手把手教你使用YOLOV5训练自己的目标检测模型-水下目标检测
大家好,我是MrRoose,小伙伴后台私信比较多的毕设系列终于来了。我将通过手把手教学系列从零教你如何搭建,训练以及使用训练好的权重来完成不同方向的课题,小伙伴可以跟读我的模型原理系列来边操作边学习其中原理。做到原理和实践相结合。
课题意义-目标检测类
随着人工神经网络的发展,基于深度学习的方法逐浙应用于陆上视觉任务中,该类方法也被逐渐引入探索水下视觉任务中。相对于传统方法,基于深度学习的方法能够提取图像的深层次特征,经过特征映射后再进行理解,提高了图像理解的能力。但此类方法需要使用大里的教据集进行训练,而由于水下环的特殊性,对水下图像采集设备要求高且技术难度大,因此不能够采集大里满足不同水下场景和各种图像质里要求的训练教据,采集到的样本容易出现类别不平衡等问题。这些都给水下环境感知带来较大的困难。
废话不多说,今天就让我带你们用YOLO模型解决此问题。
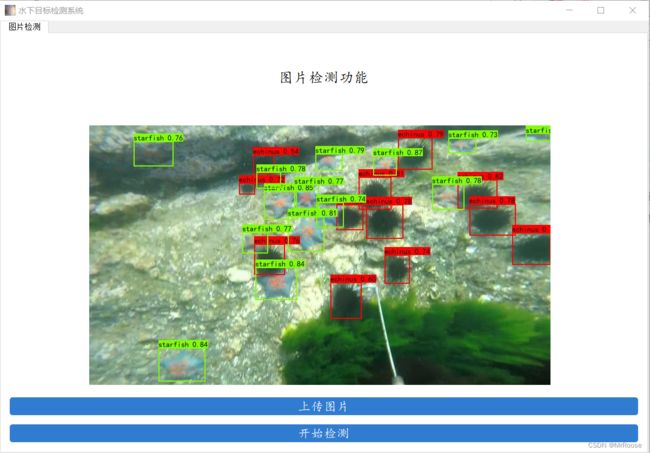
先来看看我们要实现的效果,我们将会通过数据来训练一个水下目标检测的模型,并用pyqt5进行封装,实现图片检测的功能。


配置环境
***如果对Anaconda的操作不了解,可以跟着以下步骤完成后,课余时间查漏补缺。《Anaconda安装+环境管理+包管理+实际演练例子》
(1)pycharm的安装包可以在该网盘内领取网盘地址在这里:提取码1024,安装包内包含教程,根据教程一步一步安装即可。
(2)anaconda的安装根据下面链接即可:《Anaconda安装+环境管理+包管理+实际演练例子》(注意:安装anaconda时可以在除c盘以外的盘创建文件夹后安装。电脑的用户名不要有中文)
(3)anaconda安装完成之后可以切换到国内的源来提高下载速度,
打开Anaconda Prompt,然后在base环境下输入以下代码安装国内的镜像源,命令如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
安装完镜像源可以通过c盘中的.condarc文件来查看,镜像源是否安装成功。(选做)
(4)安装好镜像源后,在base环境下创建名字为pt1.8的虚拟环境,命令如下:
conda create -n pt1.8 python=3.7
(5)创建完名字为pt1.8的虚拟环境后进入到pt1.8环境中,命令如下:
activate pt1.8
(6)然后要开始安装pytorch 1.8.0的环境了,这里面会因为你的显卡的区别稍有不同,但不要担心,一切有我。按照我的步骤来就好了,命令如下:
- gpu版本且显卡不是30系列的命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2`
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly
- gpu版本且显卡是30系列的情况:可以在https://download.pytorch.org/whl/lts/1.8/torch_lts.html网址里下载torch torchvision 和torchaudio版本。
对应关系可以看上面的命令行中的版本对应关系,然后其中文件中的数字的含义可以看以下这篇文章《torch等安装包文件的数字含义》 - cpu版本的命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装完毕之后,我们来测试一下GPU是否安装成功

(7)其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到requirement.txt文件的目录(这个文件在代码包里)下,直接执行下列指令即可完成包的安装。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
(8)虚拟环境创建好后,需要把虚拟环境配置到pycharm中,可参考以下这篇文章进行学习。
《Pycharm中如何配置已有的环境》
训练自己的水下目标检测模型
一、数据集准备
本次使用VOC格式进行训练,训练前需要自己制作好数据集。如果将图片制作成VOC和YOLO格式,可以参考以下这篇文章学习如何使用labelimg制作自己的目标检测数据集《目标检测数据集标注工具Labelimg安装与使用》
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。

训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。

此时数据集的摆放已经结束。
二、数据集的处理
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的2007_train.txt以及2007_val.txt,需要用到根目录下的voc_annotation.py。
voc_annotation.py里面有一些参数需要设置。
分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path
'''
annotation_mode用于指定该文件运行时计算的内容
annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
'''
annotation_mode = 0
'''
必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
与训练和预测所用的classes_path一致即可
如果生成的2007_train.txt里面没有目标信息
那么就是因为classes没有设定正确
仅在annotation_mode为0和2的时候有效
'''
classes_path = 'model_data/voc_classes.txt'
'''
trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
仅在annotation_mode为0和1的时候有效
'''
trainval_percent = 0.9
train_percent = 0.9
'''
指向VOC数据集所在的文件夹
默认指向根目录下的VOC数据集
'''
VOCdevkit_path = 'VOCdevkit'
classes_path用于指向检测类别所对应的txt,我们用的txt名为voc_classes.txt,txt中的内容如下:

三、开始网络训练
通过voc_annotation.py我们已经生成了2007_train.txt以及2007_val.txt,此时我们可以开始训练了。
训练的参数较多,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的classes_path。
classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样!训练自己的数据集必须要修改!
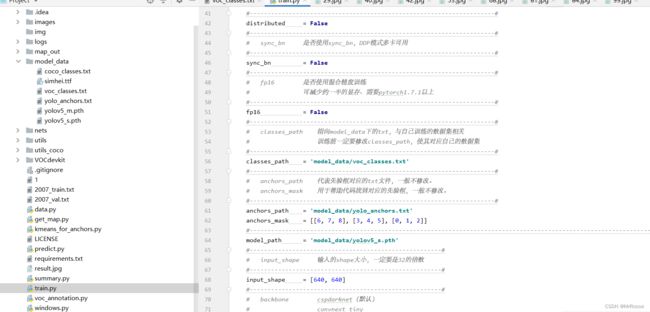 修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
其它参数的作用如下:
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
Cuda = True
#--------------------------------------------------------#
# 训练前一定要修改classes_path,使其对应自己的数据集
#--------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#---------------------------------------------------------------------#
# anchors_path代表先验框对应的txt文件,一般不修改。
# anchors_mask用于帮助代码找到对应的先验框,一般不修改。
#---------------------------------------------------------------------#
anchors_path = 'model_data/yolo_anchors.txt'
anchors_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
#----------------------------------------------------------------------------------------------------------------------------#
# 模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的。
# 如果想要让模型从0开始训练,则设置model_path = '',下面的Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
# 一般来讲,从0开始训练效果会很差,因为权值太过随机,特征提取效果不明显。
#
# 网络一般不从0开始训练,至少会使用主干部分的权值,有些论文提到可以不用预训练,主要原因是他们 数据集较大 且 调参能力优秀。
# 如果一定要训练网络的主干部分,可以了解imagenet数据集,首先训练分类模型,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = 'model_data/yolov5_s.pth'
#------------------------------------------------------#
# 输入的shape大小,一定要是32的倍数
#------------------------------------------------------#
input_shape = [640, 640]
#------------------------------------------------------#
# 所使用的YoloV5的版本。s、m、l、x
#------------------------------------------------------#
phi = 's'
#------------------------------------------------------#
# Yolov4的tricks应用
# mosaic 马赛克数据增强 True or False
# 实际测试时mosaic数据增强并不稳定,所以默认为False
# Cosine_lr 余弦退火学习率 True or False
# label_smoothing 标签平滑 0.01以下一般 如0.01、0.005
#------------------------------------------------------#
mosaic = False
Cosine_lr = False
label_smoothing = 0
#----------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。
# 显存不足与数据集大小无关,提示显存不足请调小batch_size。
# 受到BatchNorm层影响,batch_size最小为2,不能为1。
#----------------------------------------------------#
#----------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
#----------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 16
Freeze_lr = 1e-3
#----------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
#----------------------------------------------------#
UnFreeze_Epoch = 100
Unfreeze_batch_size = 8
Unfreeze_lr = 1e-4
#------------------------------------------------------#
# 是否进行冻结训练,默认先冻结主干训练后解冻训练。
#------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------#
# 用于设置是否使用多线程读取数据
# 开启后会加快数据读取速度,但是会占用更多内存
# 内存较小的电脑可以设置为2或者0
#------------------------------------------------------#
num_workers = 4
#----------------------------------------------------#
# 获得图片路径和标签
#----------------------------------------------------#
train_annotation_path = '2007_train.txt'
val_annotation_path = '2007_val.txt'
四、训练结果预测
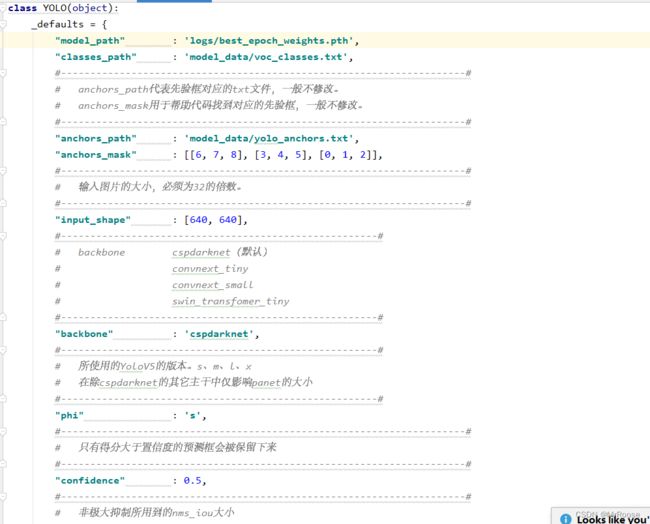
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。
我们首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
修改完就可以点击predict.py进行水下目标检测了,也可以通过运行windows.py打开ui界面,选择好图片后开始检测了。
五、模型评估
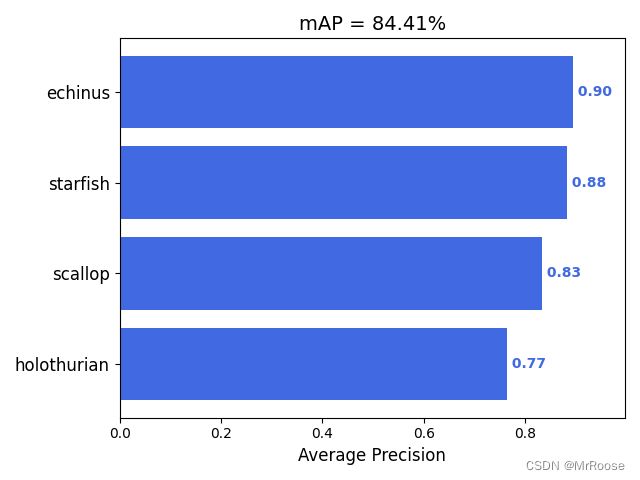
除了在博客一开头你就能看到的检测效果之外,还有一些学术上的评价指标用来表示我们模型的性能,其中目标检测最常用的评价指标是mAP,mAP是介于0到1之间的一个数字,这个数字越接近于1,就表示你的模型的性能更好。
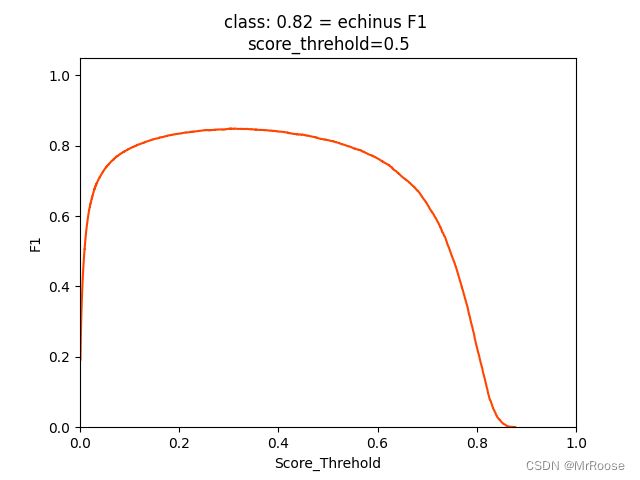
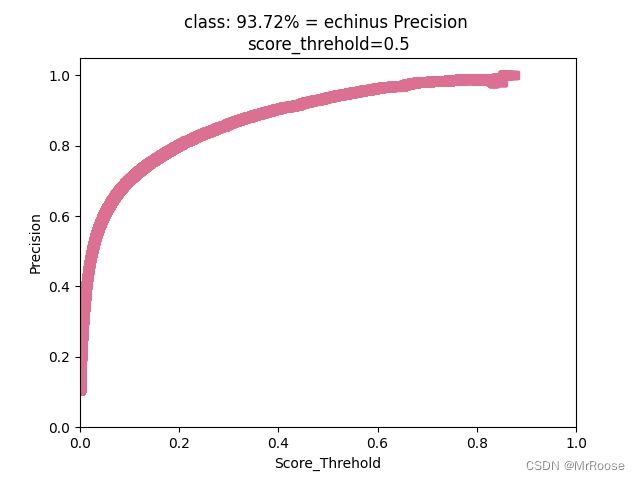
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值,以本文为例,我们可以计算echinus和starfish和scallop和holothurian这四个目标的mAP值,该值越接近1表示模型的性能越好。
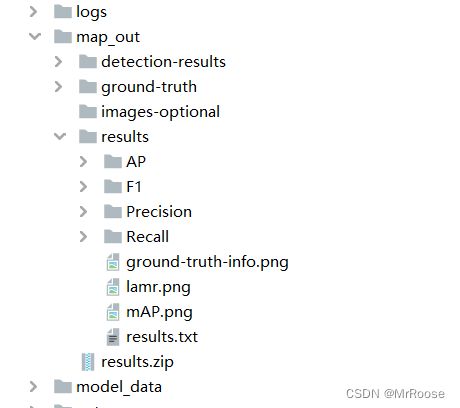
关于更加学术的定义大家可以在知乎或者csdn上自行查阅,以我们本次训练的模型为例,在模型结束之后你会找到三张图像,分别表示我们模型在验证集上的召回率、准确率和均值平均密度。
六、构建可视化界面
可视化界面的部分在windows.py文件中,是通过pyqt5完成的界面设计,在启动界面前,你需要在yolo.py文件中将模型替换成你训练好的模型,替换的位置在model_path那里和前面的操作一样,修改成你的模型地址即可,如果你有GPU的话,可以将device设置为0,表示使用第0行GPU,这样可以加快模型的识别速度嗷。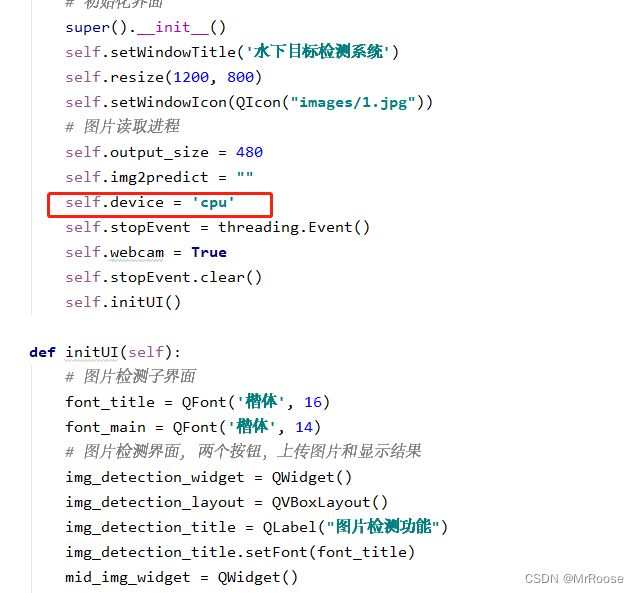
然后直接run就可以了。
