TBB并行编程_3任务分配,并发容器,筛选数据
任务分配:
对于并行编程,通常是cpu有几个核心就开几个线程,比如在上面的这个例子中,将图片均匀分为四等分,但是会发现四号区域处理的时间更长。所以由于木桶原理,花的时间由最慢的线程决定。所以实际并没有达到高效。
所以要根据任务量平均分配
解决方案:
1、调大核心数量,线程越多越好,如果超过和cpu的核心数量,那就会自动轮换,轮流执行每个线程。比如这里分配了16个线程,但实际上只有4个核心,那么就会先执行1,2,3,4四个线程,之后5、6、7、8,当一个线程退出之后下一个马上顶上去。
2、操作系统的轮换是有代价的,所以可以使用一个队列来分发任务。
我们仍是分配4个线程,但还是把图像切分为16份,作为一个“任务”推送到全局队列里去。每个线程空闲时会不断地从那个队列里取出数据,即“认领任务”。然后执行,执行完毕后才去认领下一个任务,从而即使每个任务工作量不一也能自动适应。
这种技术又称为线程池(thread pool),避免了线程需要保存上下文的开销。但是需要我们管理一个任务队列,而且要是线程安全的队列。
3、TBB的方法,因为单一的队列在给1分配任务的时候,如果2也处于闲置状态,那就会有一个性能的浪费。所以采用了任务队列,每个线程都有自己的任务队列,自己的任务做完了再去看看别人的队列有没有剩余任务。

4、随机分布:把 (x,y) 那一份,分配给 (x + y * 3) % 4 号线程。这样总体来看每个线程分到的块的位置是随机的,从而由于正太分布数量越大方差越小的特点,每个线程分到的总工作量大概率是均匀的。
tbb::simple_partitioner:
 指定粒度:
指定粒度:

tbb::auto_partitioner(默认)
自动根据 lambda 中函数的执行时间判断采用何种分配方法

tbb::affinity_partitioner 记录历史,下次根据经验自动负载均衡

simple_partitioner自动以缓存高效的方式读取。

这样能保证每次访问的数据在地址上比较靠近,并且都是最近访问过的,从而已经在缓存里可以直接读写,避免了从主内存读写的超高延迟。
并发容器
std::vector

可以用预分配的方法(不能用初始化,只能用预分配,因为vector a(n)直接创建了有 n 个元素的 vector 并初始化默认值。那样的话就只能a[i] = sin(i);pa[i] = &a[i];就不涉及到扩容了):

不连续的 tbb::concurrent_vector
std::vector 造成指针失效的根本原因在于他必须保证内存是连续的,从而不得不在扩容时移动元素。
因此可以用 tbb::concurrent_vector,他不保证元素在内存中是连续的。换来的优点是 push_back 进去的元素,扩容时不需要移动位置,从而指针和迭代器不会失效。
同时他的 push_back 会额外返回一个迭代器(iterator),指向刚刚插入的对象。

int main() {
size_t n = 1<<10;
tbb::concurrent_vector a;
tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) {
auto it = a.grow_by(2);
*it++ = std::cos(i);
*it++ = std::sin(i);
});
std::cout << a.size() << std::endl;
return 0;
} push_back一次只能推入一个元素,而grow_by一次可以推入多个元素,他也是返回一个迭代器,然后通过it++访问下一个元素所对应的迭代器,用*去赋值。
但因为concurrent_vector是跨步的,所以如果采用a[i]这种索引来访问就很低效,一般采用的是begin()和end()。
#include
#include
#include
#include
int main() {
size_t n = 1<<10;
tbb::concurrent_vector a(n);
for (auto it = a.begin(); it != a.end(); ++it) {
*it += 1.0f;
}
std::cout << a[1] << std::endl;
return 0;
} ++it是原子的操作,而it++不是,it++是先返回it的值,再向下走一步,在多线程环境下,多个线程可能同时执行it++操作,并且可能会产生竞态条件。这样的竞态条件会导致不确定的结果,并可能导致数据访问错误。
parallel_for也支持迭代器
tbb::parallel_for(tbb::blocked_range(a.begin(), a.end()),
[&] (tbb::blocked_range r) {
for (auto it = r.begin(); it != r.end(); ++it) {
*it += 1.0f;
}
}); 筛选数据
TICK(filter);
tbb::parallel_for(tbb::blocked_range(0, n),
[&] (tbb::blocked_range r) {
for (size_t i = r.begin(); i < r.end(); i++) {
float val = std::sin(i);
if (val > 0) {
a.push_back(val);
}
}
});
TOCK(filter); 这种代码就很低效,因为concurrent_vector内部采用的是直接的互斥量,所以会有锁相互竞争的情况。其实这种和一条一条的输入没什么区别。
#include
#include
#include
#include
#include "ticktock.h"
int main() {
size_t n = 1 << 20;
tbb::concurrent_vector a;
TICK(for);
tbb::parallel_for(tbb::blocked_range(0, n), [&](tbb::blocked_range r) {
std::vector local_a;
for (size_t i = r.begin(); i < r.end(); i++){
float val = std::sin(i);
if (val > 0) {
local_a.push_back(val);
}
}
auto it = a.grow_by(local_a.size());
for (size_t i = 0; i < local_a.size(); i++)
{
*it++ = local_a[i];
//copy(local_a.begin() , local_a.end() ,it)
}
});
TOCK(for);
return 0;
} 上面的代码就很高效。先用一个local_a将数据存入临时的容器中,之后将这个临时容器中的数据再放入总容器中。
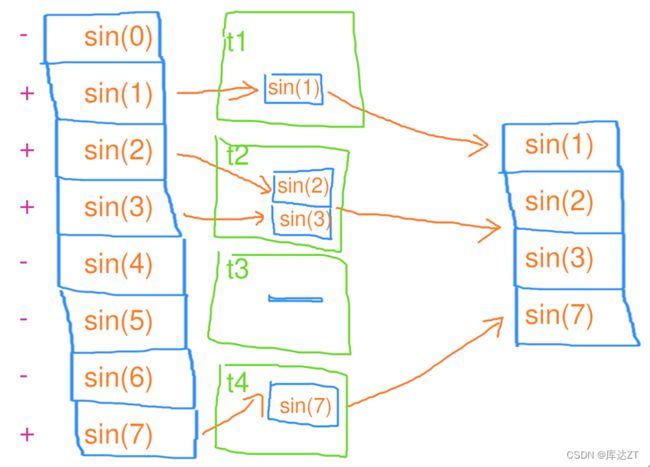
这么一看好像也不是必须要用concurrent_vector
size_t n = 1<<27;
std::vector a;
std::mutex mtx;
TICK(filter);
a.reserve(n * 2 / 3);
tbb::parallel_for(tbb::blocked_range(0, n),
[&] (tbb::blocked_range r) {
std::vector local_a;
local_a.reserve(r.size());
for (size_t i = r.begin(); i < r.end(); i++) {
float val = std::sin(i);
if (val > 0) {
local_a.push_back(val);
}
}
std::lock_guard lck(mtx);
std::copy(local_a.begin(), local_a.end(), std::back_inserter(a));
});
TOCK(filter); mutex是操作系统提供的,通常是吊起一个线程,切换到另一个线程。这句话是什么意思呢,就是通过使用mutex和线程切换,多个线程可以在共享资源上进行同步,以避免冲突和不一致的结果。当一个线程完成对共享资源的操作并释放mutex时,其他线程才能获取mutex并继续执行。这样可以保证对共享资源的安全访问,同时充分利用多线程并发的优势。
而这个切换线程的开销是不可避免的:
这时就可以使用tbb::spin_mutex(),这个是不涉及到操作系统的,他原子操作将cpu陷入循环等待,但是因为它不用进入操作系统,所以效率在锁区域较小的时候是比较高的。

用我们之前学习到的reduce也可以起到一定的效果。
今天先到这里,下一节是分治与排序