什么!!!你还在用TextRank or TFIDF 抽取关键词吗?
什么!!!你还在用TextRank or TFIDF 抽取关键词吗?
本文着眼于简略地介绍关键词提取技术的前世今生
回顾历史
- 无监督
- 统计模型
- FirstPhrases
- TfIdf
- KPMiner (El-Beltagy and Rafea, 2010)
- YAKE (Campos et al., 2020)
- 图模型
- TextRank (Mihalcea and Tarau, 2004)
- SingleRank (Wan and Xiao, 2008)
- TopicRank (Bougouin et al., 2013)
- TopicalPageRank (Sterckx et al., 2015)
- PositionRank (Florescu and Caragea, 2017)
- MultipartiteRank (Boudin, 2018)
- 统计模型
- 有监督
- Kea (Witten et al., 2005)
TFIDF
count ( w ) ∣ D i ∣ ⋅ log N 1 + ∑ i = 1 N I ( w , D i ) \frac { \operatorname { count } ( w ) } { | D _ { i } | } \cdot \log \frac { N } { 1 + \sum _ { i = 1 } ^ { N } I ( w , D _ { i } ) } ∣Di∣count(w)⋅log1+∑i=1NI(w,Di)N
名字以及包含含义即即 【词频】 乘以 【文档频率的倒数】(取对数)
词频等于 【该词出现次数】 除以 【本篇文章词总数】
文档频率 等于 【该词出现在多少文章中】 除以 【文章总数】
(1为了防止分母为0)
TextRank
S ( V i ) = 1 − d + d ⋅ ∑ j ∈ I n ( v i ) 1 ∣ o u t ( v j ) ∣ S ( V j ) S(V_{i})=1-d+d \cdot \sum _{j \in In(v_{i})}\frac{1}{|out(v_{j})|}S(V_{j}) S(Vi)=1−d+d⋅j∈In(vi)∑∣out(vj)∣1S(Vj)
在TextRank提取关键词算法中,限定窗口大小,构建词语共现网络,此时可构建无权无向图,也可根据出现次序构建无权有向图,根据PageRank算法迭代算出权重。实验证明无权无向图效果更好。(d是阻尼因子,防止外链为0的点出现Dead Ends问题)
W S ( V i ) = ( 1 − d ) + d ∗ ∑ j = 1 n ( V i ) ∑ j = N k W i W j i k W S ( V j ) W S ( V _ { i } ) = ( 1 - d ) + d * \sum _ { j = 1 n ( V _ { i } ) } \sum _ { j = N _ { k } } ^ { W _ { i } } W _ { j i k } W S ( V _ { j } ) WS(Vi)=(1−d)+d∗j=1n(Vi)∑j=Nk∑WiWjikWS(Vj)
而TextRank提取摘要算法中,构建的是有权无向图,节点是句子,权重是相似度,相似度的计算如下:
similarity ( S i S j ) = ∣ { W k } ∣ W k ∈ S i 8 W k ∈ S j ∣ log ( ∣ S i ∣ ) + log ( ∣ S i ∣ ) \operatorname { s i m i l a r i t y } ( S _ { i } S _ { j } ) = \frac { | \left\{W_{k}\right\} |W_{k}\in S_{i}8W_{k}\in S_{j}| } { \log ( | S _ { i } | ) + \log ( | S _ { i } | ) } similarity(SiSj)=log(∣Si∣)+log(∣Si∣)∣{Wk}∣Wk∈Si8Wk∈Sj∣
分子是两句子共同的词数量,分母是两个句子词数对数求和。
走进新时代
bert也可以用来抽取关键词
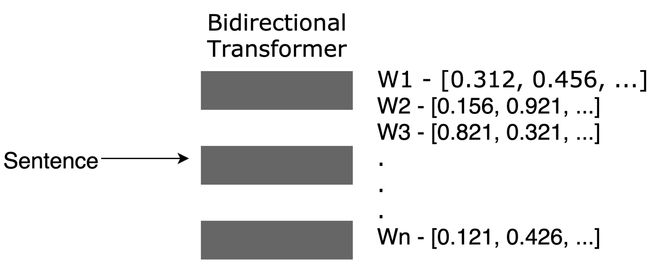
如图所示,将句子输入BERT模型,得到句子向量再与各个词的向量做余弦距离,得出关键词。
sin i = cos ( w i , W ) \sin_{i}= \cos(w_{i},W) sini=cos(wi,W)
使用起来也非常简单:
! pip install keybert
from keybert import KeyBERT
import jieba_fast
from tkitKeyBertBackend.TransformersBackend import TransformersBackend
from transformers import BertTokenizer, BertModel
doc = ""
seg_list = jieba_fast.cut(doc, cut_all=True)
doc = " ".join(seg_list)
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-2_H-128')
model = BertModel.from_pretrained("uer/chinese_roberta_L-2_H-128")
custom_embedder = TransformersBackend(embedding_model=model,tokenizer=tokenizer)
kw_model = KeyBERT(model=custom_embedder)
kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 1), stop_words=None)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T9v0qDid-1665406213346)(https://notebook-media.oss-cn-beijing.aliyuncs.com/img/20220321123630313(1)].png)
抽取关键词还可以预训练
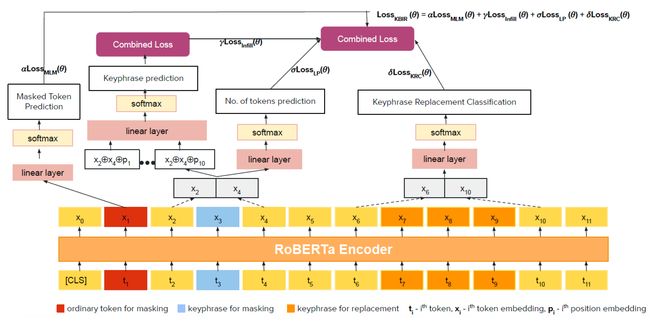
本篇论文最大的贡献在于提出了一种关键词生成的预训练手段,并且证明了此预训练方法对于其他下游任务如NER, QA, RE,summarization也有提升效果。
具体的,如上图所示,
L K B I R ( θ ) = α L M L M ( θ ) + γ L I n f i l ( θ ) + σ L L P ( θ ) + δ L K R C ( θ ) \mathcal{L}_{KBIR}(\theta)= \alpha \mathcal{L}_{MLM}(\theta)+ \gamma \mathcal{L}_{Infil}(\theta)+\sigma \mathcal{L}_{LP}(\theta)+ \delta \mathcal{L}_{KRC}(\theta) LKBIR(θ)=αLMLM(θ)+γLInfil(θ)+σLLP(θ)+δLKRC(θ)
- MLM:masked language model(masked Token Prediction) 单字符掩码任务
- Infil:Keyphrase infilling 关键词填充任务,类似于 SpanBERT,掩码于整个关键词
- LP:Length Prediction,关键词长度预测,将长度预测作为分类任务
- KRC: Keyphrase Replacement Classification 随机替换同类关键词,二分类是否被替换了
使用方法
from transformers import (
TokenClassificationPipeline,
AutoModelForTokenClassification,
AutoTokenizer,
)
from transformers.pipelines import AggregationStrategy
import numpy as np
class KeyphraseExtractionPipeline(TokenClassificationPipeline):
def __init__(self, model, *args, **kwargs):
super().__init__(
model=AutoModelForTokenClassification.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs,
aggregation_strategy=AggregationStrategy.SIMPLE,
)
return np.unique([result.get("word").strip() for result in results])
model_name = "ml6team/keyphrase-extraction-kbir-inspec"
extractor = KeyphraseExtractionPipeline(model=model_name)
引用
- 统计学习方法第2版
- Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling
- Learning Rich Representation of Keyphrases from Text
- PKE: an open source python-based keyphrase extraction toolkit.
- Capturing Global Informativeness in Open Domain Keyphrase Extraction
近期文章更新预告
接下来将更新以下内容,你的关注与打赏是创作的最大动力:
-
机器学习基础
- 决策树的前世今生
-
自己动手实现机器学习系列
- PageRank
-
深度学习基础基础知识
-
理解损失函数
-
理解激活函数
-
-
推荐系统
- W&D工程化其他文章未涉及的建议
-
知识图谱
- 表征学习
-
数据结构与算法
- 动态规划
- 背包问题总结
- 动态规划
-
语言模型
- Bert推理加速
相关论文PDF获取,可关注公众号【无数据不智能】并回复:关键词提取


