如何通过三级缓存解决 Spring 循环依赖
以下内容基于 Spring6.0.4。
这个其实是一个特别高频的面试题,松哥也一直很想和大家仔细来聊一聊这个话题,网上关于这块的文章很多,但是我一直觉得要把这个问题讲清楚还有点难度,今天我来试一试,看能不能和小伙伴们把这个问题梳理清楚。
这块我是打算整几篇文章,今天,我尽量不聊源码,单纯从设计思路方面来和小伙伴们梳理循环依赖该如何解决。
1. 循环依赖
1.1 什么是循环依赖
首先,什么是循环依赖?这个其实好理解,就是两个 Bean 互相依赖,类似下面这样:
@Service
public class AService {
@Autowired
BService bService;
}
@Service
public class BService {
@Autowired
AService aService;
}
AService 和 BService 互相依赖:
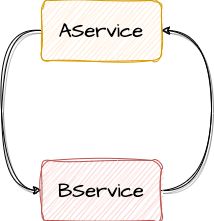
这个应该很好理解。
1.2 循环依赖的类型
一般来说,循环依赖有三种不同的形态,上面 1.1 小节是其中一种。
另外两种分别是三者依赖,如下图:
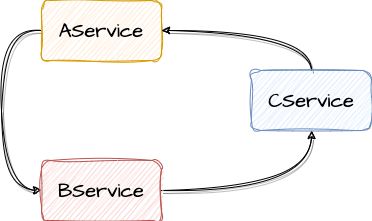
这种循环依赖一般隐藏比较深,不易发觉。
还有自我依赖,如下图:
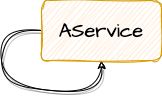
一般来说,如果我们的代码中出现了循环依赖,则说明我们的代码在设计的过程中可能存在问题,我们应该尽量避免循环依赖的发生。不过一旦发生了循环依赖,Spring 默认也帮我们处理好了,当然这并不能说明循环依赖这种代码就没问题。实际上在目前最新版的 Spring 中,循环依赖是要额外开启的,如果不额外配置,发生了循环依赖就直接报错了。
另外,Spring 并不能处理所有的循环依赖,后面松哥会和大家进行分析。
2. 循环依赖解决思路
2.1 解决思路
那么对于循环依赖该如何解决呢?其实很简单,中加加入一个缓存就可以了,小伙伴们来看下面这张图:
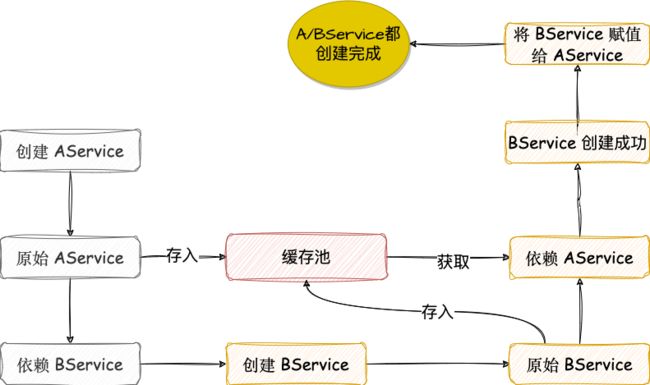
我们在这里引入了一个缓存池。
当我们需要创建 AService 的实例的时候,会首先通过 Java 反射创建出来一个原始的 AService,这个原始 AService 可以简单理解为刚刚 new 出来(实际是刚刚通过反射创建出来)还没设置任何属性的 AService,此时,我们把这个 AService 先存入到一个缓存池中。
接下来我们就需要给 AService 的属性设置值了,同时还要处理 AService 的依赖,这时我们发现 AService 依赖 BService,那么就去创建 BService 对象,结果创建 BService 的时候,发现 BService 依赖 AService,那么此时就先从缓存池中取出来 AService 先用着,然后继续 BService 创建的后续流程,直到 BService 创建完成后,将之赋值给 AService,此时 AService 和 BService 就都创建完成了。
可能有小伙伴会说,BService 从缓存池中拿到的 AService 是一个半成品,并不是真正的最终的 AService,但是小伙伴们要知道,咱们 Java 是引用传递(也可以认为是值传递,只不过这个值是内存地址),BService 当时拿到的是 AService 的引用,说白了就是一块内存地址而已,根据这个地址找到的就是 AService,所以,后续如果 AService 创建完成后,BService 所拿到的 AService 就是完整的 AService 了。
那么上面提到的这个缓存池,在 Spring 容器中有一个专门的名字,就叫做 earlySingletonObjects,这是 Spring 三级缓存中的二级缓存,这里保存的是刚刚通过反射创建出来的 Bean,这些 Bean 还没有经历过完整生命周期,Bean 的属性可能都还没有设置,Bean 需要的依赖都还没有注入进来。另外两级缓存分别是:
- singletonObjects:这是一级缓存,一级缓存中保存的是所有经历了完整生命周期的 Bean,即一个 Bean 从创建、到属性赋值、到各种处理器的执行等等,都经历过了,就存到 singletonObjects 中,当我们需要获取一个 Bean 的时候,首先会去一级缓存中查找,当一级缓存中没有的时候,才会考虑去二级缓存。
- singletonFactories:这是三级缓存。在一级缓存和二级缓存中,缓存的 key 是 beanName,缓存的 value 则是一个 Bean 对象,但是在三级缓存中,缓存的 value 是一个 Lambda 表达式,通过这个 Lambda 表达式可以创建出来目标对象的一个代理对象。
有的小伙伴可能会觉得奇怪,按照上文的介绍,一级缓存和二级缓存就足以解决循环依赖了,为什么还冒出来一个三级缓存?那就得考虑 AOP 的情况了!
2.2 存在 AOP 怎么办
上面松哥给大家介绍的是普通的 Bean 创建,那确实没有问题。但是 Spring 中还有一个非常重要的能力,那就是 AOP。
说到这里,我得先和小伙伴么说一说 Spring 中 AOP 的创建流程。
正常来说是我们首先通过反射获取到一个 Bean 的实例,然后就是给这个 Bean 填充属性,属性填充完毕之后,接下来就是执行各种 BeanPostProcessor 了(不了解 BeanPostProcessor 的小伙伴可以看松哥之前发的文章 BeanFactoryPostProcessor 和 BeanPostProcessor 有什么区别?),如果这个 Bean 中有需要代理的方法,那么系统就会自动配置对应的后置处理器,松哥举一个简单例子,假设我有如下一个 Service:
@Service
public class UserService {
@Async
public void hello() {
System.out.println("hello>>>"+Thread.currentThread().getName());
}
}
那么系统就会自动提供一个名为 AsyncAnnotationBeanPostProcessor 的处理器,在这个处理器中,系统会生成一个代理的 UserService 对象,并用这个对象代替原本的 UserService。
那么小伙伴们要搞清楚的是,原本的 UserService 和新生成的代理的 UserService 是两个不同的对象,占两块不同的内存地址!!!
我们再来回顾下面这张图:
如果 AService 最终是要生成一个代理对象的话,那么 AService 存到缓存池的其实还是原本的 AService,因为此时还没到处理 AOP 那一步(要先给各个属性赋值,然后才是 AOP 处理),这就导致 BService 从缓存池里拿到的 AService 是原本的 AService,等到 BService 创建完毕之后,AService 的属性赋值才完成,接下来在 AService 后续的创建流程中,AService 会变成了一个代理对象了,不是缓存池里的 AService 了,最终就导致 BService 所依赖的 AService 和最终创建出来的 AService 不是同一个。
为了解决这个问题,Spring 引入了三级缓存 singletonFactories。
singletonFactories 的工作机制是这样的(假设 AService 最终是一个代理对象):
当我们创建一个 AService 的时候,通过反射刚把原始的 AService 创建出来之后,先去判断当前一级缓存中是否存在当前 Bean,如果不存在,则:
- 首先向三级缓存中添加一条记录,记录的 key 就是当前 Bean 的 beanName,value 则是一个 Lambda 表达式 ObjectFactory,通过执行这个 Lambda 可以给当前 AService 生成代理对象。
- 然后如果二级缓存中存在当前 AService Bean,则移除掉。
现在继续去给 AService 各个属性赋值,结果发现 AService 需要 BService,然后就去创建 BService,创建 BService 的时候,发现 BService 又需要用到 AService,于是就先去一级缓存中查找是否有 AService,如果有,就使用,如果没有,则去二级缓存中查找是否有 AService,如果有,就使用,如果没有,则去三级缓存中找出来那个 ObjectFactory,然后执行这里的 getObject 方法,这个方法在执行的过程中,会去判断是否需要生成一个代理对象,如果需要就生成代理对象返回,如果不需要生成代理对象,则将原始对象返回即可。最后,把拿到手的对象存入到二级缓存中以备下次使用,同时删除掉三级缓存中对应的数据。这样 AService 所依赖的 BService 就创建好了。
接下来继续去完善 AService,去执行各种后置的处理器,此时,有的后置处理器想给 AService 生成代理对象,发现 AService 已经是代理对象了,就不用生成了,直接用已有的代理对象去代替 AService 即可。
至此,AService 和 BService 都搞定。
本质上,singletonFactories 是把 AOP 的过程提前了。
3. 小结
总的来说,Spring 解决循环依赖把握住两个关键点:
- 提前暴露:刚刚创建好的对象还没有进行任何赋值的时候,将之暴露出来放到缓存中,供其他 Bean 提前引用(二级缓存)。
- 提前 AOP:A 依赖 B 的时候,去检查是否发生了循环依赖(检查的方式就是将正在创建的 A 标记出来,然后 B 需要 A,B 去创建 A 的时候,发现 A 正在创建,就说明发生了循环依赖),如果发生了循环依赖,就提前进行 AOP 处理,处理完成后再使用(三级缓存)。
原本 AOP 这个过程是属性赋完值之后,再由各种后置处理器去处理 AOP 的(
AbstractAutoProxyCreator),但是如果发生了循环依赖,就先 AOP,然后属性赋值,最后等到后置处理器执行的时候,就不再做 AOP 的处理了。
不过需要注意,三级缓存并不能解决所有的循环依赖,这个松哥后面继续整文章和大家细聊。
好啦,今天这篇文章需要一定的 Spring 源码基础方能理解哦,后面松哥会再整一篇文章从源码的角度和小伙伴们验证本文的每一个细节。