力扣算法题更新(个人笔记)
2021-8-26
1. 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。

对于这个问题有两种解法
一、暴力解决
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i=0;i<nums.size();i++)
{
for(int j=i+1;j<nums.size();j++)
{
if( (nums[i]+nums[j])==target )
{
return {i,j};
}
}
}
return {};
}
};

二、哈希表
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> hashtable;
for(int i=0;i<nums.size();i++)
{
auto it=hashtable.find(target - nums[i]);
if( it!=hashtable.end())
{
return {it->second,i};
}
hashtable[nums[i]]=i;//key是数组的值,value是数组的下标
}
return {};
}
};

2021-8-27
2.两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
这里要注意下,是按逆序存储的,这样就简单多了
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头 …


自己的解法,比较笨,而且程序也不太对,因为我这不是按逆序存储处理的.所以不对. 所以做题得看清楚啊啊!!!
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
//自己的解法---有问题太笨了
ListNode* l3;//存放最后的结果
int m1=0
int n1=0;
int s;
for(int i=1;l1!=NULL;i=i*10)
{
m1=m1+l1->val*i;
l1=l1->next;
}
for(int j=i;l2!=NULL;j=j*10)
{
n1=n1+l2->val*j;
l2=l2->next;
}
int s=m1+n1;//得到和
l3->val=s%10;
l3->next->val=s/10%10;
l3->next->next->val=s/100%10;
return l3;
}
};
官方正确解答
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode *head = nullptr, *tail = nullptr;
int carry = 0;
while (l1 || l2) {
int n1 = l1 ? l1->val: 0;
int n2 = l2 ? l2->val: 0;
int sum = n1 + n2 + carry;
if (!head) {
head = tail = new ListNode(sum % 10);
} else {
tail->next = new ListNode(sum % 10);
tail = tail->next;
}
carry = sum / 10;
if (l1) {
l1 = l1->next;
}
if (l2) {
l2 = l2->next;
}
}
if (carry > 0) {
tail->next = new ListNode(carry);
}
return head;
}
};
官方解法:

2021-8-29
3. 无重复字符的最长子串

官方答案
class Solution {
public:
//这个方法就很巧妙
//主要是用到了unordered—_set的count函数
int lengthOfLongestSubstring(string s) {
// 哈希集合,记录每个字符是否出现过
unordered_set<char> occ;
int n = s.size();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
// 枚举左指针的位置,初始值隐性地表示为 -1
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.erase(s[i - 1]);
}
while (rk + 1 < n && !occ.count(s[rk + 1])) {//occ.count(s[rk + 1])能够检测是否出现过字符[rk + 1] 出现过就返回1
// 不断地移动右指针
occ.insert(s[rk + 1]);
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1);
}
return ans;
}
};
//评论区小伙伴的解答。利用map直接找到对应字符的下标
//#include map = new HashMap<>();
// int max = 0, start = 0;
// for (int end = 0; end < s.length(); end++) {
// char ch = s.charAt(end);
// if (map.containsKey(ch)) {
// start = max(map.get(ch) + 1, start);
// }
// max = max(max, end - start + 1);
// map.put(ch, end);
// }
// return max;
// }
//};
//自己的错误的解法
//class Solution {
//public:
// int lengthOfLongestSubstring(string s) {
//int sum = 0;
//int temp;
//if (s != "")
//temp = 1;
//for (int i = 0; i < s.length(); i++)
//{
// temp = 1;
// for (int j = i + 1; j < s.length(); j++)
// {
// if (s[i] != s[i + 1])
// {
// temp++;
// }
// else
// {
// break;
// }
//
// }
// if (sum < temp)
// {
// sum = temp;
// }
//}
//return sum;
// }
//};
官方解法:

5. 最长回文子串

解法一:暴力解决



解法二: 动态规划




//给你一个字符串 s,找到 s 中最长的回文子串 2021-8-29
#include 
解法三:中心扩散

//解法3:中心扩散
//时间复杂度:O(n ^ 2)O(n
// 2
//),其中 nn 是字符串的长度。长度为 11 和 22 的回文中心分别有 nn 和 n - 1n−1 个,每个回文中心最多会向外扩展 O(n)O(n) 次。
// 空间复杂度:O(1)O(1)。
class Solution {
public:
pair<int, int> expandAroundCenter(const string& s, int left, int right) {
while (left >= 0 && right < s.size() && s[left] == s[right]) {
--left;
++right;
}
return { left + 1, right - 1 };
}
string longestPalindrome(string s) {
int start = 0, end = 0;
for (int i = 0; i < s.size(); ++i) {
//这里主要解释一下 left1, right1 left2, right2
/**
* left1, right1 : 当我们以s[i]为串的头部,我们以s[i]为中心,向两边扩展 ---以s[i]为奇数回文子串的中心
* left2, right2 : 当我们判断s[i]和s[i+1]相等时。再向两边扩展 ---以s[i]和s[i+1]为偶数回文子串的中心
* 这样根据上面两个left和right就可以算出最大回文的长度了。同时起始位置就是start,结束位置是end
*/
auto [left1, right1] = expandAroundCenter(s, i, i);
auto [left2, right2] = expandAroundCenter(s, i, i + 1);
if (right1 - left1 > end - start) {
start = left1;
end = right1;
}
if (right2 - left2 > end - start) {
start = left2;
end = right2;
}
}
return s.substr(start, end - start + 1);
}
};

解法四:Manacher算法





肯定不是蓝色但是也有可能以i为中心继续扩散,假如是黑色和紫色







class Solution {
public:
int expand(const string& s, int left, int right) {
while (left >= 0 && right < s.size() && s[left] == s[right]) {
--left;
++right;
}
return (right - left - 2) / 2;
}
string longestPalindrome(string s) {
int start = 0, end = -1;
string t = "#";
for (char c: s) {
t += c;
t += '#';
}
t += '#';
s = t;
vector<int> arm_len;
int right = -1, j = -1;
for (int i = 0; i < s.size(); ++i) {
int cur_arm_len;
if (right >= i) {
int i_sym = j * 2 - i;
int min_arm_len = min(arm_len[i_sym], right - i);
cur_arm_len = expand(s, i - min_arm_len, i + min_arm_len);
} else {
cur_arm_len = expand(s, i, i);
}
arm_len.push_back(cur_arm_len);
if (i + cur_arm_len > right) {
j = i;
right = i + cur_arm_len;
}
if (cur_arm_len * 2 + 1 > end - start) {
start = i - cur_arm_len;
end = i + cur_arm_len;
}
}
string ans;
for (int i = start; i <= end; ++i) {
if (s[i] != '#') {
ans += s[i];
}
}
return ans;
}
};
2021-8-30
9.回文整数
自己的解法1:直接算整数的逆
class Solution {
public:
bool isPalindrome(int x) {
int rev=0;
int orgin=x;
while(x!=0)
{
if(x<0||rev< -2147483648/10||rev> 2147483647/10)//判断整数是否溢出或者为负数
{
return false;
}
int digit=x%10;
rev=rev*10+digit;
x=x/10;
}
return orgin==rev;
}
};

官方的解法2:
class Solution {
public:
bool isPalindrome(int x) {
// 特殊情况:
// 如上所述,当 x < 0 时,x 不是回文数。
// 同样地,如果数字的最后一位是 0,为了使该数字为回文,
// 则其第一位数字也应该是 0
// 只有 0 满足这一属性
if (x < 0 || (x % 10 == 0 && x != 0)) {
return false;
}
int revertedNumber = 0;
while (x > revertedNumber) {
revertedNumber = revertedNumber * 10 + x % 10;
x /= 10;
}
// 当数字长度为奇数时,我们可以通过 revertedNumber/10 去除处于中位的数字。
// 例如,当输入为 12321 时,在 while 循环的末尾我们可以得到 x = 12,revertedNumber = 123,
// 由于处于中位的数字不影响回文(它总是与自己相等),所以我们可以简单地将其去除。
return x == revertedNumber || x == revertedNumber / 10;
}
};

解法3:利用容器string
#include当然在得到字符串后也可不用算法库里的字符串取逆操作,可以调用回文串判断函数,如下图所示。

这里的时间和空间的复杂度应该都是n。因为利用了string。
2021-8-31
6. Z字形变换
自己的解法:找周期规律
//这个方法是采用按顺序周期法进行结算的.
class Solution {
public:
string convert(string s, int numRows) {
vector<string> rev(numRows);
int l=s.size();
int period=numRows*2-2;
int mod;
if(numRows==1)
{
return s;
}
for(int i=0;i<l;i++)
{
mod=i%period;
if(mod<numRows)
{
rev[mod]+=s[i];
}
else
{
rev[period-mod]+=s[i];
}
}
string result;
for(auto rev1:rev)
{
result+=rev1;
}
return result;
}
};

官方解法1 :

class Solution {
public:
string convert(string s, int numRows) {
if (numRows == 1) return s;
vector<string> rows(min(numRows, int(s.size())));
int curRow = 0;
bool goingDown = false;
for (char c : s) {
rows[curRow] += c;
if (curRow == 0 || curRow == numRows - 1) goingDown = !goingDown;
curRow += goingDown ? 1 : -1;
}
string ret;
for (string row : rows) ret += row;
return ret;
}
};

官方解法2:

这个方法和自己的方法本质上原理一样 .也是找周期,然后按行读取
class Solution {
public:
string convert(string s, int numRows) {
if (numRows == 1) return s;
string ret;
int n = s.size();
int cycleLen = 2 * numRows - 2;
for (int i = 0; i < numRows; i++) {
for (int j = 0; j + i < n; j += cycleLen) {
ret += s[j + i];
if (i != 0 && i != numRows - 1 && j + cycleLen - i < n)
ret += s[j + cycleLen - i];
}
}
return ret;
}
};

2021-9-1
34. 在排序数组中查找元素的第一个和最后一个位置

自己的解法:
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
//这题用暴力解决就太蠢了
//这个方法时间复杂度应该是O(n) 空间复杂度O(1)
//int l=nums.size();
int left=0,right=nums.size()-1;
while(left<=right)
{
if(nums[left]==target&&nums[right]==target)
{
return vector<int> {left,right};
}
else if(nums[left]<target)
{
left++;
}
else if(nums[right]>target)
{
right--;
}
}
return vector<int> {-1,-1};
}
};

官方解法:二分法
class Solution {
public:
int binarySearch(vector<int>& nums, int target, bool lower) {
int left = 0, right = (int)nums.size() - 1, ans = (int)nums.size();
while(left<=right)
{//lower为true则代表要得到的是lefe_index
int mid=(left+right)/2;
if(nums[mid]>target || (nums[mid]>=target && lower) ){
right=mid-1;
ans=mid;
}
else{
left=mid+1;
}
}
return ans;
}
vector<int> searchRange(vector<int>& nums, int target) {
int leftIdx = binarySearch(nums, target, true);
int rightIdx = binarySearch(nums, target, false) - 1;
if (leftIdx <= rightIdx && rightIdx < nums.size() && nums[leftIdx] == target && nums[rightIdx] == target) {
return vector<int>{leftIdx, rightIdx};
}
return vector<int>{-1, -1};
}
};


自己的解法:
class Solution {
public:
int reverse(int x) {
//比较简单
int s;
s=0;
while(x!=0)//注意这里的判断条件要写出x!=0 不能写成x>0 因为存在负数的情况
{
if( ( s> INT_MAX / 10 )|| ( s<INT_MIN / 10 ) )
{
return 0;
}
s=s*10+ x%10 ;
x=x/10;
}
return s;
}
};

官方解法:
class Solution {
public:
int reverse(int x) {
int rev = 0;
while (x != 0) {
if (rev < INT_MIN / 10 || rev > INT_MAX / 10) {
return 0;
}
int digit = x % 10;
x /= 10;
rev = rev * 10 + digit;
}
return rev;
}
};


2021-9-2
8.字符串转换整数 aoti

class Solution {
public:
int myAtoi(string s) {
int sum=0;
int flag=1;
int i=0;
while(s[i]==' ')
{
i++;
}
if(s[i]=='-')
{
flag=-1;
}
if(s[i]=='+'||s[i]=='-')
{
i++;
}
while(i<s.size()&&isdigit(s[i]))
{
int inter=s[i]-'0';
if(sum>INT_MAX/10|| (sum==INT_MAX/10 && inter>7) )
{
return flag>0?INT_MAX:INT_MIN;
}
sum=sum*10+inter;
i++;
}
return flag>0?sum:-sum;
return sum;
}
};


解法2:自动机


//自动机其实就是列表格,把各种可能性放进去
class Automation{
string state="start";//
unordered_map<string,vector<string>> table={
{"start",{"start","signed","in_number","end"}},
{"signed",{"end","end","in_number","end"}},
{"in_number",{"end","end","in_number","end"}},
{"end",{"end","end","end","end"}}
};
int get_col(char c)//获得表第二维的索引
{
if (isspace(c)) return 0;
if (c == '+' or c == '-') return 1;
if (isdigit(c)) return 2;
return 3;
}
public:
int sign=1;
long long ans=0;
void get(char c)
{
state = table[state][get_col(c)];//更新state
if(state=="in_number")
{
ans = ans * 10 + c - '0';
ans=sign==1 ? min(ans, (long long)INT_MAX): min(ans, -(long long)INT_MIN);
}
else if (state == "signed")
sign = c == '+' ? 1 : -1;
}
};
class Solution {
public:
int myAtoi(string s) {
Automation automaton;
for (char c : s)
automaton.get(c);
return automaton.sign * automaton.ans;
}
};


2021-9-3
12. 整数转罗马数字


解法1:

const pair<int,string> valuesSymbols[]={
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
};
class Solution {
public:
string intToRoman(int num) {
string roma;
for(const auto &[value,symbol]:valuesSymbols)
{
while(num>=value)
{
num-=value;
roma+=symbol;
}
if(num==0)
{
break;
}
}
return roma;
}
};


解法2:


const string thousands[] = {"", "M", "MM", "MMM"};
const string hundreds[] = {"", "C", "CC", "CCC", "CD", "D", "DC", "DCC", "DCCC", "CM"};
const string tens[] = {"", "X", "XX", "XXX", "XL", "L", "LX", "LXX", "LXXX", "XC"};
const string ones[] = {"", "I", "II", "III", "IV", "V", "VI", "VII", "VIII", "IX"};
class Solution{
public:
string intToRoman(int num)
{
return thousands[num/1000]+hundreds[num%1000/100]+tens[num%100/10]+ones[num%10];
}
};


2021-9-4
13. 罗马数字转整数



class Solution {
private:
unordered_map<char,int> Symbolsvalues={
{'I',1},
{'V',5},
{'X',10},
{'L',50},
{'C',100},
{'D',500},
{'M',1000},
};
public:
int romanToInt(string s) {
int n=s.length();
int result =0;
for(int i=0;i<n;i++)
{
int value=Symbolsvalues[s[i]];
if( i<n-1 && value<Symbolsvalues[s[i+1]] )
{
result-=value;
}
else
{
result+=value;
}
}
return result;
}
};


解法2:其实和解法1一样 但是更好理解,因为是从右往左。
class Solution {
private:
unordered_map<char,int> Symbolsvalues={
{'I',1},
{'V',5},
{'X',10},
{'L',50},
{'C',100},
{'D',500},
{'M',1000},
};
public:
int romanToInt(string s) {
int n=s.length();
int result=0;
int highestvalue=1;
for(int i=n-1 ;i>=0 ; i--)
{
int value=Symbolsvalues[s[i]];
if(value>=highestvalue)
{
result+=value;
highestvalue=value;
}
else
{
result-=value;
}
}
return result;
}
};

14. 最长公共前缀
解法1:

class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if(!strs.size())
{
return "";
}
string Prefix=strs[0];
for(int i=1;i<strs.size();i++)
{
Prefix=longestCommonPrefix(Prefix,strs[i]);
if(!Prefix.size())
{
break;
}
}
return Prefix;
}
//截取两个字符串的公共前缀---重载
string longestCommonPrefix(string &str1,string &str2) {
int l=min(str1.length(),str2.length());
string Prefix;
for(int i=0;i<l;i++)
{
if(str1[i]==str2[i])
{
Prefix+=str1[i];
}
else
{
break;
}
}
return Prefix;
}
};


解法2:

//解法2:纵向扫描
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if(!strs.size())
{
return "";
}
int length=strs[0].size();
for(int i=0;i<length;i++)
{
char c=strs[0][i];
for(int j=1;j<strs.size();j++)
{
if(i==strs[j].size() || c!=strs[j][i])
{
return strs[0].substr(0,i);
}
}
}
return strs[0];//表面strs[0]的所有字符串都通过公共前缀的验证了
}
};


还有两种解法,明天更新。
解法3:
用到了递归,麻烦的很!


//解法3:分治法 这个方法代码的递归有点绕
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if(!strs.size())
{
return "";
}
else
{
return longestCommonPrefix(strs, 0, strs.size() - 1);
}
}
//以总共有8个字符串为例
string longestCommonPrefix(vector<string>& strs, int start, int end) {
if(start==end)
{
return strs[start];
}
else
{
int mid=(start+end)/2;
string left=longestCommonPrefix(strs,start,mid);//这个地方递归结束后,就会回来执行下面的语句,就可以得到左边两个字符串的公共前缀,然后再次返回,然后对下面的语句做递归,就可以把左边组的右边两个的公共前缀找到,再返回左边四个的公共前缀找到,后面就是找右边组的公共前缀了
string right=longestCommonPrefix(strs,mid+1,end);//
return longestCommonPrefix(left,right);
}
}
//截取两个字符串的公共前缀---重载
string longestCommonPrefix(string &str1,string &str2) {
int l=min(str1.length(),str2.length());
string Prefix;
for(int i=0;i<l;i++)
{
if(str1[i]==str2[i])
{
Prefix+=str1[i];
}
else
{
break;
}
}
return Prefix;
}
};


解法4:

//解法4:二分法
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if(!strs.size())
{
return "";
}
int minLength =
min_element(strs.begin(), strs.end(), [](const string& s, const string& t) {return s.size() < t.size();})->size(); //这里面放了一个仿函数当作谓语
int low=0;
int high=minLength;
//向前向后都是移动两位
while(low<high)
{
int mid=(high-low+1)/2+low;//mid移动两位
if(isCommonPrefix(strs,mid))
{
low=mid;//low移动到mid
}
else
{
high=mid-1;
}
}
return strs[0].substr(0,low);
}
bool isCommonPrefix(const vector<string>& strs,int length)
{
string str0=strs[0].substr(0,length);//拿到第一个字符串
//后面依次跟其他的字符串进行公共前缀的比较
for(int i=1;i<strs.size();i++)
{
string str=strs[i];
for(int j=0;j<length;j++)
{
if(str0[j]!=str[j])
{
return false;
}
}
}
return true;
}
};



2021-9-6
17. 电话号码的字母组合


解法1:追溯
//解法1:采用递归
class Solution {
public:
string tmp;
vector<string> res;
vector<string> Alpha={"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};
void DFS(int pos ,string digits)
{
if(pos==digits.size())
{
res.push_back(tmp);
return ;//此次递归结束
}
int num=digits[pos]-'0';//得到数字的整形
for(int i=0;i<Alpha[num].size();i++)
{
tmp.push_back(Alpha[num][i]);//一个一个的把字母放在tmp
DFS(pos+1,digits);
tmp.pop_back();//因为要重新给tmp写入新的组合,所以把后一个字符抹掉
}
}
vector<string> letterCombinations(string digits) {
if(digits.size()==0) return res;
DFS(0,digits);
return res;
}
};
官方代码:
class Solution {
public:
vector<string> letterCombinations(string digits) {
vector<string> combinations;
if (digits.empty()) {
return combinations;
}
unordered_map<char, string> phoneMap{
{'2', "abc"},
{'3', "def"},
{'4', "ghi"},
{'5', "jkl"},
{'6', "mno"},
{'7', "pqrs"},
{'8', "tuv"},
{'9', "wxyz"}
};
string combination;
backtrack(combinations, phoneMap, digits, 0, combination);
return combinations;
}
void backtrack(vector<string>& combinations, const unordered_map<char, string>& phoneMap, const string& digits, int index, string& combination) {
if (index == digits.length()) {
combinations.push_back(combination);
} else {
char digit = digits[index];
const string& letters = phoneMap.at(digit);
for (const char& letter: letters) {
combination.push_back(letter);
backtrack(combinations, phoneMap, digits, index + 1, combination);
combination.pop_back();
}
}
}
};


解法2:深度优先



流程如下:
以“23”为例
2对应abc
3对应def
利用递归,先 遍历d e f放在partialAnswers里面,让后回到上一次的solver函数,然后遍历a b c
把 d e f 依次与 a b c都加起来构成answer 也就是 ad ae af bd be bf cd ce cf


枚举了所有的解,所以复杂度都是
解法3:广度优先


利用队列的每个节点,依次弹出相应字符串的字母。
比如先弹出a b c 然后利用下个节点的弹出,来进行字母的组合



2021-9-7
21. 合并两个有序链表


解法1:递归

这里的递归,其实就是这样,先想好最后执行merge的判断, 肯定是l1或者l2为空,然后相应的把他们返回即可。
然后递归的话,就是判断 l1->val < l2->val。
如果 l1->val < l2->val 成立,那么就进入merge(l1->next,l2)//l1要变成下一个,l2不变
相反, 如果l1->val < l2->val 成立,那么就进入merge(l1,l2->next)//l2要变成下一个,l1不变
按照上述条件进行递归。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
//解法1:递归
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(l1==NULL)
{
return l2;
}
else if(l2==NULL)
{
return l1;
}
else if(l1->val<l2->val)
{
l1->next=mergeTwoLists(l1->next,l2);
return l1;
}
else
{
l2->next=mergeTwoLists(l1,l2->next);
return l2;
}
}
};


解法2:迭代

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
//解法2:迭代 预设一个头节点
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode *pre_head =new ListNode(-1);
ListNode *prev = pre_head;
while(l1!=NULL&& l2!=NULL)
{
if(l1->val<=l2->val)
{
prev->next=l1;
l1=l1->next;
}
else
{
prev->next=l2;
l2=l2->next;
}
prev=prev->next;
}
prev->next=l1==NULL?l2:l1;
return pre_head->next;
}
};


2021-9-9
16. 最接近的三数之和

解法1:双指针
参考链接
//解法1:双指针
class Solution {
public:
int threeSumClosest(vector<int>& nums, int target) {
//排序
sort(nums.begin(),nums.end());
int n=nums.size();
int ans=nums[0]+nums[1]+nums[2];
for(int i=0;i<n;i++)
{
int s=i+1;//start
int e=n-1;//end
while(s<e)
{
int sum=nums[i]+nums[s]+nums[e];
if(fabs(target-sum)<fabs(target-ans))
{
ans=sum;//更新ans
}
if(sum>target)
{
e--;
}
else if(sum<target)
{
s++;
}
else
{
return ans;
}
}
}
return ans;
}
};


官方解法:和上面的解法一样,只是减少了某些情况下的枚举次数。

class Solution {
public:
int threeSumClosest(vector<int>& nums, int target) {
sort(nums.begin(), nums.end());
int n = nums.size();
int best = 1e7;
// 根据差值的绝对值来更新答案
auto update = [&](int cur) {
if (abs(cur - target) < abs(best - target)) {
best = cur;
}
};
// 枚举 a
for (int i = 0; i < n; ++i) {
// 保证和上一次枚举的元素不相等 这里其实就是个小优化了,减少枚举次数
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
// 使用双指针枚举 b 和 c
int j = i + 1, k = n - 1;
while (j < k) {
int sum = nums[i] + nums[j] + nums[k];
// 如果和为 target 直接返回答案
if (sum == target) {
return target;
}
update(sum);
if (sum > target) {
// 如果和大于 target,移动 c 对应的指针
int k0 = k - 1;
// 移动到下一个不相等的元素 而且j与k不能重合 这里其实就是个小优化了,减少枚举次数
while (j < k0 && nums[k0] == nums[k]) {
--k0;
}
k = k0;
} else {
// 如果和小于 target,移动 b 对应的指针
int j0 = j + 1;
// 移动到下一个不相等的元素 而且j与k不能重合 这里其实就是个小优化了,减少枚举次数
while (j0 < k && nums[j0] == nums[j]) {
++j0;
}
j = j0;
}
}
}
return best;
}
};

2021-9-10
25. K 个一组翻转链表



还是有难度的。
我们先把题目分成两个子问题,第一个子问题用来做一组反转的。第一个子问题结束后,来做将反转后的子链表接回到原链表的第二个字问题。
第一个字问题:将一组子链表进行反转
第二个字问题:将反转后的子链表接回到原链表
解法1:


参考
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
//子问题1:子链表反转
pair<ListNode* ,ListNode *> reverse(ListNode* head,ListNode* tail)
{
ListNode* prev=tail->next;
ListNode* p=head;
while(prev!=tail)
{
ListNode* nex=p->next;
p->next=prev;
prev=p;
p=nex;
}
return {tail,head};
}
ListNode* reverseKGroup(ListNode* head, int k) {
//定义一个伪的头
ListNode* hair=new ListNode(0);
hair->next=head;
ListNode* pre=hair;//pre是可以变换的 用于组组接的衔接
while(head)
{
ListNode* tail=pre;
//找到每组的尾
for(int i=0;i<k;i++)
{
tail=tail->next;
if(!tail)
{
return hair->next;//返回第一个节点
}
}
ListNode *nex;//用于前一组的尾与后一组头的衔接
tie(head,tail)=reverse(head,tail);
pre->next=head;//更新pre 这个当前组的伪头
tail->next=nex;//前一组的尾与后一组头的衔接
pre=tail;//更新pre 为后一组的伪头
head=tail->next;//更新head为后一组的头
}
return hair->next;
}
};




2021-9-11
20. 有效的括号


括号的匹配问题,用栈就可以很好的解决了,这也说明了数据结构的重要性。
解法:


class Solution {
public:
bool isValid(string s) {
//正确的输入都是偶数个字符
int n = s.size();
if (n % 2 == 1)
{
return false;
}
//利用stack来实现匹配 这样的思想在逆波兰计算器也有体现,利用栈的pop
unordered_map<char, char> pairs = {
{')', '('},
{']', '['},
{'}', '{'}
};
stack<char> stk;
for(auto c:s)
{
if(pairs.count(c))//connt用来查找key 也就是pair.first
{
if(stk.empty() || stk.top()!=pairs[c])//通过栈顶实现匹配
{
return false;
}
stk.pop();
}
else
{
stk.push(c);
}
}
return stk.empty();//如果全都弹出了,就是true 因为匹配成功了都会弹出来
}
};


2021-9-13
26. 删除有序数组中的重复项


这个题目要有一定反向思维,碰到这个题目的时候,可能首先想去判断等不等 重不重复的问题
但其实我们可以利用不相等进行实现…
利用两个指针,一个fast 一个slow
fast从 1到n-1
slow刚开始再1 之后判断fast 与fast 是否相等,不相等 把fast的值赋给 slow位置,fast越界后,返回slow,即为不重复数字的个数。





官方解释:

class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int n=nums.size();
if(n==0)
{
return 0;
}
int fast=1;
int slow=1;
while(fast<n)
{
if(nums[fast]!=nums[fast-1])
{
nums[slow]=nums[fast];
slow++;
}
fast++;
}
return slow;
}
};


2021-9-14
27. 移除元素


解法1:双指针
很简单 看代码就懂了
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
//双指针
//左指针 右指针 右指针来判断是否是目标值,左指针接受不是目标值的值
int n=nums.size();
int left=0;
int right=0;
for(;right<n;right++)
{
if(nums[right]!=val)
{
nums[left]=nums[right];
left++;
}
}
return left;
}
};


解法2:双指针优化
首先 这个题目并没有对改变后的数组元素的顺序有什么要求。
我们就可以用下面的方法:

//解法2:双指针优化 不考虑改变后数组元素的顺序
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
//双指针
//指针 右指针
int left=0;
int right=nums.size();
while(left<right)
{
if(nums[left]==val)
{
nums[left]=nums[right-1];
right--;
}
else
{
left++;
}
}
return left;
}
};


2021-9-16
28. 实现 strStr()

解法1:暴力匹配
//解法1:暴力匹配
class Solution {
public:
int strStr(string haystack, string needle) {
int n=haystack.size();
int m=needle.size();
if(needle=="")
{
return 0;
}
for(int i=0;i<=n-m;i++)
{
bool flag=true;
for(int j=0;j<m;j++)
{
if(haystack[i+j]!=needle[j])
{
flag=false;
break;
}
}
if(flag)
{
return i;
}
}
return -1;
}
};


解法2:KMP算法
参考!!!

还是有点云里雾里的
class Solution {
public:
int strStr(string s, string p) {
int n = s.size(), m = p.size();
if(m == 0) return 0;
//设置哨兵
s.insert(s.begin(),' ');
p.insert(p.begin(),' ');
vector<int> next(m + 1);
//预处理next数组
for(int i = 2, j = 0; i <= m; i++){
while(j and p[i] != p[j + 1]) j = next[j];
if(p[i] == p[j + 1]) j++;
next[i] = j;
}
//匹配过程
for(int i = 1, j = 0; i <= n; i++){
while(j and s[i] != p[j + 1]) j = next[j];
if(s[i] == p[j + 1]) j++;
if(j == m) return i - m;
}
return -1;
}
};


2021-9-22
36. 有效的数独




class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
//最笨的办法就是BF咯
//想想其他方法 我们可以利用其他的结果数组来记录各个数字出现的次数
// row[i][] 记录第i行各个数字出现的次数 比如数字9的次数存放在row[i][8]里
// col[j][] 记录第j列各个数字出现的次数
// matrix[3][3][k] 记录3x3矩阵里各个数字出现的次数
int row[9][9];
int col[9][9];
int matrix[3][3][9];
int i,j;
//一定要记得数组初始化
memset(row,0,sizeof(row));
memset(col,0,sizeof(col));
memset(matrix,0,sizeof(matrix));
for(i=0;i<9;i++)
{
for(j=0;j<9;j++)
{
char c=board[i][j];
if(c!='.')
{
int index=c-'0'-1;
row[i][index]++;
col[j][index]++;
matrix[i/3][j/3][index]++;
if(row[i][index]>1 || col[j][index]>1 || matrix[i/3][j/3][index]>1)
{
return false;
}
}
}
}
return true;
}
};
memset()用法


这么简单的题
想了半天
我真是不适合做程序员啊!!!
2021-9-24
35. 搜索插入位置


解析
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
//二分法
//
int n=nums.size();
int left=0;
int right=n-1;
int ans=n;//
while(left<=right)
{
int mid=(right-left)/2+left;
if(target<= nums[mid])
{
ans=mid;
right=mid-1;
}
else
{
left=mid+1;
}
}
return ans;
}
};


39. 组合总和

这个题目有点难度
代码流程如下
解析
emplace_back
class Solution {
public:
void dfs(vector<int>& candidates, int target, vector<vector<int>>& ans, vector<int>& combine, int idx)
{
if(idx==candidates.size())
{
return;
}
if(target==0)
{
ans.emplace_back(combine);//emplace_back效率比push_back高
return;
}
dfs(candidates,target,ans,combine,idx+1);
if(target-candidates[idx]>=0)
{
combine.emplace_back(candidates[idx]);
dfs(candidates,target-candidates[idx],ans,combine,idx);
combine.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
//感觉挺复杂的
//回溯法
vector<vector<int>> ans;
vector<int> combine;
dfs(candidates, target, ans, combine, 0);
return ans;
}
};


2021-9-27
29. 两数相除

记住
fabs(-2147483648)=-2147483648
int divide(int a, int b) {
if (a == INT_MIN && b == -1) return INT_MAX;
int sign = (a > 0) ^ (b > 0) ? -1 : 1;//使用异或看着舒服多了
//把它们都变成负数来处理
//如果使用fabs的话 会遇到fabs(-2147483648)=-2147483648 的尴尬情形
if (a > 0) a = -a;
if (b > 0) b = -b;
unsigned int res = 0;
while (a <= b) {
a -= b;
res++;
}
return sign == 1 ? res : -res;
}


优化


为什么是logn*logn ,因为从22到10 ,从10到4,从4到1需要logn
int divide(int a, int b) {
if (a == INT_MIN && b == -1) return INT_MAX;
int sign = (a > 0) ^ (b > 0) ? -1 : 1;
if (a > 0) a = -a;
if (b > 0) b = -b;
unsigned int res = 0;
//这里的a和b都是负数
while (a <= b) {
int value = b;
// 如果不用 unsigned 的话,那么当 a = -2147483648, b = 1 的时候,k 会越界
unsigned int k = 1;
// 0xc0000000 是十进制 -2^30 的十六进制的表示
// 判断 value >= 0xc0000000 的原因:保证 value + value 不会溢出
// 可以这样判断的原因是:0xc0000000 是最小值 -2^31 的一半,
// 而 a 的值不可能比 -2^31 还要小,所以 value 不可能比 0xc0000000 小
while (value >= 0xc0000000 && a <= value + value) {
k += k;
value += value;
}
a -= value;
res += k;
}
// bug 修复:因为不能使用乘号,所以将乘号换成三目运算符
return sign == 1 ? res : -res;
}


再次优化

3<



class Solution {
public:
int divide(int dividend, int divisor) {
//这里是c++实现的代码。视频是java讲的,所以有点不一样
//特殊判断
if (dividend == INT_MIN && divisor == -1) return INT_MAX;
int sign = (dividend > 0) ^ (divisor > 0) ? -1 : 1;
unsigned int ua = abs(dividend);
unsigned int ub = abs(divisor);
unsigned int res = 0;
for(int i=31;i>=0;i--)
{
if( (ua>>i)>=ub )//等同于 ua>= ub<
{
ua=ua-(ub<<i);
res+=1<<i;//也就是k
}
}
// bug 修复:因为不能使用乘号,所以将乘号换成三目运算符
return sign == 1 ? res : -res;
}
};


解析
2021-9-30
53. 最大子序和
 解法1:动态规划1
解法1:动态规划1

class Solution {
public:
int maxSubArray(vector<int>& nums) {
//
int ans,maxans=nums[0];
int pre=0;
for(int i=0;i<nums.size();i++)
{
pre=max(pre+nums[i],nums[i]);
maxans=max(maxans,pre);
}
return maxans;
}
};


解法2:动态规划2

class Solution {
public:
//动态规划2
int maxSubArray(vector<int>& nums) {
int numSize=nums.size();
int sum=0;
for(int i=1;i<numSize;i++)
{
if(nums[i-1]>0)
{
nums[i]+=nums[i-1];
}
}
int result=findMax(nums);
return result;
}
int findMax(vector<int> vec) {
int max =INT_MIN;
for (auto v : vec) {
if (max < v) max = v;
}
return max;
}
};


解法3:贪心算法

class Solution
{
public:
int maxSubArray(vector<int> &nums)
{
//类似寻找最大最小值的题目,初始值一定要定义成理论上的最小最大值
int result = INT_MIN;
int numsSize = int(nums.size());
int sum = 0;
for (int i = 0; i < numsSize; i++)
{
sum += nums[i];
result = max(result, sum);
//如果sum < 0,重新开始找子序串
if (sum < 0)
{
sum = 0;
}
}
return result;
}
};


解法4:分治
解析
class Solution {
public:
//分治算法
int maxSubArray(vector<int>& nums) {
int result=INT_MIN;
int numSize=int(nums.size());
result=maxSubArraySolver(nums,0,numSize-1);
return result;
}
int maxSubArraySolver(vector<int>& nums,int left,int right)
{
if(left==right)
{
return nums[left];
}
int mid=(left+right)/2;
//递归调用
int leftSum=maxSubArraySolver(nums,left,mid);//分组后左边最大的连续和
int rightSum=maxSubArraySolver(nums,mid+1,right);//分组后右边最大的连续和
int midSum=findMaxCrossingSubarray(nums,left,mid,right); //考虑连续元素最大值跨中间的情况
int result= max(leftSum,rightSum);
result=max(result,midSum);
return result;
}
//考虑连续元素最大值跨中间的情况
int findMaxCrossingSubarray(vector<int>& nums,int left,int mid,int right)
{
int leftSum=INT_MIN;
int sum=0;
for(int i=mid;i>=left;i--)
{
sum+=nums[i];
leftSum=max(leftSum,sum);
}
int rightSum=INT_MIN;
sum=0;
for(int j=mid+1;j<=right;j++)
{
sum+=nums[j];
rightSum=max(rightSum,sum);
}
return rightSum+leftSum;;
}
};




这里的方法一和方法二指的是 动态规划1和分治。
2021-10-5
46. 全排列

解法:回溯


解析
class Solution {
public:
void back_track(vector<vector<int>> &res,vector<int>& output,int first,int len)
{
//递归推出的条件0
if(first==len)
{
res.emplace_back(output);
return;
}
for(int i=first;i<len;i++)
{
swap(output[i],output[first]);
back_track(res,output,first+1,len);
swap(output[i],output[first]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
//首先全排列的子排列的元素个数和原数组元素个数相同
//采用 回溯
vector<vector<int> > res;
back_track(res, nums, 0, (int)nums.size());
return res;
}
};


94. 二叉树的中序遍历



解法1:递归

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void InorderTraverse(TreeNode *T,vector<int> &res)
{
if(T==nullptr)
{
return;
}
InorderTraverse(T->left,res);//递归到左孩子
res.push_back(T->val);
InorderTraverse(T->right,res);//递归到右孩子
}
vector<int> inorderTraversal(TreeNode* root) {
//当作复习一下二叉树的中序遍历
//用递归
vector<int> res;
InorderTraverse(root,res);
return res;
}
};


解法2:迭代
//解法2:迭代 难一点 牛的啊 利用栈来实现
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
//当作复习一下二叉树的中序遍历
//用迭代
vector<int> res;
stack<TreeNode* > stk;
while(root!=nullptr|| !stk.empty())
{
while(root!=nullptr)
{
stk.push(root);
root=root->left;
}
root=stk.top();
stk.pop();
res.push_back(root->val);
root=root->right;
}
return res;
}
};


解法3:Morris 中序遍历
解析


//解法3:利用前驱
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
TreeNode *predecessor = nullptr;
while (root != nullptr)
{
if (root->left != nullptr)
{
// predecessor 节点就是当前 root 节点向左走一步,然后一直向右走至无法走为止
predecessor = root->left;
while (predecessor->right != nullptr && predecessor->right != root)
{
predecessor = predecessor->right;
}
// 让 predecessor 的右指针指向 root,继续遍历左子树
if (predecessor->right == nullptr)
{
predecessor->right = root;//设置predecessor的后继是root 也可以理解为root的前驱是predecessor
root = root->left;
}
// 说明左子树已经访问完了,我们需要断开链接
else
{
res.push_back(root->val);
predecessor->right = nullptr;
root = root->right;
}
}
// 如果没有左孩子,则直接访问右孩子
else
{
res.push_back(root->val);
root = root->right;
}
}
return res;
}
};


2021-10-7
48. 旋转图像


解析
解法1:使用辅助数组

//解法1:辅助函数法
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n=matrix.size();//获取二维数组的维度 也就是最外层矩形框的边长
auto matrix_new=matrix;
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)//
{
matrix_new[i][j]=matrix[n-1-j][i];//这个公式就是 后面的列=前面的行,后面的行=n-1-是前面的列
}
}
matrix=matrix_new;
}
};


解法2:原地旋转



//解法2:原地旋转 一次四个数交换,四个数之间相隔n n为数组维度
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
//直接修改输入的二维矩阵
int n=matrix.size();//获取二维数组的维度 也就是最外层矩形框的边长
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)//这里写成n+1是要考虑维度为奇数的时候 使得所有数都能够交换
{
int temp=matrix[i][j];
matrix[i][j]=matrix[n-1-j][i];//这个公式就是 后面的列=前面的行,后面的行=n-1-是前面的列
matrix[n-1-j][i]=matrix[n-1-i][n-1-j];
matrix[n-1-i][n-1-j]=matrix[j][n-1-i];
matrix[j][n-1-i]=temp;
}
}
}
};


解法3:用翻转代替旋转

//解法3:辅助函数法
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
//直接修改输入的二维矩阵
int n=matrix.size();//获取二维数组的维度 也就是最外层矩形框的边长
//水平翻转
for(int i=0;i<n/2;i++)
{
for(int j=0;j<n;j++)
{
swap(matrix[i][j],matrix[n-1-i][j]);
}
}
//对角线翻转
for(int i=0;i<n;i++)
{
for(int j=0;j<i;j++)//j
{
swap(matrix[i][j],matrix[j][i]);
}
}
}
};


88. 合并两个有序数组
解析
解法1:直接合并后排序
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for (int i = 0; i != n; ++i) {
nums1[m + i] = nums2[i];
}
sort(nums1.begin(), nums1.end());
}
};
快速排序


解法2:双指针

//解法2:双指针
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int p1=0,p2=0;
int sorted[m+n];
int temp;
while(p1<m||p2<n)
{
if(p1==m)
{
temp=nums2[p2++];
}
else if(p2==n)
{
temp=nums1[p1++];
}
else if(nums1[p1]<nums2[p2])
{
temp=nums1[p1++];
}
else
{
temp=nums2[p2++];
}
sorted[p1+p2-1]=temp;//p1+p2-1 因为有一个往后面移一位
}
for(int i=0;i<m+n;i++)
{
nums1[i]=sorted[i];
}
}
};


解法3:逆向双指针

//解法3:逆双指针 从后面遍历 直接覆盖0就完事了
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int p1=m-1,p2=n-1;
int tail=m+n-1;
int temp;
while(p1>=0||p2>=0)
{
if(p1==-1)
{
temp=nums2[p2--];
}
else if(p2==-1)
{
temp=nums1[p1--];
}
else if(nums1[p1]>nums2[p2])
{
temp=nums1[p1--];
}
else
{
temp=nums2[p2--];
}
nums1[tail--]=temp;
}
}
};


2021-10-8
47. 全排列 II

解析
解法:追溯+剪切

class Solution {
public:
void dfs(vector<int>nums ,vector<int>& temp,vector<vector<int>>& res,vector<bool>& used)
{
if (temp.size() == nums.size())
{
res.emplace_back(temp);
return;
}
for(int i=0;i<nums.size();i++)
{
if (used[i]) continue;
// 去重的条件
// 这里还是很难理解的!!!
// 对于 !used[i - 1] 的解释请见 issue:https://gitee.com/douma_edu/douma_algo_training_camp/issues/I48M6Q
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) continue; //used[i - 1]为真代表上一节点已经遍历过 既然遍历过 即不再当前路径temp下 就取反 这是视频里的解释
//我对used[i - 1]的理解是 为了防止 nums 中相邻两个元素一样的情况下把这次情况给跳过 ,比如nums=112
//这个时候1 1都应该放在temp里面 但是如果只有nums[i] == nums[i - 1]这一个条件 就会把这个第二个1跳过 当然不行了 加上!used[i - 1]后就没有问题了
//当上一节点完全遍历完了,它就会这个节点对应的used就会变成false 这是要点!!!!
temp.push_back(nums[i]);
used[i] = true;
dfs(nums, temp, res, used);
temp.pop_back();
used[i] = false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
//首先全排列的子排列的元素个数和原数组元素个数相同
//采用 回溯 剪切去重
sort(nums.begin(), nums.end());// 排序,去重的基础这个排序是前提
vector<vector<int> > res;
vector<int> temp;//
vector<bool> used = vector<bool>(nums.size());//
dfs(nums, temp, res,used);
return res;
}
};


2021-10-9
40. 组合总和 II

这道题结合上面的全排列II的代码来看比较好。
解析
class Solution {
public:
void dfs(vector<int>& candidates, int start,int target, vector<int>& temp,vector<vector<int>>& res)
{
if(target==0)
{
res.emplace_back(temp);
return;
}
for(int i=start;i<candidates.size() && target-candidates[i]>=0;i++)
{
if(i>start && candidates[i]==candidates[i-1]) //这里的start其实和全排列II里面的used作用类似
{
continue;
}
temp.push_back(candidates[i]);
dfs(candidates,i+1,target-candidates[i],temp,res);
temp.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target)
{
//组合总和II和组合总和I 不同的是 组合总和II的candidates里面有重复的元素 因此我们需要一个数组来标记已经用过的数
vector<vector<int>> res;
vector<int> temp;
sort(candidates.begin(),candidates.end());//去重的基础
dfs(candidates,0,target,temp,res);
return res;
}
};


58. 最后一个单词的长度


解法:反向遍历
超简单!
class Solution {
public:
int lengthOfLastWord(string s) {
int n=s.size();
int e=n-1;
int count =0;
while( s[e]==' ')
{
e--;
}
while(e>=0 && s[e]!=' ')
{
count++;
e--;
}
return count;
}
};


83. 删除排序链表中的重复元素



/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
//遍历链表
ListNode* p;
if(!head)
{
return head;
}
p=head;
while(p->next)//p->next 不能用p来判断
{
if(p->val==p->next->val)
{
p->next=p->next->next;
}
else//这里要在else里面改变p的值
{
p=p->next;
}
}
return head;
}
};


2021-10-10
49. 字母异位词分组

解法1:哈希表排序

//解法1:哈希表排序
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> mp;
vector<vector<string>> res;
for(auto &str:strs)
{
string key=str;
sort(key.begin(),key.end());
mp[key].emplace_back(str);
}
for(unordered_map<string,vector<string>>::iterator it=mp.begin();it!=mp.end();it++)
{
res.emplace_back(it->second);
}
return res;
}
};


解法2:计数

class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
// 自定义对 array 类型的哈希函数 这里自定义了哈希函数 是为了避免冲突
auto arrayHash = [fn = hash<int>{}] (const array<int, 26>& arr) -> size_t
{
return accumulate
( arr.begin(), arr.end(), 0u, [&](size_t acc, int num)
{
return (acc << 1) ^ fn(num);//具体的哈希函数 (acc << 1)异或fn(num)
//fn(num)应该是调用stl自己内部的关于整形的哈希函数
}
);
};
unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);
for (string& str: strs) {
array<int, 26> counts{};
int length = str.length();
for (int i = 0; i < length; ++i) {
counts[str[i] - 'a'] ++;
}
mp[counts].emplace_back(str);
}
vector<vector<string>> ans;
for (auto it = mp.begin(); it != mp.end(); ++it) {
ans.emplace_back(it->second);
}
return ans;
}
};
有点绕
这里的自定义哈希函数写法值得学习。


下面用一个评论区好友的方法
//解法2:利用各字符串中字母出现的频次
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> mp;
vector<vector<string>> res;
for(auto s:strs)
{
string str=string(26,'0');
for(auto c:s) ++str[c-'a'];
mp[str].emplace_back(s);
}
for(unordered_map<string,vector<string>>::iterator it=mp.begin();it!=mp.end();it++)
{
res.emplace_back(it->second);
}
return res;
}
};

2021-10-11
24. 两两交换链表中的节点

解析
解法1:递归

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
//解法1:递归
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head==nullptr|| head->next==nullptr)
{
return head;
}
ListNode *subres;
ListNode *headnext=head->next;
subres=swapPairs(head->next->next);
head->next=subres;
headnext->next=head;
return headnext;
}
};


解法2:迭代


/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
//解法2:迭代
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* prehead = new ListNode(0);
prehead->next=head;
ListNode *temp;
temp=prehead;
while(temp->next!=nullptr&& temp->next->next!=nullptr)
{
ListNode *node1=temp->next;
ListNode *node2=temp->next->next;
temp->next=node2;
node1->next=node2->next;
node2->next=node1;
temp=node1;
}
return prehead->next;
}
};


100. 相同的树


解法1:深度遍历

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
//解法1:深度遍历
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
if(p==nullptr && q==nullptr )
{
return true;
}
else if(p==nullptr || q==nullptr)
{
return false;
}
else if(p->val !=q->val)
{
return false;
}
else
{
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
}
};


解法2:广度遍历

这里对官方的答案做了修改,只用一个队列就可以实现。
//解法2:广度优先
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
queue <TreeNode*> que;
que.push(p);
que.push(q);
while(!que.empty())
{
p=que.front();
que.pop();
q=que.front();
que.pop();
if(p==nullptr && q==nullptr)
{
continue;
}
if((p == nullptr || q == nullptr) || p->val != q->val){
return false;
}
que.push(p->left);
que.push(q->left);
que.push(p->right);
que.push(q->right);
}
return true;
}
};


2021-10-12
70. 爬楼梯

解法1:动态规划



解法2:矩阵快速幂



//解法2:矩阵快速幂
class Solution {
public:
//矩阵用vector表示
//定义矩阵乘法
vector<vector<long long>> multiply(vector<vector<long long>> &a, vector<vector<long long>> &b)
{
vector<vector<long long>> c(2,vector<long long>(2));//初始化
for(int i=0;i<2;i++)
{
for(int j=0;j<2;j++)
{
c[i][j]=a[i][0]*b[0][j]+a[i][1]*b[1][j];
}
}
return c;
}
//定义矩阵的幂次方的方法--二分法求矩阵的幂次方
vector<vector<long long>> matrixPow(vector<vector<long long>> a,int n)
{
vector<vector<long long>> ret = {{1, 0}, {0, 1}};//单位矩阵
while(n>0)//计算a^n
{
if( (n&1)==1 )//就是判断n的二进制表示最后一位是否为1,是的话就是奇数,否则偶数
{
ret=multiply(ret,a);
}
n>>=1;//n除2
a=multiply(a,a);
}
return ret;
}
//
int climbStairs(int n) {
vector<vector<long long>> ret = {{1, 1}, {1, 0}};
vector<vector<long long>> res = matrixPow(ret, n);
return res[0][0];
}
};


解法3:

class Solution {
public:
int climbStairs(int n) {
double sqrt5 = sqrt(5);
double fibn = pow((1 + sqrt5) / 2, n + 1) - pow((1 - sqrt5) / 2, n + 1);
return (int)round(fibn / sqrt5);//round是四舍五入
}
};


2021-10-13
38. 外观数列

解析1
解法1:迭代
//解法1:迭代
class Solution {
public:
string countAndSay(int n) {
if(n == 1)
return "1"; // f(1) = 1
string res = "1"; // f(1) = 1, 作为迭代的初始值放入到结果中
for(int i=0; i<n-1; i++)
{
string currentCombinedStr = "";
char curFirstChar = res[0]; // 存放当前分片的第一个字符
int currentCharCount = 0;
for(char ch : res) // 将当前的字符与当前分片的第一个字符比较
{
if(ch == curFirstChar)
currentCharCount += 1;
else {
// 出现新的字符时,把已处理的连续相同字符的信息插入到结果字符串中
currentCombinedStr.append(to_string(currentCharCount));
currentCombinedStr.push_back(curFirstChar);
//重新分割
curFirstChar = ch;
currentCharCount = 1;
}
}
// 把末尾连续相同字符的信息插入到结果字符串中(对末尾一段字符来说,不会再有新的字符了)
currentCombinedStr.append(to_string(currentCharCount));
currentCombinedStr.push_back(curFirstChar);
res = currentCombinedStr; // 将结果用作下一轮循环的初始值
}
return res;
}
};

时间复杂度和空间复杂度都是n
解法2:递归
解析2
递归应该更好理解
class Solution {
public:
string countAndSay(int n) {
if(n == 1) return "1";
string previous = countAndSay(n-1), result = ""; // 使用递归来一层一层往前推
int count = 1; // count用来计数
for(int i=0;i<previous.length();i++)
{
if(previous[i] == previous[i+1])
{
count ++; // 比如previous是111221时,111部分会让count=3,此时i在第三个1处
}
else
{
result += to_string(count) + previous[i]; // result会从空变成“31”(当i在第三个1处时)
count = 1; // 由于i在第三个1处时,i+1处的值为2,1 != 2,所以count重新变成1
}
}
return result;
}
};
// 测试用例参考:n时是312211,previous是111221

时间复杂度是n^2
空间复杂度是n
2021-10-22
这段时间刷不了几道题了,MD要考教资!
15. 三数之和
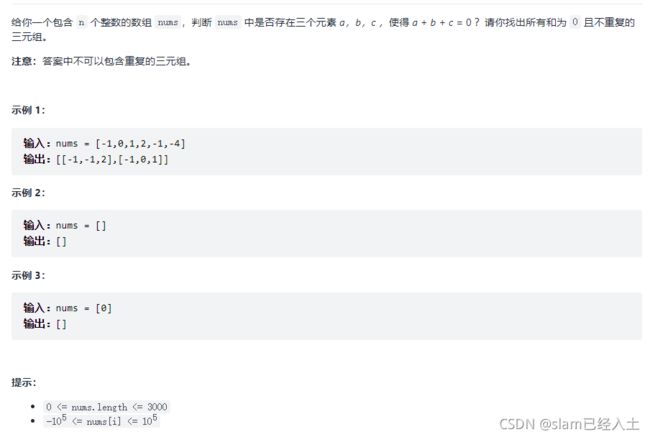
自己的解法:超出时间范围 但自己在IDE里调试了,是可以用的,遇到规模太大的nums就不行了
//自己的解法 超出时间限制???
class Solution {
public:
void DFS(int start,vector<int>& nums,vector<int>& temp,vector<vector<int>>& res)
{
if(temp.size()==3 && accumulate(temp.begin(), temp.end(), 0) ==0 )
{
res.emplace_back(temp);
return ;
}
for(int i=start;i<nums.size() && temp.size()<=3;i++)
{
if(i>start && nums[i]==nums[i-1])
{
continue;
}
temp.push_back(nums[i]);
DFS(i+1,nums,temp,res);
temp.pop_back();
}
}
vector<vector<int>> threeSum(vector<int>& nums) {
//用树的思想 然后回溯 这个题目和前面的组合题类似
vector<vector<int>> res;
vector<int> temp;
sort(nums.begin(),nums.end());//去重的基础
DFS(0,nums,temp,res);
return res;
}
};
运行结果

main函数代码
int main() {
vector<int> nums;
vector<vector<int>> res;
nums={-1,-1,-4,0,1,2,4};
for(auto it =nums.begin();it<nums.end();it++)
{
cout<< *it <<" ";
}
cout<<endl;
Solution3 s3;
res=s3.threeSum(nums);
for(auto it =res.begin();it<res.end();it++)
{
for(auto it1 =it->begin();it1<it->end();it1++)
{
cout<<*it1 <<" ";
}
cout<<endl;
}
cout<<endl;
return 0;
}
官方解法:双指针



//这个和官方代码不一样 这个更清晰 更简单
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums)
{
int size = nums.size();
if (size < 3) return {}; // 特判
vector<vector<int> >res; // 保存结果(所有不重复的三元组)
std::sort(nums.begin(), nums.end());// 排序(默认递增)
for (int i = 0; i < size; i++) // 固定第一个数,转化为求两数之和
{
if (nums[i] > 0) return res; // 第一个数大于 0,后面都是递增正数,不可能相加为零了
// 去重:如果此数已经选取过,跳过
if (i > 0 && nums[i] == nums[i-1]) continue;
// 双指针在nums[i]后面的区间中寻找和为0-nums[i]的另外两个数
int left = i + 1;
int right = size - 1;
while (left < right)
{
if (nums[left] + nums[right] > -nums[i])
right--; // 两数之和太大,右指针左移
else if (nums[left] + nums[right] < -nums[i])
left++; // 两数之和太小,左指针右移
else
{
// 找到一个和为零的三元组,添加到结果中,左右指针内缩,继续寻找
res.push_back(vector<int>{nums[i], nums[left], nums[right]});
left++;
right--;
// 去重:第二个数和第三个数也不重复选取
// 例如:[-4,1,1,1,2,3,3,3], i=0, left=1, right=5
while (left < right && nums[left] == nums[left-1]) left++;
while (left < right && nums[right] == nums[right+1]) right--;
}
}
}
return res;
}
};


2021-11-1
67. 二进制求和


class Solution {
public:
//二进制求和 逢二进一
string addBinary(string a, string b) {
string res;
int nsize=max(a.size(),b.size());
//先反转这两个字符串
reverse(a.begin(),a.end());
reverse(b.begin(),b.end());
int flag=0;//用于表示 进位
for(int i=0;i<nsize;i++)
{
flag+=i <a.size() ?( a[i] == '1' ) :0;
flag+=i <b.size() ?( b[i] == '1' ) :0;
res.push_back( (flag%2) ? '1': '0' );
flag= flag/2;
}
//就是最高位也进位了 所以还要再加一个1
if(flag)
{
res.push_back('1');
}
reverse(res.begin(),res.end());
return res;
}
};



class Solution:
def addBinary(self, a, b) -> str:
x, y = int(a, 2), int(b, 2)
while y:
answer = x ^ y
carry = (x & y) << 1
x, y = answer, carry
return bin(x)[2:]

2021-11-2
90. 子集 II

解法1:递归

//解法1:递归
class Solution {
public:
vector<int> temp;
vector<vector<int>> res;
void dfs(vector<int>& nums, int startIndex)
{
res.push_back(temp);
for(int i=startIndex;i<nums.size();i++)
{
//去重
if(i>startIndex && nums[i-1]==nums[i])
{
continue;
}
temp.push_back(nums[i]);
dfs(nums,i+1);
temp.pop_back();//弹出 保证最大的循环 每次temp初始都是空的
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
//用递归
res.clear();
temp.clear();
sort(nums.begin(), nums.end()); // 去重的前提
dfs(nums, 0);
return res;
}
};


解法2:迭代

//建议自己debug一下 牛的
class Solution {
public:
vector<int> t;
vector<vector<int>> ans;
vector<vector<int>> subsetsWithDup(vector<int> &nums) {
sort(nums.begin(), nums.end());
int n = nums.size();
for (int mask = 0; mask < (1 << n); ++mask) {
t.clear();
bool flag = true;
for (int i = 0; i < n; ++i) {
if (mask & (1 << i)) {
if (i > 0 && (mask >> (i - 1) & 1) == 0 && nums[i] == nums[i - 1]) {
flag = false;
break;
}
t.push_back(nums[i]);
}
}
if (flag) {
ans.push_back(t);
}
}
return ans;
}
};


2020-11-3
66. 加一

class Solution {
public:
vector<int> plusOne(vector<int>& digits) {
int n = digits.size();
for (int i = n - 1; i >= 0; --i) {
if (digits[i] != 9) {
++digits[i];
for (int j = i + 1; j < n; ++j) {
digits[j] = 0;//9后面的为0
}
return digits;
}
}
// digits 中所有的元素均为 9
vector<int> ans(n + 1);
ans[0] = 1;
return ans;
}
};


2021-11-9
41. 缺失的第一个正数

自己的解法:考虑所有情况
效率有点低
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
sort(nums.begin(),nums.end());//排序
//找到第一个大于0的数的位置
int start=-1;
int n_size=nums.size();
for(int i=0;i<n_size;i++ )
{
if(nums[i]>0)
{
start=i;//找到第一个大于0的数的位置
break;
}
}
if(start==-1||nums[start]>=2)//都是负数 或者 第一个大于0的数>=2。说明1没有出现
{
return 1;
}
for(int i=start+1;i<n_size;i++)
{
//去掉两数相等的情况
if(nums[i]==nums[i-1])
{
continue;
}//判断相邻数之间是否间隔为1 如果间隔不为1,说明中间的那个数就是缺少的最小正整数
else if(nums[i]!= (nums[i-1]+1) )
{
return nums[i-1]+1;
}
}
//这种情况就是 123这种情况
return nums[n_size-1]+1;
}
};

解法1:将数组视为哈希表



//解法1:将数组视为哈希表
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n=nums.size();
//把小于等于0的数设置为n+1 就是不用处理它们
for(auto &num:nums)
{
if(num<=0)
{
num=n+1;
}
}
for(int i=0;i<n;i++)
{
int num=abs(nums[i]);//避免已经变为负数的情况
if(num<=n)
{
nums[num-1]=-abs(nums[num-1]);
}
}
for(int i=0;i<n;i++)
{
if(nums[i]>0)
{
return i+1;
}
}
return n+1;
}
};


解法2:置换

这个方法巧妙啊!!
//解法2:置换
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n=nums.size();
//举个例子 3 4 -1 4 9 -5
for(int i=0;i<n;i++)
{
while(nums[i]>0 && nums[i]<=n && nums[nums[i]-1] !=nums[i] )//将值放在对应的位置上,也就是交换
{
swap(nums[i],nums[nums[i]-1]);
}
}
// -1 4 3 4 9 -5
for(int i=0;i<n;i++)
{
if(nums[i]!=i+1)
// 4!=1+1
return i+1;//返回2
}
return n+1;
}
};


69. Sqrt(x)

解法1:袖珍计算器算法

class Solution {
public:
int mySqrt(int x) {
if (x == 0) {
return 0;
}
int ans = exp(0.5 * log(x));
return ((long long)(ans + 1) * (ans + 1) <= x ? ans + 1 : ans);
}
};


解法2:二分查找

class Solution {
public:
int mySqrt(int x) {
int l = 0, r = x, ans = -1;
while (l <= r) {
int mid = l + (r - l) / 2;
if ((long long)mid * mid <= x) {
ans = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
return ans;
}
};


解法3:牛顿迭代




//牛顿迭代
class Solution {
public:
int mySqrt(int x) {
if(x==0)
{
return 0;
}
double c=x,x0=x;
while(1)
{
double xi=0.5*(x0+c/x0);//算出新的xi
if(fabs(xi-x0)<1e-7)
{
break;
}
x0=xi;//更新x0
}
return int(x0);
}
};


剑指offer第二版
2021-11-10
剑指 Offer 03. 数组中重复的数字

class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
//用哈希表
unordered_map<int,bool> hash;
int res;
for(auto num:nums)
{
if(hash[num])
{
res=num;
break;
}
hash[num]=true;
}
return res;
}
};

时间复杂度:是数组的长度N
空间复杂度:N
官方解法:也是用哈希
class Solution {
public int findRepeatNumber(int[] nums) {
Set<Integer> set = new HashSet<Integer>();
int repeat = -1;
for (int num : nums) {
if (!set.add(num)) {
//set还有add接口?并且还会判断是否已经存在这个数 人傻了,这是java代码
repeat = num;
break;
}
}
return repeat;
}
}

剑指 Offer 04. 二维数组中的查找
这个方法太巧妙了!


//用的精选里面的解法,太巧妙了
class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
int i=matrix.size()-1,j=0;
while(i>=0&&j<matrix[0].size())//这里注意一下 要写成matrix[0],这样才是获得列数
{
if(matrix[i][j]>target)
{
i--;
}
else if(matrix[i][j]<target)
{
j++;
}
else
{
return true;
}
}
return false;
}
};
剑指 Offer 07. 重建二叉树


有点难理解
解析
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
unordered_map<int,int> map;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
//前序 根左右
//中序 左根右
//对于一个节点来说,它有它的左子树,它有它的右子树
//左子树下面还会有左子树和右子树
//右子树下面还会有左子树和右子树
//所以需要用到递归
//对于根节点root来说
//它的左子树的前序序列根节点是 root +1 , 其中序左边界范围是根节点root的左边界范围,其中序右边界范围是中序中根节点root位置-1
//它的右子树的前序序列根节点是 根节点root+左子树长度+1, 其中序左边界范围是中序中根节点root位置+1,其中序右边界范围是 根节点root的右边界范围
//至此我们就可以开始写函数了
// 将中序序列用哈希表存储,便于查找根节点
for(int i = 0;i < inorder.size();i++)
map[inorder[i]] = i;
// 传入参数:前序,中序,前序序列根节点,中序序列左边界,中序序列右边界
return build(preorder,inorder,0,0,inorder.size()-1);
}
TreeNode* build(vector<int>& preorder, vector<int>& inorder,int pre_root,int in_left,int in_right)
{
if(in_left > in_right)//超出边界
return NULL;
TreeNode *root=new TreeNode(preorder[pre_root]);
int in_root=map[preorder[pre_root]];//根节点在中序中的位置
// 左子树在前序中的根节点位于:pre_root+1,左子树在中序中的边界:[in_left,in_root-1]
root->left = build(preorder,inorder,pre_root+1,in_left,in_root-1);
// 右子树在前序中的根节点位于:根节点+左子树长度+1 = pre_root+in_root-in_left+1
root->right = build(preorder,inorder,pre_root+ in_root-1-in_left+1+1,in_root+1,in_right);
return root;
}
};

2021-11-12
剑指 Offer 05. 替换空格

自己的解法
//自己的解法
class Solution {
public:
string replaceSpace(string s) {
string res;
int i=0;
for(auto c:s)
{
if(c!=' ')
{
res.append(1,c);
}
else
{
res.append("%20");
}
}
return res;
}
};

时间复杂度为 字符串的大小n
空间复杂度 比字符串的大小n略大,因为每个空格要换成%20.

解法2:原地修改



//原地修改
class Solution {
public:
string replaceSpace(string s) {
//统计s里面空格的个数,用来重新给s赋新的尺寸
int count=0;
int old_len=s.size();
for(auto c:s)
{
if(c==' ')
{
count++;
}
}
s.resize(old_len+2*count);//扩展s
int new_len=s.size();
//从后面遍历
for(int j=new_len-1,i=old_len-1; i<j; i--,j--)
{
if(s[i]!=' ')
{
s[j]=s[i];
}
else
{
s[j-2]='%';
s[j-1]='2';
s[j]='0';
j=j-2;
}
}
return s;
}
};


剑指 Offer 06. 从尾到头打印链表

解法:递归法
//递归法
class Solution {
public:
void OutPutVal_Reverse(ListNode * head, vector<int> &res)
{
if(head==NULL)
{
return ;
}
OutPutVal_Reverse(head->next,res);
res.push_back(head->val);
}
vector<int> reversePrint(ListNode* head) {
//这是个单向链表
//可以用递归
vector<int> res;
OutPutVal_Reverse(head,res);
return res;
}
};


解法:辅助栈法

//辅助栈法
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<int> st;
vector<int> res;
while(head!=NULL)
{
st.push(head->val);
head=head->next;
}
//栈 先入后出
while(!st.empty())
{
res.push_back(st.top());
st.pop();
}
return res;
}
};


剑指 Offer 09. 用两个栈实现队列



class CQueue {
public:
stack<int> A;
stack<int> B;//用于将A倒序排序,从而间接实现CQueue的头部删除的功能
CQueue() {
}
void appendTail(int value) {
A.push(value);
}
int deleteHead() {
//先判读B是不是空
//如果B不是空,就把B pop
if(!B.empty())
{
int t=B.top();
B.pop();
return t;
}
//A为空,说明没有元素
if(A.empty())
{
return -1;
}
//剩下的情况就是A不是空,但是B是空 就把 A倒序给B
while(!A.empty())
{
B.push(A.top());
A.pop();
}
int t=B.top();
B.pop();
return t;
}
};
/**
* Your CQueue object will be instantiated and called as such:
* CQueue* obj = new CQueue();
* obj->appendTail(value);
* int param_2 = obj->deleteHead();
*/


2021-11-15
剑指 Offer 10- I. 斐波那契数列

解法:动态规划
解析


//动态规划
class Solution {
public:
int fib(int n) {
//斐波那契数非常经典
//可以用动态规划
int a=0,b=1;
int sum;
for(int i=0;i<n;i++)
{
sum=(a+b)% 1000000007 ;
a=b;
b=sum;
}
return a;
}
};


解法:矩阵快速幂

class Solution {
public:
const int MOD = 1000000007;
int fib(int n) {
if (n < 2) {
return n;
}
vector<vector<long>> q{{1, 1}, {1, 0}};
vector<vector<long>> res = pow(q, n - 1);
return res[0][0];
}
//二分法求矩阵的幂次方 ---时间复杂度log(n)
vector<vector<long>> pow(vector<vector<long>>& a, int n) {
vector<vector<long>> ret{{1, 0}, {0, 1}};
while (n > 0) {
if (n & 1) {//只有n为奇数才会为真
ret = multiply(ret, a);
}
n >>= 1;
a = multiply(a, a);
}
return ret;
}
//定义矩阵乘法
vector<vector<long>> multiply(vector<vector<long>>& a, vector<vector<long>>& b) {
vector<vector<long>> c{{0, 0}, {0, 0}};
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
c[i][j] = (a[i][0] * b[0][j] + a[i][1] * b[1][j]) % MOD;
}
}
return c;
}
};


2021-11-16
剑指 Offer 10- II. 青蛙跳台阶问题

解法:递归
简单,但是超出时间范围。
class Solution {
public:
int mod=1000000007;
int dfs(int target)
{
if(target<=1)
{
return 1;
}
int l=0,r=0;
if(target-1>=0)
{
l=dfs(target-1);
}
if(target-2>=0)
{
r=dfs(target-2);
}
return (l+r)%mod;
}
int numWays(int n) {
int res=dfs(n);
return res;
}
};
解法:动态规划

class Solution {
public:
int mod=1000000007;
int numWays(int n) {
int a,b,sum;
a=1,b=1;
for(int i=0;i<n;i++)
{
sum=(a+b)%mod;
a=b;
b=sum;
}
return a;
}
};


class Solution {
public:
int mod=1000000007;
int numWays(int n) {
int a,b,sum;
a=1,b=1;
for(int i=2;i<=n;i++)
{
sum=(a+b)%mod;
a=b;
b=sum;
}
if(n==0|n==1)
{
return 1;
}
return sum;
}
};


2021-11-17
剑指 Offer 11. 旋转数组的最小数字

自己的解法:
class Solution {
public:
int minArray(vector<int>& numbers) {
//从开头开始的多少个搬到后面去呢
//是把从最开始到递增的数组给它放在最后面 然后把最小的数拿出
//目的是拿出最小的数
int res;
if(numbers.size()==1)
{
return numbers[0];
}
//有两种情况 一个里面完全就是递增的数组 那就只需要拿第一个元素就行
// 还有一个就是前面递增,中间有一个不是递增
for(int i=1;i<numbers.size();i++)
{
if(numbers[i-1]>numbers[i])
{
res=numbers[i];
break;
}
}
if(numbers[0]<res)
{
res=numbers[0];
}
return res;
}
};

时间复杂度:n,n为数组的长度
空间复杂度:1
解法1:二分

//二分法
class Solution {
public:
int minArray(vector<int> &numbers) {
int size = numbers.size();
if (size == 0) {
return 0;
}
int left = 0;
int right = size - 1;
while (left < right) {
int mid = left + (right - left) / 2;
// int mid = left + ((right - left) >> 1);
if (numbers[mid] > numbers[right]) {
// [3, 4, 5, 1, 2],mid 以及 mid 的左边一定不是最小数字
// 下一轮搜索区间是 [mid + 1, right]
left = mid + 1;
} else if (numbers[mid] == numbers[right]) {
// 只能把 right 排除掉,下一轮搜索区间是 [left, right - 1]
right--;
} else {
// 此时 numbers[mid] < numbers[right]
// mid 的右边一定不是最小数字,mid 有可能是,下一轮搜索区间是 [left, mid]
right = mid;
}
}
return numbers[left];
}
};


解法2:分而治之
也是用的二分 将问题拆解为两部分
比如3 4 5 1 2
拆成3 4, 5 1 2
然后继续从中间拆分
//分而之治
class Solution {
public:
int minArray(vector<int>& numbers,int left,int right)
{
if(left+1>=right)//表示子问题里是由两个数 返回最小的那个
{
return min(numbers[left],numbers[right]);
}
if(numbers[left]<numbers[right])//整个数组是递增的,返回第一个 第一个就是最小的
{
return numbers[left];
}
//下面的就是 3 4 5 1 2这种情况的了
int mid=left+(right-left)/2;
return min(minArray(numbers,left,mid-1), minArray(numbers,mid,right));
}
int minArray(vector<int>& numbers) {
int len=numbers.size();
return minArray(numbers,0,len-1);
}
};

复杂度和二分应该是一样的。
剑指 Offer 12. 矩阵中的路径




#include 

空间复杂度:1