【计算机体系结构-04】流水线:基础与中级概念 (Pipelinling: Basic and Intermediate Concepts)
1. 借题引入
在亚当·斯密所著的《国富论》一书中有描述过这样的场景,扣针制造业中制造一个扣针需要先后完成抽铁丝、拉直、切截、削尖铁丝的一端、打磨铁丝的另一端(以便安装圆头),制作圆头也需要二三种不同的操作,包括装圆头、涂白、包装这些工序。这样详细的划分后,制作一个扣针的步骤被分为 18 道工序。有一个小的工厂中为制作扣针雇佣了十个工人,其中有几个工人需要兼顾完成两三道工序,在这样小工厂中虽然资源匮乏的就连必要的机械设备也很简陋,但只要每个工人都勤勉地工作,一天也能生产出 12 磅扣针,每磅扣针约有 4000 枚,这样这个工厂每天可以生产出 48000 枚扣针,即每人每天可以制造出 4800 枚。如果这些工人没有分工合作而是各自独立完成扣针制作,恐怕没有任何一个人可以完成一天 4800 枚的目标。
2. 流水线
实际上上面的例子已经是一个流水线业务了,一条生产线由 10 个工人来承担,那么我们称这样的生产线为 10 级流水线([注]:超过 5 级流水线也被称为超流水线。)
在计算机中,流水线是一种将多条指令重叠执行的实现技术。我们知道一条指令的执行需要多个操作,而流水线技术就是充分利用了这些操作之间的并行性。如今流水线是用于加快 CPU 速度的关键实现技术。
就像上面的扣针生产线,在一条生产线上由多个工人分别负责不同的任务共同协作完成一个扣针的制作,并且工人之间的执行的动作步骤都是并行的。计算机中的流水线也一样,流水线中的每个步骤完成指令的一部分,不同步骤并行完成指令中的不同部分。而这些步骤中的每一步被称为流水级 (pipe stage) 或流水段 (pipe segment)。流水级前后连接形成流水线,指令将从流水线的一端进入,通过这些流水级从另一端退出。
在扣针生产线中,吞吐量 (throughput) 定义为每小时生产的扣针数量,由完整的扣针退出生产线的频率决定。类似的,指令流水线的吞吐量由指令退出流水线的频率决定。所有流水级是连在一起的,所以每个流水级都必须做好同时工作的准备(并行工作)。
将一条指令在流水线中下移一步所需要的时间为处理器周期 (processor cycle)。因为是所有流水级同时进行,那么处理器周期的长度则由最慢的流水级所需要的时间决定。在计算机中,这一处理器周期通常为 1 个时钟周期(有时也会是 2 个,但非常少见)。
流水线设计者的目标是平衡每条流水线的长度,就像扣针生产线的设计者尝试拆分制作步骤并平衡每个步骤的时间一样。如果各流水级达到完美平衡,那么每条指令在流水线处理器 (pipelined processor) 上的时间(假定为理想条件)就等于:

在这样的条件下,因为实现了流水线,从而得到的加速比等于流水级的数目,就像一个 n 级生产线在理想情况下可以将扣针生产速度提高至 n 倍一样。但一般情况,这些流水线之间不会达到完美平衡,此外,流水线本身还会产生开销。因此,在流水线处理器上,处理每条指令的时间不会等于其最低可能指,但可以非常接近。
流水线可以缩短每条指令的平均执行时间。 这一缩短量可记作每条指令时钟周期数 (CPI-Clock Cycle Per Instruction) 的下降、时钟周期时间的缩短,或者这两者的组合。如果在开始时,处理器需要多个时钟周期来处理一条指令,那么将认为流水线的作用时降低了 CPI;而如果在开始时,处理器需要一个较长的时钟周期来处理一条指令,那么就认为流水线是缩短了时钟周期的时间。
3. RISC 指令集基础知识
精简指令集 RISC 是一种载入——存储体系结构 (Load-Store Architecture)。所有的 RISC 架构都有以下几个关键属性。
- 所有数据操作都是对寄存器中的操作,通常会改变整个寄存器(每个寄存器为
32位或64位); - 仅有
Load和Store操作会影响存储器,他们分别将数据从存储器移到寄存器或从寄存器移到存储器。 - 指令格式相对固定,所有指令位宽通常相同。在
RISC-V中,寄存器说明符rs1、rs2和rd总是固定在同一个位置编码从而简化了控制。
这些简单属性极大的简化了流水线的实现,这也是这样设计这些指令集的原因。这里假定各位读者已经了解了 RISC-V ISA。若没有,则可以通过笔者的这篇博客快速了解《RISC-V ISA》文章待编写,链接待添加。
4. RISC 指令集的简单实现
先来看不采用流水线是如何实现 RISC 指令集,此处用一种简单的实现来描述,在 RISC 子集中的每条指令最多需要 5 个时钟周期完成。这 5 个时钟周期如下所述:
- (1) 指令提取周期 (
IF-Instruction Fetch)
将程序计数器 (PC-Program Counter) 发送到存储器,从存储器提取当前指令。向程序计数器加4(MIPS每条指令的长度位4个字节),将程序计数器更新到下一个连续程序计数器; - (2) 指令译码/寄存器提取周期 (
ID-Instruction Decode)
对提取到的指令译码,并从寄存器堆中读取与寄存器源说明符相对应的寄存器。在读取寄存器时对其进行相等测试,以确定是否为分支。
指令译码与寄存器的读取时并行执行的,这可能是因为在RISC体系结构中,寄存器描述符位于固定位置。这一技术称为固定字段译码 (Fixed-Field Decoding)。需要注意的是,这里也许会读取一个寄存器但并不会使用,虽然这么做没有什么好处,但也不会影响到性能。(由于读取寄存器与译码在同一个周期完成,读取一个不会用到的寄存器,从时间上来讲并没有增加。不过这样的读取无需寄存器的确会增加功耗,特定场景下的设计可以避免这个问题。)由于一个指令的立即数部分也位于同一位置,所以在需要符号扩展立即数时,也是在这一周期计算。 - (3) 执行/有效地址周期 (
EX-Execution)
ALU对上一周期中准备的操作数进行操作,根据指令类型执行四种操作之一。
<1> 存储器访问——ALU将基址寄存器和偏移量加到一起,形成有效地址;
<2> 寄存器-寄存器ALU指令——ALU用读取到的寄存器堆值,根据ALU操作码执行指定操作;
<3> 寄存器-立即数ALU指令——ALU用读取到的寄存器堆的第一个值和符号扩展立即数执行ALU操作码指定的操作;
<4> 条件分支——判断条件是否为真。
在Load-Store体系结构中,有效地址与执行周期何以合并到一个时钟周期中,这是因为没有指令需要同时计算数据地址并对数据执行操作。 - (4) 存储器访问 (
MEM-Memory)
如果该指令是一条load指令,则使用上一周期计算的有效地址从存储器中读取数据。如果是一条store指令,则使用有效地址将从寄存器堆的第二个寄存器读取的数据写入存储器。 - (5) 写回周期 (
WB-Write Back)
<1> 寄存器-寄存器ALU指令或load指令。
将结果写入寄存器堆,无论是来自寄存器系统(load指令),还是来自ALU(ALU指令)。
在这样的设计中,分支指令需要 3 个时钟周期(IF、ID、EX),存储指令需要 4 个周期(IF、ID、EX、MEM),其它所有指令需要 5 个周期。假设分支频率为 12%,存储频率为 10%,对于这样的典型指令分布,总的 CPI 为 4.66。(12% × 3 + 10% × 4 + 78% × 5 = 4.66)
5. RISC 处理器的经典五级流水线
对于上面的无流水线指令集的实现,几乎不用进行什么改造就可以实现流水化,只需要在每个时钟周期开始一条新的指令就行,即将上面的每个时钟周期变成一个流水级完成了流水化。这样的实现的流水线就会像下面这样。

在每个时钟周期,提取另一条指令,并开始它的五个周期的执行过程。如果在每个时钟周期都启动一条指令,其性能最多可达非流水化处理器的 5 倍。流水线中各个阶段的名称与非流水线实现方式中每个周期的名称相同。
上面的流水化是一种理想情况的设计。首先要确定的是流水线处理器的每个时钟周期都会发生什么,确保不会在同一时钟周期内对相同数据路径源执行两个不同操作。

[注]:该图描述的是各流水级之间的数据路径。
CC (Clock Cycle): 时钟周期;
IM (Instruction Memory): 指令存储器;
Reg (Register): 寄存器;
ALU (Arithmetic Logic Unit): 算术逻辑单元;
DM (Data Memory): 数据存储器;
上图绘制了一个 RISC 数据路径的简化版。IF 周期从 IM 中提取指令,ID 周期读寄存器并译码指令,EX 周期使用 ALU 计算有效地址,MEM 周期一周期计算的有效地址从存储器中读取数据(Load 指令),或直接使用有效地址将从寄存器堆的第二个寄存器读取的数据写入存储器(ALU 指令),WB 周期将结果写入寄存器。
从以下三点可以看出,主要功能单元是在不同周期使用的,因此多条指令的执行重叠不会引入多少冲突。
第一,这里使用分离的指令存储器 IM 和数据存储器 DM 从而避免了指令提取和数据存储器访问之间可能会发生的冲突。
[注]:若流水线处理器的时钟周期等于非流水线版本的时钟周期,则存储器系统必须提供 5 倍的带宽。
第二,在该过程中的两个阶段都使用了寄存器堆,一个是在 ID 中读取,一个是在 WB 中写入。 图中为了描述寄存器的一部分在该流水级进行读取,另一部分进行写入,分别用左右两侧的实线或虚线来表示。因此可以看到每个时钟周期需要执行两次读取和一次写入,为了处理对相同寄存器的多次读取和一次写入,将这样设计,在时钟周期的前半部分写寄存器,在后半部分读寄存器。
第三,上图并没有给出程序计数器 PC,为了在每个时钟周期都启动一条新的指令,我们必须在每个时钟周期使程序计数器递增并存储它,这必须在 IF 阶段完成,以便为下一条指令做好准备。另外还需要一个加法器,在 ID 期间计算潜在的分支目标。
尽管确保了流水线中的指令不会因为试图在同一个时钟周期使用同一个硬件资源导致的冲突。现在还必须要确保不同流水级之间的指令不会相互干扰。可以通过在连续流水级之间引入流水线寄存器来完成,即在时钟周期的末尾将流水级得出的所有结果都保存到寄存器中,在下一个时钟周期作为下一级的输入。
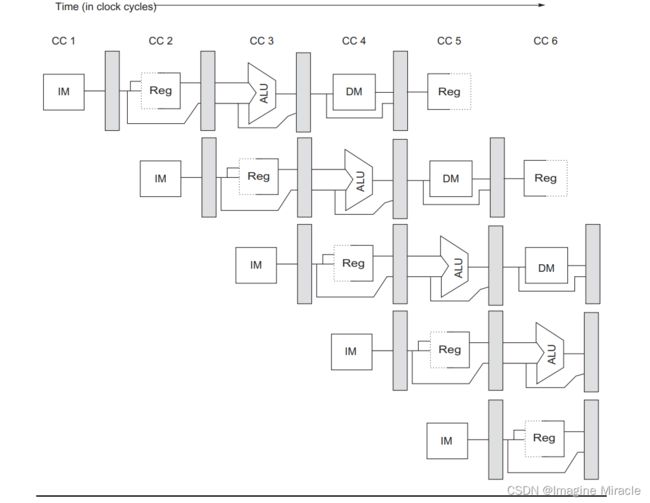
为了防止流水级相邻级中两条不同指令之间的干扰而引入流水线寄存器,由于寄存器具有边沿触发特性,即取值在时钟沿即使改变。在流水化处理器中,如果要将中间结果从一级传送到另一级,而原位置与目标位置可能并非直接相邻此时流水线寄存器则发挥着关键作用(因为只有寄存器中的值在跨越时钟边界后任得以保存)。例如,load 指令中存储的寄存器值是在 ID 期间读取的,但要等到 MEM 才会真正用到,它在 MEM 级中通过两个流水线寄存器传送给数据存储器。
6. 流水化的基本性能问题
流水化提高了 CPU 指令吞吐量(单位时间内完成的指令数),但并不会缩短单条指令的执行时间。事实上,由于实现流水线的本身控制会产生一定的开销,通常情况下还会在一定程度上延长每条指令的执行时间。虽然说单条指令的运行速度并没有加快,但是吞吐量的增加则意味着程序可以更快的运行,缩短了每条指令的平均执行时间,从而达到总执行时间的缩短。
由于单条指令的执行时间并没有缩短,这实际上限制了流水线的实际深度。除了因为流水线延时产生的据限之外,流水级之间的失衡和流水化开销也会造成限制。流水级之间的不平衡会降低性能,这是因为时钟的运行速度不可能快于最缓慢的流水级。
流水线开销包含流水线寄存器的延时和时钟偏差。流水线寄存器增加了建立时间,即在发出触发写操作的时钟信号之前,寄存器输入必须保持稳定的时间,并且时钟周期的传播也会产生延时。时钟偏差是时钟到达任意两个寄存器时刻之间的最大延时,时钟周期的下限也受此因素的影响。如果时钟周期小于时钟偏差与延时开销之和,那么一个时钟周期中就没有留给有用工作的时间,此时再增加流水线也就没有了意义。
如果流水线中每条指令之间都相互独立没有依赖性,那么这种简单的 RISC 流水线对于证书指令是可以正常运行。但事实上,流水线中的指令很多都是存在相互依赖的关系,这也是导致流水线冒险的一个原因。
觉得这篇文章对你有帮助的话,就留下一个赞吧*^v^*
请尊重作者,转载还请注明出处!感谢配合~
[作者]: Imagine Miracle
[版权]: 本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
[本文链接]: https://blog.csdn.net/qq_36393978/article/details/128848711