Java 集合【学习笔记】Java 基础
若文章内容或图片失效,请留言反馈。部分素材来自网络,若不小心影响到您的利益,请联系博主删除。
写这篇博客旨在制作笔记,方便个人在线阅览,巩固知识。无他用。
学习视频
- 【黑马程序员 | Java 基础教程 | 零基础快速掌握 Java 集合框架】
- 【黑马程序员 | Java 零基础视频教程 | 上部】
- 【黑马程序员 | Java 零基础视频教程 | 下部】
学习资料: 【黑马程序员】Java 入门到起飞(提取码:9987)
推荐阅读博客:【漫画:什么是红黑树?】
Java 基础(查缺补漏)
- Java 集合【学习笔记】Java 基础:https://blog.csdn.net/yanzhaohanwei/article/details/129458827
- Stream 流 【学习笔记】Java 基础:https://blog.csdn.net/yanzhaohanwei/article/details/129258429
吐槽:基础不牢,地动山摇
1.Java 集合概述
- 集合和数组的优势对比
长度可变
添加数据的时候不需要考虑索引,默认将数据添加到末尾 - 什么是集合
提供一种存储空间可变的存储模型,存储的数据容量可以发生改变。
集合中存储的是元素对象的地址。 - 泛型的使用
泛型在编译的阶段就可以约定操作的数据的类型

- List 系列集合:添加的元素是有序的、可重复的、有索引的
- ArrayList、LinekdList、Vector:有序、可重复、有索引。
- Vector 是线程安全的,是 List 系列集合的一种古老的实现类。
- Set 系列集合:添加的元素是无序的、不重复的、无索引的
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引。
- TreeSet:按照大小默认升序排序、不重复、无索引

2.入门了解
2.1.ArrayList 入门
ArrayList 集合的特点:长度可以变化,只能存储引用数据类型。
下面介绍一下 ArrayList 类的常用方法
2.1.1.构造方法
| 方法名 | 说明 |
|---|---|
public ArrayList() |
创建一个空的集合对象 |
2.1.2 成员方法
| 方法名 | 说明 |
|---|---|
public boolean add(E e) |
将指定的元素追加到此集合的末尾 |
public boolean remove(E e) |
删除指定元素,返回值表示是否删除成功 |
public E remove(int index) |
删除指定索引处的元素,返回被删除的元素 |
public E set(int index, E element) |
修改指定索引处的元素,返回被修改的元素 |
public E get(int index) |
返回指定索引处的元素 |
public int size() |
返回集合中的元素的个数 |
2.1.3.代码测试
诸位可以自行运行一下下方的代码,加深理解
Student.java
public class Student {
String name;
Integer age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
}
ArrayListDemo.java
public class ArrayListDemo {
public static void main(String[] args) {
System.out.println("------------------------------------------------");
// operateIntegerList();
operateStrList();
// createStudentList();
System.out.println("------------------------------------------------");
}
private static void operateIntegerList() {
ArrayList<Integer> arrayInteger = new ArrayList<>();
Collections.addAll(arrayInteger, 1, 2, 3, 4, 5);
for (Integer integer : arrayInteger) {
System.out.print(integer + " ");
}
}
private static void operateStrList() {
// 1.创建一个集合
ArrayList<String> strList = new ArrayList<>();
// 2.添加元素
strList.add("张无忌");
strList.add("张翠山");
strList.add("张三丰");
strList.add("宋远桥");
strList.add("俞莲舟");
System.out.println("最初的集合:" + strList);
// 3.删除元素
boolean result_1 = strList.remove("张翠山");
boolean result_2 = strList.remove("殷素素"); // 删除一个不存在的元素
System.out.println(result_1); // true
System.out.println("元素 [张翠山] 被成功删除");
System.out.println("【boolean remove(element)】删除元素后的集合:" + strList);
System.out.println(result_2); // false
System.out.println("集合中不存在 [殷素素] 元素");
String removeStr = strList.remove(1);
System.out.println("索引 1 处的元素 [" + removeStr + "] 被删除");
System.out.println("【E remove(int index)】删除元素后的集合:" + strList);
// 4.修改元素
System.out.println("修改 索引 1 处的元素:[" + strList.get(1) + "]");
strList.set(1, "宋远桥_Plus");
System.out.println("【E set(int index, E element)】修改后的集合:" + strList);
// 5.查询元素
String searchStr = strList.get(0);
System.out.println("【E get(int index)】查询集合中索引 0 处的元素:[" + searchStr + "]");
// 6.遍历
System.out.println("-------【遍历集合】-------");
System.out.print("[");
for (int i = 0; i < strList.size(); i++) {
if (i == strList.size() - 1) {
System.out.print(strList.get(i));
} else {
String str = strList.get(i);
System.out.print(str + " ");
}
}
System.out.println("]" + "\n" + "------------------------");
}
private static void createStudentList() {
List<Student> students = new ArrayList<>();
Student s1 = new Student("吉良吉影", 33);
Student s2 = new Student("东方仗助", 16);
Student s3 = new Student("广濑康一", 15);
Student s4 = new Student("虹村亿泰", 17);
Collections.addAll(students, s1, s2, s3, s4);
System.out.println("---------------------------------------");
for (int i = 0; i < students.size(); i++) {
System.out.println("[" + students.get(i).getName() + ":" + students.get(i).getAge() + "]");
}
System.out.println("---------------------------------------");
for (Student student : students) {
System.out.println(student);
}
System.out.println("---------------------------------------");
}
}
2.2.工具类 Arrays
2.2.1.成员方法
| 方法名 | 说明 |
|---|---|
public static String toString(数组) |
把数组拼接成一个字符串 |
public static int binarySearch(数组, 查找的元素) |
使用二分查找法查找元素 |
public static int[] copyOf(原数组, 新数组的长度) |
拷贝数组 |
public static boolean[] copyOfRange(原数组, 起始索引, 结束索引) |
拷贝数组(指定范围:包头不包尾) |
public static void fill(数组, 元素) |
用输入的元素覆盖填充数组中的所有数据 |
public static void sort(数组) |
按照默认方式进行数组排序(升序排序) |
public static void sort(数组, 排序规则) |
按照指定的规则进行数组排序 |
2.2.2.sort() 方法详解
这里详细介绍一下 public static void sort(数组, 排序规则) 方法。
java/util/Arrays.java
public static <T> void sort(T[] a, Comparator<? super T> c)
底层原理:该方法是利用 插入排序 + 二分查找 的方式来进行排序操作的。
- 开始时,默认把 0 索引处的数据当做是有序的序列,默认把 1 索引处的数据和其他之后的数据当做无序的序列
- 遍历无序的序列得到里面的每一个元素,假设当前遍历得到的元素是 A 元素
- 把 A 往有序序列中进行插入,在插入的时候,是利用二分查找来确定 A 元素的插入点
- 拿着 A 元素,和插入点的元素进行比较,比较的规则就是 compare() 方法中的方法体
- 如果方法的返回值是负数,拿着 A 继续和前面的数据进行比较
- 如果方法的返回值是正数和 0,拿着 A 继续和后面的数据进行比较
- 直到可以确定 A 的最终位置,才可以停止这一轮的比较
这里我们说的再形象一点
java/util/Comparator.java
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
}
- o1:表示该元素在无序序列中;o2:表示该元素在有序序列中
- 该方法的返回值是负数时,元素会继续向前排序;该方法返回值是正数时,元素会继续向后排序。
- 该方法的返回值是 0 时,元素会向后进一次(一次就行,毕竟两元素都相等了)
显然,这是很典型的插入排序的算法。
2.2.3.sort() 方法代码测试
诸位可以自行测试一下下方代码,帮助自己理解
public class ArraysDemo {
public static void main(String[] args) {
System.out.println("-------------------------------------------------");
Integer[] data_5 = {2, 1, 9, 3, 5, 4, 8, 6, 7};
System.out.println("排序前的数组 data_5:" + Arrays.toString(data_5));
System.out.println("-------------------------------------------------");
Arrays.sort(data_5, new Comparator<Integer>() {
@Override
public int compare(Integer t1, Integer t2) {
System.out.print("[t1:" + t1 + "] ");
System.out.print("[t2:" + t2 + "]\n");
// return t1 - t2; // 升序排序
return t2 - t1; // 降序排序
}
});
System.out.println("-------------------------------------------------");
System.out.println("排序后的数组 data_5:" + Arrays.toString(data_5));
System.out.println("-------------------------------------------------");
}
}
3.Collection
3.1.Collection 概述和使用
3.1.1.Collection 集合概述
Collection 集合概述
- 是单列集合的顶层接口,它表示一组对象,这些对象也称为 Collection 的元素
- JDK 不提供此接口的任何直接实现。它提供更具体的子接口(如 Set 和 List)实现
创建 Collection 集合的对象
- 多态的方式
- 具体的实现类 ArrayList
3.1.2.Collection 集合的常用方法
| 方法名 | 说明 |
|---|---|
public boolean add(E e) |
添加元素(Set 集合中不会添加重复的元素) |
public boolean remove(Object o) |
从集合中移除指定的元素 |
public boolean removeIf(Object o) |
根据条件进行移除 |
public void clear() |
清空集合中的元素 |
public boolean contains(Object o) |
判断集合中是否存在指定的元素 |
public boolean isEmpty() |
判断集合是否为空 |
ipublic nt size() |
集合的长度,也就是集合中元素的个数 |
public Object[] toArray() |
把集合中的元素存储到对象数组中 |
- 注意事项
boolean remove(Object o):从集合中移除指定的元素- 因为 Collection 集合里定义的是共性的方法,故此时不可以通过索引来进行删除,只能通过元素的对象进行删除。
- 该方法有的返回值类型是布尔类型。删除成功,返回 true;删除失败,返回 false。
- 如果要删除的元素不存在,则算删除失败,返回 false。
boolean contains(Object o):判断集合中是否包含该元素- 该方法的底层是依赖 equals() 方法进行判断是否存在的。
- 若集合中存储的是自定义对象,也想通过 contains() 方法来判断集合中是否包含该元素,那么在 JavaBean 中,必须要重写 equal() 方法。否则使用的就是 Object 类中的 equals() 方法,其依赖地址值判断。
3.1.3.代码测试
诸位可自行运行一下下方代码,加深理解。
Student.java
public class Student {
String name;
Integer age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student_2 student_2 = (Student_2) o;
return age == student_2.age && Objects.equals(name, student_2.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
CollectionDemo_1.java
public class CollectionDemo_1 {
public static void main(String[] args) {
testArrayList_1();
// testHashSet();
// testArrayList_2();
}
private static void testArrayList_1() {
Collection<String> collection = new ArrayList<>();
collection.add("张三");
collection.add("李四");
collection.add("王五");
collection.add("赵六");
System.out.println("集合:" + collection);
// collection.clear(); // 清空
boolean element1 = collection.remove("张三");
System.out.println("删除存在的元素的返回值:" + element1); // true
boolean element2 = collection.remove("朱元璋");
System.out.println("删除不存在的元素的返回值:" + element2); // false
System.out.println("被删除元素后的集合:" + collection);
System.out.println("判断元素是否包含 [李四]:" + collection.contains("李四"));
System.out.println("判断元素是否包含 [李三四]:" + collection.contains("李三四"));
boolean isEmpty = collection.isEmpty();
System.out.println("集合是否为空:" + isEmpty);
System.out.println("集合的长度是:" + collection.size());
}
private static void testArrayList_2() {
Collection<Student> collection = new ArrayList<>();
Collections.addAll(collection, new Student("LiSiSi", 23), new Student("LiSi", 24), new Student("WangWu", 25));
System.out.println(collection);
boolean result = collection.contains(new Student("LiSi", 24));
System.out.println("集合中是否包含 LiSi 元素:" + result);
}
private static void testHashSet() {
Collection<String> collection = new HashSet<>();
collection.add("张三");
collection.add("李四");
collection.add("王五");
collection.add("赵六");
collection.add("田七");
System.out.println(collection);
collection.add("张三"); // 不会添加重复的元素
System.out.println(collection);
}
}
3.2.迭代器
3.2.1.基本介绍
迭代器介绍
- 迭代器是集合的专用遍历方式,迭代器在 JAVA 中的类是
java/util/Iterator.java Iterator:返回此集合中元素的迭代器,默认指向当前集合的 0 索引(通过集合对象的 iterator() 方法得到)iterator() Iterator<String> iterator = list.iterator();
Iterator 中的常用方法
boolean hasNext():判断当前位置是否有元素可以被取出,有元素则返回 true,无元素则返回 falseE next():获取当前位置的元素,并将迭代器对象移向下一个索引位置boolean flag = iterator.hasNext(); String nextString = iterator.next();
Collection 集合的遍历
List<String> list = new ArrayList<>();
Collections.addAll(list, "刘备", "曹操", "孙权");
Iterator<String> it = list.iterator(); // 创建指针
// 利用循环去不断地获取集合中的每一个元素
while (it.hasNext()) { // 判断是否有元素
String str = it.next(); // 获取当前元素,并移动指针
System.out.print(str + " ");
}
- 注意事项
- 在遍历完集合后,仍然强行向下移动获取指针的话,会报错:
java.util.NoSuchElementException。 - 迭代器遍历完毕后,指针不会复位。要想重新使用迭代器遍历的话,只得重新创建另一个迭代器对象。
- 迭代器遍历的时候,不能用集合中的方法来对元素进行增加或删除操作,要有迭代器中提供的 remove() 方法。
- 在遍历完集合后,仍然强行向下移动获取指针的话,会报错:
3.2.2.代码测试
诸位可自行运行下方代码块中的代码,以加深理解。
public class CollectionDemo_2 {
public static void main(String[] args) {
List<String> collection = new ArrayList<>();
Collections.addAll(collection, "刘备", "曹操", "孙权", "司马懿", "刘裕");
// test_1(collection);
// test_2(collection);
test_3(collection);
}
private static void test_1(List<String> collection) {
Iterator<String> it = collection.iterator();
while (it.hasNext()) {
String str = it.next();
System.out.println(str);
}
// 上面的循环结束后,迭代器的指针已经指向了最后方没有元素的位置了。
try {
it.next(); // NoSuchElementException
} catch (NoSuchElementException e) {
e.printStackTrace();
}
System.out.println("---------------------------------");
// 迭代器遍历完毕后,指针不会复位
System.out.println(it.hasNext()); // false
System.out.println("---------------------------------");
// 若是想再对集合进行一次遍历操作,只能是再次获取一个新的迭代器对象
Iterator<String> it2 = collection.iterator();
while (it2.hasNext()) {
System.out.println(it2.next());
}
}
private static void test_2(List<String> collection) {
Iterator<String> iterator = collection.iterator();
try {
while (iterator.hasNext()) {
// 下面移动了两次指针,直接超过了集合的最大长度。
// 故在遍历完集中中的所有元素之后,最终报错:NoSuchElementException
String str = iterator.next();
System.out.println(str);
System.out.println(iterator.next());
System.out.println(iterator.next());
}
} catch (NoSuchElementException e) {
e.printStackTrace();
}
}
private static void test_3(List<String> collection) {
System.out.println(collection);
Iterator<String> it = collection.iterator();
while (it.hasNext()) {
String str = it.next();
if ("司马懿".equals(str)) collection.remove("司马懿"); // JAVA11 版本中,该方法未报错,且删除成功了
if ("刘裕".equals(str)) collection.add("萧道成"); // 添加失败
}
System.out.println(collection); // 并没有出现添加的元素
collection.add("萧衍");
System.out.println(collection);
}
}
3.2.3.小结
- 迭代器在遍历集合的时候是不依赖索引的。
- 迭代器需要掌握三个方法
Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { String str = iterator.next(); System.out.println(str); } - 迭代器的四个细节
- 如果当前位置没有元素了,还要继续强行获取,会报
NoSucheElementException错误 - 迭代器遍历完毕后,指针是不会复位的
- 循环中只能使用一次 next() 方法
- 迭代器遍历的时候,不可以用集合的方法进行增加或者删除。
- 如果当前位置没有元素了,还要继续强行获取,会报
3.3.增强 for 循环
基本介绍
- 它是 JDK 5 之后出现的,其内部原理就是一个 Iterator 迭代器
- 实现了 Iterable 接口的类才可以使用迭代器和增强 for
- 所有的单列集合和数组都可以用增强 for 来进行遍历(Map 这种双列集合不可以用它)
格式
for(集合/数组中元素的数据类型 变量名 : 集合/数组名) {
// 已经将当前遍历到的元素封装到变量中了,直接使用变量即可
}
- 注意事项:
- 在增强 for 中修改变量,并不会改变集合中原本的数据。
- 比如例子中的
for (String s : list)中的 s,它其实就是记录每一次循环遍历到的元素数据的第三方变量。
具体案例
List<String> list = new ArrayList<>();
Collections.addAll(list, "刘备", "曹操", "孙权", "司马懿", "刘裕");
// 在增强 for 中修改变量,并不会改变集合中原本的数据
// 下方的 s 只不过是一个记录数据的第三方变量名罢了
for (String s : list) {
s = "陈霸先";
System.out.print(s + " ");
}
System.out.println("\n" + list);
控制台输出信息
陈霸先 陈霸先 陈霸先 陈霸先 陈霸先
[刘备, 曹操, 孙权, 司马懿, 刘裕]
3.4.forEach
得益于 JDK 8 开始提供的新技术(Lambda 表达式),我们可以使用到一种更简单、更直接的遍历集合的方式。
| 方法名称 | 说明 |
|---|---|
default void forEach(Consumer action) |
可以结合 Lambda 遍历 |
java/lang/Iterable.java
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
其实 forEach() 方法的底层就是一个循环遍历,依次得到集合中的每一个元素,并且把每一个元素传递给 accept() 方法。accpet() 方法的形式参数,其依次代表着集合中的每一个元素。
具体案例
List<String> list = new ArrayList<>();
Collections.addAll(list, "刘备", "曹操", "孙权", "司马懿", "刘裕");
- 匿名内部类的方式
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.print(s + " ");
}
});
- Lambda 表达式的方式
list.forEach((s) -> System.out.print(s + " "));
- 方法引用的方式
list.forEach(System.out::print);
3.5.小结
- Collection 是单列集合的顶层接口,它的所有方法被 Set 和 List 系列集合共享
- Collection 中常见的成员方法
- add()、clear()、remove()、contains()、isEmpty()、size()
- 三种通用的遍历方式
- 迭代器:在遍历的过程中需要删除元素,建议使用迭代器中提供的 remove() 方法
- 如果只是想遍历单列集合的话,可以使用增强 for、Lambda 表达式
4.List 集合
4.1.List 集合的概述和特点
List 集合的概述
- 有序集合,这里的有序指的是存取顺序
- 用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
- 与 Set 集合不同,List 集合通常允许重复的元素
集合的特点:存取有序、集合中的元素可以重复、有索引
4.2.List 集合的特有方法
4.2.1.方法介绍
- Collection 中的成员方法 List 都继承了。
- List 集合中的元素是有索引的,故其多了很多在索引上操作的方法。
| 方法名 | 描述 |
|---|---|
void add(int index, E element) |
在此集合中的指定位置插入指定的元素 |
E remove(int index) |
删除指定索引处的元素,返回被删除的元素 |
E set(int index, E element) |
修改指定索引处的元素,返回被修改的元素 |
E get(int index) |
返回指定索引处的元素 |
注意事项
void add(int index, E element):在此集合中的指定位置插入指定的元素,该索引上的旧元素和其后的元素会依次向后移动E remove(int index)- 在调用该方法的时,若方法出现了重载现象,会优先调用实参和形参类型一致的方法
- remove() 方法是不会自动装箱的
4.2.2.示例代码
示例代码-1
List<String> list = new ArrayList<>();
Collections.addAll(list, "李世民", "侯君集", "尉迟恭", "李靖", "秦琼");
list.add("徐世绩");
// 在指定位置出插入元素,原先索引上的元素会依次向后移动
list.add(1, "程知节");
System.out.println(list); // [李世民, 程知节, 侯君集, 尉迟恭, 李靖, 秦琼, 徐世绩]
// 删除指定索引处的元素,并返回被删除的元素
System.out.println(list.remove(3)); // 尉迟恭
System.out.println(list); // [李世民, 程知节, 侯君集, 李靖, 秦琼, 徐世绩]
示例代码-2
public class ListDemo_2 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5);
System.out.println("初始元素:" + list);
// testRemove(list);
Integer set = list.set(0, 111);
System.out.println("被修改元素的原值:" + set);
System.out.println(list);
System.out.println("集合中索引 2 处的值是:" + list.get(2));
}
private static void testRemove(List<Integer> list) {
// 2 和 2 同为 int 类型,故此处使用的是索引
System.out.println(list.remove(2)); // 返回 3
System.out.println(list); // [1, 2, 4, 5]
Integer i = Integer.valueOf(1); // 手动装箱
// 此处的 i 和集合中的元素都是 Integer 类型,故使用的是集合中的元素的数据
boolean isRemoved = list.remove(i);
System.out.println(isRemoved); // true
System.out.println(list); // [2, 4, 5]
}
}
4.3.List 中的五种遍历方式
创建集合
List<String> list = new ArrayList<>();
Collections.addAll(list, "李世民", "侯君集", "尉迟恭", "李靖", "秦琼", "程知节", "徐世绩");
- 迭代器遍历
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
- 增强 for 遍历
for (String s : list) {
System.out.println(s);
}
- forEach 遍历
// 匿名内部类
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.print(s + " ");
}
});
System.out.println();
// Lambda 表达式
list.forEach((s) -> System.out.print(s + " "));
- 普通 for 遍历
for (int i = 0; i < list.size(); i++) {
if (i == list.size() - 1) System.out.print(list.get(i));
else System.out.print(list.get(i) + " ");
}
- 列表迭代器遍历
ListIterator<String> listIT = list.listIterator();
while (listIT.hasNext()) {
String s = listIT.next();
if ("侯君集".equals(s)) {
listIT.add("李承乾");
}
}
System.out.println(list); // [李世民, 侯君集, 李承乾, 尉迟恭, 李靖, 秦琼, 程知节, 徐世绩]
五种遍历方式对比
- 迭代器遍历:在遍历的过程中需要删除元素,可以使用迭代器。
- 列表迭代器遍历:在遍历的过程中需要添加元素,可以使用列表迭代器。
- 增强 for 遍历、forEach 遍历:只想遍历集合的话,可以直接使用增强 for 或 forEach 遍历。
- 普通 for 遍历:如果遍历集合的时候想操作索引,可以使用普通 for 遍历。
4.4.ArrayList 集合底层原理
关于 ArrayList 的相关方法在之前的 【ArrayList 入门】一节中已经讲过了,这里不再赘述。
ArrayList 集合底层原理
- 利用空参创建的集合,在底层创建一个默认长度是 0 的数组
- 添加第一个元素的时候,底层会创建一个新的长度为 10 的数组
- 数组存满的时候,会扩容 1.5 倍
- 如果一次添加了多个元素,且数组扩容了 1.5 倍 还放不下的话,则新创建数组的长度以实际为准
ArrayList 集合部分源码
java/util/ArrayList.java
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private int size;
- 利用空参创建的集合,在底层创建一个默认长度是 0 的数组
public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }
- 指定数组长度创建集合
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
- 使用 add() 方法第一次给集合添加数据

- 使用 add() 方法第十一次给集合添加数据

4.5.LinkedList 集合
4.5.1.LinkedList 的特有方法
- LinkdedList 的底层的数据结构是双链表,查询慢,头尾插入删除性能高。
LinkdedList 中间插入的性能其实是很低的,因为需要不断调用 next 来找到下一个中间的定位地址

- LinkdedList 本身提供了很多直接操作首尾元素的特有 API。
| 方法名 | 说明 |
|---|---|
public void addFirst(E e) |
在该列表开头插入指定的元素 |
public void addLast(E e) |
将指定的元素追加到此列表的末尾 |
public E getFirst() |
返回此列表中的第一个元素 |
public E getLast() |
返回此列表中的最后一个元素 |
public E removeFirst() |
从此列表中删除并返回第一个元素 |
public E removeLast() |
从此列表中删除并返回最后一个元素 |
4.5.2.示例代码
示例代码
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
Collections.addAll(list, "长孙无忌", "褚遂良", "魏征", "房玄龄", "杜如晦", "封德彝");
System.out.println("list:" + list);
method1(list); // addFirst()
method2(list); // addLast()
method3(list); // getLast()、getFirst()
method4(list); // removeFirst() + removeLast()
}
private static void method4(LinkedList<String> list) {
String first = list.removeFirst();
System.out.println("removeFirst():" + first);
String last = list.removeLast();
System.out.println("removeLast():" + last);
System.out.println("list:" + list);
}
private static void method3(LinkedList<String> list) {
String first = list.getFirst();
String last = list.getLast();
System.out.println("list.getFirst():" + first);
System.out.println("list.getLast():" + last);
}
private static void method2(LinkedList<String> list) {
list.addLast("马周");
System.out.println("list.addLast(\"马周\"):" + list);
}
private static void method1(LinkedList<String> list) {
list.addFirst("萧瑀");
System.out.println("list.addFirst(\"萧瑀\"):" + list);
}
}
控制台输出信息
list:[长孙无忌, 褚遂良, 魏征, 房玄龄, 杜如晦, 封德彝]
list.addFirst("萧瑀"):[萧瑀, 长孙无忌, 褚遂良, 魏征, 房玄龄, 杜如晦, 封德彝]
list.addLast("马周"):[萧瑀, 长孙无忌, 褚遂良, 魏征, 房玄龄, 杜如晦, 封德彝, 马周]
list.getFirst():萧瑀
list.getLast():马周
removeFirst():萧瑀
removeLast():马周
list:[长孙无忌, 褚遂良, 魏征, 房玄龄, 杜如晦, 封德彝]
4.5.3.LinkedList 集合的底层原理
java/util/LinkedList.java
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() { }
... ...
// 这个是 LinkedList 类里的一个比较核心的内部类
private static class Node<E> {
E item; // 存储元素
Node<E> next; // 后继节点
Node<E> prev; // 前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
... ...
}
- 使用 add() 方法给集合添加数据
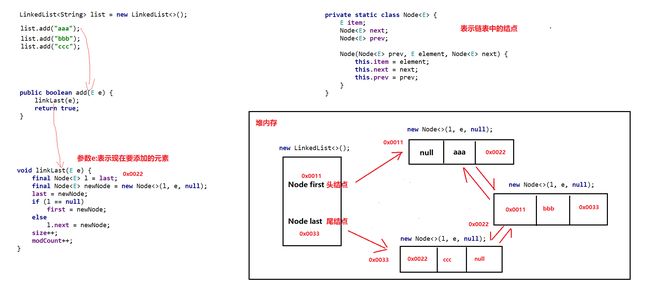
4.6.Iterator 底层原理
java/util/Iterator.java
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
可见迭代器是一个接口,具体的代码实现是在集合里的。
java/util/ArrayList.java

private class Itr implements Iterator<E> {
... ...
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException(); // 抛出并发异常
}
... ...
}
- fail-fast 一旦发现遍历的同时,其它人来修改,会马上抛出异常。
- ArrayList 是 fail-fast 的典型代表,遍历的同时不能修改,会立刻抛出异常。
- fail-safe 发现遍历的同时,其它人来修改,应当能有应对策略。例如牺牲一致性来让整个遍历运行完成。
- CopyOnWriteArrayList 是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离。
5.树(数据结构)
5.1.树的基本概念
树的相关概念
- 节点:在树结构中,每一个元素称之为节点
- 度:每一个节点的子节点数量称之为度

树的子节点的内部结构

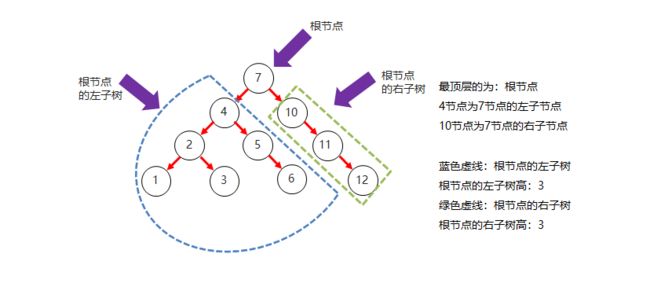
5.2.二叉树
二叉树的特点:在二叉树中,任意一个节点的度要小于等于 2
二叉树的结构图
5.3.二叉查找树
二叉查找树,又称二叉排序树或二叉搜索树

二叉查找树的特点:
- 每一个节点上最多有有两个子节点
- 左子树上所有节点的值都小于根节点的值
- 右子树上所有节点的值都大于根节点的值
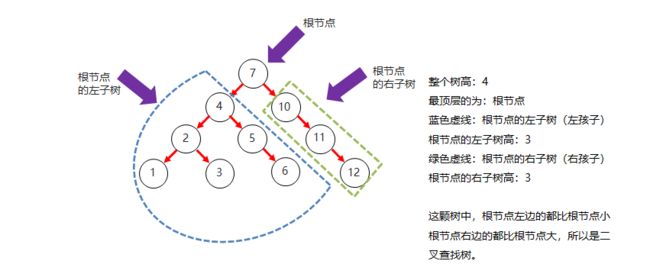
二叉查找树添加节点的规则:小的存左边,大的存右边,一样的不存。
二叉树的遍历方式:
- 深度优先遍历
- 前序遍历:当前节点,左子节点,右子节点
- 中序遍历:左子节点,当前节点,右子节点
- 后序遍历:左子节点,右子节点,当前节点
- 广度优先遍历
- 层序遍历:一层层的去遍历
5.4.平衡二叉树
5.4.1.平衡二叉树的基本概念
- 在满足查找二叉树的大小规则下,让树尽可能矮小,以此提高查数据的性能。
- 任意节点的左右两个子树的高度差不超过 1,任意节点的左右两个子树都是一颗平衡二叉树。
5.4.2.平衡二叉树的旋转机制
相关视频:【Java 基础 | 集合 | 数据结构 | 平衡二叉树旋转机制】
下面写的有点简略,如果看不懂的话,可以看看上面推荐的这个视频。
平衡二叉树旋转
- 旋转触发时机:当添加一个节点之后,该树不再是一颗平衡二叉树
- 左旋
- 将根节点的右侧往左拉,原先的右子节点变成新的父节点,并把多余的左子节点出让,给已经降级的根节点当右子节点
- 右旋
- 将根节点的左侧往右拉,左子节点变成了新的父节点吗,并把多余的右子节点出让,给已经降级根节点当左子节点
- 左旋

- 右旋

5.4.3.平衡二叉树旋转的四种情况
- 左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡
- 如何旋转?直接对整体进行右旋即可
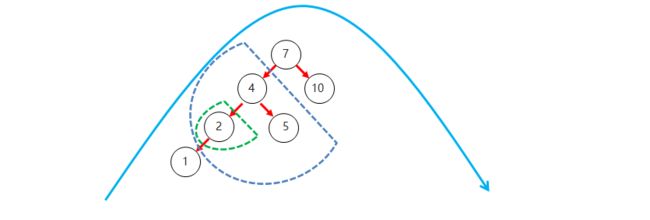
- 左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡
- 如何旋转?先在左子树对应的节点位置进行左旋,再对整体进行右旋

- 右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡
- 如何旋转?直接对整体进行左旋即可

- 右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡
- 如何旋转?先在右子树对应的节点位置进行右旋,在对整体进行左旋

5.5.红黑树
推荐阅读博客:《漫画:什么是红黑树?》
相关视频:【Java 基础 | 集合 | 数据结构 | 红黑树、红黑规则、添加节点处理方案】
红黑树添加节点后如何保持红黑规则这块儿是难点,这里建议看看上面推荐的视频,讲的蛮好的(通俗易懂)。
5.5.1.红黑树的基本概念
平衡二叉树
- 特点
- 高度平衡
- 当左右子树的高度超过 1 的时候,其需要通过旋转来保持平衡。
- 弊端:平衡二叉树查找效率虽高,但是其在添加节点的过程中,旋转次数实在是太多了,这样会造成时间的浪费。
红黑树的基本概念
- 红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构
- 1972 年出现的时候,其被称为 “平衡二叉B树”。1978年其名被修改为 “红黑树”。
- 每一个节点可以是红的,也可以是黑的
- 红黑树不是高度平衡的,它的平衡是通过 “特有的红黑规则” 进行实现的
- 红黑树的节点相较于二叉树的节点,多了一个记录颜色的指针。

5.5.2.红黑树的红黑规则
红黑树的红黑规则
- 每一个节点或是红色的,或者是黑色的
- 根节点必须是黑色
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为 Nil,这些 Nil 视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点

5.2.3.红黑树添加节点的规则
- 红黑树添加节点的默认颜色:添加节点时,默认节点的颜色是红色的(效率高)。

- 红黑树添加节点后如何保持红黑规则(难点)

- 注意事项:虽然不能出现两个红色节点相连的情况,但是可以出现两个黑色节点相连的情况。
6.Set 集合

6.1.Set 集合的概述和使用
6.1.1.Set 集合概述和特点
- 无序:存储元素的顺序是不一致的
- 不重复:不可以存储重复元素
- 无索引:没有带索引的方法,不能使用普通 for 循环遍历,也不能太过索引来获取元素
6.1.2.Set 集合的实现类
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引。
- TreeSet:按照大小默认升序排序、不重复、无索引
Set 接口中的方法上基本与 Collection 的 API 一致
6.1.3.Set 集合的三种遍历方式
// Set 集合的三种遍历方式,诸位可以自行运行一下下方的代码
public class SetDemo_1 {
public static void main(String[] args) {
Set<String> hashSet = new HashSet<>();
Collections.addAll(hashSet, "兆敏", "海兰察", "阿桂");
System.out.println(hashSet);
// ergodic_iterator(hashSet);
// ergodic_forPlus(hashSet);
ergodic_forEach(hashSet);
}
private static void ergodic_forEach(Set<String> hashSet) {
hashSet.forEach(s -> System.out.print(s + " "));
}
private static void ergodic_forPlus(Set<String> hashSet) {
for (String string : hashSet) {
System.out.print(string + " ");
}
}
private static void ergodic_iterator(Set<String> hashSet) {
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.print(s + " ");
}
}
}
6.2.HashSet
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
HashSet 集合的底层采用哈希表来存储数据
哈希表的组成
- JDK 8 之前:数组 + 链表
- JDK 8 开始:数组 + 链表 + 红黑树
6.2.1.哈希值【重点】
哈希值简介
- 是 JDK 根据对象的地址或者字符串或者数字算出来的 int 类型的数值
如何获取哈希值
- 所有对象都可以调用 Object 类中的方法
public int hashCode()(返回对象的哈希码值),默认使用地址值进行计算
对象哈希值的特点
- 同一个对象多次调用 hashCode() 方法返回的哈希值是相同的。
- 默认情况下,不同对象的哈希值是不同的。
- 而如果重写了 hashCode() 方法的话,就可以实现不同对象的哈希值相同的情况。
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也是有可能是一样的。
System.out.println(s1.hashCode()); // 24022543 System.out.println(s2.hashCode()); // 24022543
既然两个对象有相同的哈希值时,属性值也不一定相同,那我们如何准确的比较对象的属性值呢?
此时就需要重写 equals() 方法了,目的是比较对象内部的属性值。
参考书籍:《Head First Java》
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
6.2.2.哈希表的结构【重点】
哈希表的组成
- JDK 8 之前:数组 + 链表
- JDK 8 开始:数组 + 链表 + 红黑树
- 创建一个默认长度为 16,默认加载因子是 0.75 的数组,数组名是 table
HashSet<String> table = new HashSet<>(); - 根据元素的哈希值跟数组的长度计算出应存入的位置
int index = (数组长度 - 1) & 哈希值; - 判断当前位置是否为 null
- 如果是 null 就会直接存入数组
- 如果不是 null,就表示该位置有元素,调用 equals() 方法比较属性值
- 属性值一样,则不存入数组中
- 属性值不一样,则存入数组,形成链表
- JDK 8 以前:新元素存入数组,老元素挂在新元素下面(头插法)
存在并发扩容出现死链的问题 - JDK 8 以后:新元素直接挂在老元素下面(尾插法)
- JDK 8 以前:新元素存入数组,老元素挂在新元素下面(头插法)
JDK 8 之前:数组 + 链表

JDK 8 以后
- 节点个数少于等于 8 个:数组 + 链表
- 节点个数多于 8 个:数组 + 红黑树
- 注意:当链表长度超过 树化阈值 8 时,会先尝试扩容来减少链表长度,如果 数组容量 >= 64,才会进行 树化

注意事项(总结)
- 在 JDK 8 的哈希表中,当链表的长度超过 8 的时候,且数组长度大于大于 64 时,其才会自动转换为红黑树
- 如果集合中存储的是自定义对象,则必须要重写 hashCode() 方法和 equals() 方法
哈希表需要通过哈希值来找到数组的元素位置,而我们想要比较的是对象的属性值,故只能重写上面两个方法
对象先调用 hashCode() 方法来进行比较,hashCode 相同,再调用 equals() 方法比较
6.2.3.图解流程
两张图总结上面的描述
- JAVA 8 中的哈希表

- JAVA 8 中的哈希流程图

6.2.4.关于 HashSet 的三个问题
问题 1:HashSet 为什么是无序的?
在 Java 中的哈希表里,是通过 (数组长度 - 1) & 哈希值 计算出元素应存入的数组位置的,之后再插入该位置的链表/红黑树里。
HashSet 在遍历查找元素的过程中,其是按照数组的顺序一个个遍历的,我们并不能保证我们查找到的数组位置上的链表(或红黑树)上的目标值的位置与存入集合的顺序是一致的。例如我们要找的目标值在数组的第一个位置的链表头(这里就默认头结点有数据的吧),但这里我们并不能保证它就是第一个放入集合的元素。
问题 2:HashSet 为什么没有索引?
其底部是数组 + 链表(或数组 + 链表 +红黑树 )组成的,并不好规定相应的索引规则。
说的通俗一点,数组底下还挂着链表呢,给链表的索引统一为同一数字?
此外还有扩容的情况,哈希值的重新计算等问题 … … 是不好制定一套相应的索引规则的。
问题 3:HashSet 是利用什么机制保证数据去重的?
利用 hashCode() 方法得到哈希值,通过哈希值确定元素在的数组中的位置,之后再调用 equals() 方法比较对象属性的值是否相同。
强调:如果 HashSet 中存储的是自定义对象,那么一定要在自定义对象中重写 hashCode() 方法和 equals() 方法。
6.2.5.练习案例
- 需求:创建一个存储学生对象的集合,存储多个学生对象。
- 要求:学生对象的成员变量值相同时,我们就认为是同一个对象。
Student.java
public class Student {
private String name;
private int age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
HashSetDemo.java
public class HashSetDemo {
public static void main(String[] args) {
Student s1 = new Student("徐阶", 80);
Student s2 = new Student("高拱", 70);
Student s3 = new Student("张居正", 50);
Student s4 = new Student("张居正", 50);
HashSet<Student> hashSet = new HashSet<>();
hashSet.add(s1);
hashSet.add(s2);
hashSet.add(s3);
hashSet.add(s4);
System.out.println(hashSet);
// 打印结果:[Student{name='张居正', age=50}, Student{name='徐阶', age=80}, Student{name='高拱', age=70}]
}
}
6.3.LinkedHahSet
LinkedHahSet 继承了 HashSet
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable
- 有序、不重复、无索引。
- 这里的有序指的是保证存储和取出的元素的顺序一致
- 原理:底层数据结构依然是哈希表,但是每个元素又额外多了一个双链表的机制记录存储的顺序
6.4.TreeSet
TreeSet 是一个基于 TreeMap 的 NavigableSet 实现
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable
6.4.1.TreeSet 的基本介绍
TreeSet 的特点
- 按照大小默认升序排序、不重复、无索引
- 可排序:按照元素的默认规则(从小到大)升序排序
- TreeSet 集合底层是基于红黑树的数据结构实现排序的,增删改差的性能都比较好。
TreeSet 集合的默认排序规则
- 对于数值类型:Integer、Double,会按照从小到大的顺序进行排序
- 对于字符、字符串类型:会按照字符在ASCII 码表中的数字升序进行排序
例如这里的字符串数组(已排序过):[aaa, ab, aba, cd, qwer] - 若想对于自定义的类的集合排序,需要让其实现 Comparable 接口
- 默认排序,就是让元素所属的类实现 Comparable 接口,重写 compareTo(T o)方法
诸位可以自行运行一下下方的代码,加深理解
Student_3.java
public class Student_3 implements Comparable<Student_3> {
private String name;
private int age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
@Override
public int compareTo(Student_3 s) {
System.out.println("--------------------------------------------------------------------------");
System.out.println("this(当前要添加的元素,未排序):" + this);
System.out.println("s(当前已经在红黑树中的元素,已排序):" + s);
System.out.println("--------------------------------------------------------------------------");
/*
* 首先默认是升序排序(未排序 - 已排序)
* 返回值是负数,表示当前要添加的元素更大,需要存储在左边
* 返回值是正数,表示当前要添加的元素更小,需要存储在右边
* 返回值是 0,表示当前要添加的元素已经存在,舍弃
*/
int result = this.getAge() - s.getAge(); // 按照年龄大小升序排序
return result;
}
}
TreeSetDemo.java
public class TreeSetDemo {
public static void main(String[] args) {
Student_3 s1 = new Student_3("zhangsan", 23);
Student_3 s3 = new Student_3("wangwu", 25);
Student_3 s2 = new Student_3("lisi", 24);
Student_3 s4 = new Student_3("zhaoliu", 26);
Student_3 s5 = new Student_3("lisi", 24);
TreeSet<Student_3> students = new TreeSet<>();
Collections.addAll(students, s1, s4, s3, s2, s5);
System.out.println(students);
}
}
TreeSet 集合添加数据的过程

6.4.2.默认排序 Comparable 的使用
java/lang/Comparable.java
public interface Comparable<T> {
public int compareTo(T o);
}
练习案例
- 需求
- 存储学生对象并遍历,创建 TreeSet 集合使用无参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 实现步骤
- 使用空参构造创建 TreeSet 集合
- 用 TreeSet 集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自定义的 Student 类实现 Comparable 接口
- 自然排序,就是让元素所属的类实现 Comparable 接口,重写 compareTo(T o)方法
- 重写接口中的 compareTo() 方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
- 使用空参构造创建 TreeSet 集合
Student.java
public class Student implements Comparable<Student>{
private String name;
private int age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
@Override
public int compareTo(Student o) {
// 主要判断条件: 按照对象的年龄从小到大排序
int result = this.age - o.age;
// 次要判断条件: 在对象的年龄相同时,按照对象的姓名的字母顺序排序
result = result == 0 ? this.name.compareTo(o.getName()) : result;
return result;
}
}
MyTreeSet_1.java
public class MyTreeSet_1 {
public static void main(String[] args) {
// 创建集合对象
TreeSet<Student> ts = new TreeSet<>();
// 创建学生对象
Student s1 = new Student("zhangsan", 28);
Student s2 = new Student("lisi", 27);
Student s3 = new Student("wangwu", 29);
Student s4 = new Student("zhaoliu", 28);
Student s5 = new Student("qianqi", 30);
// 把学生添加到集合
Collections.addAll(ts, s3, s2, s1, s5, s4);
// 遍历集合
for (Student student : ts) {
System.out.println(student);
}
}
}
输出结果
Student{name='lisi', age=27}
Student{name='zhangsan', age=28}
Student{name='zhaoliu', age=28}
Student{name='wangwu', age=29}
Student{name='qianqi', age=30}
6.4.3.比较器排序 Comparator 的使用
java/util/TreeSet.java
public Comparator<? super E> comparator() {
return m.comparator();
}
java/util/Comparator.java
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
// ... ...
}
练习案例
- 需求
- 存储老师对象并遍历,创建 TreeSet 集合使用带参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 实现步骤
- 用 TreeSet 集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收 Comparator 的实现类对象,重写 compare(T o1,T o2) 方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
Teacher.java
public class Teacher {
private String name;
private int age;
// 无参构造方法、带参构造方法、get()/set()方法、toString()方法 略
}
MyTreeSet_2.java
public class MyTreeSet_2 {
public static void main(String[] args) {
// 创建集合对象
TreeSet<Teacher> ts = new TreeSet<>(new Comparator<Teacher>() {
@Override
public int compare(Teacher o1, Teacher o2) {
// o1 表示现在要存入的那个元素(尚未排序)
// o2 表示已经存入到集合中的元素(已经在红黑树中了,是已经排序过了的元素)
int result = o1.getAge() - o2.getAge(); // 主要条件
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result; // 次要条件
return result;
}
});
// 创建老师对象
Teacher t1 = new Teacher("zhangsan", 23);
Teacher t2 = new Teacher("lisi", 22);
Teacher t3 = new Teacher("wangwu", 24);
Teacher t4 = new Teacher("zhaoliu", 24);
// 把老师添加到集合
Collections.addAll(ts, t2, t4, t1, t3);
// 打印集合
ts.forEach(System.out::println);
}
}
控制台输出
Teacher{name='lisi', age=22}
Teacher{name='zhangsan', age=23}
Teacher{name='wangwu', age=24}
Teacher{name='zhaoliu', age=24}
6.4.5.两种比较方式总结
- 两种比较方式小结
- 自然排序:自定义类实现 Comparable 接口,重写 compareTo 方法,根据返回值进行排序
- 比较器排序:创建 TreeSet 对象的时候传递 Comparator 的实现类对象,重写 compare 方法,根据返回值进行排序
- 在使用的时候,默认使用自然排序,当自然排序不满足现在的需求时,必须使用比较器排序
- 两种方式中关于返回值的规则
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为 0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
6.4.6.小结
- TreeSet 集合的特点是怎么样的?
- 可排序、不可重复、无索引
- 底层是基于红黑树来实现排序的,增删改查的性能好
- TreeSet 集合自定义排序规则有几种方式
- 方式一:JavaBean 类实现 Comparable 接口,指定比较规则
- 方式二:创建集合时,自定义 Comparator 比较器的对象,指定比较规则
- 当方式一和方式二都存在的时候,优先选用方式二的比较规则
- 方法返回值的特点(此处的返回值默认是未排序 - 已排序,升序排序)
- 负数:表示当前要添加的元素是小的,存左边
- 正数:表示当前要添加的元素是大的,存右边
- 0:表示当前要添加的元素已经存在了,舍弃
6.5.源码分析(伪)
java/util/HashSet.java
public HashSet() {
map = new HashMap<>();
}
java/util/LinkedHashSet.java
public LinkedHashSet() {
super(16, .75f, true);
}
java/util/HashSet.java
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
java/util/TreeSet.java
public TreeSet() {
this(new TreeMap<E,Object>());
}
显然,这三个 Set 接口的实现类都与 Map 接口的实现类息息相关,故真正的源码分析会放到 Map 集合的篇章中再讲。
7.Map

7.1.双列集合的特点
- 双列集合一次需要存一对数据,分别是键和值
- 键不可重复,值可以重复
- 键和值是一一对应的关系,每一个键只能找到自己对应的值
- 键 + 值 这个整体我们称之为 “键值对” 或 “键值对对象”。在 Java 中,叫做 “Entry 对象”。
7.2.Map 集合的概述和使用
7.2.1.Map 中的常见 API
| 方法名 | 说明 |
|---|---|
V put(K key, V value) |
添加元素 |
V remove(Object key) |
根据键删除键值对元素 |
void clear() |
移除所有的键值对元素 |
boolean containsKey(Object key) |
判断集合是否包含指定的键 |
boolean containsValue(Object value) |
判断集合是否包含指定的值 |
boolean isEmpty() |
判断集合是否为空 |
int size() |
集合的长度,也就是集合中键值对的个数 |
V put(K key, V value) 细节
- 添加功能 或 覆盖功能
- 在添加数据的时候,如果键不存在,那么直接把键值对对象添加到 map 集合中,方法返回 null
- 在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,并返回被覆盖的旧值。
其实这样说也不是特别对,准确的来说,是把新的对象的值赋值给旧的对象的值,真正替换掉的只有键值对对象的值
诸位可以自行运行一下下方代码
public class MapDemo_1 {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
System.out.println("-----------------------------------");
System.out.println(map.put(1, "阿朱")); // null
System.out.println(map.put(2, "黄蓉")); // null
System.out.println(map.put(3, "小龙女")); // null
System.out.println("被覆盖的值:" + map.put(3, "赵敏")); // 返回被覆盖的值:小龙女
System.out.println(map); // {1=阿朱, 2=黄蓉, 3=赵敏}
System.out.println("当前键值对的数量:" + map.size()); // 3
System.out.println("-----------------------------------");
System.out.println(map.containsKey(2)); // true
System.out.println(map.containsKey(10)); // false
System.out.println(map.containsValue("赵敏")); // true
System.out.println(map.containsValue("王语嫣")); // false
System.out.println(map.remove(1)); // 阿朱
System.out.println(map); // {2=黄蓉, 3=赵敏}
System.out.println("-----------------------------------");
System.out.println(map.isEmpty()); // false
map.clear(); // 清空集合里所有的键值对元素,没有返回值
System.out.println(map); // {}
System.out.println(map.isEmpty()); // true
System.out.println("-----------------------------------");
}
}
7.2.2.Map 集合的获取功能
| 方法名 | 说明 |
|---|---|
V get(Object key) |
根据键获取值 |
Set |
获取所有键的集合 |
Collection |
获取所有值的集合 |
Set |
获取所有键值对对象的集合 |
诸位可以自行运行一下下方代码
public class MapDemo_2 {
public static void main(String[] args) {
//创建集合对象
Map<Integer, String> map = new HashMap<>();
//添加元素
map.put(1, "乔峰");
map.put(2, "郭靖");
map.put(3, "杨过");
map.put(4, "张无忌");
System.out.println(map.get(1)); // 乔峰
System.out.println(map.get(3)); // 杨过
Set<Integer> keySet = map.keySet();
System.out.println("keySet:" + keySet); // keySet:[1, 2, 3, 4]
Collection<String> values = map.values();
System.out.println("values:" + values); // values:[乔峰, 郭靖, 杨过, 张无忌]
Set<Map.Entry<Integer, String>> entries = map.entrySet();
System.out.println("entries:" + entries); // entries:[1=乔峰, 2=郭靖, 3=杨过, 4=张无忌]
}
}
7.2.3.Map 的遍历方式
对于 Map 的遍历方式,在大的方向上可以分为 4 种。
- 迭代器(Iterator)方式遍历
- ForEach 的方式遍历
- Lambda 表达式遍历(JDK 1.8+)
- Streams API 遍历(JDK 1.8+)
分的再具体点的话,可以分成 7 种
- 可以使用迭代器(Iterator)+ EntrySet 的方式进行遍历
- 可以使用迭代器(Iterator)+ KeySet 的方式进行遍历
- 可以使用 For Each EntrySet 的方式进行遍历
- 可以使用 For Each KeySet 的方式进行遍历
- 可以使用 Lambda 表达式的方式进行遍历
- 可以使用 Streams API 单线程的方式进行遍历
- 可以使用 Streams API 多线程的方式进行遍历
| 示例代码 |
首先我们创建一个 Map 集合
Map<Integer, String> map = new HashMap();
map.put(1, "Spring");
map.put(2, "SpringMVC");
map.put(3, "SpringBoot");
map.put(4, "SpringCloud");
map.put(5, "MyBatis");
map.put(6, "MyBatisPlus");
Iterator KeySet
private static void ergodic_KeySet_1(Map<Integer, String> map) {
Set<Integer> keySet = map.keySet();
Iterator<Integer> iterator = keySet.iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key + ";" + map.get(key));
}
}
ForEach KeySet
private static void ergodic_KeySet_2(Map<Integer, String> map) {
Set<Integer> keySet = map.keySet();
for (Integer key : keySet) {
System.out.println(key + ":" + map.get(key));
}
}
Iterator EntrySet
private static void ergodic_EntrySet_1(Map<Integer, String> map) {
Set<Map.Entry<Integer, String>> entries = map.entrySet();
Iterator<Map.Entry<Integer, String>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey() + ";" + entry.getValue());
}
}
ForEach EntrySet
private static void ergodic_EntrySet_2(Map<Integer, String> map) {
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
for (Map.Entry<Integer, String> entry : entrySet) {
System.out.println(entry.getKey() + ";" + entry.getValue());
}
}
ForEach Lambda
private static void ergodic_Lambda_ForEach(Map<Integer, String> map) {
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
}
);
}
- Stream API 单线程
private static void ergodic_Stream_1(Map<Integer, String> map) {
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
- Stream API 多线程
private static void ergodic_Stream_2(Map<Integer, String> map) {
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
其中 Map 的 forEach() 方法源码如下
java/util/Map.java
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
我们使用 forEach() 遍历 Map 集合时,主要就是编写 accept() 方法
// 匿名内部类的方式
map.forEach(new BiConsumer<Integer, String>() {
@Override
public void accept(Integer key, String value) {
System.out.println(key + ":" + value);
}
});
// 用 Lambda 表达式简化一下
map.forEach((key, value) -> System.out.println(key + ":" + value));
7.3.HashMap
7.3.1.基本介绍
HashMap 的特点
- HashMap 是 Map 的一个实现类
- HashMap 中没有需要额外学习的特有方法,直接使用 Map 里的方法即可
- 特点都是由键决定的:无序、不重复、无索引
- HashMap 和 HashSet 的底层原理是一模一样的,都是哈希表的结构
HashMap 的底层原理
- HashMap 的底层是哈希表结构
- HashMap 依赖 hashCode() 方法和 equals() 方法保证键的唯一
- 如果键要存储的是自定义对象,需要重写 hashCode() 方法 和 equals() 方法
这里需要重点说的还是 JAVA 中的 哈希表 的结构
- 在 JDK 8 之前:数组 + 链表
- 自 JDK 8 开始:数组 + 链表 + 红黑树
HashMap 通过 键的哈希值 来找到元素在数组中的位置(hashCode() 方法)。
在 HashMap 插入元素到数组的时候(map.put(key, value))
- 相应数组的位置若为 null,则直接插入键值对
- 如果相应数组的位置不为 null,其会通过 equals() 方法 比较键的属性值
- 如果数组中存在和 Entry 对象的键的相同的属性值,那么这里会用新的 Entry 对象 覆盖 旧的 Entry 对象。
- 如果属性值不相同的话,其就会插入该位置下的链表或红黑树。
- 在 JDK 7 中,新元素插入链表的方式是头插法。
- 在 JDK 8 及其以后的版本中,新元素插入链表的方式是尾插法。
当链表长度超过 树化阈值 8 时,会先尝试扩容来减少链表长度,如果 数组容量>=64,才会进行树化(红黑树)
7.3.2.练习案例
80 人去旅游,有 [A, B, C, D] 四个景点。每个人只能选一个景点,请统计出哪个景点要去的人最多。
public class HashMapDemo_1 {
public static void main(String[] args) {
String[] strings = {"A", "B", "C", "D"};
System.out.println("景点名称:" + Arrays.toString(strings));
List<String> list = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < 80; i++) {
int index = random.nextInt(strings.length);
list.add(strings[index]);
}
Map<String, Integer> hashMap = new HashMap<>();
for (String name : list) {
if (hashMap.containsKey(name)) {
Integer count = hashMap.get(name);
count++;
hashMap.put(name, count);
} else {
hashMap.put(name, 1);
}
}
System.out.println("统计情况:" + hashMap);
int max = 0;
Set<Map.Entry<String, Integer>> entries = hashMap.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
int count = entry.getValue();
if (count > max) {
max = count;
}
}
System.out.println("最大值:" + max);
for (Map.Entry<String, Integer> entry : entries) {
int count = entry.getValue();
if (count == max) {
System.out.println("投票最多的景点:" + entry.getKey());
}
}
}
}
7.4.LinkedHashMap
- 由键决定:有序、不重复、无索引
- 此处的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然是哈希表,只是每一个键值对元素又额外多了一个双链表的机制记录存储的顺序。
7.5.TreeMap
7.5.1.基本介绍
- TreeMap 和 TreeSet 的底层原理是一样的,它们的底层都是红黑树结构。
- 由键决定特性:不重复、无索引、可排序
- 可排序:对键进行排序
- 注意:默认按照键的大小,进行从小到大的排序(即升序排序)。当然,也可以调用者自己规定键的排序规则。
代码书写两种排序规则
- 让集合中的对象实现 Comparable 接口,指定比较规则
- 创建集合时传递 Comparator 比较器对象,指定比较规则(优先级更高)
7.5.2.案例一(使用 Comparator)
案例需求:
- 创建一个 TreeMap 集合,键是整数类型,表示 id 值;值是字符串类型,表示商品名称。
- 要求按照 id 升序排列
public class TreeMapDemo_1 {
public static void main(String[] args) {
Map<Integer, String> treeMap = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer unsorted, Integer sorted) {
return unsorted - sorted; // 升序排序
// return sorted - unsorted; // 降序排序
}
});
treeMap.put(3, "九个核桃");
treeMap.put(1, "粤利粤");
treeMap.put(2, "康帅傅");
treeMap.put(4, "雷碧");
treeMap.put(4, "可恰可乐");
System.out.println(treeMap);
}
}
7.5.3.案例二(使用 Comparable)
案例需求
- 创建一个 TreeMap 集合,键是学生对象(Student),值是地址(String)
- 学生类的属性:姓名、年龄
- 要求按照学生的年龄进行排序,如果年龄相同则按照姓名进行排序
Student.java
public class Student implements Comparable<Student> {
private String name;
private int age;
// 构造方法、get()/set() 方法、toString() 方法、hashCode() 方法、equals() 方法 省略 ... ...
@Override
public int compareTo(Student unsorted) {
int result = unsorted.age - this.age;
result = result == 0 ? unsorted.name.compareTo(this.name) : result;
return result;
}
}
TreeMapDemo_2.java
public class TreeMapDemo_2 {
public static void main(String[] args) {
// 创建 TreeMap 集合对象
Map<Student, String> treeMap = new TreeMap<>();
// 创建学生对象
Student s1 = new Student("Tom", 6);
Student s2 = new Student("Jerry", 6);
Student s3 = new Student("Spike", 8);
// 将学生对象添加到 TreeMap 集合中
treeMap.put(s1, "A 区");
treeMap.put(s2, "B 区");
treeMap.put(s3, "C 区");
// 遍历 TreeMap 集合,打印每个学生的信息
treeMap.forEach((student, address) -> System.out.println(student + ":" + address));
}
}
7.5.4.案例三:利用 TreeMap 进行统计
案例需求:
- 字符串内容:“aababcabcdabcde”
- 请统计字符串中每一个字符出现的次数,并且按照以下格式输出
- 输出形式:a(5)b(4)c(3)d(2)e(1)
public class TreeMapDemo_3 {
public static void main(String[] args) {
String strings = "aababcabcdabcde";
Map<Character, Integer> treeMap = new TreeMap<>();
for (int i = 0; i < strings.length(); i++) {
char c = strings.charAt(i);
if (treeMap.containsKey(c)) {
int count = treeMap.get(c);
count++;
treeMap.put(c, count);
} else {
treeMap.put(c, 1);
}
}
System.out.println(treeMap);
// 遍历集合,并且按照指定的方式进行拼接
StringBuilder stringBuilder = ergodic_1(treeMap);
System.out.println(stringBuilder);
StringJoiner stringJoiner = ergodic_2(treeMap);
System.out.println(stringJoiner);
}
private static StringJoiner ergodic_2(Map<Character, Integer> treeMap) {
StringJoiner stringJoiner = new StringJoiner("", "", "");
treeMap.forEach((key, value) -> stringJoiner.add(key + "").add("(").add(value + "").add(")"));
return stringJoiner;
}
private static StringBuilder ergodic_1(Map<Character, Integer> treeMap) {
StringBuilder stringBuilder = new StringBuilder();
treeMap.forEach(new BiConsumer<Character, Integer>() {
@Override
public void accept(Character key, Integer value) {
stringBuilder.append(key).append("(").append(value).append(")");
}
});
return stringBuilder;
}
}
7.6.源码分析
7.6.1.HashMap 源码分析
java/util/HashMap.java
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
HashMap 里面每一个节点对象的内部属性
- 链表中的键值对对象
int hash;:键的哈希值final K key;:键V value;:值Node:下一个节点的地址值
- 红黑树中的键值对对象
int hash;:键的哈希值final K key;:键V value;:值TreeNode:父节点的地址值TreeNode:左子节点的地址值TreeNode:右子节点的地址值boolean red;:节点的颜色
- HashMap 类中中要知道的一些成员变量
transient Node<K,V>[] table; // 记录了节点组成的数组的地址值
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 数组的默认长度是 16
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认的加载因子
- 如果我们用空参构造创建 HashMap 的对象,底层的节点组成的数组并没有创建
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
- 添加元素的时候要考虑到三种情况
- 数组位置是 null
- 数组位置不是 null,键不重复,挂载下面形成链表/红黑树
- 数组位置不为 null,键重复,元素覆盖
// 节点组成的数组在我们添加元素的时候才会创建
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 利用键计算出对应的哈希值,再对哈希值进行一些额外的处理
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
下方的代码是更改删减版,更易于阅读,把握关键信息
/**
* @param hash 键的哈希值
* @param key 键
* @param value 值
* @param onlyIfAbsent 如果键重复了,是否保留?
* true:表示老元素的值保留,不会覆盖
* false:表示老元素的值不保留,会进行覆盖
* @param evict
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K, V>[] tab; // 定义一个局部变量,用来记录哈希表中数组的地址值。
Node<K, V> p; // 临时的第三方变量,用来记录键值对对象的地址值
int n; // 表示当前数组的长度
int i; // 表示索引
tab = table; // 把哈希表中数组的地址值,赋值给局部变量 tab
if (tab == null || (n = tab.length) == 0) {
// 1.如果当前是第一次添加数据,底层会创建一个默认长度为 16,加载因子为 0.75 的数组
// 2.如果不是第一次添加数据,会看数组中的元素是否达到了扩容的条件
// 如果没有达到扩容条件,底层不会做任何操作
// 如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中
tab = resize();
// 表示把当前数组的长度赋值给n
n = tab.length;
}
// 拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置
i = (n - 1) & hash; // index
p = tab[i]; // 获取数组中对应元素的数据
if (p == null) {
// 底层会创建一个键值对对象,直接放到数组当中
tab[i] = newNode(hash, key, value, null);
} else {
Node<K, V> e;
K k;
// 等号的左边:数组中键值对的哈希值
// 等号的右边:当前要添加键值对的哈希值
// 如果键不一样,此时返回 false
// 如果键一样,返回 true
boolean b1 = p.hash == hash;
if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))) {
e = p;
} else if (p instanceof TreeNode) {
// 判断数组中获取出来的键值对是不是红黑树中的节点
// 如果是,则调用方法 putTreeVal,把当前的节点按照红黑树的规则添加到树当中。
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
} else {
// 如果从数组中获取出来的键值对不是红黑树中的节点
// 表示此时下面挂的是链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 此时就会创建一个新的节点,挂在下面形成链表
p.next = newNode(hash, key, value, null);
// 判断当前链表长度是否超过 8,如果超过 8,就会调用方法 treeifyBin
// treeifyBin 方法的底层还会继续判断
// 判断数组的长度是否大于等于 64
// 如果同时满足这两个条件,就会把这个链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 举例:e 为[0x0044 ddd 444],要添加的元素为[0x0055 ddd 555]
// 如果哈希值一样,就会调用 equals 方法比较内部的属性值是否相同
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
break;
}
p = e;
}
}
// 如果 e 为 null,表示当前不需要覆盖任何元素
// 如果 e 不为 null,表示当前的键是一样的,值会被覆盖
// 举例:e 为 [0x0044 ddd 444],要添加的元素为 [0x0055 ddd 555]
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {
// 等号的右边:当前要添加的值(0x0055 的 555)
// 等号的左边:旧值(0x0044 的 444)
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
// 这里的 threshold 记录的就是(数组的长度 * 0.75),可以理解为其就是哈希表的扩容时机(16 * 0.75 = 12)
if (++size > threshold) {
resize();
}
// 表示当前没有覆盖任何元素,返回 null
return null;
}
此处贴一下 HashMap 中的节点类的部分源码
HashMap 中的内部类:Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash; // 键的哈希值
this.key = key; // 键
this.value = value; // 值
this.next = next; // 记录下一个节点的地址值
}
// ... ...
}
HashMap 中的内部类:TreeNode
TreeNode 继承了 LinkedHashMap.Entry,LinkedHashMap.Entry 又继承了 HashMap.Entry
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点的地址值
TreeNode<K,V> left; // 左子节点的地址值
TreeNode<K,V> right; // 右子节点的地址值
TreeNode<K,V> prev; // 删除后需要取消下一个链接
boolean red; // 节点颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// ... ...
}
- 下方代码块的源代码的相对路径是:
java/util/LinkedHashMap.java
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
7.6.2.TreeMap 源码分析
java/util/TreeMap.java
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
- TreeMap 中每一个节点的内部属性
K key;:键V value;:值Entrye:父节点的地址值Entry:左子节点的地址值Entry:右子节点的地址值boolean red;:节点的颜色int hash;:键的哈希值
- TreeMap 类中中要知道的一些成员变量
public class TreeMap<K,V>{
private final Comparator<? super K> comparator; // 比较器对象(比较规则)
private transient Entry<K,V> root; // 根节点
private transient int size = 0; // 集合的长度
}
- 空参构造(空参构造就是没有传递比较器对象)
public TreeMap() {
comparator = null;
}
- 带参构造(带参构造就是传递了比较器对象)
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
- 添加元素
public V put(K key, V value) {
return put(key, value, true);
}
/**
* @param key 键
* @param value 值
* @param replaceOld 当键重复的时候,是否需要覆盖值
* true:覆盖
* false:不覆盖
* @return
*/
private V put(K key, V value, boolean replaceOld) {
// 获取根节点的地址值,赋值给局部变量 t
Entry<K, V> t = root;
// 判断根节点是否为 null
// 如果为 null,表示当前是第一次添加,会把当前要添加的元素,当做根节点
// 如果不为 null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码
if (t == null) {
// 方法的底层,会创建一个 Entry 对象,把他当做根节点
addEntryToEmptyMap(key, value);
// 返回 null,表示此时没有覆盖任何的元素
return null;
}
int cmp; // 表示两个元素的键比较之后的结果
Entry<K, V> parent; // 表示当前要添加节点的父节点
// 表示当前的比较规则
// 如果我们是采取默认的自然排序,那么此时 comparator 记录的是 null,cpr 记录的也是 null
// 如果我们是采取比较去排序方式,那么此时 comparator 记录的是就是比较器
Comparator<? super K> cpr = comparator;
// 表示判断当前是否有比较器对象
// 如果传递了比较器对象,就执行 if{} 里面的代码,此时以比较器的规则为准
// 如果没有传递比较器对象,就执行 else{} 里面的代码,此时以自然排序的规则为准
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else {
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
} else {
// 把键进行强转,强转成 Comparable 类型的
// 要求:键必须要实现 Comparable 接口
// 如果没有实现这个接口,此时在强转的时候,就会报错
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t; // 此处的赋值操作即把根节点当做当前节点的父节点
// 调用 compareTo 方法,比较根节点和当前要添加节点的大小关系
cmp = k.compareTo(t.key);
if (cmp < 0)
// 如果比较的结果为负数,那么就继续到根节点的左边去找
t = t.left;
else if (cmp > 0)
// 如果比较的结果为正数,那么继续到根节点的右边去找
t = t.right;
else {
// 如果比较的结果为 0,会覆盖
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
// 在这个方法的底层就会把当前节点按照指定的规则进行添加
addEntry(key, value, parent, cmp < 0);
return null;
}
private void addEntry(K key, V value, Entry<K, V> parent, boolean addToLeft) {
Entry<K, V> e = new Entry<>(key, value, parent);
if (addToLeft)
parent.left = e;
else
parent.right = e;
// 添加完毕之后,需要按照红黑树的规则进行调整
fixAfterInsertion(e);
size++;
modCount++;
}
根据红黑树的规则调整
private void fixAfterInsertion(Entry<K, V> x) {
// 因为红黑树的节点默认就是红色的
x.color = RED;
/*
* 按照红黑规则进行调整
* * parentOf:获取 x 的父节点
* * parentOf(parentOf(x)):获取 x 的爷爷节点
* * leftOf:获取左子节点
*/
while (x != null && x != root && x.parent.color == RED) {
// 判断当前节点的父节点是爷爷节点的左子节点还是右子节点
// 目的:为了获取当前节点的叔叔节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
// 表示当前节点的父节点是爷爷节点的左子节点
// 那么下面就可以用 rightOf() 方法获取到当前节点的叔叔节点
Entry<K, V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
/* 叔叔节点为红色的处理方案 */
// 把父节点设置为黑色
setColor(parentOf(x), BLACK);
// 把叔叔节点设置为黑色
setColor(y, BLACK);
// 把爷爷节点设置为红色
setColor(parentOf(parentOf(x)), RED);
// 把爷爷节点设置为当前节点
x = parentOf(parentOf(x));
} else {
/* 叔叔节点为黑色的处理方案 */
// 表示判断当前节点是否为父节点的右子节点
if (x == rightOf(parentOf(x))) {
// 表示当前节点是父节点的右子节点
x = parentOf(x);
// 左旋
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
// 表示当前节点的父节点是爷爷节点的右子节点
// 那么下面就可以用 leftOf() 方法获取到当前节点的叔叔节点
Entry<K, V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
// 把根节点设置为黑色
root.color = BLACK;
}
此处贴一下 TreeMap 中的键值对对象的部分源码
private static final boolean RED = false;
private static final boolean BLACK = true;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
// 节点的颜色(此处默认是黑色)
// 在 TreeMap 调用 put() 方法的时候会调整颜色的
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
// ... ...
}
7.7.关于 Map 的五个问题
- 问题一:TreeMap 添加元素的时候,键是否需要重写 hashCode 和 equals 方法?
- 此时是不需要重写的。
- 问题二:HashMap 是哈希表结构的,JDK8 开始由数组,链表,红黑树组成的。
- 既然有红黑树,HashMap 的键是否需要实现 Compareable 接口或者传递比较器对象呢?
- 不需要的。因为在 HashMap 的底层,默认是利用哈希值的大小关系来创建红黑树的
- 问题三:TreeMap 和 HashMap 谁的效率更高?
- 如果是最坏情况,添加了 8 个元素,这 8 个元素形成了链表,此时 TreeMap 的效率要更高。
- 但是这种情况出现的几率非常的少。
- 一般而言,还是 HashMap 的效率要更高。
- 问题四:你觉得在 Map 集合中,Java 会提供一个如果键重复了,不会覆盖的 put 方法呢?
- putIfAbsent 方法就是这样的一个方法。
- 此时 putIfAbsent 本身不重要。这里主要想讲的是一个思想:
- 代码中的逻辑都有两面性,如果我们只知道了其中的 A 面,而且代码中还发现了有变量可以控制两面性的发生。
- 那么该逻辑一定会有 A 面。
- 习惯:
- boolean 类型的变量控制,一般只有 A、B 两面,因为 boolean 只有两个值
- int 类型的变量控制,一般至少有三面(正数、负数、0),因为 int 可以取多个值。
- 习惯:
- 问题五:三种双列集合,以后如何选择?(HashMap、LinkedHashMap、TreeMap)
- 默认:HashMap(效率最高)
- 如果要保证存取有序:LinkedHashMap
- 如果要进行排序:TreeMap
8.可变参数
在 JDK 1.5 之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化。
- 格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ } - 底层:其实就是一个数组
- 好处:在传递数据的时候,省的我们自己创建数组并添加元素了,JDK 底层帮我们自动创建数组并添加元素了
- 注意事项
- 一个方法只能有一个可变参数
- 在方法的形参中,如果方法中是有多个参数的,那么可变参数要放在最后一个位置。
代码演示
public class ArgsDemo {
public static void main(String[] args) {
int sum = getSum(6, 7, 2, 12, 2121);
System.out.println(sum);
}
public static int getSum(int... arr) {
int sum = 0;
for (int a : arr) sum += a;
return sum;
}
}
应用场景:Collections
- 在 Collections 中也提供了添加一些元素方法
public static:往集合中添加一些元素。boolean addAll(Collection c, T... elements)
public class CollectionsDemo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
// 采用[工具类]一次完成像集合中添加元素的操作
Collections.addAll(list, 5, 222, 1, 2);
System.out.println(list);
}
}
9.集合工具类:Collections
java.utils.Collections 是集合的工具类,用来对集合进行操作的。
Collections 中提供的一些 API
| 方法名称 | 说明 |
|---|---|
public static void shuffle(List list) |
打乱集合顺序 |
public static |
将集合中元素按照默认规则排序 |
public static |
将集合中元素按照指定规则排序 |
public static |
将集合中元素按照默认规则排序 |
public static ) |
将集合中元素按照指定规则排序 |
public static |
以二分查找法朝招元素 |
public static |
拷贝集合中的元素 |
public static |
使用指定的元素填充集合 |
public static |
根据默认的自然排序获得最大值/最小值 |
public static void swap(List list, int i, int j) |
交换集合中指定位置的元素 |
- 注意:
Collections.sort()不可以直接对自定义类型的 List 集合排序,除非其实现了比较规则 Comparable 接口
示例代码
Student.java
public class Student {
private String name;
private int age;
// 构造方法、get/set、toString(省略)
}
CollectionsDemo_2
public class CollectionsDemo_2 {
public static void main(String[] args) {
// 创建四个学生对象 存储到集合中
List<Student> list = new ArrayList<Student>();
list.add(new Student("rose", 18));
list.add(new Student("jack", 16));
list.add(new Student("abc", 20));
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge(); // 以学生的年龄升序
}
});
list.forEach(System.out::println);
}
}
- 打印结果
Student{name='jack', age=16}
Student{name='rose', age=18}
Student{name='abc', age=20}