使用Tonic加载标准本地的事件数据
使用Tonic加载标准本地的事件数据
os.walk()
callable and optional
numpy数组的保存:二进制文件(bin or npy)
Tonic帮助文档:How do I wrap my own recordings?
如果您在磁盘上有自己的记录,并且希望使用Tonic进行快速数据加载和应用转换,那么您可以将它们包装在一个自定义类中。最简单的选择是使用torchvision DatasetFolder类。如果这不适用于您的情况,您可以编写自己的类,在其中提供init、getitem和len方法的最小集合,然后就可以开始了。这个笔记是关于从本地numpy文件读取事件记录的模板类。我们将从创建一些虚拟文件开始
1.模拟创建随机的事件流数据
程序通过np.random.rand(n_events)创建n_events个服从0-1均匀分布的随机样本值,并将其存储在numpy数组中,通过sensor_size[index]确定事件四元组中每一个元素的范围大小。dtype中确定了四元组中每个元素的数据类型为int
"""
模型创建随机的事件流数据 事件四元组
"""
import numpy as np
from tonic import Dataset, transforms
import torch
import os
sensor_size = (100, 200, 2)
n_recordings = 10 # 文件中包含10个事件流 例如 NMNIST 中包含 10000 个事件流
"""
创建随机的事件流,并且保留在本地,以二进制文件格式保留
"""
def create_random_input(
sensor_size=sensor_size,
# 事件流中的事件个数
n_events=10000,
# 事件流中的事件以元组的形式表示,('x', 'y', 't', 'p') x、y坐标 t 时间辍(微秒级别) p 事件极性 均为整型
dtype=np.dtype([("x", int), ("y", int), ("t", int), ("p", int)])
):
events = np.zeros(n_events, dtype=dtype)
# np.random.rand() 返回一个或者一组服从“0-1”均匀分布的随机样本值
# np.random.rand(5) return:[0.16132617 0.74789463 0.51725874 0.34676313 0.73510629]
# np.random.rand(n_events) * sensor_size[0] 将该组样本值中的每一个元素均乘以 sensor_size[0]
events["x"] = np.random.rand(n_events) * sensor_size[0]
events["y"] = np.random.rand(n_events) * sensor_size[1]
events["p"] = np.random.rand(n_events) * sensor_size[2]
events["t"] = np.sort(np.random.rand(n_events) * 1e6)
return events
模拟事件流效果显示:
print(create_random_input())
print(type(create_random_input()))
# 运行结果
[(91, 2, 307, 0) (38, 1, 577, 0) (95, 62, 1119, 0) ...
(60, 104, 999259, 1) (71, 20, 999370, 0) (35, 156, 999674, 0)]
<class 'numpy.ndarray'>
保存事件流数据
保存为npy格式如下图
# 将事件流数据保留到本地 保存的文件格式为 npy
[
# 数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中
np.save(f"../Tonic_dir/tutorials/data/rand_by_myself/recording{i}.npy", create_random_input())
for i in range(0,10)
]

保存为bin格式
# 将事件流数据保留到本地 文件保存的格式为 bin
[
# 数组是以未压缩的原始二进制格式保存在扩展名为.bin的文件中
create_random_input().tofile(f"../Tonic_dir/tutorials/data/rand_by_myself/recording{i}.bin")
for i in range(30,40)
]

2.继承Dataset类加载本地的事件流数据
该程序只针对 以npy为后缀的事件流数据,以bin为后缀的数据可以根据文字开头numpy数组的保存:二进制文件链接跳转,修改os.path.join(self.data_dir,f"recording{i}.npy") for i in range(n_recordings)以及events = np.load(self.filenames[index])两个部分,修改为读取bin文件的方式
使用此程序,需要修改self.data_dir即事件流文件目录路径
"""
继承Dataset类加载本地的事件流数据
"""
class MyRecordings(Dataset):
sensor_size = (
34,
34,
2,
) # the sensor size of the event camera or the number of channels of the silicon cochlear that was used
ordering = (
"xytp" # the order in which your event channels are provided in your recordings
)
def __init__(
self,
train=True,
transform=None,
target_transform=None,
):
super(MyRecordings, self).__init__(
save_to='./', transform=transform, target_transform=target_transform
)
self.train = train
# replace the strings with your training/testing file locations or pass as an argument
# 本地事件流文件路径
self.data_dir = f"../Tonic_dir/tutorials/data/rand_by_myself/Test/0"
if train:
self.filenames = [
# f"recording{i}.npy" 为 数据流文件
os.path.join(self.data_dir,f"recording{i}.npy") for i in range(n_recordings)
]
else:
raise NotImplementedError
def __getitem__(self, index):
# 加载文件中的事件流
events = np.load(self.filenames[index])
if self.transform is not None:
events = self.transform(events)
return events
def __len__(self):
return len(self.filenames)
使用程序读取事件流数据,程序并为对事件流数据进行人工标注
dataset = MyRecordings(train=True)
events = dataset[0]
print(events)
dataloader = torch.utils.data.DataLoader(dataset, shuffle=True)
events = next(iter(dataloader))
print(events)
3.加载事件流数据并对其进行人工标注
该程序改编自 tonic.datasets.NMNIST数据集加载的源码,将其网络下载的部分进行删剪得到
程序只能对以bin为后缀的事件流数据进行人工标注,因为程序中getitem()中得到对应索引的事件流数据使用的是tonic.io.read_minst_file()函数,函数经过测试得到无法对以npy为后缀的事件流数据进行解析,其中的解析算法会报错
tonic.io.read_minst_file()函数网址链接
程序中需要修改的为classes数组,根据自己数据集的标签进行修改
"""
对本地的事件流数据使用Tonic进行标注
有关网络下载的内容可以删除
Parameters:
save_to (string): Location to save files to on disk.
train (bool): If True, uses training subset, otherwise testing subset.
first_saccade_only (bool): If True, only work with events of the first of three saccades.
Results in about a third of the events overall.
如果为True,则只处理三个扫视中的第一个事件。大约三分之一的事件的结果
transform (callable, optional): A callable of transforms to apply to the data.
target_transform (callable, optional): A callable of transforms to apply to the targets/labels.
一个可调用的转换应用到目标/标签。
transforms (callable, optional): A callable of transforms that is applied to both data and
labels at the same time.
同时应用于数据和标签的转换可调用对象
"""
import os
from typing import Callable, Optional
import numpy as np
from tonic.dataset import Dataset
from tonic.io import read_mnist_file
class MYDATASET(Dataset):
train_filename = "train.zip"
train_folder = "Train"
test_filename = "test.zip"
test_folder = "Test"
classes = [
"0 - zero",
"1 - one",
]
sensor_size = (34, 34, 2)
dtype = np.dtype([("x", int), ("y", int), ("t", int), ("p", int)])
ordering = dtype.names
"""
构造函数
Callable 作为函数参数使用,其实只是做一个类型检查的作用,检查传入的参数值 get_func 是否为可调用对象
函数是可以调用的,变量是不可以调用的
Optional 可选类型 可选参数具有默认值,具有默认值的可选参数不需要在其类型批注上使用 Optional,因为它是可选的
Optional[int] 等价于 Union[int, None] 意味着:既可以传指定的类型 int,也可以传 None
如:transform: Optional[Callable]
tranform 的 参数是一个 列表,其中参数可以为 Callable(可调用对象) 类型 也可以为 None
"""
def __init__(
self,
save_to: str,
train: bool = True,
first_saccade_only: bool = False,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
transforms: Optional[Callable] = None,
):
super().__init__(
save_to,
transform=transform,
target_transform=target_transform,
transforms=transforms,
)
self.train = train
self.first_saccade_only = first_saccade_only
if train:
self.filename = self.train_filename
self.folder_name = self.train_folder
else:
self.filename = self.test_filename
self.folder_name = self.test_folder
# 在父类DataSet 中 self.location_on_system = os.path.join(save_to, self.__class__.__name__)
# self.__class__.__name__ 当前类类名 类名需要与本地的事件流数据集的外层名录名一致
# file_path = os.path.join(self.location_on_system, self.folder_name)
file_path = save_to
# os.walk扫描test文件夹下所有的子目录和文件
# 二进制事件流文件的后缀名 --- 根据自己 文件 后缀名进行修改
events_file_end = "bin"
# 事件流标签的数据类型的别名 如 NMNIST 的标签为 0到9 为 int
label_type = int
for path, dirs, files in os.walk(file_path):
# 排序
files.sort()
# file 是 最底层目录下的 二进制数据流文件
for file in files:
if file.endswith(events_file_end):
# path 事件流上层目录的路径
# self.data 列表存储了所有的 事件流二进制文件
self.data.append(path + "/" + file)
# path 路径的 最后一个名录名称
label_number = label_type(path[-1])
# self.targets 列表存储了所有的 事件流二进制文件 对应的标签
self.targets.append(label_number)
def __getitem__(self, index):
"""
Returns:
a tuple of (events, target) where target is the index of the target class.
(events, target)的元组,其中target是目标类的索引
"""
# events 得到 self.data 对应 index 索引下的 事件流文件
events = read_mnist_file(self.data[index], dtype=self.dtype)
if self.first_saccade_only:
events = events[events["t"] < 1e5]
# target 得到 self.targets 对应 index 索引下的 事件流文件所对应的标签
target = self.targets[index]
if self.transform is not None:
events = self.transform(events)
if self.target_transform is not None:
target = self.target_transform(target)
# 对事件流与标签同时进行transform
if self.transforms is not None:
events, target = self.transforms(events, target)
return events, target
# 得到文件中事件流的文件的个数
def __len__(self) -> int:
return len(self.data)
测试程序:
"""
对 MYDATASET 进行测试
"""
import tonic
import tonic.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from MYDATASET import MYDATASET
dataset = MYDATASET(save_to="/home/zxz/Proj/DP/Do/demo_03/Tonic_dir/tutorials/data/rand_by_myself",train=True)
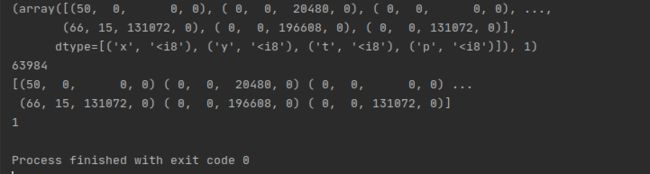
print(dataset[7])
events,target = dataset[7]
print(len(events))
print(events)
print(target)
测试效果:
注意:数据集的目录文件结构如下,其中0、1为标签