解读Facebook CAN:如何给人工智能赋予艺术创作的力量
雷锋网 AI 科技评论按:能够迭代进化、模仿指定数据特征的GAN(生成式对抗性网络)已经是公认的处理图像生成问题的好方法,自从提出以来相关的研究成果不少,在图像增强、超分辨率、风格转换任务中的效果可谓是惊人的。 (具体可以参见 Valse 2017 | 生成对抗网络(GAN)研究年度进展评述 - 雷锋网(公众号:雷锋网) )

利用GAN达到图像超分辨率和风格转换示例
今年也有利用GAN做的简笔画到图像转换模型pix2pix(代码地址 https://github.com/phillipi/pix2pix ,demo地址 https://affinelayer.com/pixsrv/ )。除了下图转换猫的,还有建筑物的、鞋子的、包包的,模型非常有想象力,随便画也没关系,感兴趣的读者可以自己到demo地址里画画看。

demo中用把线条转换成猫的示例
GAN能生成艺术作品吗?
GAN既然已经有如此的图像生成能力了,我们能不能用GAN生成艺术作品呢,毕竟许多现代艺术作品看照片好像也并不怎么复杂,比如下面这幅;超写实主义的就更不用说了。
蒙德里安《红黄蓝的构成》
然而,要创造出一副人类觉得有艺术价值的作品并没有那么简单。人类喜欢创新性的作品,人类不喜欢完全模仿的作品;《蒙娜丽莎》和《兰亭集序》只有原作者的原版才被认可是世界艺术瑰宝,后世的人就算基于它们创作,也要有自己的创新,才能带来新的艺术价值,才能被观赏者认可。
根据GAN的基本结构,鉴别器D要判断生成器G生成的图像是否和其它已经提供给鉴别器D的图像是同一个类别(特征相符),这就决定了最好的情况下输出的图像也只能是对现有作品的模仿,如果有创新,就会被鉴别器D识别出来,就达不成目标了。上面几个GAN的例子就能体现出鉴别器D带来的这个特点,用GAN生成的艺术作品也就注定缺乏实质性的创新,艺术价值有限。
那么,能不能让GAN具有一些创新的能力,让这些创新有艺术价值、带有这些创新的作品还能够被人类认可呢?罗格斯大学艺术与人工智能实验室、Facebook人工智能研究院(FAIR)、查尔斯顿学院艺术史系三方合作的这篇论文就通过CAN(Creative Adversarial Network,创造性对抗网络)给出了一种答案。神经网络库Keras的作者François Chollet也在Twitter上推荐了这篇文章。

先看看作品如何

CAN模型生成的一些艺术作品
可以看到,生成的艺术作品风格非常多样,从简单的抽象画到复杂的线条组合都有,内容层次也有区分。论文中也有对比测试结果,CAN生成的作品不仅比GAN生成的更讨人喜欢,甚至来自巴塞尔艺术展的人类艺术作品都比不上CAN。(具体数据看后文)
如何认识艺术创新
刚才说到,艺术作品需要有创新性,CAN中的C就是Creative,创新性的意思。那么创新性要如何衡量呢、如何达到呢?
以往基于GAN的图像生成方法研究中,人类可以把训练好的网络生成的图像和客观事实相对比(超分辨率、图像补全问题中)或者根据经验判断(风格转换问题中),用来衡量网络的效果;也有过一些更早期的算法,让人类作为训练反馈的一环,引导网络的训练过程。但是对于这次的课题需要设计一个能自动训练和生成、还要衡量作品的创新性的系统而言,以往的方法就起不到什么帮助。
同时,在作者们看来,为了能模仿人类艺术创作的过程,算法中很重要的一部分就是要把算法的创意过程和人类艺术家以往的艺术作品联系起来,像人类一样把对以往艺术的理解和创造新艺术形态的能力整合在一起。 为了能够想办法找到一个能够衡量创新性、参与迭代训练的创新性指标,作者们找来了一组艺术理论。
D.E.Berlyne认为,从生理心理学的角度讲,人类的状态中有一种叫做“唤醒水平”的指标,它可以衡量一个人有多警醒、多兴奋;唤醒水平可以从最低的睡觉、休息,一直到暴怒、激动。而一副作品具有“唤醒潜力”的总体特质,它可以提升或者降低观者的唤醒水平;它是作品新颖性、意外性、复杂性、多义性和疑惑性高低的综合体现,这几个属性越高,作品的唤醒潜力就越高。
Colin Martindale(1943-2008)提出过一个假说,他认为在任一时刻,创意艺术家们都会尝试增加他们作品的“唤醒潜力”,这就是一种拓宽创作习惯边界的方法。但是,这种增加动作必须使得观察者的负面反应尽可能小(尽量使观察者不付出额外的努力),否则过于激进的产品就会受到负面的评价。
Colin Martindale还提出过一个假说,他认为当艺术家探索艺术风格的更多作用的时候,转换艺术风格就会有提高“唤醒潜力”的作用。
这组理论只是解释艺术创新的理论中的寥寥几个,但是它们综合起来给出了两个具有计算性的、可以用于迭代训练的指标:
-
创新作品的创新程度不能过高,观者不认为作品是艺术作品的可能性应当尽可能小;
-
新的艺术风格就是创新的体现。
CAN网络的构建
根据提炼出的这两个指标,论文中基于GAN的原型构建了这样一种新型的对抗性网络CAN。
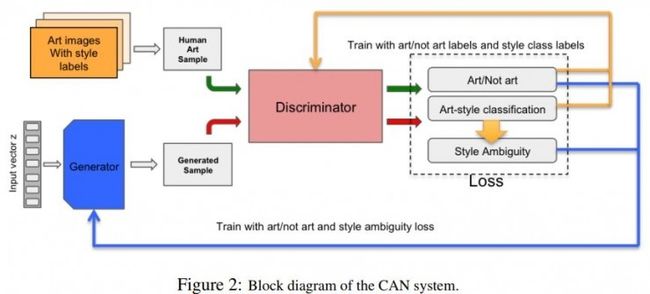
CAN模型的系统框图
首先,对于“指标1:创新作品的创新程度不能过高,观者不认为作品是艺术作品的可能性应当尽可能小”,就可以转换为经典的对抗性网络,G生成图像,经过艺术作品训练过的D判断G生成图像的是不是艺术作品。这样的对抗性网络生成的图像就已经可以被人类看作是艺术作品。
然后,论文中的模型还根据“指标2:新的艺术风格就是创新的体现”增加了一部分新结构用来处理艺术风格。
论文中使用了25类不同的带标签艺术作品用于D的训练,包含了抽象印象派、立体派、现代派、巴洛克、文艺复兴早期等等风格的共7万5千多幅。然后经过训练的D除了要反馈一幅图像“是否是艺术作品”外,还要反馈“能否分辨图像是哪种艺术风格”。G然后就会利用D的反馈生成尽量难以分辨艺术风格的图像——难以归类到现有分类中的,就是创新了。
“是否是艺术作品”、“是否难以分辨艺术风格”是两种对立的信号,前一种信号会迫使生成器G生成能够被看作的艺术的图像,但是假如它在现有的艺术风格范畴中就达到了这个目标,鉴别器D就能够分辨出图像的艺术风格了,然后生成器就会受到惩罚。这样后一种信号就会让生成器生成难以分辨风格的作品。所以两种信号就可以共同作用,让生成器能够尽可能探索整个创意空间中艺术作品的范围边界,同时最大化生成的作品尽可能游离于现有的标准艺术风格之外。
这也就是论文标题「CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms」的含义,创造性对抗网络可以学习艺术风格,然后背离这些现有的风格进行艺术创作。
还说艺术风格,现在是“不好分辨”,“好分辨”不行吗?
相比GAN,CAN增加的反馈是“是否难以分辨艺术风格”,追求的是生成的图像艺术风格难以分辨。虽然根据艺术理论的推导,新的艺术风格是一种创新,但既然是多加了一个反馈,追求“生成的图像艺术风格容易分辨”可以吗?会不会也能生成不错的作品呢?
从另一个角度看,假如追求“难以分辨”的CAN确实比追求“容易分辨”的CAN生成的图像更好,那这就是模型选取了合理的反馈的最佳体现。
说做就做。除了CAN之外,论文中还建立了三种模型用来对比。
-
DCGAN 64x64:经过艺术作品训练的DCGAN(深度卷积生成式对抗网络),输出分辨率为64x64
-
DCGAN 256x256:相比DCGAN 64x64,生成器多加了两层网络,输出分辨率为256x256
-
scCAN:style-classification-CAN,追求“生成的图像艺术风格容易分辨”的CAN
这三种模型生成的画面像下面这样
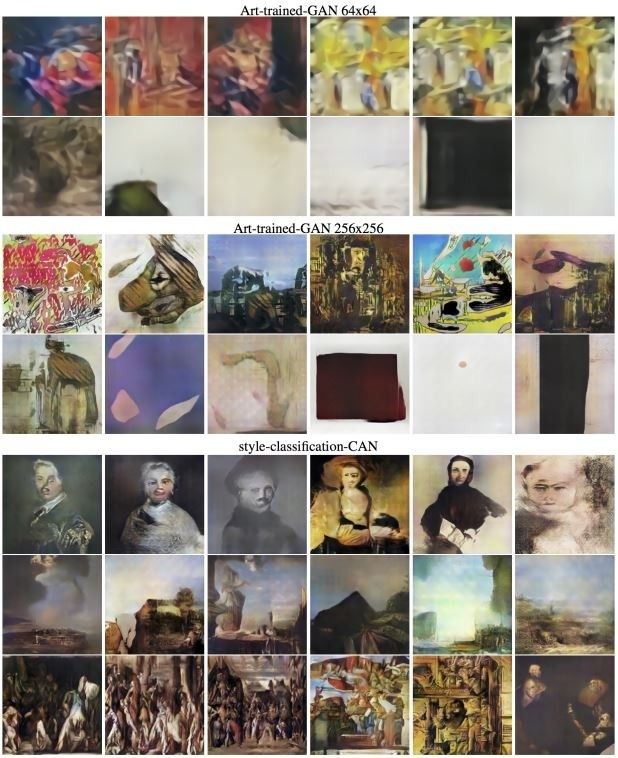
两种DCGAN和scCAN生成的画面
scCAN生成的画面中确实有了可辨认的风格,比如人物特写、风景或者群像。但是直观看上去并不怎么讨人喜欢。
让我们再来看一组CAN生成的图像,上方是人类评价最高的、下方是人类评价最低的。应该说都比scCAN生成的图像精彩得多。

人类评价最高和最低的CAN生成的图像
人类能给CAN的图像打几分?
根据刚才的图像可以看到,CAN的效果当然不错,DCGAN 256x256的图像其实也挺好。那么CAN的图像对观画的人来说是不是真的已经难以分辨创作者了呢?跟真的艺术家创作的作品相比高下又如何呢?
为了具体比较,论文中做了几个实验,让人类给不同组的作品打分。
实验1、2: 来自抽象印象派艺术家的作品、选自巴塞尔艺术展的作品、CAN生成的图像、DCGAN生成的图像,一共4组作品,由普通人判断这些作品来自人还是电脑,并给作品打分。
结果:实验1里有53%的人认为CAN的图像是来自人类的,认为DCGAN 64x64的图像来自人的有35%; 实验2里认为CAN的图像来自人类的比例是75%,DCGAN 256x256则是65%。来自抽象印象派艺术家的作品无疑是比例最高的,但有意思的是,两个实验里认为巴塞尔艺术展的作品来自人的比例都还不如CAN高(实验1中41%,实验2中48%)。

实验2的结果数据,先让人类评价者从几个角度评价作品,再判断是否是人类创作的。认为图像是人类创作的评价者比例为Q6
实验3:让人类评价者从用心程度、视觉结构、互动性、启发性几个角度给作品评分,结果CAN全部得分最高。这个结果可谓出人意料。
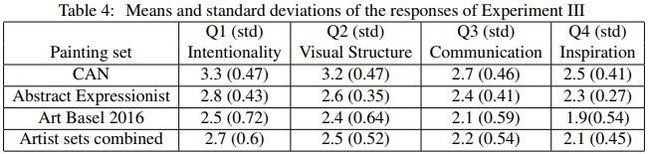
实验3结果数据
实验4:为了确认CAN和scCAN之间新颖性和美学表现的高低,请了一群艺术史学生对随机选出的CAN和scCAN图像进行评价。认为CAN的图像更新颖的比例为59.47%,认为CAN的图像更加有美学吸引力的比例为60%,确实有显著区别。
结论
论文中表示,虽然这样的模型还是不能对艺术风格概念有任何语义方面的理解,不过它确实展现出了从以往的艺术作品中学习的能力。至于为什么人类会在多个方面给CAN打出高分,作者们也希望和大家进行开放性的探讨。
论文原文地址: https://arxiv.org/abs/1706.07068 ,雷锋网 AI 科技评论编译
本文作者:杨晓凡
本文转自雷锋网禁止二次转载,原文链接