Java多线程并发实战详解,最详细
写在前面
你们好,我是小庄。很高兴能和你们一起学习Java。如果您对Java感兴趣的话可关注我的动态.
写博文是一种习惯,在这过程中能够梳理和巩固知识。
这里写目录标题
- 一、简介
- 二、线程的状态
-
- 1、New (新建)和运行
- 2、start()和run()的区别
- 3、线程的方法
- 4、守护线程
- 三、多线程的信息共享
- 四、消费者-生产者案例
- 五、Java多线程锁
-
- 1、锁状态
- 2、死锁
- 3、饥饿锁
- 4、Lock显示锁
- 5、AQS算法
- 6、可重入锁和读写锁
- 六、线程池
-
- 1、线程组
- 2、线程池——Executors
- 3、ForkJoin
- 七、线程辅助类
-
- 1、CountDownLatch
- 2、CyclicBarrier
- 3、Phaser
- 4、Exchanger
- 5、Semaphore
一、简介
聊多线程之前我们先来聊聊进程
进程
进程是操作系统结构的基础;是一次程序的执行;是一个程序及其数据在处理机上顺序执行时所发生的活动;是程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单位。
具体一点,来看图
正在操作系统中运行的程序可以理解为进程
线程
线程可以理解为在进程中独立运行的子任务,例如:在酷狗音乐中,我们可以下载音乐的同时可以听歌。
总结一下:
1、一个进程可以有多个线程
2、线程是进程的一个实体,是CPU调度和分派的最小单位
3、进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址和空间
4、在JVM虚拟机中,多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈
既然我们知道进程和线程的概念了,那我们聊聊多进程和多线程
多进程
多进程就是多个进程,系统把时间划分为多个时间片(时间很短),在单核电脑中,通过不断的切换运行(串行),多核电脑中多个任务可以并行执行
为什么要使用多线程
多线程的优点:
1、多线程的数据是共享的
2、多线程的通讯更高效
3、多线程更轻量级,更容易切换
4、多线程更加容易管理
二、线程的状态
线程有六种状态:
- New (新建)
- Runnable (可运行)
- Blocked (堵塞)
- Waiting (等待)
- Terminated (终止)
1、New (新建)和运行
我们要使用线程,就必须新建线程,告知编译器这是线程
我们新建线程的方式有三种方式。
方式一:继承Thread类,并且重写run()方法
方式二:实现Runnable接口,并且实现run()方法
方式三:实现Callable接口,并且实现call()方法,通过线程池启动
我们知道,只能继承一个类,却可以实现多个接口,所以,推荐使用实现接口的方式
如果我们查看源码我们会发现,Thread类实际上也是实现Runnable接口
方式二和方式三有什么区别呢?
方式二没有返回值,方式三有返回值
call()方法可能会引发异常,run()方法不会引发异常
Callable一般和Future结合运用,这个就留到后面线程池再讲吧
下面来看代码
代码实例
方式一:
我们定义一个MyThread类,继承Thread类,并重写run()方法
public class MyThread extends Thread{
@Override
public void run() {
//currentThread() 返回对当前正在执行的线程对象的引用,getName()获取线程名
System.out.println(Thread.currentThread().getName()+"正在运行");
}
}
方式二:
我们定义一个MyThread2类,实现Runnable接口,并重写run()方法
public class MyThread2 implements Runnable{
@Override
public void run() {
//currentThread() 返回对当前正在执行的线程对象的引用,getName()获取线程名
System.out.println(Thread.currentThread().getName()+"正在运行");
}
}
我们在主函数中进行测试
public class ThreadDemo{
public static void main(String[] args){
System.out.println("继承Thread的启动方法");
//start()是启动线程的方法
new MyThread().start();
System.out.println("实现Runnable的启动方法");
new Thread(new MyThread2()).start();
System.out.println("使用lambda表达式启动(底层实现Runnable)");
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"正在运行");
}).start() ;
}
}
上面代码我们看到我们使用的是start()方法启动线程,而不是使用run()方法启动线程。
2、start()和run()的区别
start()是并行执行,run()是串行执行。
什么是串行运行,也就是先执行上面代码,执行完。再执行下面代码
什么是并行运行,能够同时执行,不管先后顺序
我们通过代码来看他们之间的区别
首先,我们在MyThread类的run()方法上执行一个死循环语句
public class MyThread3 extends Thread{
@Override
public void run() {
while(true) {
System.out.println("线程正在运行");
try {
//休眠一秒钟
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
我们先来看通过run()启动
public class ThreadDemo {
public static void main(String[] args) {
//启动线程
new MyThread3().run();
//打印
System.out.println("Main方法执行结束");
}
}
运行后,我们发现,打印内容(Main方法执行结束) 并没有执行,说明使用run()方法是必须等上面的代码执行结束后才能执行下面的代码
最后记得把这个线程关闭掉

我们再来看start()方法
同样,我们使用上面的MyThread3类,只在ThreadDemo类做小改动
public class ThreadDemo {
public static void main(String[] args) {
//启动线程
new MyThread().start();
//打印
System.out.println("Main方法执行结束");
}
}
我们来看图片

通过图我们发现,打印的内容也执行了,MyThread线程还在运行。
这说明使用start()方法是并行执行,不需要等MyThread执行完再执行
注意: 一个线程对象不能多次start(),否则会报异常,例如下面代码
MyThread t=new MyThread();
//同一个线程对象多次start(),报异常
t.start();
t.start();
3、线程的方法
上面的例子我们也使用了部分的方法,接下来我把常用方法先列举出来
| 方法 | 作用 |
|---|---|
start() |
启动线程并调用run方法 |
activeCount() |
返回当前线程活动线程数的估计 |
currentThread() |
返回对当前正在执行的线程对象的引用。 |
getName() |
返回此线程的名称 |
isAlive() |
测试这个线程是否活着。 |
setName(String name) |
给线程设置名称 |
setDaemon(boolean on) |
将此线程标记为守护线程(true)或用户线程。(默认false) |
关于线程堵塞的方法
| 方法 | 作用 |
|---|---|
sleep(long millis) |
线程休眠一段时间后醒来,单位是毫秒, |
wait() |
等待,直到被notify()或notifyAll()唤醒 |
interrupt() |
中断这个线程。 |
interrupted() |
测试当前线程是否中断。 |
yield() |
线程退回到就绪状态 |
join(long millis) |
等待一个线程结束后运行 |
4、守护线程
我们可能会疑问:什么是守护线程,怎么实现的,什么时候会用到它
别急,我们慢慢探讨它
什么是守护线程
守护线程唯一用途是为其他线程(普通线程)提供服务,当用户线程不存在时,守护线程会自动销毁。
怎么实现守护线程
线程启动前设置setDaemon(true)开启守护线程,我们来看普通线程和守护线程的区别
我们先定义线程类,设置不断运行
public class MyThread extends Thread{
@Override
public void run() {
while(true) {
System.out.println("线程正在运行...");
//设置运行的间隔时间
try {
//间隔一秒
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
我们使用普通线程的方式启动
public class ThreadDemo {
public static void main(String[] args) {
//new实例化线程类
MyThread t= new MyThread();
//启动线程
t.start();
//设置运行的间隔时间
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("Main方法运行结束");
}
}
运行结果:Main方法已经结束,但线程类会一直运行
线程正在运行...
线程正在运行...
Main方法运行结束
线程正在运行...
线程正在运行...
线程正在运行...
我们来看使用守护线程,记得一定要在线程启动前设置setDaemon(true) ,否则报异常
public class ThreadDemo {
public static void main(String[] args) {
//new实例化线程类
MyThread t= new MyThread();
//设置为守护线程
t.setDaemon(true);
//启动线程
t.start();
//设置运行的间隔时间
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("Main方法运行结束");
}
}
运行结果:当Main方法运行结束后,普通线程就被停止运行了
线程正在运行...
线程正在运行...
Main方法运行结束
小结
普通线程的结束,是run方法的运行结束
守护线程的结束,是run方法的运行结束或main函数结束。不确定
守护线程永远不要访问资源!文件或数据库等
守护线程主要运用在垃圾回收器中,这个是JVM虚拟机的知识,本篇就不展开聊了
三、多线程的信息共享
在多线程的环境下,如果同时有很多人操作一个数据的时候,有可能会造成信息不一致,我们先来看下面的售票案例
售票类
public class MyThread extends Thread{
private int num=10;
@Override
public void run() {
while(true) {
if(num>0) {
System.out.println(Thread.currentThread().getName()+"门票剩下:"+num);
num=num-1;
//我们让线程停0.1秒
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {
break;
}
}
}
}
测试类
public class ThreadDemo {
public static void main(String[] args) {
//实例化MyThread类
MyThread t=new MyThread();
//启动三个线程
new Thread(t).start();
new Thread(t).start();
new Thread(t).start();
}
}
打印结果
Thread-2门票剩下:10
Thread-1门票剩下:10
Thread-3门票剩下:10
Thread-2门票剩下:9
Thread-1门票剩下:7
Thread-3门票剩下:8
Thread-3门票剩下:6
Thread-2门票剩下:5
Thread-1门票剩下:4
Thread-3门票剩下:3
Thread-1门票剩下:1
Thread-2门票剩下:1
我们发现,打印出了十二张票(结果不确定),而且出现了重复的票数,这并不是我们想要的。
为了避免这种情况,我们采用了volatile加上synchronized关键字进行对以上代码完善。
我们先来看代码,测试类保持不变,只改变售票类
public class MyThread extends Thread{
private volatile int num=10;
@Override
public void run() {
while(true) {
//票数减少
jian();
//我们让线程停0.1秒
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if(num<=0) {
break;
}
}
}
public synchronized void jian() {
if(num>0) {
System.out.println(Thread.currentThread().getName()+"门票剩下:"+num);
num=num-1;
}
}
}
打印结果:
Thread-1门票剩下:10
Thread-3门票剩下:9
Thread-2门票剩下:8
Thread-1门票剩下:7
Thread-2门票剩下:6
Thread-3门票剩下:5
Thread-3门票剩下:4
Thread-1门票剩下:3
Thread-2门票剩下:2
Thread-2门票剩下:1
通过完善后,这个结果正是我们想要的

那么我们来聊聊volatile和synchronized这两个关键字
volatile关键字的作用是当变量发生改变时,所有的线程都是可见的(可见性)。volatile关键字可以保证变量的操作是不会被重排序
它在计算机中的内存模型是这样的:

线程从主存读取数据到工作缓存中,当变量修改后,把工作缓存刷新到主存中。我们发现,每一个线程都有自己的工作缓存,当一个线程的工作缓存修改值之后,其他线程并不知道,所以我们在关键步骤要进行加锁限制
synchronized关键字的作用是每次只允许一个线程对里面的代码进行操作,synchronized同步方法和同步语句块,它是互斥锁(重量级锁),允许锁重入
synchronized保障原子性、可见性和有序性
聊到这里,很多小伙伴可能懵了,什么是可见性,原子性,有序性和重排序,什么是锁、什么是锁重入。这些问题正是我们接下来聊的。
可见性
可见性是指一个线程对共享变量的修改,对于其他所有线程来说是否是可以看到的,也就是说线程A修改了一个变量,线程B看到了这个变量发生了改变,如果线程B要对这个变量进行修改,那么就是拿已经被线程A修改过的变量值进行修改
原子性
原子性是一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。也就是说线程A在操作变量C时,那么线程B将不能对变量C进行操作。变量C暂时是线程A独有的。等线程A操作结束后线程B才可以对变量C操作。
原子性相关的类:
AtomicInteger:整型
AtomicBoolean:布尔类型
AtomicIntegerArray:数组
…
这里我们只举例三个,其他的请查看Java的API文档
具体使用如下:比较常用的i++操作被换成下面代码
//声明,初始化值为0
AtomicInteger num=new AtomicInteger();
System.out.println("初始值:"+num);
//原子上增加一个当前值。 类似i++操作,只不过这个线程安全
num.incrementAndGet();
System.out.println("执行增加操作后的值:"+num);
有序性
程序执行的顺序按照代码的先后顺序执行,也就是从上往下执行代码。
重排序
关于指令重排序的问题,我们用代码来聊聊。比如下面有三行代码
a=0; // (1)
a=8; // (2)
b=a; // (3)
上面代码中,(1)、(2)没有依赖关系;(3)、(1)或者(3)、(2)有依赖关系。
在多线程环境下:虚拟机执行指令的时候,实行重排序,有可能是先执行步骤为(1) -> (3) -> (2),那么此时b=0;
volatile可以避免重排序,保证有序性,至于volatile是怎么做到的,是因为实现了JVM内存屏障
代码演示解析如下
A变量的操作
B变量的操作
volatile X变量的操作
C变量的操作
D变量的操作
以上的代码有4种情况发生
1) A、B可以重排序
2)C、D可以重排序
3)A、B不可以重排序到X的后面
4)C、D不可以重排序到X的前面
四、消费者-生产者案例
我们通过这个著名的案例来巩固我们上面所学的知识,
生产者不断的往仓库中存放产品,消费者从仓库中消费产品。
其中生产者和消费者都可以有若干个。
由于仓库的容量有限,所以规则有:
仓库满时不能存放产品,仓库空时不能消费产品
我们需要仓库类、产品类、生产者类、消费者类和一个测试类
仓库类:规定好仓库的容量,分别定义存产品和取产品方法
//仓库类
public class Store {
//仓库容量,最多存储5个产品
private volatile Product[] products=new Product[5];
//初始化长度为0
private volatile int num=0;
//往仓库里面放产品
public synchronized void push(Product product) {
while(num==products.length) {
System.out.println("仓库满了!");
try {
//进入等待状态,仓库不能再放东西了
wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//把产品放到数组中,然后数组长度加1
products[num++]=product;
System.out.println(Thread.currentThread().getName()+"生产了产品:"+"当前仓库有"+num+"件产品");
//激活所有等待的线程
notifyAll();
}
//往仓库里面取产品
public synchronized void pop() {
while(num==0) {
try {
//进入等待状态,没有产品可消费了
wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//长度减一,匹配到消费的产品的数组下标
--num;
//将内容清空
products[num]=null;
System.out.println(Thread.currentThread().getName()+"消费了一个产品,仓库剩下:"+num+"件产品");
//激活所有等待的线程
notifyAll();
}
}
产品类:主要记录产品信息,简单即可
public class Product {
//产品id
private String id;
//产品名
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
生产者类:
import java.util.UUID;
//生产者
public class Producer implements Runnable{
//定义产品类
Product product=new Product();
//定义仓库类
Store store;
//构造函数
public Producer() {}
//有参构造
public Producer(Store store) {
this.store=store;
}
@Override
public void run() {
int i=0;
//设置一个生产者只能生产5个产品
while(i<5) {
i++;
//设置产品名
product.setName("产品"+i);
//设置唯一UUID,
String id=UUID.randomUUID().toString().replace("-", "");
//设置产品id
product.setId(id);
//往仓库存产品
store.push(product);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
消费者:
//消费者
public class Consumer implements Runnable{
//定义仓库类
Store store;
public Consumer() {}
public Consumer(Store store) {
this.store=store;
}
@Override
public void run() {
int i=0;
//设置一个消费者最多消费5个产品
while(i<5) {
//消费产品
store.pop();
i++;
//休息0.1秒
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
最后我们进入测试类:
public class Test {
public static void main(String[] args) {
Store store=new Store();
Thread p1=new Thread(new Producer(store));
p1.setName("生产者1");
Thread p2=new Thread(new Producer(store));
p2.setName("生产者2");
Thread c1=new Thread(new Consumer(store));
c1.setName("消费者1");
Thread c2=new Thread(new Consumer(store));
c2.setName("消费者2");
//先启动生产者
p1.start();
p2.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//启动消费者
c1.start();
c2.start();
}
}
打印结果:
生产者1生产了产品:当前仓库有1件产品
生产者2生产了产品:当前仓库有2件产品
生产者1生产了产品:当前仓库有3件产品
生产者2生产了产品:当前仓库有4件产品
生产者2生产了产品:当前仓库有5件产品
仓库满了!
仓库满了!
消费者1消费了一个产品,仓库剩下:4件产品
消费者2消费了一个产品,仓库剩下:3件产品
生产者2生产了产品:当前仓库有4件产品
生产者1生产了产品:当前仓库有5件产品
消费者1消费了一个产品,仓库剩下:4件产品
消费者2消费了一个产品,仓库剩下:3件产品
生产者1生产了产品:当前仓库有4件产品
生产者2生产了产品:当前仓库有5件产品
消费者1消费了一个产品,仓库剩下:4件产品
消费者2消费了一个产品,仓库剩下:3件产品
生产者1生产了产品:当前仓库有4件产品
消费者1消费了一个产品,仓库剩下:3件产品
消费者2消费了一个产品,仓库剩下:2件产品
消费者2消费了一个产品,仓库剩下:1件产品
消费者1消费了一个产品,仓库剩下:0件产品
相信通过生产者-消费者案例,我们对多线程的通信的了解更加的深入
我们接下来聊聊Java锁
五、Java多线程锁
1、锁状态
锁有哪些?我们主要分为四种状态:
new状态(什么锁都没有加)、偏向锁(jdk15被废除)、轻量级锁(无锁或自旋锁)、重量级锁
锁升级过程:偏向锁 -> 轻量级锁 -> 重量级锁
锁一旦升级,就不能降级。因为降级是在垃圾回收的时候进行的,降级是没有意义的了(都已经回收了)
偏向锁:偏向第一个进来的线程,在竞争不是非常激烈的情况下使用。常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁
轻量级锁:轻量级锁也被称为无锁或自旋锁,为什么这么说呢,我们通过轻量级锁的底层CAS算法来介绍轻量级锁是怎么实现的

从上面流程图我们可以看出,CAS算法是通过循环判断实现的,通过判断传进来的值是否发生变化来判断是否需要更新E的值为V,如果原值发生了变化(被其他线程修改为不同的值)那么就会重新更新E的值,然后再继续判断。从中我们看以看出它的缺点之一是:可能会相当耗内存。
流程图中CAS是无法解决ABA问题的。如果变量A被修改为变量B,然后又修改会变量A,由于判断是只是传进来的值是否一致,而变量A的值并没有发生变化,只是被修改多次。
如何解决ABA问题
我们给E值加一个版本号(标识)给它,当E的值被修改后,版本号就发生了变化,在判断的时候我们同时判断版本号是否一致,这样就解决了ABA问题了
重量级锁: 目前我们所熟悉的synchronized就是一个重量级锁,也叫互斥锁,它的原理是一个房间,每次只能允许一个线程进(加锁),其他线程就只能阻塞等待,等待进去的线程出来(锁释放)后,其他线程就会再次竞争进去一个线程…
以上我们对锁的锁定状态(三个)进行了简单介绍,下面我们聊聊死锁
2、死锁
什么是死锁(怎样造成了死锁)

上图就是典型的哲学家吃面问题(死锁问题),如果每个人(线程)同时拿起右边的筷子或者同时拿起左边筷子都会导致谁都吃不了面(死锁);
比如线程A拿了右边的筷子,当线程A要拿左边的筷子时,已经被线程D拿走了,线程D想要拿左边的筷子时,同样被别的线程拿走了,这样就造成了死锁
我们通过代码来理解,我们需要两个线程类进行模拟
线程一:
public class MyThread extends Thread{
@Override
public void run() {
synchronized(ThreadDemo.A) {
System.out.println("我是线程一,我拿到了锁A");
synchronized(ThreadDemo.B) {
//验证是否执行下面代码
System.out.println("我是线程一,两个锁我都拿到了");
}
}
}
}
线程二:
public class MyThread2 extends Thread{
@Override
public void run() {
synchronized(ThreadDemo.B) {
System.out.println("我是线程二,我拿到了锁B");
synchronized(ThreadDemo.A) {
System.out.println("我是第二个线程,两个锁我都拿到了");
}
}
}
}
最后我们来进行测试
public class ThreadDemo {
//定义静态变量,让其被锁住
public static String A="lock1";
public static String B="lock2";
public static void main(String[] args) {
MyThread t1=new MyThread();
MyThread2 t2=new MyThread2();
t1.start();
t2.start();
}
}

测试完记得关闭线程,以免造成卡顿哦
通过上图,我们发现,程序一直在运行中,两个线程的第二个文本没有打印出来,也就是两个线程都准备拿第二把锁的时候,发现已经被对方拿走了,双方谁都想争夺对方的锁,这就造成了死锁
活锁解决方案(活锁)
规定锁的获取顺序,也就是两个线程都必须先拿锁A,再拿锁B
实现原理:
假设线程一先拿到了锁A,那就得等线程一把锁A释放了线程二才能拿。下面我们只对MyThread2类进行修改
public class MyThread2 extends Thread{
@Override
public void run() {
synchronized(ThreadDemo.A) {
System.out.println("我是线程二,我拿到了锁B");
synchronized(ThreadDemo.B) {
System.out.println("我是第二个线程,两个锁我都拿到了");
}
}
}
}
运行结果:
我是线程一,我拿到了锁A
我是线程一,两个锁我都拿到了
我是线程二,我拿到了锁B
我是第二个线程,两个锁我都拿到了
3、饥饿锁
顺序加锁会产生饥饿问题,因为线程顺序排的不够好时,会造成有的线程频繁执行,而有的线程很少执行(饥饿),饿的饿死,饱的饱死。废话不多说,我们来看下面代码了解其原理
为了验证饥饿问题,我们通过三个线程类进行模拟,然后通过测试结果进行讨论
线程一:
public class MyThread extends Thread{
@Override
public void run() {
while(true) {
synchronized(ThreadDemo.A) {
synchronized(ThreadDemo.B) {
//验证是否执行下面代码
System.out.println("我是线程一,我在吃面");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
线程二:
public class MyThread2 extends Thread{
@Override
public void run() {
while(true) {
synchronized(ThreadDemo.B) {
synchronized(ThreadDemo.C) {
System.out.println("我是线程二,我在吃面");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
线程三:
public class MyThread3 extends Thread{
@Override
public void run() {
while(true) {
synchronized(ThreadDemo.A) {
synchronized(ThreadDemo.C) {
System.out.println("我是线程三,我在吃面");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
测试类启动线程:
public class ThreadDemo {
//定义静态变量,让其被锁住
public static String A="lock1";
public static String B="lock2";
public static String C="lock3";
public static void main(String[] args) {
MyThread t1=new MyThread();
MyThread2 t2=new MyThread2();
MyThread3 t3=new MyThread3();
t1.start();
t2.start();
t3.start();
}
}
打印结果:
我是线程一,我在吃面
我是线程一,我在吃面
我是线程一,我在吃面
我是线程一,我在吃面
我是线程一,我在吃面
我是线程一,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程三,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程三,我在吃面
我是线程三,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程二,我在吃面
我是线程一,我在吃面
我是线程一,我在吃面
我们设置了循环,程序会一直被运行,我们发现,线程三执行次数比线程二次数少很多,线程三出现饥饿,由于本文是通过三个线程进行模拟的,效果可能不会很明显,如果使用五个,十个线程,根据顺序加锁,饥饿效果会更加明显一些。我们接着聊Lock锁
4、Lock显示锁
sychronized 和 Lock
synchronized的特点
1、是阻塞的
2、每次只能允许一个线程执行
3、自动释放锁
Lock特点
1、非阻塞的,支持中断,超时不获取,更加灵活
2、设置为共享锁时允许多个线程同时访问
3、必须要手动释放锁
4、可以通过trylock()方法判断是否获得锁
我们来看它的方法
| 方法 | 作用 |
|---|---|
lock() |
获得锁 |
tryLock() |
只有在调用时才可以获得锁。判断锁是否空闲 |
unlock() |
释放锁。 |
5、AQS算法
AQS全称:AbstractQueuedSynchronizer(队列同步器)
AQS算法的实现是CAS算法+volatile
为什么它是队列同步器呢,我们来看下它底层实现图

通过上图,我们了解到AQS在线程中间采用了双链表队列存储,state表示锁状态,当锁被使用时,状态为true,否则为false。这里采用的volatile修饰,保证了锁状态的可见性。
AQS分为:
· 公平锁:按照队列原则,先到先得
· 非公平锁:无视队列原则,抢着来,虚拟机默认使用非公平锁
假设线程D过来了,按照公平锁,应该要排到线程C后面等待,等线程C执行完才轮到它。要是按照非公平锁,它首先会去抢锁,抢不过再进入队列。
6、可重入锁和读写锁
可重入锁又称之为递归锁,是指同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁
synchronized支持可重入,我们就通过代码来解释可重入的概念
线程类:
public class MyThread extends Thread{
@Override
public void run() {
m1();
}
public synchronized void m1() {
System.out.println("m1开启");
try {
//休息一下
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
m2();
System.out.println("m1结束");
}
public synchronized void m2() {
System.out.println("m2被调用");
}
}
测试类:
public class ThreadDemo {
public static void main(String[] args) {
MyThread t=new MyThread();
t.start();
}
}
打印结果:
m1开启
m2被调用
m1结束
代码解析: 通过上面线程类,我们发现,m1()方法和m2()方法都使用了synchronized加锁,进入m1()方法后,当调用m2()方法时,发现是同一个线程,最后只使用了m1()方法的锁,这就是可重入锁的概念理解。
如果不可重入锁,那么m2()就进不去,最后导致死锁问题
注意:ReentrantLock是可重入锁
我们来看它的案例
import java.util.concurrent.locks.ReentrantLock;
public class ThreadDemo {
//定义可重入锁
private static final ReentrantLock reentrant=new ReentrantLock();
public static void main(String[] args) {
buyMilkTea();
}
private static void buyMilkTea() {
ThreadDemo demo=new ThreadDemo();
//五个学生
int num=5;
Thread[] students=new Thread[num];
//学生线程启动
for(int i=0;i<num;i++) {
students[i]=new Thread(new Runnable() {
@Override
public void run() {
long waitTime=(long) (Math.random()*100);
try {
Thread.sleep(waitTime);
//学生去买奶茶
demo.tryToBuyMilkTea();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
//学生线程启动
students[i].start();
}
}
public void tryToBuyMilkTea() {
boolean flag=true;
while(flag) {
//判断是否锁是否空闲
if(reentrant.tryLock()) {
try {
//模拟随机等待时间
long waitTime=(long) (Math.random()*100);
Thread.sleep(waitTime);
//学生要求买一杯奶茶
System.out.println(Thread.currentThread()+"请给我来一杯");
//买完退出
flag=false;
//释放重入锁
reentrant.unlock();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {
//锁被占用
System.out.println("再等等");
}if(flag) {//设置间隔时间
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
打印结果
再等等
再等等
Thread[Thread-1,5,main]请给我来一杯
再等等
Thread[Thread-2,5,main]请给我来一杯
再等等
再等等
Thread[Thread-3,5,main]请给我来一杯
Thread[Thread-0,5,main]请给我来一杯
Thread[Thread-4,5,main]请给我来一杯
读写锁分为:
1、读锁:共享锁
2、写锁:独占锁
共享锁: 意思就是大家都可以持有同一把锁,都可以进去,在读操作时,一般允许多线程同时访问
独占锁: 意思就是锁被一个线程独占,其他线程得等着,等锁释放了才能选出一个进去,在写操作时,为了保证原子性,数据正确性,采用独占锁
ReadWriteLock这个接口实现了读写锁的功能,ReentrantReadWriteLock类继承了它,我们先列出它的方法,再根据代码加深理解
我只列出部分方法,其它方法请查阅JDK的api文档
| 方法 | 作用 |
|---|---|
readLock() |
返回用于阅读的锁。 |
writeLock() |
返回用于写入的锁。 |
我们通过案例把可重入锁和读写锁进行讲解
案例内容:有一个老板,四个员工
一个老板负责写订单,在写订单时员工不能查看订单(独占锁)
等老板写完订单后,四个员工都可以查看订单(共享锁)
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class LockTest {
private static final ReentrantReadWriteLock reentrantread=new ReentrantReadWriteLock();//可重入读写锁
public static void main(String[] args) {
handleOrder();
}
//订单操作方法
private static void handleOrder() {
LockTest test=new LockTest();
//定义老板线程匿名类
Thread boss=new Thread(new Runnable() {
@Override
public void run() {
while(true) {
//老板写订单
test.addOrder();
try {
long waitTime=(long)(Math.random()*1000);
Thread.sleep(waitTime);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
});
//启动线程
boss.start();
//定义四个员工
int work=4;
Thread[] works=new Thread[work];
for(int i=0;i<work;i++) {
//定义员工线程匿名类
works[i]=new Thread(new Runnable() {
@Override
public void run() {
while(true) {
//看订单
test.viewOrder();
try {
long waitTime=(long)(Math.random()*1000);
Thread.sleep(waitTime);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
});
//启动员工线程
works[i].start();
}
}
//查看订单方法
protected void viewOrder() {
//启动读锁
reentrantread.readLock().lock();
try {
long waitTime=(long) (Math.random()*1000);
//设置等待时间
Thread.sleep(waitTime);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("查看了订单");
//释放锁
reentrantread.readLock().unlock();
}
//添加订单方法
protected void addOrder() {
//启动写锁
reentrantread.writeLock().lock();
try {
long waitTime=(long) (Math.random()*1000);
//设置间隔时间
Thread.sleep(waitTime);
//打印写操作
System.out.println("写了一个订单");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//释放锁
reentrantread.writeLock().unlock();
}
}
六、线程池
在将线程池之前,我们先来看线程组
1、线程组
上面的代码都是对单个线程进行操作,这并不能满足我们的需求,我们缺乏对很多个线程进行管理,比如想知道多个线程的存活状态或者遍历多个线程都会很麻烦,然后线程组就合理恰当的出现了。
什么是线程组
线程组是线程的集合,有了线程组我们能够更好的管理线程
我们可以通过enumerate()方法遍历线程组的线程,我们可以通过list()方法打印所有线程组信息。
线程组通过ThreadGroup类实现
我们来看下面代码
线程类:Searcher
import java.util.Random;
public class Searcher implements Runnable{
@Override
public void run() {
//获取线程名字
String name=Thread.currentThread().getName();
System.out.println(name);
try {
//模拟工作状态
work();
//对中断异常处理
}catch(InterruptedException e) {
//打印中断的线程
System.out.printf("Thread %s: 被中断了\n",name);
return;
}
System.out.printf("Thread %s:完成\n",name);
}
private void work() throws InterruptedException {
//随机工作
Random random=new Random();
int times=(int) (random.nextDouble()*100);
Thread.sleep(times);
}
}
测试类
public class ThreadGroupDemo {
public static void main(String[] args) {
//定义线程组,并起名为Search
ThreadGroup group=new ThreadGroup("Search");
Searcher search=new Searcher();
for(int i=0;i<10;i++) {
//分配新的Thread对象,引用线程组
Thread thread=new Thread(group,search);
//启动线程
thread.start();
//线程休眠
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println("===============");
//打印活线程的数量
System.out.printf("active 线程数量 :%d\n",group.activeCount());
System.out.println("线程组信息明细");
//获取线程组信息并打印
group.list();
System.out.println("===============");
//初始化线程组长度
Thread[] threads=new Thread[group.activeCount()];
//遍历线程组的线程
group.enumerate(threads);
//监控线程状态
waitfinish(group);
//中断线程
group.interrupt();
}
//如果活的线程数量大于9,则不断等待
private static void waitfinish(ThreadGroup group) {
//判断线程是否需要休息
while(group.activeCount()>9) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
打印结果:
Thread-0
Thread-1
Thread-2
Thread Thread-2:完成
Thread-9
Thread-8
Thread-7
Thread Thread-0:完成
Thread Thread-1:完成
Thread-6
Thread-5
Thread-4
Thread-3
Thread Thread-7:完成
===============
active 线程数量 :6
线程组信息明细
java.lang.ThreadGroup[name=Search,maxpri=10]
Thread[Thread-3,5,Search]
Thread[Thread-4,5,Search]
Thread[Thread-5,5,Search]
Thread[Thread-6,5,Search]
Thread[Thread-8,5,Search]
Thread[Thread-9,5,Search]
===============
Thread Thread-4: 被中断了
Thread Thread-6: 被中断了
Thread Thread-5: 被中断了
Thread Thread-8: 被中断了
Thread Thread-3: 被中断了
Thread Thread-9: 被中断了
线程组的缺点 :
1、能够有效管理多个线程,但是管理效率低
2、任务分配和执行过程高度耦合
3、重复创建线程,关闭线程操作,无法重用线程
线程组的诸多特点使得我们向线程池投怀送抱
2、线程池——Executors
线程组我们知道很多缺点,而线程池弥补了线程组的不足,获得了大家的认可。
线程池的特点:
1、预设好线程数量,并且可以弹性增加
2、多次执行很小很小的任务(任务分的很小)
3、任务分配和执行过程解耦
4、程序员无需关心线程池执行任务过程,由虚拟机自动执行
线程池的创建:
方式一: Executors.newFixedThreadPool(8);创建8个线程容量的线程池
方式二: Executors.newCachedThreadPool();创建线程池,线程数量根据具体使用线程数而定。
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
public class ExecutorDemo{
public static void main(String[] args) {
//方式一创建线程池,给固定的线程
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newFixedThreadPool(8);
//方式二,不指定线程数,根据线程数量开,也就是说下面执行开了50个线程一起执行
//ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
//启动50个线程
for(int i=0;i<50;i++) {
Thread thread=new Thread(()->{
System.out.println(Thread.currentThread().getName()+"正在运行");
try {
//休息片刻
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
});
//执行指定线程任务
executor.execute(thread);
}
//关闭线程池
executor.shutdown();
}
}
建议采用方式一:因为允许线程数一般不能太多,因为计算机内存核数是固定的,线程数如果太多,会很大影响性能。
主要类或接口
- Executors:用于创建线程池,线程工厂
- ExecutorService:线程池的接口,并且继承Executor接口
- ThreadPoolExecutor:线程池服务,实现ExecutorService接口
- FutureTask:Future的实现类,存储Callable返回结果,get()来获取返回值
- Callable:类似Runnable,区别是有返回值和实现方法不一样
ExecutorService的方法
| 方法 | 作用 |
|---|---|
shutdown() |
关闭线程池 |
invokeAll(Collection> tasks) |
执行给定的任务,返回持有他们的状态和结果的所有完成的期货列表 |
submit(Callable |
提交值返回任务以执行,并返回代表任务待处理结果的Future |
awaitTermination(long timeout, TimeUnit unit) |
阻止所有任务在关闭请求完成后执行,或发生超时,或当前线程中断,以先到者为准 |
ThreadPoolExecutor类的方法
| 方法 | 作用 |
|---|---|
getMaximumPoolSize() |
返回允许的最大线程数。 |
getPoolSize() |
返回池中当前的线程数。 |
getActiveCount() |
返回正在执行任务的线程的大概数量。 |
execute(Runnable command) |
在将来某个时候执行给定的任务。 |
ThreadPoolExecutor类的构造方法
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue
- corePoolSize
核心线程数目,最多保留的线程数 - maximumPoolSize 最大线程数目
- keepAliveTime 生存时间,针对
救急线程 - unit 时间单位
- workQueue 阻塞队列
- threadFactory 线程工厂,可以为线程创建时起名字
- handler 拒绝策略
注意: 这里的构造方法我们可以通过Executors的线程工厂对应设置,我们来看jdk的api图

我们通过一个案例来理解
线程类:实现Callable接口,并返回结果
import java.util.concurrent.Callable;
public class Results implements Callable<Integer>{
int start;
int end;
public Results(int start,int end) {
this.start=start;
this.end=end;
}
@Override
public Integer call() throws Exception {
int sum=0;
for(int i=start;i<=end;i++) {
sum+=i;
}
return sum;
}
}
下面我们来看Executor的具体使用
import java.util.ArrayList;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.ThreadPoolExecutor;
public class ExecutorDemo{
public static void main(String[] args) {
//开启线程池,指定线程数
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newFixedThreadPool(8);
try {
//数组集合 指定Future类的泛型
ArrayList<Future<Integer>> list=new ArrayList<>();
for(int i=0;i<10;i++) {
//定义Future类获取返回结果,分十次计算1~1000的和,submit是ExecutorService接口的方法
Future<Integer> f=executor.submit(new Results(i*100+1,(i+1)*100));
//往数组集合添加元素,也就是返回结果存到数组集合中
list.add(f);
}
System.out.printf("Main:已经完成多少个任务:%d\n",executor.getCompletedTaskCount());
//初始化总数
int sum=0;
//遍历获取
for(int i=0;i<list.size();i++) {
try {
//累加返回结果
sum+=list.get(i).get();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println("1 ~ 1000的和为:"+sum);
}finally {
//关闭线程池
executor.shutdown();
}
}
}

3、ForkJoin
ForkJoin是Java的另一个并发框架,和Executor不同的是,ForkJoin对任务进行分解、治理、合并(分治思想),适用于整体任务量不好确定的场合(最小任务可确定)
我们举例加法
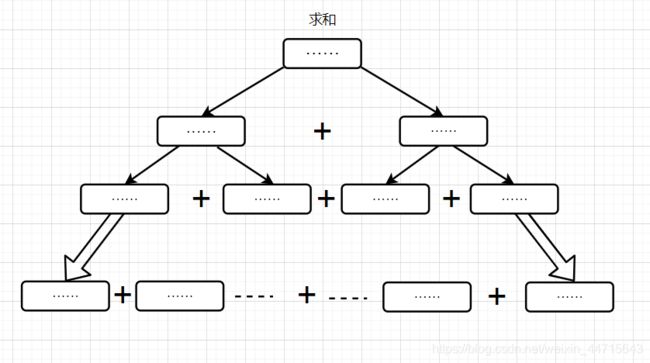
我们用到了二分法,递归
同样,我们列举出主要类:
- ForkJoinPool 任务池
- RecursiveAction 继承ForkJoinTask类,没有返回值的任务
- RecursiveTask 同样继承ForkJoinTask类,有返回值的任务
ForkJoinPool 任务池的方法
| 方法 | 作用 |
|---|---|
submit(ForkJoinTask |
提交一个ForkJoinTask来执行。 |
getPoolSize() |
返回已启动但尚未终止的工作线程数。 |
getActiveThreadCount() |
返回正在执行任务的线程的大概数量。 |
execute(ForkJoinTask task) |
为异步执行给定任务的排列。 |
invoke(ForkJoinTask |
执行给定的任务,在完成后返回其结果 |
RecursiveAction和RecursiveTask 类的重写的方法
compute() |
这个任务执行的主要计算。 |
|---|
ForkJoinTask抽象类的方法
| 方法 | 作用 |
|---|---|
fork() |
在当前任务正在运行的池中异步执行此任务 |
get() |
等待计算完成,然后检索其结果。 |
isDone() |
返回 true如果任务已完成 |
join() |
当 isDone 是true返回计算结果。 |
通过代码熟悉一下,我们先来看RecursiveTask类的使用
import java.util.concurrent.RecursiveTask;
public class ForkJoinTaskDemo extends RecursiveTask<Long>{
//小任务小于5时继续分解
private static final long MaxSize = 5;
private int start,end;
public ForkJoinTaskDemo(int start ,int end) {
this.start=start;
this.end=end;
}
@Override
protected Long compute() {
//初始化总和
Long sum=0L;
//获取有多少个数
int length=end-start;
//每次累加5个数操作
if(length<=MaxSize) {
for(int i=start;i<=end;i++) {
sum=sum+i;
}
}
else {
//切分二块任务,取中间值
int middle=(start+end)/2;
//递归调用
ForkJoinTaskDemo left=new ForkJoinTaskDemo(start,middle);
ForkJoinTaskDemo right=new ForkJoinTaskDemo(middle+1,end);
//给定线程任务,完成返回结果
invokeAll(left,right);
//左右进行计算结果返回
Long sum1=left.join();
Long sum2=right.join();
//汇总最后结果
sum=sum1+sum2;
}
//返回总数
return sum;
}
}
我们进行测试
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
public class ForkJoinMain {
public static void main(String[] args) {
//创建线程池
ForkJoinPool pool=new ForkJoinPool();
//创建任务
ForkJoinTaskDemo join=new ForkJoinTaskDemo(1,100000000);
//提交任务
ForkJoinTask<Long> result=pool.submit(join);
do {
System.out.println("当前正在运行的线程有:"+pool.getActiveThreadCount()+"个");
try {
//休眠片刻
Thread.sleep(50);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}while(!join.isDone());//获取工作线程
try {
//打印最后总数
System.out.println("和为"+result.get().toString());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//关闭线程池
pool.shutdown();
}
上面代码通过分治思想,把1~100000000的数进行累加,计算速度非常快,我们也看到线程池数量在不断的变化,默认最高线程数是电脑核数的2倍
下面我们接着看RecursiveAction类的具体使用
import java.util.concurrent.RecursiveAction;
public class ForkJoinActionDemo extends RecursiveAction{
//小任务超过5时开始采用分支计算
private static final long MaxSize = 5;
private int start,end;
public ForkJoinActionDemo(int start ,int end) {
this.start=start;
this.end=end;
}
@Override
protected void compute() {
//获取有多少个数
int length=end-start;
//但长度小于5开始执行下面代码
if(length<MaxSize) {
System.out.println("我被分解成"+length+"个后开始执行");
}else {
//切分二块任务,取中间值
int middle=(start+end)/2;
//递归调用
ForkJoinActionDemo left=new ForkJoinActionDemo(start,middle);
ForkJoinActionDemo right=new ForkJoinActionDemo(middle+1,end);
//给定线程任务,完成返回结果
invokeAll(left,right);
//异步执行
left.fork();
right.join();
}
}
}
我们接着看测试类
import java.util.concurrent.ForkJoinPool;
public class ForkJoinMain {
public static void main(String[] args) {
//创建线程池
ForkJoinPool pool=new ForkJoinPool();
//创建任务
ForkJoinActionDemo join=new ForkJoinActionDemo(1,100);
//提交任务
pool.submit(join);
do {
System.out.println("当前正在运行的线程有:"+pool.getActiveThreadCount()+"个");
try {
Thread.sleep(50);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}while(!join.isDone());
//关闭线程
pool.shutdown();
}
}
通过学习上面的代码,我们会加深ForkJoin并发框架的理解。
ForkJoin采用了分治思想,能够控制任务分解粒度,提高多线程的执行效率,线程能够复用,执行过程解耦
七、线程辅助类
1、CountDownLatch
等待锁,是一个同步辅助类,用来同步执行一个或多个进程
| 方法 | 作用 |
|---|---|
countDown() |
计数减一 |
await() |
等待latch变成0,否则不执行 |
我们通过百米赛跑的例子来看。我们知道鸣枪后才能赛跑,然后一百米后,等全部选手跑完全程表示比赛结束,忽略其他特殊情况。
import java.util.concurrent.CountDownLatch;
public class ThreadDemo {
public static void main(String[] args) {
//设置距离100米
int distance=100;
//设置选手个数
int amount=10;
//设置鸣枪计数
CountDownLatch count=new CountDownLatch(1);
CountDownLatch c=new CountDownLatch(distance);
//设置十个选手
for(int i=0;i<amount;i++) {
new Thread(()->{
try {
//等待鸣枪开始跑
count.await();
System.out.println(Thread.currentThread().getName()+"跑完了");
//计数100米,倒计时
for(int j=0;j<distance;j++) {
Thread.sleep(50);
//距离缩短
c.countDown();
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}).start();
}
System.out.println("准备比赛...");
System.out.println("比赛开始!");
//鸣枪开始,计数减一
count.countDown();
try {
//等待跑步结束
c.await();
System.out.println("比赛结束!");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
2、CyclicBarrier
集合点,和上面的CountDownLatch十分相似
构造函数是需要同步的线程数量
CyclicBarrier(int parties, Runnable barrierAction)
创建一个新的 CyclicBarrier ,当给定数量的线程(线程)等待时,它将跳闸,当屏障跳闸时执行给定的屏障动作,由最后一个进入屏障的线程执行。
| 方法 | 作用 |
|---|---|
await() |
等待其他线程到达数量后就放行 |
我们来举个例子,设置一个二维数组,然后每个线程对一行数据计算和,最后在汇总类进行汇总。
首先,我们定义汇总类,在主类中我们把每一个线程的数据存到数组中,然后传给这个类,进行计算
public class CalculateResult implements Runnable{
//结果数组
final int[] results;
//通过构造方法获取带有结果的数组
public CalculateResult(int[] results) {
this.results=results;
}
@Override
public void run() {
int sum=0;
//对结果数组累加
for(int data:results) {
sum+=data;
}
//返回最后结果
System.out.println("最终结果为:"+sum);
}
}
我们定义主类,一个线程计算一行数据,最后把结果存到数组中传给上面的汇总类。
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierDemo {
//共享成员变量num
volatile static int num=0;
public static void main(String[] args) {
//定义一个二维数组
final int[][] numbers=new int [3][5];
//定义一个数组,用于存放每个线程计算的结果
final int[] results=new int[3];
//设置一个临时变量,给二维数组赋值后就没有用了
int temp=0;
for(int i=0;i<3;i++) {
for(int j=0;j<5;j++) {
//设置二维数组的值是从1到15
temp++;
numbers[i][j]=temp;
}
}
//自定义类,把每个线程计算结果传进去,用于计算
CalculateResult result=new CalculateResult(results);
//CyclicBarrier的使用,设置3个线程,3个线程完成后直接调用自定义类的run方法
CyclicBarrier barrier=new CyclicBarrier(3,result);
//分三个线程跑三个不同的任务
for(int i=0;i<3;i++) {
new Thread(()->{
//每个线程和的初始值
int sum=0;
//把二维数组的第num行数据赋值给新数组
int[] row=numbers[num];
//遍历数组累加
for(int data:row) {
sum+=data;
//把每个线程的计算结果返回到新的数组存放
results[num]=sum;
}
//给二维数组下标加一
num++;
try {
//打印每个线程计算的结果
System.out.println(Thread.currentThread().getName()+"计算结果为:"+sum);
//关键代码,等待三个线程全部完成
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}).start();
}
}
}
通过上面代码,我们发现,CyclicBarrier辅助类很像一个集合点,>CyclicBarrier定义的线程数全部完成后,我再往下走。
3、Phaser
允许执行并发多阶段任务,同步辅助类,和上面两个辅助类不同的是,一个线程我们可以控制多个阶段执行
| 方法 | 作用 |
|---|---|
arriveAndAwaitAdvance() |
到达这个移相器,等待其他人。 |
arriveAndDeregister() |
到达这个移相器并从其中注销,而无需等待别人到达。 |
我们来课堂答题,等所有学生答完题之后再接着提问下一个问题
import java.util.concurrent.Phaser;
public class PhaserDemo {
volatile static int i;
public static void main(String[] args) {
int students=3;
Phaser phaser=new Phaser(students);
for(int j=0;j<students;j++) {
new Thread(()->{
try {
//第一题
i=1;
doWork();
//等所有学生答完
phaser.arriveAndAwaitAdvance();
//第二题
i=2;
doWork();
//等所有学生答完
phaser.arriveAndAwaitAdvance();
//第三题
i=3;
doWork();
//等所有学生答完
phaser.arriveAndAwaitAdvance();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}).start();
}
}
public static void doWork() throws InterruptedException {
String name=Thread.currentThread().getName();
System.out.println(name+"开始答题");
Thread.sleep(1000);
System.out.println(name+"第"+i+"道题答题结束");
}
}
4、Exchanger
在并发线程中互相交换信息
允许两个线程建立交换点,当两个线程都到达交互点时,数据互相交换
| 方法 | 作用 |
|---|---|
exchange(V x) |
两个线程之间互相交换信息 |
exchange(V x,long timeout, TimeUnit unit) |
等待另一个线程到达此交换点(除非当前线程为 interrupted或指定的等待时间已过),然后将给定对象传输给它,接收其对象作为回报。 |
下面我们弄一个简单的交互效果
import java.util.concurrent.Exchanger;
public class ExchangerDemo {
public static void main(String[] args) {
Exchanger<String> e=new Exchanger();
new Thread(()-> {
String speak="说:你好,我是张三";
try {
//数据交换
speak=e.exchange(speak);
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
//最后结果
System.out.println(Thread.currentThread().getName()+""+speak);
},"张三").start();
new Thread(()->{
String speak="说:你好,我是李四";
try {
//数据交换
speak=e.exchange(speak);
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
//最后结果
System.out.println(Thread.currentThread().getName()+""+speak);
},"李四").start();
}
}
运行结果
李四说:你好,我是张三
张三说:你好,我是李四
从中我们知道数据已经进行了交换
5、Semaphore
Semaphore这个辅助类可以实现限流的效果
| 方法 | 作用 |
|---|---|
acquire() |
从该信号量获取许可证,阻止直到可用,或线程为 interrupted |
release() |
释放许可证,将其返回到信号量 |
每个acquire()方法都会阻塞,直到许可证可用,然后才能使用它
每个release()添加许可证,潜在地释放阻塞获取方。
我们通过车辆检查放行进行讨论
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
public static void main(String[] args) {
//限制通过的数量
int quantity=1;
Semaphore s=new Semaphore(quantity);
new Thread(() ->{
//看是否能够acquire到,quantity的值就减一,当quantity为0时,线程就不能acquire到
try {
s.acquire();
System.out.println("检查Car1");
//阻塞片刻,此时还有取可证acquire
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName()+"放行");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
//释放信号量
s.release();
}
//启动Car1线程
},"Car1").start();
new Thread(() ->{
//看是否能够acquire到,quantity就减一,当quantity为0时,线程就不能acquire到
try {
s.acquire();
System.out.println("检查Car2");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName()+"放行");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
//释放信号量
s.release();
}
//启动Car2线程
},"Car2").start();
}
}
我们注意看quantity变量,上面代码我们给它的值是1,然后运行结果如下:
检查Car1
Car1放行
检查Car2
Car2放行
注意: 把quantity变量的值改为2之后,程序运行结果如下
检查Car1
检查Car2
Car1放行
Car2放行
通过上面的结果分析,Semaphore的有限流效果,限制最多有多少个线程同时访问,在实际开发中很实用