follow迪导,对几个SPPF、SPP、simSPPF模块进行了速度测试
目录
- 1. 参考链接
- 2. 代码
- 3. 结果
1. 参考链接
- P导:YOLOv5网络详解
下面做个简单的小实验,对比下SPP和SPPF的计算结果以及速度,代码如下(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分)
- 迪导:空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC
感兴趣的点1:
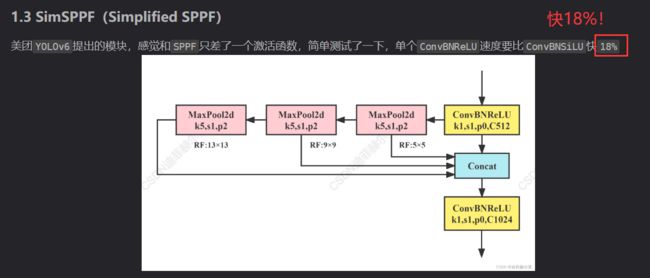
感兴趣的点2:

2. 代码
import time
import torch
import torch.nn as nn
import warnings
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Identity() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Tanh() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Sigmoid() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.ReLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.LeakyReLU(0.1) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = Mish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = FReLU(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = AconC(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = MetaAconC(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = SiLU_beta(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = FReLU_noBN_biasFalse(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = FReLU_noBN_biasTrue(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
"""
摘录自P导的:https://blog.csdn.net/qq_37541097/article/details/123594351
下面做个简单的小实验,对比下SPP和SPPF的计算结果以及速度,代码如下(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分):
"""
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
class SimSPPF(nn.Module):
'''Simplified SPPF with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size=5):
super().__init__()
c_ = in_channels // 2 # hidden channels
self.cv1 = SimConv(in_channels, c_, 1, 1)
self.cv2 = SimConv(c_ * 4, out_channels, 1, 1)
self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
class SimConv(nn.Module):
'''Normal Conv with ReLU activation'''
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, bias=False):
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
def main():
input_tensor = torch.rand(128, 128, 16, 16)
spp = SPP()
sppf = SPPF()
simsppf = SimSPPF(128, 128)
conv = Conv(128, 128, 1, 1, 1)
simconv = SimConv(128, 128, 1, 1, 1)
output = sppf(input_tensor)
output1 = conv(input_tensor)
output2 = simconv(input_tensor)
print(torch.equal(output, output2))
t_start = time.time()
for _ in range(100):
conv(input_tensor)
print(f"Conv time: {time.time() - t_start}")
# 测试simconv运行速度
t_start = time.time()
for _ in range(100):
simconv(input_tensor)
print(f"SimConv time: {time.time() - t_start}")
# 测试sppf运行速度
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"SPPF time: {time.time() - t_start}")
# 测试spp运行速度
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"SPP time: {time.time() - t_start}")
# 测试spp运行速度
t_start = time.time()
for _ in range(100):
simsppf(input_tensor)
print(f"simSPPF time: {time.time() - t_start}")
if __name__ == '__main__':
main()
# import torch
# import numpy as np
# from torch.optim import SGD
# from torch.optim import lr_scheduler
# from torch.nn.parameter import Parameter
# model = [Parameter(torch.randn(2, 2, requires_grad=True))]
# optimizer = SGD(model, lr=0.1)
# scheduler=lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
3. 结果
下面那个False可能没啥用吧,咱也不知道~
就对比着看看结果就是了
False
Conv time: 2.4718410968780518
SimConv time: 2.3119094371795654
SPPF time: 10.516266584396362
SPP time: 21.73476767539978
simSPPF time: 9.221047163009644