C++字符编码的查看和检测
1、查看字符编码
查询汉字GBK、UTF8、UNICODE编码的值的网站如下:
汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode (qqxiuzi.cn)
“汉字”编码的数据如下:

现使用程序demo进行验证:
// Encode.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include
#include
#include
using namespace std;
//将wstring转换成string
string wstring2string(wstring wstr,UINT nCode)
{
string result;
//获取缓冲区大小,并申请空间,缓冲区大小事按字节计算的
int len = WideCharToMultiByte(nCode, 0, wstr.c_str(), wstr.size(), NULL, 0, NULL, NULL);
char* buffer = new char[len + 1];
//宽字节编码转换成多字节编码
WideCharToMultiByte(nCode, 0, wstr.c_str(), wstr.size(), buffer, len, NULL, NULL);
buffer[len] = '\0';
//删除缓冲区并返回值
result.append(buffer);
delete[] buffer;
return result;
}
int main()
{
char szChn1[20] = {"汉字"};
wstring wstrChn = L"汉字";
string strCh = wstring2string(wstrChn,CP_UTF8);
char szChn2[20] = { 0 };
int nSize = sizeof(strCh);
int nlen = strCh.length();
int nStrlen = strlen(strCh.c_str());
strncpy_s(szChn2,strCh.c_str(), nStrlen);
std::cout << "Hello World!\n";
}
上述程序的执行结果如下:
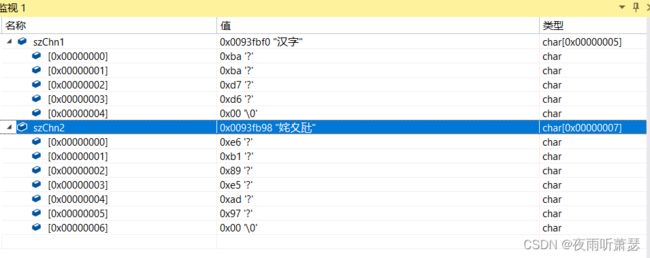
从上述的程序结果可以看出,szChn1的编码是BABAD7D6,是GBK编码;szChn2的字符编码是E6B189E5AD97,是UTF8编码。
注1:/***********************计算字符串长度函数简单比较**********************************/
(1)size()与length()完全等同,string的成员函数,遇到空字符不会被截断,可以返回字符串真实长度。
(2)strlen(),源于C语言,参数是char*,遇到空字符会截断,从而无法返回字符串真实长度。
(3) sizeof是C/C++中的一个操作符(operator),简单的说其作用就是返回一个对象或者类型所占的内存字节数。
注2:/***********************字符编码知识**********************************/
(1)ASCII 是美国国家标准学会制定的,使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。
(2)GBK是中国信息技术标准化技术委员会制订表示汉字的编码,采用双字节编码方式。
(3)UNICODE是国际标准化组织定义一套编码方案来解决所有国家的编码问题,注意Unicode不是一个新的编码规则,而是一套字符集(为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)),可以将Unicode理解为一本世界编码的字典。
(4)UTF8:由于Unicode比较浪费网络带宽和硬盘,制订了UTF8,最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。UTF8是比较通用的编码方式。
ANSI是当前系统默认的编码,取决于电脑安装的字符,所以我们大多数电脑编码默认是GBK。
编码方式知识参考如下博文:ASCII,Unicode和UTF-8终于找到一个能完全搞清楚的文章了_Deft_MKJing宓珂璟的博客-CSDN博客_ascii和utf
还有一篇文章写的不错,如下:ASCII、Unicode、GBK、UTF-8之间的关系_longwen_zhi的博客-CSDN博客_ascii gbk
2、判断字符编码
判断字符编码的demo如下:
// Encode.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include
#include
#include
using namespace std;
//将wstring转换成string
string wstring2string(wstring wstr,UINT nCode)
{
string result;
//获取缓冲区大小,并申请空间,缓冲区大小事按字节计算的
int len = WideCharToMultiByte(nCode, 0, wstr.c_str(), wstr.size(), NULL, 0, NULL, NULL);
char* buffer = new char[len + 1];
//宽字节编码转换成多字节编码
WideCharToMultiByte(nCode, 0, wstr.c_str(), wstr.size(), buffer, len, NULL, NULL);
buffer[len] = '\0';
//删除缓冲区并返回值
result.append(buffer);
delete[] buffer;
return result;
}
//
enum Encode { ANSI = 1, UTF16_LE, UTF16_BE, UTF8_BOM, UTF8 };
Encode IsUtf8Data(const uint8_t* data, size_t size)
{
bool bAnsi = true;
uint8_t ch = 0x00;
int32_t nBytes = 0;
for (auto i = 0; i < size; i++)
{
ch = *(data + i);
if ((ch & 0x80) != 0x00)
{
bAnsi = false;
}
if (nBytes == 0)
{
if (ch >= 0x80)
{
if (ch >= 0xFC && ch <= 0xFD)
{
nBytes = 6;
}
else if (ch >= 0xF8)
{
nBytes = 5;
}
else if (ch >= 0xF0)
{
nBytes = 4;
}
else if (ch >= 0xE0)
{
nBytes = 3;
}
else if (ch >= 0xC0)
{
nBytes = 2;
}
else
{
return Encode::ANSI;
}
nBytes--;
}
}
else
{
if ((ch & 0xC0) != 0x80)
{
return Encode::ANSI;
}
nBytes--;
}
}
if (nBytes > 0 || bAnsi)
{
return Encode::ANSI;
}
return Encode::UTF8;
}
Encode DetectEncode(const uint8_t* data, size_t size)
{
if (size > 2 && data[0] == 0xFF && data[1] == 0xFE)
{
return Encode::UTF16_LE;
}
else if (size > 2 && data[0] == 0xFE && data[1] == 0xFF)
{
return Encode::UTF16_BE;
}
else if (size > 3 && data[0] == 0xEF && data[1] == 0xBB && data[2] == 0xBF)
{
return Encode::UTF8_BOM;
}
else
{
return IsUtf8Data(data, size);
}
}
/
int main()
{
char szChn1[5] = {"汉字"};
wstring wstrChn = L"汉字";
string strCh = wstring2string(wstrChn,CP_UTF8);
char szChn2[7] = { 0 };
int nSize = sizeof(strCh);
int nlen = strCh.length();
int nStrlen = strlen(strCh.c_str());
strncpy_s(szChn2,strCh.c_str(), nStrlen);
Encode emCode1;
emCode1 = IsUtf8Data((const unsigned char*)szChn1,strlen(szChn1));
Encode emCode2;
emCode2 = IsUtf8Data((const unsigned char*)szChn2, strlen(szChn2));
std::cout << "Hello World!\n";
}
执行结果如下:

上述demo中部分代码参考于C++判断字符串编码格式(ANSI\UTF16_LE\UTF16_BE\UTF8\UTF8_BOM)_xingyundandan的博客-CSDN博客_c++ 查看字符串的编码