单链表你别再找我了,我怕双向链表误会
目录
带头双向循环链表的创建和初始化
创建一个新的结点(方便复用)
链表判空
链表打印
链表尾插
链表尾删
链表头插
链表头删
任意插入
任意删除
链表查找
链表销毁
完整代码
前言
- 之前我们讲了结构最简单,实现起来却最为复杂的单链表——不带头单向不循环链表,但其往往不会被运用到存储数据当中,而是作为一些数据结构的子结构(如哈希表)。
- 而今天我们要学的则是听起来,看起来结构最为复杂,但是实施起来却最为简单的带头双向循环链表。
带头双向循环链表的创建和初始化
首先我们需要一个哨兵位,因为在单链表的学习当中我们发现,如果没有哨兵位,当链表为空的时候插入结点就要改变头结点,这时候就要传二级指针或者返回值,也要和其他情况区分,不能一套代码解决所有情况。但如果带哨兵位头节点的话,二级指针和返回值都不需要用到,并且头删头插尾插尾删都特别的方便,它的优势处,下面会一一体现。
结点的定义也和单链表不同,多了一个指针指向前一个结点
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}ListNode;
此时的head就是我们的哨兵位,但是不存储有效数据。如果链表为空,则head的prev以及next都指针都指向自己。
基于以上思路,我们可以写出创建一个哨兵位的代码了,也就是双向链表的建立。
ListNode* ListCreate()
{
ListNode*dummmyhead=(ListNode*)malloc(sizeof(ListNode));
dummmyhead->next = dummmyhead;
dummmyhead->prev = dummmyhead;
return dummmyhead;
}创建一个新的结点(方便复用)
- 在后续的插入接口中,要经常创建一个新的结点进行插入,所以在开头我们可以先将其制作成一个接口,方便代码的复用,这是很重要的工程项目思维。
- 创建新的结点,其实就是向内存申请一块空间,用malloc即可
- 防止野指针问题,每次创建的新结点的prev和next指针我们都置空。之后将这个节点的地址返回即可,因为该节点的空间是在堆上的,函数栈帧销毁不会影响这段空间。
按照以上思路,我们可以写出以下函数接口
//创建一个新节点,方便复用
ListNode* BuyNode(int x)
{
ListNode* newNode=(ListNode*)malloc(sizeof(ListNode));
if (newNode == NULL)
{
perror("malloc fail");
return NULL;
}
newNode->data = x;
newNode->next = NULL;
newNode->prev = NULL;
return newNode;
}链表判空
- 和单链表一样,当链表为空了,就不可以再进行删除操作了,因此在后面的删除接口中判空是要用到的,我们还是可以先提前将其封装成一个接口,这样可以提高代码的可读性
- 这里需要运用到bool值,空返回
true;不空返回false

上文创建头结点的时候提到了哨兵位的prev和next指针都指向自己,所以如果链表为空,那么dummyhead->next=dummyhead
根据以上思路我们可以写出以下函数接口
bool ListEmpty(ListNode* pHead)
{
assert(pHead);
return pHead->next == pHead;
}链表打印
- 打印是为了观察以后的各个接口是否正确,比起调试来说更简单直观一些
- 将写的代码可视化了,增加了我们的一点成就感
- 遍历除了dummyhead以外的结点,直到重新指向dummyhead的时候结束
- 自己可以设计一些箭头,看起来更加好看一点
下面为函数接口实现:
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
printf("dummyhead<-> ");
while (cur != pHead)
{
printf("%d <-> ",cur->data);
cur = cur->next;
}
printf("dummyhead ");
}
链表尾插
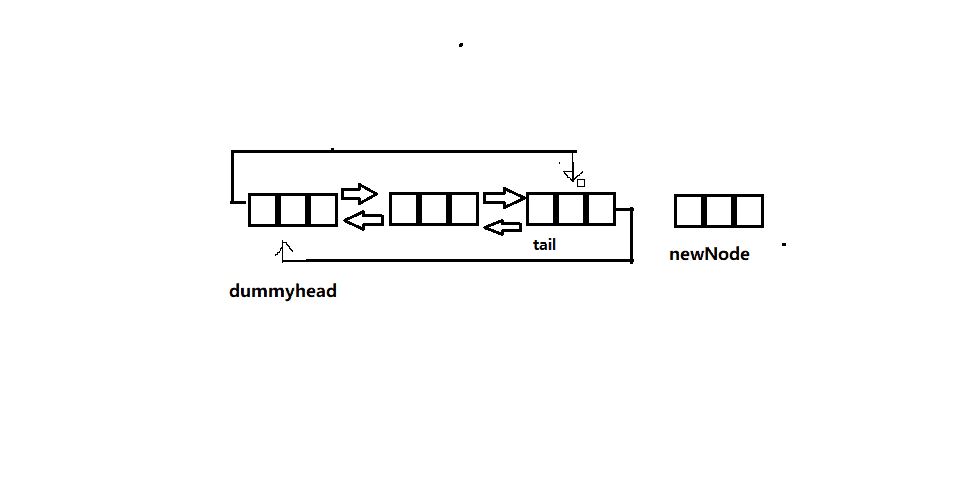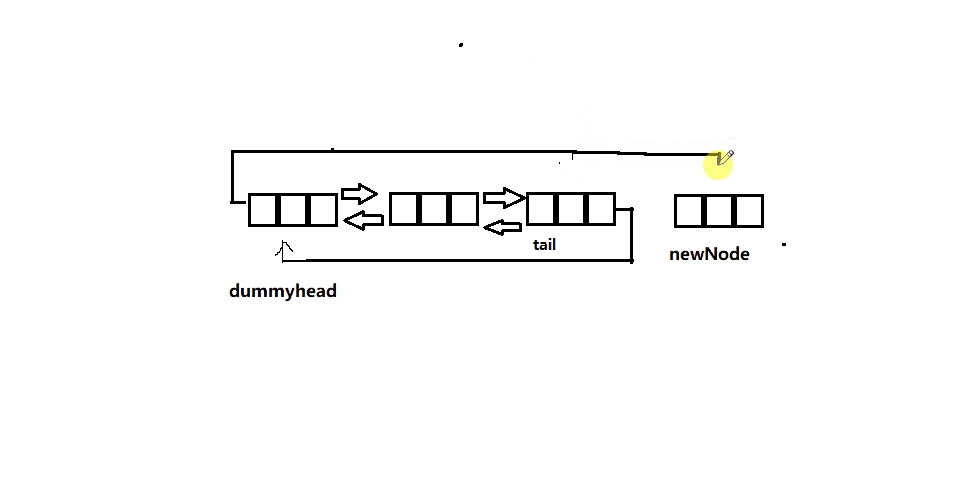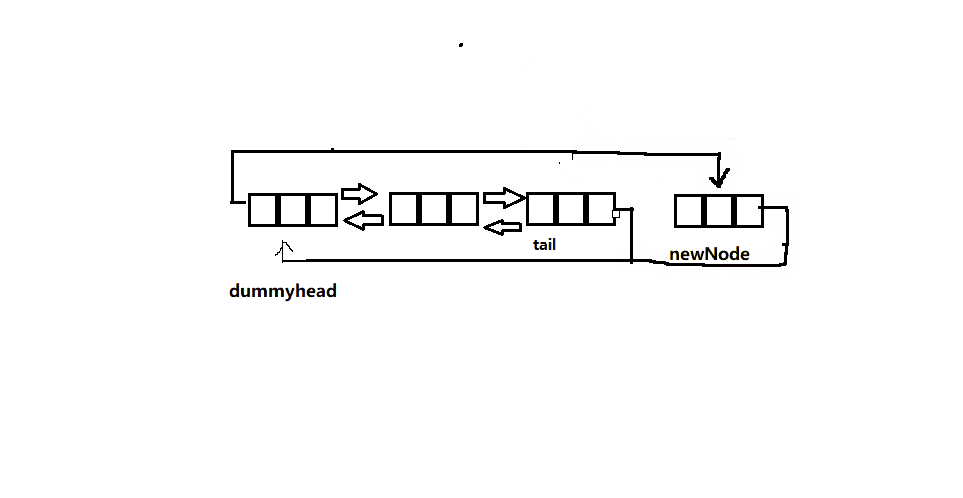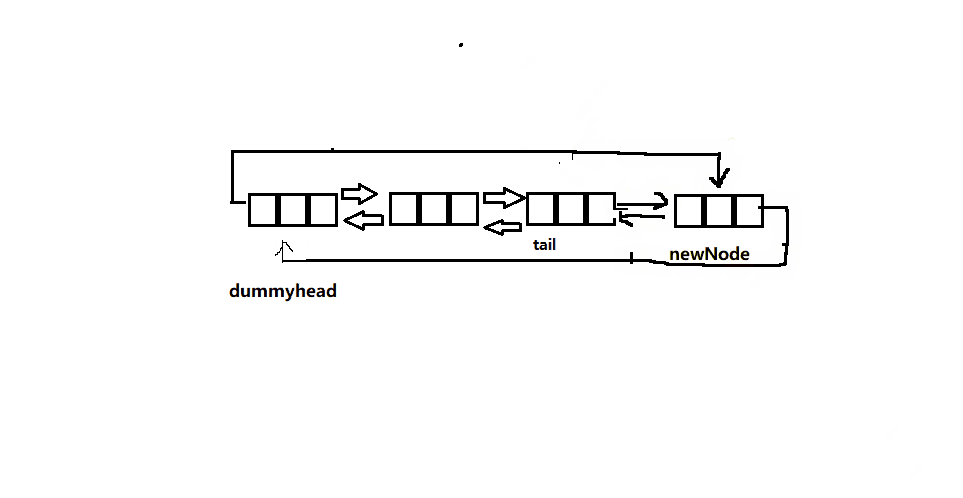
- 单链表中我们要从前往后找到最后一个结点,然后再插入,时间复杂度为O(N)。
- 而双向链表实现起来十分简单,因为哨兵位的前一个结点就是链表的尾了,这样时间复杂度直接降为O(1),效率提升的让人不敢相信。
- 如果此时链表中没有有效的节点,那么此时直接得到一个节点与头节点连接即可,不需要考虑单链表章节是否要更新头指针的情况,这也体现了带头的优处。
下面为函数接口实现:
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newNode=BuyNode(x);
ListNode* tail = pHead->prev;
pHead->prev = newNode;
newNode->next = pHead;
newNode->prev = tail;
tail->next = newNode;
}链表尾删
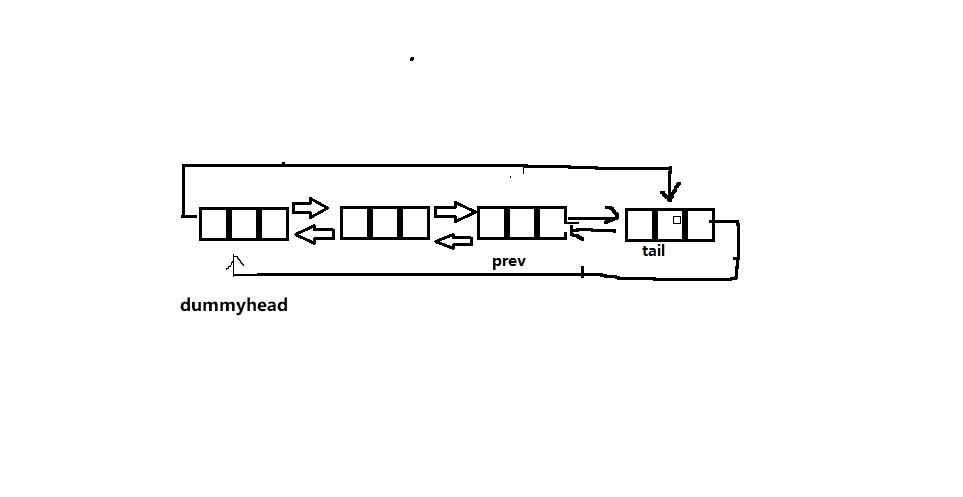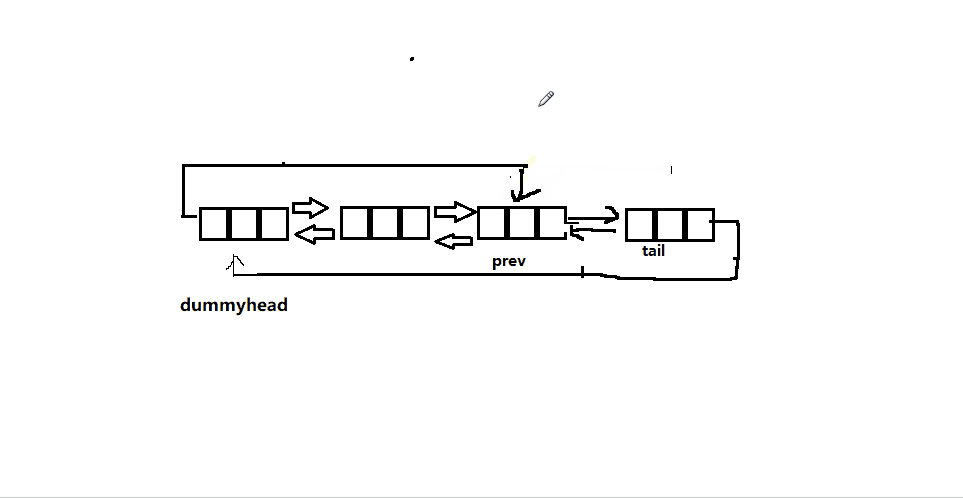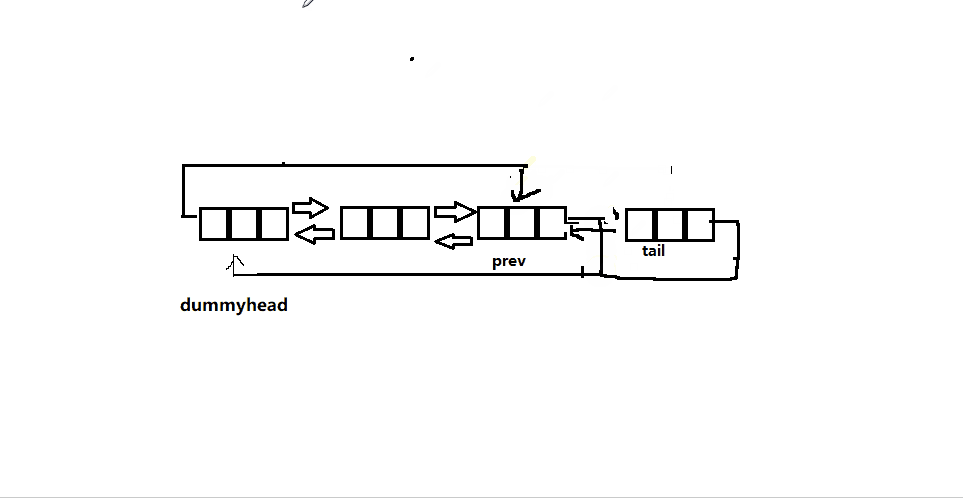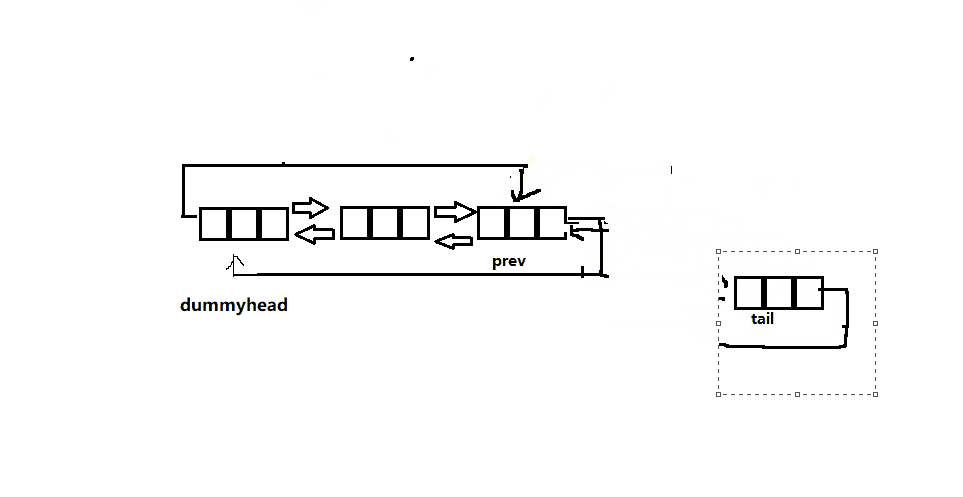
- 尾删就是要删除最后一个结点,所以我们要找到最后一个结点的前一个结点(dummyhead->prev->prev),将其与头结点相连,然后free掉尾结点。
-
如果此时没有节点,这是判空的作用就来了,没有节点当然就是不给删咯,直接
assert断言暴打。 -
即使链表只有一个结点,也没有任何影响,大家可以自己手动画图一下,十分好理解
以下为函数实现接口:
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* tail = pHead->prev;
ListNode* prev = tail->prev;
pHead->prev = prev;
prev->next = pHead;
free(tail);
}链表头插
- 头插,即头结点和新结点相连,再将新结点与原来的头结点相连,这样新结点就成为了新的头结点啦!
- 为了避免改变结点指向后写出错误代码,我们在修改指向前可以先定义几个变量,也增加代码可读性
以下为函数接口实现:
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* head = pHead->next;
ListNode* newNode = BuyNode(x);
pHead->next = newNode;
newNode->prev = pHead;
newNode->next = head;
head->prev = newNode;
}链表头删
- 头删,即将哨兵位的下一个结点删除,将哨兵位和头结点的下一个结点连接起来。
- 依然为了防止将链表指向修改后导致的代码书写错误,我们可以先定义变量记录头结点的下一个指针
- 如果此时没有节点,这是判空的作用就来了,没有节点当然就是不给删咯,直接
assert断言暴打。 - 即使链表只有一个结点,也没有任何影响,大家可以自己手动画图一下,十分好理解
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* head = pHead->next;
ListNode* next = head->next;
pHead->next = next;
next->prev = pHead;
free(head);
}任意插入
- 这里的任意插入,是将你要插入的节点插入到你想要插入的位置的前面。
- 同样的,这里需要传递一个节点的指针(pos)代表你要插入的位置
- 既然是在想插入的位置的前面插入,那么这里就需要存放一下该位置的前一个节点的地址,然后进行连接即可
以下为相关代码的实现:
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* newNode = BuyNode(x);
ListNode* prev = pos->prev;
prev->next = newNode;
newNode->prev = prev;
newNode->next = pos;
pos->prev = newNode;
}任意删除
-
任意删除,是删除
pos位置,这个pos就有序列表是你指定要删除的那个节点的地址。 -
既然是删除
pos位置,就需要存放一下pos的前一个节点的地址和pos的下一个节点的地址,以便于连接。最后释放pos位置的节点即可。
下面为函数接口实现:
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
// 判断pos的有效性
assert(pos);
// 存放pos的下一个节点的地址
ListNode* next = pos->_next;
// 存放pos的前一个节点的地址
ListNode* prev = pos->_prev;
// 删除(释放)pos
free(pos);
// 连接
prev->_next = next;
next->_prev = prev;
}
链表查找
- 查找也就是从头结点往后一个一个看是否与值匹配,找到的话就返回首个匹配的节点位置(也可以自己修改)
- 单链表是到NULL结束循环,而这里则是当指针重新指向dummyhead的时候,意味着所有结点都已经查找完了,此时返回NULL
下面为函数接口实现:
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == x)
return cur;
else cur = cur->next;
}
return NULL;
}链表销毁
- 因为各个结点都是malloc出来的,所以如果不在使用后销毁可能会导致内存泄漏,所以我们要养成良好习惯,即使很多编译器已经很明智了
- 销毁的对象包括dummyhead
- 需要额外记录被销毁的结点的下一个结点
下面为函数接口实现:
// 双向链表销毁
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(pHead);
}总结
至此,常用的接口我们已经实现的差不多了,我们会发现,双向链表正是靠其复杂的结构从而使得代码实现起来非常方便,不得不佩服想出这种结构的人。
相对于单链表,这种带头双向循环链表简直是六边形链表,任何方面都碾压了单链表。
单链表别再来找我了,我怕双向链表误会
以下是完整代码,有需求的小伙伴们可以拿走哦
完整代码
#include"List.h"
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode*dummmyhead=(ListNode*)malloc(sizeof(ListNode));
dummmyhead->next = dummmyhead;
dummmyhead->prev = dummmyhead;
return dummmyhead;
}
//创建一个新节点,方便复用
ListNode* BuyNode(int x)
{
ListNode* newNode=(ListNode*)malloc(sizeof(ListNode));
if (newNode == NULL)
{
perror("malloc fail");
return NULL;
}
newNode->data = x;
newNode->next = NULL;
newNode->prev = NULL;
return newNode;
}
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
printf("dummyhead<-> ");
while (cur != pHead)
{
printf("%d <-> ",cur->data);
cur = cur->next;
}
printf("dummyhead ");
}
//判断链表是否为空
bool ListEmpty(ListNode* pHead)
{
assert(pHead);
return pHead->next == pHead;
}
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newNode=BuyNode(x);
ListNode* tail = pHead->prev;
pHead->prev = newNode;
newNode->next = pHead;
newNode->prev = tail;
tail->next = newNode;
}
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* tail = pHead->prev;
ListNode* prev = tail->prev;
pHead->prev = prev;
prev->next = pHead;
free(tail);
}
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* head = pHead->next;
ListNode* newNode = BuyNode(x);
pHead->next = newNode;
newNode->prev = pHead;
newNode->next = head;
head->prev = newNode;
}
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!ListEmpty(pHead));
ListNode* head = pHead->next;
ListNode* next = head->next;
pHead->next = next;
next->prev = pHead;
free(head);
}
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
if (cur->data == x)
return cur;
else cur = cur->next;
}
return NULL;
}
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* newNode = BuyNode(x);
ListNode* prev = pos->prev;
prev->next = newNode;
newNode->prev = prev;
newNode->next = pos;
pos->prev = newNode;
}
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
}
// 双向链表销毁
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;
while (cur != pHead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(pHead);
}