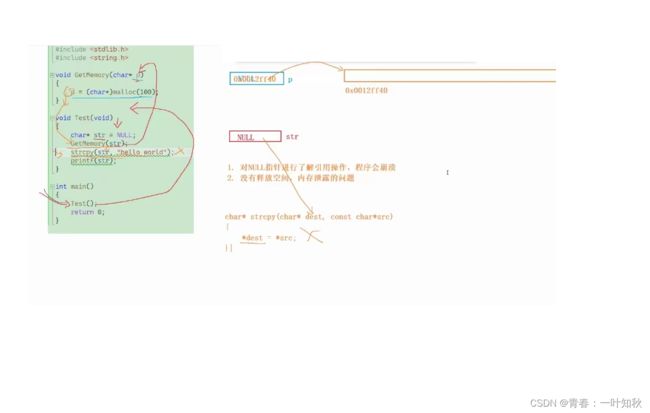
以上代码要想正常按照逻辑使用要进行以下改正:
#include
#include
#include
//在动态内存中,一级指针只是直接指向开辟空间,二维指针是指向地址的地址
void GetMemory(char** p)
{
*p = (char*)malloc(100);
}
void Test(void)
{
char* str = NULL;
GetMemory(&str);
strcpy(str, "hello world");
printf(str);
free(str);
str = NULL;
}
int main()
{
Test();
return 0;
}
当我们用二级指针进行传参时,直接传向str的地址,然后通过解引用直接找到str指向空间进行开辟,这种操作与函数通过地址来进行数据更改的道理是一样的,因此,在程序运行上将不会出现任何问题。
三,空间地址的跳动与转换
1,地址的跳动变换
首先,要提醒的是,平常说的数组名等于首元素的地址,但是有特殊情况,“&数组名”代表的是整个数组的地址,"sizeof(数组名)"也代表整个数组的地址,而"sizeof(数组名+0)"不是整个数组的地址,只是访问数组元素的地址。除了这两个情况外,其余情况数组名都代表首元素的地址。
首先,我们运用一维数组来观察特性:
#include
int main()
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));//16
//注意:只有在sizeof(数组名),里面只有数组名时才等于整个数组的地址
//当sizeof()里的参数有其他东西时,就不等于数组的全部地址了,按正常理解即可
printf("%d\n", sizeof(a+0));//是首元素的地址,即4/8
printf("%d\n", sizeof(*a));//此时a为首元素的地址,解引用为首元素,为4
printf("%d\n", sizeof(&a));//为数组的地址,大小为4/8
//*(解引用操作符)和&(取地址)操作符“相反”
//两者抵消后sizeof(*&a)==sizeof(a),及大小为16
printf("%d\n", sizeof(*&a));//16
printf("%d\n", sizeof(&a+1));//注意,&a+1仍为地址,大小为4/8
return 0;
}
然后,用二位数组来观察,有关细节代码和分析如下:
#include
int main()
{
int a[3][4] = { 0 };
fprintf(stdout, "%d\n", sizeof(a));//3*4*4=48字节
//注意:在二维数组中,可看成其元素是一维数组
//即a[0]代表第一行一维数组的数组名
fprintf(stdout, "%d\n", sizeof(a[0]));//大小为16字节
fprintf(stdout, "%d\n", sizeof(a[0]+0));//即第一行数组名的首地址,为4字节
//a+1是直接跨越了一个一维数组,即从第二行开始,表第二行数组的地址
fprintf(stdout, "%d\n", sizeof(a + 1));//4/8字节
//*(a+1)等效于a[1],即第二行一维数组的数组名
fprintf(stdout, "%d\n", sizeof(*(a + 1)));//大小为16字节
//&a[0]==(a+0),即&a[0] + 1 == a + 1
fprintf(stdout, "%d\n", sizeof(&a[0] + 1));//第二行数组的地址,为4/8字节
fprintf(stdout, "%d\n", sizeof(*(&a[0] + 1)));//即第二行数组,大小为4*4=16
return 0;
}
2,地址的转换使用
上面,我们已经明白了普通地址的之间转换时什么情况,但是当输出地址访问的空间与数据类对应的空间出现差异的话,运行起来将会出现不一样的输出。这种情况跟系统的大小字节端存储有关,在计算机中,一般都是用小字节端存储的,在这里,我也用小字节端来运用。
首先,来观察以下代码:
#include
#include
int main()
{
int a[4] = { 1,2,3,4 };
int* p1 = (int*)(&a + 1);
//计算机以小端的形式的存储的情况,此时p2指针为int型,解引用将会访问4字节
//但是转换成(int)a+1即数值加一,转换成指针后要以大小字节端进行观察
int* p2 = (int*)((int)a + 1);
fprintf(stdout, "%x, %x", p1[-1], *p2);//输出4和02000000
return 0;
}
对于p1[-1]的输出就简单了,当整个数组的地址加1后就直接跳过整个数组的地址了,所以p[-1]将访问数组的最后的那个元素。对于*p2的观察,我们先要看(int)a + 1,当首元素地址加1时将会跳到下一个字节所对应的地址,在小端存储时,a[0]数据对应4个字节,也就是一次性跳动4个地址,这四种地址对应数据为01 00 00 00,再往后对应的为02 00 00 00,当首元素加1后的4个地址所对应的数据为00 00 00 02,即最终输出。
有了以上的知识后,我们看以下代码,提醒一下:因为常量数据在内存中是以补码形式存储的,所以直接输出常量地址会以补码的十六进制形式输出。
#include
int main()
{
int a[5][5];
int(*p)[4] = a;//此时p为数组指针,加1直接跳过4个元素的地址,即跳过一个数组
fprintf(stdout, "%p %d", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
指针与指针相减等于元素个数,两者之间相差4个元素,即小减大为-4,而-4在内存中是以补码形式存储的,数值的%p是直接将其补码当作地址展示出来,所以,以-4的补码的十六进制形式输出