DETR的位置编码
记录一下,以防忘记。
首先,致谢知乎vincent DETR论文详解
DETR中有这样一个类和一个包装函数
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
def to(self, device):
# type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)假如batch_size=2,有两张图片分别为
im0 = torch.rand(3,200,200)
im1 = torch.rand(3,200,250)我们使用 nested_tensor_from_tensor_list 函数将它们打包在一块,这里调用了NestedTensor类,它的作用就是构成 {tensor, mask} 这么一个数据结构,在这里,tensor就是图片的值,那mask是啥?
当一个batch中的图片大小不一样的时候,我们要把它们处理的整齐,简单说就是把图片都padding成最大的尺寸,padding的方式就是补零,那么batch中的每一张图都有一个mask矩阵,所以mask大小为(2, 200, 250), tensor大小为(2, 3, 200, 250)。

DETR - Backbone
从DETR的角度来看,当我们用resnet50提取特征得到特征维度为 (2, 1024, 24, 32),这里输出的的mask的维度为 (2, 24, 32),mask使用F.interpolate得到。
DETR - Position Encoding
首先,DETR官方源码中包括了正弦位置编码和可学习位置编码,我们这次讲下正弦位置编码。首先,Transformer带有位置信息的特征是通过 Feature Embedding + Position Embedding 相加得到的,至于为什么相加,请看这篇博文 为什么Transformer / ViT 中的Position Encoding能和Feature Embedding直接相加?
在DETR中,位置编码构造方法与Transformer原文中的位置编码一致。
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors #(2,1024, 24,32)
mask = tensor_list.mask #(2, 24,32)
assert mask is not None
not_mask = ~mask #就是有像素值得位置
y_embed = not_mask.cumsum(1, dtype=torch.float32) #沿y方向累加,(1,1,1)--(1,2,3)
# (1,1,1,...) #y_embed
# (2,2,2,...)
# (3,3,3,...)
# (...)
x_embed = not_mask.cumsum(2, dtype=torch.float32) #沿x方向累加,(1,1,1).T--(1,2,3).T
# (1,2,3,...) #x_embed
# (1,2,3,...)
# (1,2,3,...)
# (...)
if self.normalize: #进行归一化
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale #(2,24,32)
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale #(2,24,32)
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
# self.num_pos_feats=128,
# dim_t = [1,2,3,4,...,128]
# 以下按上述公式计算
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t #(2,24,32,128)
pos_y = y_embed[:, :, :, None] / dim_t #(2,24,32,128)
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos #(2,256, 24,32)位置编码(positional encoding),最直观方式是将第一个pixel赋予1,第二个pixel赋予2,以此类推,但当pixel序列足够大时,会造成位置嵌入(positional embedding)的值过大,所以采用正弦曲线把值控制在-1到1之间,但由于正弦曲线的周期性,可能会造成不同位置值相同的情况。
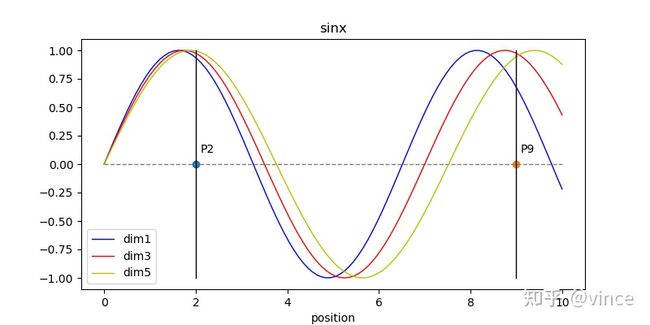
因此,作者将positional embedding 扩充为一个d维的向量,这个向量用来为每个pixel提供位置信息,再和该位置的pixel embedding相加,增强模型输入,至于引用d维正弦函数的作用大致是控制不同通道位置编码的波长,波长随d由小到大。以下是positional encoding过程的举例。
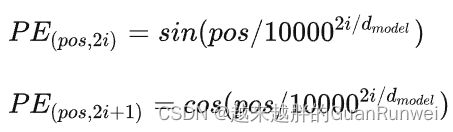
下图为不同维度对应的正弦曲线,可以看到随d越大,正弦曲线的波长越大,这样做的原因是,如果每个Position只对应一个正弦曲线,那么由于正弦曲线的周期性,P2,P9(不同的位置点)可能计算出相同值。而采用每个位置对应多个维度,即多个不同波长的正弦曲线,任何两位置由d维向量表示,就不会发生位置不同,值相同的情况。
另外positional embedding的周期有 2� 到10000 ∗2� 变化,而每个位置在embedding demension上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,最终使模型学到位置之间的依赖关系和自然语言的时序特征(Pixel的时序特征)。
DETR论文中引入attention机制使用的模块是transformer,第一步先要将feature map投射变换成Q,K,V,Q可以理解为语义空间向量投射变维的输出,K可以理解为字典,V为字典对应的输出,通过Q与K点乘(典型的attention操作)得到V的加权系数,然后对V加权求和,最后经过一个前向网络输出类别和坐标预测,transformer丢失位置信息,所以又添加了一个位置编码(Position Enconding),所谓PE是根据目标的位置坐标,将位置坐标转换为固定维度的编码,转换方式是将位置坐标代入不同波长的三角函数里,三角函数天生具有描述相对位置的作用,而之所以要使用不同波长的三角函数进行计算而不是单波长,是为了描述相对位置同时保存绝对位置,因为波长过小,位置较远的像素将超出同一个周期导致绝对位置丢失,所以大家可以粗略的理解为,小波长精确描述距离较近的相对位置,大波长描述距离较远绝对位置。