《Communication-Efficient Learning of Deep Networks from Decentralized Data》
Communication-Efficient Learning of Deep Networks from Decentralized Data
这篇文章算是联邦学习的开山之作吧,提出了FedAvg的算法,文中对比了不同客户端本地训练次数,客户端训练数据集划分的影响。
0. Abstract
现代移动设备可以获取大量适合学习模型的数据,然而,这些丰富的数据通常是隐私敏感的、数量很大的,这可能导致无法记录到数据中心并使用传统方法进行培训。本文提倡一种替代方案,将训练数据分布在移动设备上,并通过聚合本地计算的更新来学习共享模型,称为联合学习。
本文在五种模型四个数据集下测试了联邦学习的效果。
1. Introduction
每个客户端都有一个从未上传到服务器的本地训练数据集。相反,每个客户端计算一个对服务器维护的当前全局模型的更新,并且只有这个更新才会被通信。
主要贡献
1)确定了移动设备上分散数据的训练问题作为一个重要的研究方向;
2)选择一个简单实用的算法,可以应用于这一设置;
3)对所提出的方法进行了广泛的实证评估。更具体地说,我们引入了FederatedAveraging算法,它将每个客户端的局部随机梯度下降(SGD)与执行模型平均的服务器相结合。对该算法进行了大量的实验,证明了该算法对不平衡和非iid数据分布具有鲁棒性,并且可以将在分散数据上训练深度网络所需的通信次数减少几个数量级。
联邦学习的理想问题有以下属性:
1)在移动设备上进行的训练比在数据中心中通常可用的代理数据上进行的训练具有明显的优势。
2)这些数据是隐私敏感的或大的(与模型的大小相比),所以最好不要纯粹为了模型训练的目的而将其记录到数据中心(服务于集中收集原则)。
3)对于监督任务,数据上的标签可以从用户交互中自然地推断出来。
隐私安全:与持久数据上的数据中心培训相比,联邦学习具有明显的隐私优势。
联邦优化:我们将联邦学习中隐含的优化问题称为联邦优化,它与分布式优化建立了联系(并形成对比)。联邦优化与典型的分布式优化问题有几个关键的区别:
- 非独立同分布:标签分布不均
- 不平衡:样本数量不同
- 大规模
- 通信约束:移动设备经常离线,或者连接速度慢或费用高。
我们的目标是使用额外的计算,以减少训练模型所需的通信轮数。有两种主要的方法可以增加计算量:1)增加并行性,在每个通信轮之间我们使用更多的客户端独立工作;2)增加了每个客户端的计算量,每个客户端在每个通信轮之间执行一个更复杂的计算,而不是执行一个简单的计算,比如梯度计算。我们研究了这两种方法,但我们实现的加速主要是由于在每个客户机上增加了更多的计算量,一旦使用了客户机上的最小并行度。
2. FedAvg
我们在每一轮中选择一个客户端的Cfraction,并计算这些客户端所持有的所有数据的损失梯度。因此,C控制全局批量大小,C = 1对应的是全批量(非随机)梯度下降我们将此基线算法称为FederatedSGD(或federdsgd)。
FedAvg计算量由三个关键参数控制:C,每轮执行计算的客户端的比例; E,每个客户端在每一轮中对其本地数据集进行训练的次数; 和B,用于客户端更新的本地minibatch大小。 我们写b=∞来表示整个局部数据集被视为单个小批处理。 因此,在该算法族的一个端点上,我们可以取b= ∞ \infty ∞和e=1,这正好对应于FEDSGD。
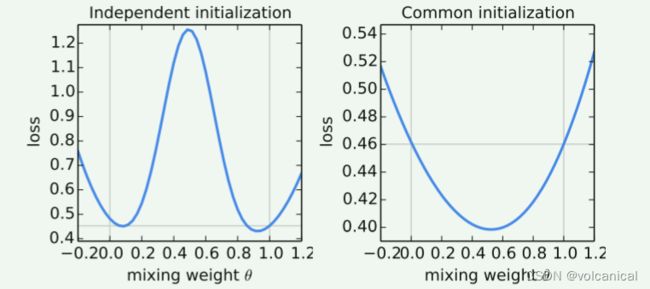
θ \theta θ是两个模型的聚合参数,聚合权重一个是 θ \theta θ一个是 1 − θ 1-\theta 1−θ,根据实验结果图我们可以发现,如果两个模型的初始模型参数不同,使用平均聚合0.5的结果不是很好,反而单独使用一个模型的权重, θ \theta θ接近0或者1反而更好。但是如果两个模型初始化使用相同的模型参数,那么使用0.5进行聚合的结果就会比较好。

FedAvg算法分为客户端的服务器两块,客户端就是简单地本地训练,这里训练首先划分了一个batch的大小,batch集合为 B \mathcal{B} B,然后客户端需要迭代E轮,那样客户端就总共需要循环 E ∗ n k B E*\frac{n_k}{B} E∗Bnk次。服务器负责选中随机客户端,并且下发全局模型并且等待客户端返回更新结果,这里的更新权重是以客户端本地的数据量来决定的,客户端本地的数据量越多,FedAvg聚合时所占的权重也就越大。
3. Experiment
实验设置:初步研究包括两个数据集上的三个模型族。前两个是MNIST数字识别任务[26]:
1)一个简单的多层感知器,有2个隐藏层,每个层有200个单元,使用ReLu激活(总共199,210个参数),我们称之为MNIST 2NN。
2)有两个5x5卷积层的CNN(第一个是32个通道,第二个是64个,每个都有2x2 max pooling),全连接层有512个单元,ReLu激活,最后有softmax输出层(总共1663370个参数)。
研究了在客户端上划分MNIST数据的两种方法:IID,数据被洗牌,然后划分为100个客户端,每个客户端接收600个示例,以及Non-IID,按照数字标签对数据排序,将其划分为200个大小为300的分片,并为100个客户端分配2个分片。这是一种病态的非iid数据分区,因为大多数客户机将只有两个数字的示例,这让我们可以探索我们的算法在高度非iid数据上的破坏程度。
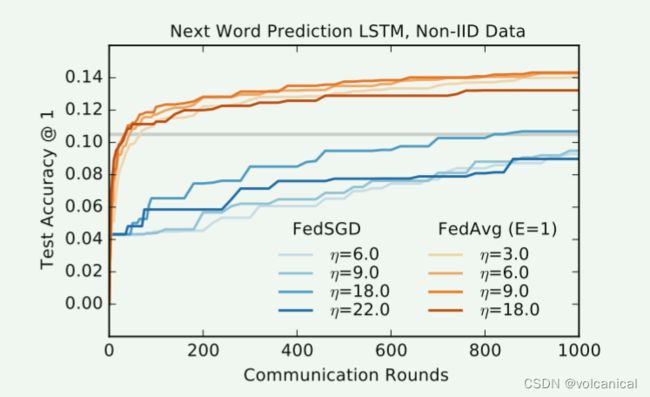
对于语言建模,我们从莎士比亚全集[32]构建了一个数据集。生成包含1146个客户机的数据集。对于每个客户,我们将数据分解为一组训练线(角色的前80%的线)和测试线(最后的20%,四舍五入到至少一行)。同样分为IID和non-IID的两组数据,使用的模型为LSTM。
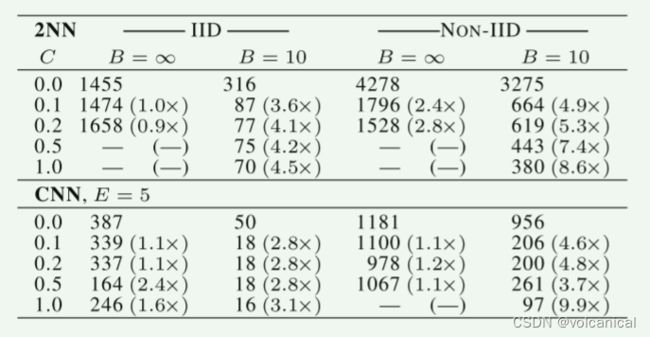
对于b= ∞ \infty ∞(对于MNIST每轮处理所有600个客户机示例为一个批次),在增加客户机部分方面只有很小的优势。 使用较小的批处理大小b=10显示了使用c≥0.1的显著改进,尤其是在非IID情况下。 基于这些结果,在我们剩下的大部分实验中,我们确定C=0.1,这在计算效率和收敛速度之间取得了很好的平衡。 比较表1中b= ∞ \infty ∞和b=10列的轮数,可以看到显著的加速,我们接下来将对此进行研究。

在本节中,我们将C=0.1,并在每一轮中为每个客户机添加更多的计算量,或者减少B,或者增加E,或者两者兼而有之。我们根据这个统计信息对表中每一部分的行进行排序。 我们看到,通过改变e和b来增加u是有效的。
通过实验结果可以看出,增大客户端本地训练迭代次数,减少batch的大小可以有效地加大客户端本地的计算时长,同时也可以带来更大的训练加速,在更少的大轮次内达到收敛的效果。
准确率曲线图
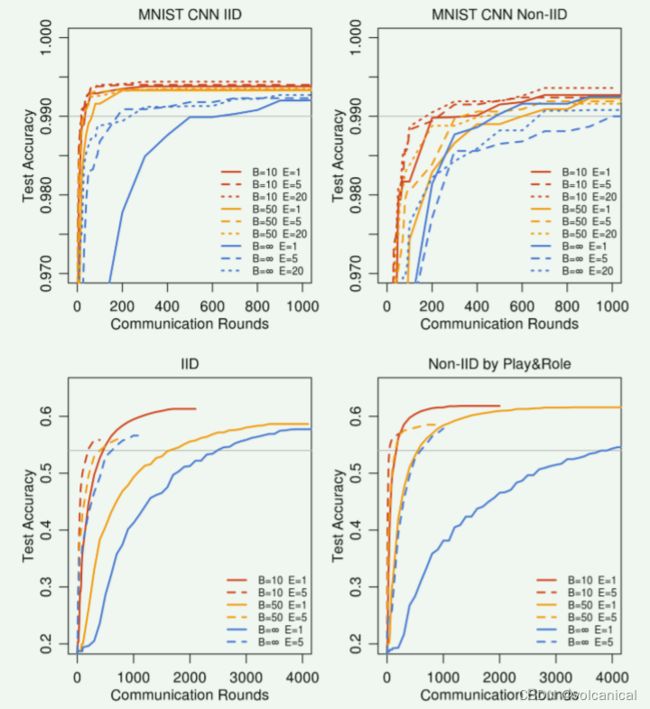
在CIFAR10数据集上作者还与SGD进行了对比,这里的SGD但就是对集中式机器学习,并以此作为基线。(其实我觉得这有点不公平,这就是分布式机器学习和集中式机器学习对比了,效率肯定吊打单机学习)

在LSTM上结果相同
4. Conclusion
我们的实验表明联邦学习是可行的,因为FedAvg使用相对较少的通信轮来训练高质量的模型。