常见过拟合、欠拟合原因及解决办法
引言
在机器学习中,我们将模型在训练集上的误差称之为训练误差,又称之为经验误差,在新的数据集(比如测试集)上的误差称之为泛化误差,泛化误差也可以说是模型在总体样本上的误差。对于一个好的模型应该是经验误差约等于泛化误差,也就是经验误差要收敛于泛化误差,根据霍夫丁不等式可知经验误差在一定条件下是可以收敛于泛化误差的。
当机器学习模型对训练集学习的太好的时候(再学习数据集的通性的时候,也学习了数据集上的特性,这些特性是会影响模型在新的数据集上的表达能力的,也就是泛化能力),此时表现为经验误差很小,但往往此时的泛化误差会很大,这种情况我们称之为过拟合,而当模型在数据集上学习的不够好的时候,此时经验误差较大,这种情况我们称之为欠拟合。具体表现如下图所示,第一幅图就是欠拟合,第三幅图就是过拟合。

过拟合
原因
1、训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度
2、训练集和测试集特征分布不一致
3、样本里的噪音数据干扰过大,大到模型过分的记住了噪音特征,而忽略了真实的输入输出间的关系
4、权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征
方法
1、simpler model structure
调小模型复杂度,使其适合自己训练集的数量级(缩小宽度和减小深度)
2、data augmentation
训练集越多,过拟合的概率越小。在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等
3、regularization
参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。正则化是指通过引入额外新信息来解决过拟合问题的一种。这种额外信息通常的形式是模型复杂性带来的惩罚度。正则化可以保持模型简单,另外,规则项的使用还可以约束我们模型的特性。
4、dropout
在训练的时候让神经元以一定概率不工作。
dropout会导致网络的训练速度慢2、3倍,而且数据小的时候,dropout的效果并不会太好,因此只会在大型网络上使用。
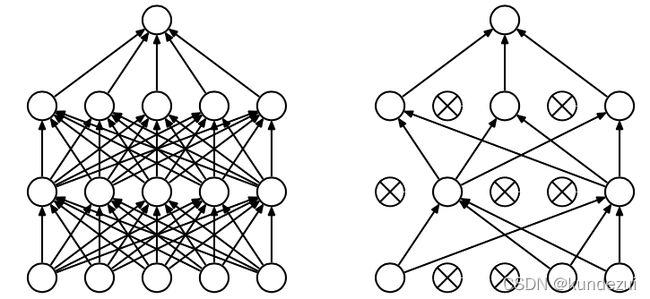
左图没有dropout的标准神经网络,右图有dropout的神经网络,即在训练时候以一定的概率p来跳过一定的神经元
5、Early stopping
对模型进行训练的过程即使对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
其具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data 的 accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accuracy都不再提高了,在继续训练也是无益的。那么该做法的重点就是“怎样才认为accuracy不再提高了?” “并不是accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy上去了,因此不能根据一次两次连续降低就判断不再提高了”。
一般做法是:在训练过程中,记录到目前为止最好的alidation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping),这种策略也称为“No-improvement-in-n” , n即Epoch的次数,可以根据实际情况选取,如10、20、30…
开源代码
import numpy as np
import torch
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt', trace_func=print):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
上次验证集损失值改善后等待几个epoch
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
如果是True,为每个验证集损失值改善打印一条信息
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
检测数量的最小变化,以符合改进的要求
Default: 0
path (str): Path for the checkpoint to be saved to.
Default: 'checkpoint.pt'
trace_func (function): trace print function.
Default: print
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
self.trace_func = trace_func
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
self.trace_func(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.
验证损失减少时保存模型
'''
if self.verbose:
self.trace_func(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
# 这里会存储迄今最优的模型
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
伪代码——pytorch
# 打包数据集
mydata_loader = Dataloader(dataset= , batch_size= 批量大小, shuffle = True or False 是否打乱数据顺序)
model = MyModel()
# 指定损失函数, 这里是交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 指定优化器
optimizer = torch.nn.Adam(model.parameters())
# 初始化early stopping 对象
# 这里是当验证集损失在连续20次训练周期中都没有得到降低时,停止模型训练,防止过拟合
patience = 20
early_stopping = EarlyStopping(patience = patience, verbose = True)
batch_size = 64
n_epochs = 100 #可以设置大一点,比较希望通过早停法来结束模型训练
# 训练模型,直到epoch == n_epochs 或者触发early_stopping来结束训练
for epoch in range(1, n_epochs+1):
# 模型设置为训练模式
model.train()
# 按小批量训练
for batch, (data, label) in enumerate(mydata_loader):
# 清空所有参数的梯度
optimizer.zero_grad()
# 输出模型预测值
output = model(data)
# 计算损失
loss = criterion(output, label)
# 计算损失对于各个参数的梯度
loss.backward()
# 执行单步优化操作: 更新参数
optimizer.step()
# 模型设置为评估/测试模式,关闭dropout,并将模型参数锁定
model.eval()
# 一般如果验证集不是很大,模型验证时就不需要按批量进行,但要注意输入参数的维度不能错
# 预测数据pre_data 对应目标/标签 pre_label
valid_output = model(pre_data)
valid_loss = criterion(valid_output, pre_label)
early_stopping(valid_loss, model)
# 若满足early stopping 要求
if early_stopping.early_stop:
print("Early Stopping!")
# 结束模型训练
break
# 获得 early stopping 时的模型参数
model.load_state_dict(torch.load('checkpoint.pt'))
参考文档:pytorch-实现早停法
参考文档:深度学习技巧之早停法
6、ensemble
集成学习算法也可以有效的减轻过拟合。
Bagging通过评价多个模型的结果,来降低模型的方差。Boosting不仅能过减小偏差,还能减小方差。
欠拟合
原因及方法
1、欠拟合是由于学习不足,可以考虑添加特征,从数据中挖掘更多的特征,有时候还需要对特征进行变换,使用组合特征和高次特征
2、模型简单也会导致欠拟合,如线性模型只能拟合一次函数的数据。尝试使用更高级的模型有助于解决欠拟合,如svm等
3、正则化参数是用来防止过拟合的,出现欠拟合的情况就要考虑减少正则化参数了。