[力扣刷题总结](递归和回溯篇)
文章目录
- ~~~~~~~~~~~~递归~~~~~~~~~~~~
-
- 一.递归和迭代的区别
- 21. 合并两个有序链表
-
- 解法1:递归
- 解法2:迭代
- 263. 丑数
-
- 解法1:迭代
- 解法2:递归
- 相似题目:264. 丑数 II
-
- 解法1:优先队列
- 解法2:动态规划
- ~~~~~~~~~~~~回溯~~~~~~~~~~~~
-
- 一. 什么是回溯法
- 二.回溯法的效率
- 三.回溯法解决的问题
- 四.回溯法模板
- 五.总结
- \\\\\\\\ ~~回溯:组合问题~~ \\\\\\\\
-
- 组合问题的去重
- 77. 组合
-
- 解法1:回溯
- 解法2:回溯+剪枝
- 39. 组合总和
-
- 解法1:回溯
- 解法2:剪枝优化
- 40. 组合总和 II
-
- 解法1:回溯
- 22. 括号生成
-
- 解法1:回溯
- \\\\\\\\ ~~回溯:分割问题~~ \\\\\\\\
- 131. 分割回文串
-
- 解法1:回溯
- 解法2:回溯+动态规划优化
- 相似题目:132. 分割回文串 II
-
- 解法1:动态规划
- 93. 复原 IP 地址
-
- 解法1:回溯
- 相关题目:468. 验证IP地址
-
- 解法1:字符串
- 306. 累加数
-
- 解法1:回溯+字符串
- 698. 划分为k个相等的子集
-
- 解法1:回溯
- 相似题目:473. 火柴拼正方形
-
- 解法1:回溯
- 相似题目: 416. 分割等和子集
-
- 解法1:动态规划
- 解法2:优化动态规划
- \\\\\\\\ ~~回溯:子集问题~~ \\\\\\\\
- 78. 子集
-
- 解法1:回溯
- 90. 子集 II
-
- 解法1:回溯
- 491. 递增子序列
-
- 解法1:回溯
- \\\\\\\\ ~~回溯:排列问题~~ \\\\\\\\
- 相关题目:31. 下一个排列
-
- 解法1:双指针
- 相关题目:60. 排列序列
-
- 解法1:双指针
- 46. 全排列
-
- 解法1:回溯
- 47. 全排列 II
-
- 解法1:回溯
- \\\\\\\\ ~~回溯:棋盘问题~~ \\\\\\\\
- 51. N 皇后
-
- 解法1:回溯
- 解法2:基于位运算的回溯
- 相似题目:52. N皇后 II
-
- 解法1:回溯
- 解法2:位运算+回溯
- 37. 解数独
-
- 解法1:回溯法
- \\\\\\\\ ~~回溯:其他~~ \\\\\\\\
- 95. 不同的二叉搜索树 II
-
- 解法1:回溯+二叉搜索树
- 相似题目:241. 为运算表达式设计优先级
-
- 解法1:回溯+分治
递归
一.递归和迭代的区别
本小节主要参考深入浅出迭代和递归
1.定义:
递归
是指函数、过程、子程序在运行过程序中直接或间接调用自身而产生的重入现像。在计算机编程里,递归指的是一个程:函数不断引用自身,直到引用的对象已知。
迭代
重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
2.理解:
_第1张图片](http://img.e-com-net.com/image/info8/f7e96c52d8f549d8b09841828e7babd1.jpg)
递归:
从问题开始出发,也就是从最顶层开始,逐层深入到最简单的问题(最底层的解决方法),得到答案, 如果完成则提交,如果未完成,再次返回上一层,用最底层解决上层,然后逐层返回到最顶层的问题。
它关注现在的状态,以及以前的状态, 不知晓它未来的状态是否走向何处, 但是它必定要返回以前的状态。
本质是自己调用自己去完成自己的问题,但是自己要给自己一个出口,否则自己一直在自己的世界里活着,那就是自闭了。
迭代:
先从最简单的开始,形成一个答案之后,比较是否已经完全迭代完要求,如果没有,继续迭代,直到找到解决方案。在这个过程中,存在用新的解决方法覆盖旧的解决方案,直接覆盖也就是只关注目前的状态,不会去返回、影响以前或者未来的状态。它只产生目前的结果,直到迭代结束返回最终结果。
本质就是以新代旧,用最新的结果当做目前的解决方案或者解决方法,不断的覆盖掉以前的方法,直到满足结果为止,所以它也要有出口。
3.总结:
二者之间的差别就是自己调用自己和以新代旧,也可以说这不算是差别,因为根本搭不到一块,在,二者的主体概念考虑已经不在一个领域内,但是二者也存在部分的交集,都是为了寻找出口,拿到解决方案。
递归:自己调用自己,层层递进寻找出口,出口未必是解决方案。
迭代:以新代旧,出口一定是解决方案。
21. 合并两个有序链表
力扣链接
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
_第2张图片](http://img.e-com-net.com/image/info8/559e387b867a4687b84c6aee8072a705.jpg)
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
解法1:递归
思路:
这个问题之前给人家形象的比喻讲解过。
你拿两串珠子,分别按照题意标上有序递增的数字
另外你再拿一根线,把这两串珠子合并成一串,这时候你会怎么做呢?
当然是两个原串头上挑小的串起来呀!哪个小串哪个,另外一串没有了就整个串上就完了
_第3张图片](http://img.e-com-net.com/image/info8/0a3b7d91ee874de884e3b37d06c368e4.jpg)
_第4张图片](http://img.e-com-net.com/image/info8/335a549b528f483ca3108a3e95baa467.jpg)
_第5张图片](http://img.e-com-net.com/image/info8/dcff502236f740bb81b93618142a93fe.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//递归
if(list1 == nullptr) return list2;
else if(list2 == nullptr) return list1;
else if(list1->val < list2->val){
list1->next = mergeTwoLists(list1->next,list2);
return list1;
}else{
list2->next = mergeTwoLists(list1,list2->next);
return list2;
}
}
};
复杂度分析:

时间复杂度:O(n + m),其中 n 和 m 分别为两个链表的长度。因为每次调用递归都会去掉 l1 或者 l2 的头节点(直到至少有一个链表为空),函数 mergeTwoList 至多只会递归调用每个节点一次。因此,时间复杂度取决于合并后的链表长度,即 O(n+m)。
空间复杂度:O(n + m),其中 n 和 m 分别为两个链表的长度。递归调用 mergeTwoLists 函数时需要消耗栈空间,栈空间的大小取决于递归调用的深度。结束递归调用时 mergeTwoLists 函数最多调用 n+m 次,因此空间复杂度为 O(n+m)。对于递归调用 self.mergeTwoLists(),当它遇到终止条件准备回溯时,已经递归调用了 m+n次,使用了 m+n个栈帧,故最后的空间复杂度为 O(m + n)。
解法2:迭代
思路:
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//迭代
ListNode* head = new ListNode;
ListNode* pre = head;
while(list1 != nullptr && list2 != nullptr){
if(list1->val < list2->val){
pre->next = list1;
list1 = list1->next;
}else{
pre->next = list2;
list2 = list2->next;
}
pre = pre->next;
}
pre->next = (list1 == nullptr ? list2 : list1);
return head->next;
}
};
复杂度分析:
时间复杂度:O(n + m),其中 n 和 m 分别为两个链表的长度。因为每次循环迭代中,l1 和 l2 只有一个元素会被放进合并链表中, 因此 while 循环的次数不会超过两个链表的长度之和。所有其他操作的时间复杂度都是常数级别的,因此总的时间复杂度为 O(n+m)。
空间复杂度:O(1)。我们只需要常数的空间存放若干变量。
263. 丑数
力扣链接
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
输入:n = 6
输出:true
解释:6 = 2 × 3
示例 2:
输入:n = 8
输出:true
解释:8 = 2 × 2 × 2
示例 3:
输入:n = 14
输出:false
解释:14 不是丑数,因为它包含了另外一个质因数 7 。
示例 4:
输入:n = 1
输出:true
解释:1 通常被视为丑数。
提示:
-231 <= n <= 231 - 1
解法1:迭代
class Solution {
public:
bool isUgly(int n) {
//迭代
vector<int> a = {2,3,5};
for(auto& aa:a){
while(n % aa == 0 && n>0){
n /= aa;
}
}
return n == 1;
}
};
解法2:递归
class Solution {
public:
bool isUgly(int n) {
//递归
if(n == 0) return false;
if(n == 1) return true;
if(n % 2 == 0) return isUgly(n/2);
if(n % 3 == 0) return isUgly(n/3);
if(n % 5 == 0) return isUgly(n/5);
return false;
}
};
相似题目:264. 丑数 II
力扣链接
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
输入:n = 10
输出:12
解释:[1, 2, 3, 4, 5, 6, 8, 9, 10, 12] 是由前 10 个丑数组成的序列。
示例 2:
输入:n = 1
输出:1
解释:1 通常被视为丑数。
提示:
1 <= n <= 1690
解法1:优先队列
_第6张图片](http://img.e-com-net.com/image/info8/2293bd52b1f242a49754b124d705bcc8.jpg)
思路:
利用优先队列有自动排序的功能
每次取出队头元素,存入队头元素2、队头元素3、队头元素*5
但注意,像 12 这个元素,可由 4 乘 3 得到,也可由 6 乘 2 得到,所以要注意去重。采用 set 来识别有无重复
代码:
class Solution {
public:
int nthUglyNumber(int n) {
//小根堆
priority_queue<long,vector<long>,greater<long>> heap;
vector<int> a = {2,3,5};
unordered_set<long> uset;
uset.insert(1);
heap.push(1);
for(int i = 1;i<=n;i++){
long x = heap.top();
heap.pop();
if (i == n) return x;
for(int aa:a){
long t = aa*x;
if(!uset.count(t)){
uset.insert(t);
heap.push(t);
}
}
}
return -1;
}
};
_第7张图片](http://img.e-com-net.com/image/info8/9599e7254f2e4864bb1f5023398b83a6.jpg)
解法2:动态规划
思路:
_第8张图片](http://img.e-com-net.com/image/info8/779702a107d64b87bca9344e48823318.jpg)
代码:
class Solution {
public:
int nthUglyNumber(int n) {
//动态规划
int p2 = 1,p3 = 1, p5 =1;
vector<int> dp(n+1);
dp[1] = 1;
for(int i =2;i<=n;i++){
int num2 = dp[p2]*2, num3 = dp[p3]*3, num5 = dp[p5]*5;
dp[i] = min(num2,min(num3,num5));
if(dp[i] == num2) p2++;
if(dp[i] == num3) p3++;
if(dp[i] == num5) p5++;
}
return dp[n];
}
};
复杂度分析:
时间复杂度:O(n)。需要计算数组dp 中的 n 个元素,每个元素的计算都可以在 O(1) 的时间内完成。
空间复杂度:O(n)。空间复杂度主要取决于数组dp 的大小。
回溯
本小节主要参考代码随想录
一. 什么是回溯法
(1)回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
(2)回溯是递归的副产品,只要有递归就会有回溯。 所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。
_第9张图片](http://img.e-com-net.com/image/info8/3fd346c7abd84cfe8eea66a6936b81d6.jpg)
二.回溯法的效率
(1)回溯法的性能如何呢,这里要和大家说清楚了,虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法。因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
(2)那么既然回溯法并不高效为什么还要用它呢?因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。此时大家应该好奇了,都什么问题,这么牛逼,只能暴力搜索。
三.回溯法解决的问题
(1)回溯法,一般可以解决如下几种问题:
组合问题:N个数里面按一定规则找出k个数的集合
切割问题:一个字符串按一定规则有几种切割方式
子集问题:一个N个数的集合里有多少符合条件的子集
排列问题:N个数按一定规则全排列,有几种排列方式
棋盘问题:N皇后,解数独等等
相信大家看着这些之后会发现,每个问题,都不简单!
(2)另外,会有一些同学可能分不清什么是组合,什么是排列?
组合是不强调元素顺序的,排列是强调元素顺序。
例如:{1, 2} 和 {2, 1} 在组合上,就是一个集合,因为不强调顺序,而要是排列的话,{1, 2} 和 {2, 1} 就是两个集合了。记住组合无序,排列有序,就可以了。
四.回溯法模板
这里给出Carl总结的回溯算法模板。在讲二叉树的递归 (opens new window)中说了递归三部曲,这里列出回溯三部曲。
(1)回溯函数模板返回值以及参数
在回溯算法中,习惯是函数起名字为backtracking,这个起名大家随意。
回溯算法中函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
回溯函数伪代码如下:
void backtracking(参数)
(2)回溯函数终止条件
既然是树形结构,那么我们在讲解二叉树的递归 (opens new window)的时候,就知道遍历树形结构一定要有终止条件。
所以回溯也有要终止条件。
什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
所以回溯函数终止条件伪代码如下:
if (终止条件) {
存放结果;
return;
}
(3)回溯搜索的遍历过程
在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
_第10张图片](http://img.e-com-net.com/image/info8/6d8901ac6a6d4d5ba543af1f9b17eb4f.jpg)
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
这份模板很重要,后面做回溯法的题目都靠它了!
五.总结
本篇讲解了什么是回溯算法,知道了回溯和递归是相辅相成的。
接着提到了回溯法的效率,回溯法其实就是暴力查找,并不是什么高效的算法。
然后列出了回溯法可以解决几类问题,可以看出每一类问题都不简单。
最后讲到回溯法解决的问题都可以抽象为树形结构(N叉树),并给出了回溯法的模板。
\\\\ 回溯:组合问题 \\\\
组合问题的去重
要去重的是“同一树层上的使用过”而不是“同一树支上的使用过”
(1)给定一个无重复元素的正整数数组
去重:设置startIndex即可
(2)给定一个有重复元素的正整数数组
方法1:used数组
首先把给candidates排序,让其相同的元素都挨在一起。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。 此时for循环里就应该做continue的操作。
图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
used[i - 1] == true,说明同一树支candidates[i - 1]使用过
used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
continue;
}
方法2:直接用startIndex来去重也是可以的, 就不用used数组了
首先把给candidates排序,让其相同的元素都挨在一起。
if (i > startIndex && candidates[i] == candidates[i - 1]) {
continue;
}
77. 组合
力扣链接
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入:n = 1, k = 1
输出:[[1]]
提示:
1 <= n <= 20
1 <= k <= n
解法1:回溯
思路:
(1)本题这是回溯法的经典题目。直接的解法当然是使用for循环,例如示例中k为2,很容易想到 用两个for循环,这样就可以输出 和示例中一样的结果。
代码如下:
int n = 4;
for (int i = 1; i <= n; i++) {
for (int j = i + 1; j <= n; j++) {
cout << i << " " << j << endl;
}
}
输入:n = 100, k = 3 那么就三层for循环,代码如下:
int n = 100;
for (int i = 1; i <= n; i++) {
for (int j = i + 1; j <= n; j++) {
for (int u = j + 1; u <= n; n++) {
cout << i << " " << j << " " << u << endl;
}
}
}
如果n为100,k为50呢,那就50层for循环,是不是开始窒息。此时就会发现虽然想暴力搜索,但是用for循环嵌套连暴力都写不出来!
咋整?
(2)回溯搜索法来了,虽然回溯法也是暴力,但至少能写出来,不像for循环嵌套k层让人绝望。那么回溯法怎么暴力搜呢?
上面我们说了要解决 n为100,k为50的情况,暴力写法需要嵌套50层for循环,那么回溯法就用递归来解决嵌套层数的问题。 递归来做层叠嵌套(可以理解是开k层for循环),每一次的递归中嵌套一个for循环,那么递归就可以用于解决多层嵌套循环的问题了。
此时递归的层数大家应该知道了,例如:n为100,k为50的情况下,就是递归50层。
一些同学本来对递归就懵,回溯法中递归还要嵌套for循环,可能就直接晕倒了!
如果脑洞模拟回溯搜索的过程,绝对可以让人窒息,所以需要抽象图形结构来进一步理解。
我们在关于回溯算法,你该了解这些! (opens new window)中说道回溯法解决的问题都可以抽象为树形结构(N叉树),用树形结构来理解回溯就容易多了。
那么我把组合问题抽象为如下树形结构:
_第11张图片](http://img.e-com-net.com/image/info8/058faf9284b84411bfdc2b03f2f321b2.jpg)
可以看出这个棵树,一开始集合是 1,2,3,4, **从左向右取数,取过的数,不在重复取。**第一次取1,集合变为2,3,4 ,因为k为2,我们只需要再取一个数就可以了,分别取2,3,4,得到集合[1,2] [1,3] [1,4],以此类推。
每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围。 图中可以发现n相当于树的宽度,k相当于树的深度。
那么如何在这个树上遍历,然后收集到我们要的结果集呢?图中每次搜索到了叶子节点,我们就找到了一个结果。相当于只需要把达到叶子节点的结果收集起来,就可以求得 n个数中k个数的组合集合。
回溯法三部曲:
(1)递归函数的返回值以及参数
在这里要定义两个全局变量,一个用来存放符合条件单一结果,一个用来存放符合条件结果的集合。
代码如下:
vector> result; // 存放符合条件结果的集合
vector path; // 用来存放符合条件结果
其实不定义这两个全局遍历也是可以的,把这两个变量放进递归函数的参数里,但函数里参数太多影响可读性,所以我定义全局变量了。
函数里一定有两个参数,既然是集合n里面取k的数,那么n和k是两个int型的参数。然后还需要一个参数,为int型变量startIndex,这个参数用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,…,n] )。为什么要有这个startIndex呢?
每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围,就是要靠startIndex。 从下图中红线部分可以看出,在集合[1,2,3,4]取1之后,下一层递归,就要在[2,3,4]中取数了,那么下一层递归如何知道从[2,3,4]中取数呢,靠的就是startIndex。
_第12张图片](http://img.e-com-net.com/image/info8/e1ac8b5d4d364e9fa431d99086be787a.jpg)
所以需要startIndex来记录下一层递归,搜索的起始位置。
那么整体代码如下:
vector> result; // 存放符合条件结果的集合
vector path; // 用来存放符合条件单一结果
void backtracking(int n, int k, int startIndex)
(2)回溯函数终止条件
什么时候到达所谓的叶子节点了呢?path这个数组的大小如果达到k,说明我们找到了一个子集大小为k的组合了,在图中path存的就是根节点到叶子节点的路径。
如图红色部分:
_第13张图片](http://img.e-com-net.com/image/info8/19e3d0be85a94838bad1625f47d22ecd.jpg)
此时用result二维数组,把path保存起来,并终止本层递归。
所以终止条件代码如下:
if (path.size() == k) {
result.push_back(path);
return;
}
(3)单层搜索的过程
回溯法的搜索过程就是一个树型结构的遍历过程,在如下图中,可以看出for循环用来横向遍历,递归的过程是纵向遍历。
_第14张图片](http://img.e-com-net.com/image/info8/8bebb6788fd54d33ad0b0c47ebf0d16f.jpg)
如此我们才遍历完图中的这棵树。for循环每次从startIndex开始遍历,然后用path保存取到的节点i。
代码如下:
for (int i = startIndex; i <= n; i++) { // 控制树的横向遍历
path.push_back(i); // 处理节点
backtracking(n, k, i + 1); // 递归:控制树的纵向遍历,注意下一层搜索要从i+1开始
path.pop_back(); // 回溯,撤销处理的节点
}
可以看出backtracking(递归函数)通过不断调用自己一直往深处遍历,总会遇到叶子节点,遇到了叶子节点就要返回。backtracking的下面部分就是回溯的操作了,撤销本次处理的结果。
代码:
class Solution {
private:
vector<vector<int>> result; // 存放符合条件结果的集合
vector<int> path; // 用来存放符合条件结果
void backtracking(int n, int k, int startIndex) {
if (path.size() == k) {
result.push_back(path);
return;
}
for (int i = startIndex; i <= n; i++) {
path.push_back(i); // 处理节点
backtracking(n, k, i + 1); // 递归
path.pop_back(); // 回溯,撤销处理的节点
}
}
public:
vector<vector<int>> combine(int n, int k) {
result.clear(); // 可以不写
path.clear(); // 可以不写
backtracking(n, k, 1);
return result;
}
};
回溯法模板:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
_第15张图片](http://img.e-com-net.com/image/info8/3dd7d02f032848038f66d18444d23e78.jpg)
解法2:回溯+剪枝
思路:
(1)我们说过,回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的。
在遍历的过程中有如下代码:
for (int i = startIndex; i <= n; i++) {
path.push_back(i);
backtracking(n, k, i + 1);
path.pop_back();
}
这个遍历的范围是可以剪枝优化的,怎么优化呢?来举一个例子,n = 4,k = 4的话,那么第一层for循环的时候,从元素2开始的遍历都没有意义了。 在第二层for循环,从元素3开始的遍历都没有意义了。
这么说有点抽象,如图所示:
_第16张图片](http://img.e-com-net.com/image/info8/500384aec9804051ab57f9e28613498d.jpg)
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置。如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。
注意代码中i,就是for循环里选择的起始位置。
for (int i = startIndex; i <= n; i++) {
(3)接下来看一下优化过程如下:
已经选择的元素个数:path.size();
还需要的元素个数为: k - path.size();
在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
_第17张图片](http://img.e-com-net.com/image/info8/d9c629d674884af591affd11976aa5a9.jpg)
所以优化之后的for循环是:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
public:
void backtracking(int n, int k, int startIndex){
//终止条件
if (path.size() == k){
result.push_back(path);
return;
}
for(int i = startIndex;i<=n-(k-path.size())+1;i++){
path.push_back(i);
backtracking(n,k,i+1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
backtracking(n,k,1);
return result;
}
};
39. 组合总和
力扣链接
给定一个无重复元素的正整数数组 candidates 和一个正整数 target ,找出 candidates 中所有可以使数字和为目标数 target 的唯一组合。
candidates 中的数字可以无限制重复被选取。如果至少一个所选数字数量不同,则两种组合是唯一的。
对于给定的输入,保证和为 target 的唯一组合数少于 150 个。
示例 1:
输入: candidates = [2,3,6,7], target = 7
输出: [[7],[2,2,3]]
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
示例 4:
输入: candidates = [1], target = 1
输出: [[1]]
示例 5:
输入: candidates = [1], target = 2
输出: [[1,1]]
提示:
1 <= candidates.length <= 30
1 <= candidates[i] <= 200
candidate 中的每个元素都是独一无二的。
1 <= target <= 500
解法1:回溯
思路:
(1)题目中的无限制重复被选取,出现0 可咋办?然后看到下面提示:1 <= candidates[i] <= 200,就放心了。本题和77.组合 (opens new window),216.组合总和III (opens new window)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
_第18张图片](http://img.e-com-net.com/image/info8/c7b90bc4b4194fbdac729bc02f8544f7.jpg)
注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!而在77.组合 (opens new window)和216.组合总和III (opens new window)中都可以知道要递归K层,因为要取k个元素的组合。
(2)回溯三部曲
2.1递归函数参数
这里依然是定义两个全局变量,二维数组result存放结果集,数组path存放符合条件的结果。(这两个变量可以作为函数参数传入)。首先是题目中给出的参数,集合candidates, 和目标值target。
此外还定义了int型的sum变量来统计单一结果path里的总和,其实这个sum也可以不用,用target做相应的减法就可以了,最后如何target==0就说明找到符合的结果了,但为了代码逻辑清晰,依然用了sum。
本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:77.组合 (opens new window),216.组合总和III (opens new window)。 如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合(opens new window)
注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍。
代码如下:
vector> result;
vector path;
void backtracking(vector& candidates, int target, int sum, int startIndex)
2.2.递归终止条件
本题搜索的过程抽象成树形结构如下:
_第19张图片](http://img.e-com-net.com/image/info8/50a5cd6187354a9891865959e461e402.jpg)
从叶子节点可以清晰看到,终止只有两种情况,sum大于target和sum等于target。
sum等于target的时候,需要收集结果,代码如下:
if (sum > target) {
return;
}
if (sum == target) {
result.push_back(path);
return;
}
2.3.单层搜索的逻辑
单层for循环依然是从startIndex开始,搜索candidates集合。
注意本题和77.组合 (opens new window)、216.组合总和III (opens new window)的一个区别是:本题元素为可重复选取的。
如何重复选取呢,看代码,注释部分:
for (int i = startIndex; i < candidates.size(); i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i); // 关键点:不用i+1了,表示可以重复读取当前的数
sum -= candidates[i]; // 回溯
path.pop_back(); // 回溯
}
代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum > target) {
return;
}
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size(); i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i); // 不用i+1了,表示可以重复读取当前的数
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
result.clear();
path.clear();
backtracking(candidates, target, 0, 0);
return result;
}
};
复杂度分析:
_第20张图片](http://img.e-com-net.com/image/info8/3bc1601a56174afc82e8a537315861ad.jpg)
解法2:剪枝优化
思路:
_第21张图片](http://img.e-com-net.com/image/info8/c8a0ec5d7d814fc8bdd3bc9a5aa18796.jpg)
以及上面的版本一的代码大家可以看到,对于sum已经大于target的情况,其实是依然进入了下一层递归,只是下一层递归结束判断的时候,会判断sum > target的话就返回。 其实如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
那么可以在for循环的搜索范围上做做文章了。对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历。
如图:
_第22张图片](http://img.e-com-net.com/image/info8/de52afe86b404bfbb3761cb33f236f6d.jpg)
for循环剪枝代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
// 如果 sum + candidates[i] > target 就终止遍历
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i);
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
result.clear();
path.clear();
sort(candidates.begin(), candidates.end()); // 需要排序
backtracking(candidates, target, 0, 0);
return result;
}
};
40. 组合总和 II
力扣链接
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
提示:
1 <= candidates.length <= 100
1 <= candidates[i] <= 50
1 <= target <= 30
解法1:回溯
思路:
(1)这道题目和39.组合总和 (opens new window)如下区别:
1.本题candidates 中的每个数字在每个组合中只能使用一次。
2.本题数组candidates的元素是有重复的,而39.组合总和 (opens new window)是无重复元素的数组candidates
最后本题和39.组合总和 (opens new window)要求一样,解集不能包含重复的组合。
**本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合。**一些同学可能想了:我把所有组合求出来,再用set或者map去重,这么做很容易超时!
所以要在搜索的过程中就去掉重复组合。
很多同学在去重的问题上想不明白,其实很多题解也没有讲清楚,反正代码是能过的,感觉是那么回事,稀里糊涂的先把题目过了。
这个去重为什么很难理解呢,所谓去重,其实就是使用过的元素不能重复选取。 这么一说好像很简单!
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
那么问题来了,我们是要同一树层上使用过,还是同一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
强调一下,树层去重的话,需要对数组排序!
选择过程树形结构如图所示:
_第23张图片](http://img.e-com-net.com/image/info8/c61028ca71784dec9fc0356740d8df68.jpg)
可以看到图中,每个节点相对于 39.组合总和 (opens new window)我多加了used数组,这个used数组下面会重点介绍。
(2)回溯三部曲
1.递归函数参数
与39.组合总和 (opens new window)套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。
这个集合去重的重任就是used来完成的。
代码如下:
vector
vector path; // 符合条件的组合
void backtracking(vector& candidates, int target, int sum, int startIndex, vector& used) {
2.递归终止条件
与39.组合总和 (opens new window)相同,终止条件为 sum > target 和 sum == target。
代码如下:
if (sum > target) { // 这个条件其实可以省略
return;
}
if (sum == target) {
result.push_back(path);
return;
}
sum > target 这个条件其实可以省略,因为和在递归单层遍历的时候,会有剪枝的操作,下面会介绍到。
3.单层搜索的逻辑
这里与39.组合总和 (opens new window)最大的不同就是要去重了。
前面我们提到:要去重的是“同一树层上的使用过”,如果判断同一树层上元素(相同的元素)是否使用过了呢。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
此时for循环里就应该做continue的操作。
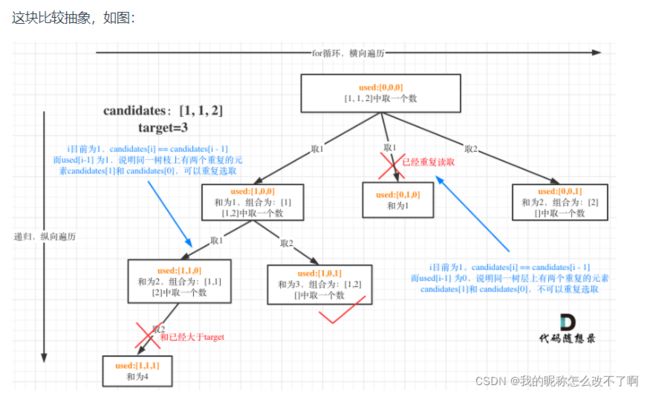
这块比较抽象,如图:
_第24张图片](http://img.e-com-net.com/image/info8/7478f41dd8a743e7be737226d43a7006.jpg)
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
used[i - 1] == false,说明同一树层candidates[i - 1]使用过
这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!
那么单层搜索的逻辑代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
used[i] = true;
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1:这里是i+1,每个数字在每个组合中只能使用一次
used[i] = false;
sum -= candidates[i];
path.pop_back();
}
注意sum + candidates[i] <= target为剪枝操作,在39.组合总和 (opens new window)有讲解过!
代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
used[i] = true;
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
used[i] = false;
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<bool> used(candidates.size(), false);
path.clear();
result.clear();
// 首先把给candidates排序,让其相同的元素都挨在一起。
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0, 0, used);
return result;
}
};
这里直接用startIndex来去重也是可以的, 就不用used数组了。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
// 要对同一树层使用过的元素进行跳过
if (i > startIndex && candidates[i] == candidates[i - 1]) {
continue;
}
sum += candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, sum, i + 1); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
sum -= candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
path.clear();
result.clear();
// 首先把给candidates排序,让其相同的元素都挨在一起。
sort(candidates.begin(), candidates.end());
backtracking(candidates, target, 0, 0);
return result;
}
};
22. 括号生成
力扣链接
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
示例 2:
输入:n = 1
输出:[“()”]
提示:
1 <= n <= 8
解法1:回溯
思路:
_第25张图片](http://img.e-com-net.com/image/info8/e954598ed0db4abcb11629717a376555.jpg)
代码:
class Solution {
private:
vector<string> result;
string path;
public:
void backtracking(int n, int leftNum, int rightNum){
//终止条件
if(path.size() == 2*n){
result.push_back(path);
return ;
}
if(leftNum<n){//遍历
path.push_back('(');
backtracking(n,leftNum+1,rightNum);//递归
path.pop_back();//回溯
}
if(leftNum > rightNum){//遍历
path.push_back(')');
backtracking(n,leftNum,rightNum+1);//递归
path.pop_back();//回溯
}
}
vector<string> generateParenthesis(int n) {
backtracking(n,0,0);
return result;
}
};
\\\\ 回溯:分割问题 \\\\
131. 分割回文串
力扣链接
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = “aab”
输出:[[“a”,“a”,“b”],[“aa”,“b”]]
示例 2:
输入:s = “a”
输出:[[“a”]]
提示:
1 <= s.length <= 16
s 仅由小写英文字母组成
解法1:回溯
思路:
(1)本题这涉及到两个关键问题:
切割问题,有不同的切割方式
判断回文
相信这里不同的切割方式可以搞懵很多同学了。这种题目,想用for循环暴力解法,可能都不那么容易写出来,所以要换一种暴力的方式,就是回溯。
回溯究竟是如何切割字符串呢?我们来分析一下切割,其实切割问题类似组合问题。例如对于字符串abcdef:
组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中在选组第三个.....。
切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中在切割第三段.....。
所以切割问题,也可以抽象为一颗树形结构,如图:
_第26张图片](http://img.e-com-net.com/image/info8/0180d18d62134af4be6b470d2d123b1e.jpg)
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
(2)回溯三部曲
2.1.递归函数参数
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
在回溯算法:求组合总和(二) (opens new window)中我们深入探讨了组合问题什么时候需要startIndex,什么时候不需要startIndex。
代码如下:
vector> result;
vector path; // 放已经回文的子串
void backtracking (const string& s, int startIndex) {
2.2.递归函数终止条件
_第27张图片](http://img.e-com-net.com/image/info8/1e3d1dc2657d4a6088af594364306348.jpg)
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止终止条件。
那么在代码里什么是切割线呢?在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
所以终止条件代码如下:
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
}
2.3.单层搜索的逻辑
来看看在递归循环,中如何截取子串呢?在for (int i = startIndex; i < s.size(); i++)循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector path中,path用来记录切割过的回文子串。
代码如下:
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 如果不是则直接跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经填在的子串
}
注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1。
(3)判断回文子串
最后我们看一下回文子串要如何判断了,判断一个字符串是否是回文。可以使用双指针法,一个指针从前向后,一个指针从后先前,如果前后指针所指向的元素是相等的,就是回文字符串了。
那么判断回文的C++代码如下:
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
代码:
class Solution {
private:
vector<vector<string>> result;
vector<string> path;
public:
void backtracking(string s,int startIndex){
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()){
result.push_back(path);
return;
}
for(int i = startIndex;i<s.size();i++){
if(isPartition(s,startIndex,i)){
// 获取[startIndex,i]在s中的子串
path.push_back(s.substr(startIndex,i-startIndex+1));
}else continue;
backtracking(s,i+1);// 寻找i+1为起始位置的子串
path.pop_back();// 回溯过程,弹出本次已经填在的子串
}
}
bool isPartition(const string& s, int start, int end){
while (start < end){
if (s[start] != s[end]){
return false;
}
start++;
end--;
}
return true;
}
vector<vector<string>> partition(string s) {
backtracking(s,0);
return result;
}
};
复杂度分析:
_第28张图片](http://img.e-com-net.com/image/info8/a5059991c70742ecb8ecca0d7dacf3f3.jpg)
解法2:回溯+动态规划优化
思路:
(1)_第29张图片](http://img.e-com-net.com/image/info8/87ca78a357b24fe5ab151c5fc91bf590.jpg)
(2)动态规划预处理完成之后,我们只需要 O(1) 的时间就可以判断任意s[i…j] 是否为回文串了。
代码:
class Solution {
private:
vector<vector<string>> result;
vector<string> path;
public:
void backtracking(string s,int startIndex,const vector<vector<bool>>& dp){
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()){
result.push_back(path);
return;
}
for(int i = startIndex;i<s.size();i++){
if(dp[i][startIndex]){
// 获取[startIndex,i]在s中的子串
path.push_back(s.substr(startIndex,i-startIndex+1));
}else continue;
backtracking(s,i+1,dp);// 寻找i+1为起始位置的子串
path.pop_back();// 回溯过程,弹出本次已经填在的子串
}
}
vector<vector<string>> partition(string s) {
vector<vector<bool>> dp(s.size(),vector<bool>(s.size(),false));
for(int i = 0;i<s.size();i++){
for(int j = 0;j<=i;j++){
if(s[i] == s[j]){
if(i-j<3) dp[i][j] = true;
else dp[i][j] = dp[i-1][j+1];
}
}
}
backtracking(s,0,dp);
return result;
}
};
复杂度分析:


相似题目:132. 分割回文串 II
力扣链接
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
示例 1:
输入:s = “aab”
输出:1
解释:只需一次分割就可将 s 分割成 [“aa”,“b”] 这样两个回文子串。
示例 2:
输入:s = “a”
输出:0
示例 3:
输入:s = “ab”
输出:1
提示:
1 <= s.length <= 2000
s 仅由小写英文字母组成
解法1:动态规划
思路:
(1)递推「最小分割次数」思路
我们定义 f[r] 为将 [1,r] 这一段字符分割为若干回文串的最小分割次数,那么最终答案为f[n]。
不失一般性的考虑 f[r]如何转移:
1.从「起点字符」到「第 r 个字符」能形成回文串。那么最小分割次数为 0,此时有 f[r] = 0;
2.从「起点字符」到「第 r 个字符」不能形成回文串。此时我们需要枚举左端点 l,如果 [l,r]这一段是回文串的话,那么有 f[r] = f[l - 1] + 1。
在 2 中满足回文要求的左端点位置 l 可能有很多个,我们在所有方案中取一个min 即可。
(2)快速判断「任意一段子串是否回文」思路
_第30张图片](http://img.e-com-net.com/image/info8/ed05a6f0bb0043128b70bb6645e152bf.jpg)
(3)dp数组如何初始化
首先来看一下dp[0]应该是多少。
dp[i]: 范围是[0, i]的回文子串,最少分割次数是dp[i]。
那么dp[0]一定是0,长度为1的字符串最小分割次数就是0。这个是比较直观的。
在看一下非零下标的dp[i]应该初始化为多少?
在递推公式dp[i] = min(dp[i], dp[j] + 1) 中我们可以看出每次要取最小的dp[i]。
那么非零下标的dp[i]就应该初始化为一个最大数,这样递推公式在计算结果的时候才不会被初始值覆盖!
如果非零下标的dp[i]初始化为0,在那么在递推公式中,所有数值将都是零。
非零下标的dp[i]初始化为一个最大数。
代码如下:
vector dp(s.size(), INT_MAX);
dp[0] = 0;
其实也可以这样初始化,更具dp[i]的定义,dp[i]的最大值其实就是i,也就是把每个字符分割出来。
所以初始化代码也可以为:
vector dp(s.size());
for (int i = 0; i < s.size(); i++) dp[i] = i;
代码:
class Solution {
public:
int minCut(string s) {
vector<vector<bool>> dp(s.size(),vector<bool>(s.size(),false));
for (int i = 0;i<s.size();i++){
for(int j = 0;j<=i;j++){
if(s[i] == s[j]){
if(i-j<3) dp[j][i] = true;
else dp[j][i] = dp[j+1][i-1];
}
}
}
vector<int> cutCount(s.size(),INT_MAX);
cutCount[0] = 0;
for(int i = 1;i<s.size();i++){
if(dp[0][i]) cutCount[i] = 0;
else{
for(int j = 0;j<i;j++){
if(dp[j+1][i]) cutCount[i] = min(cutCount[i],cutCount[j]+1);
}
}
}
return cutCount[s.size()-1];
}
};
复杂度分析:

93. 复原 IP 地址
力扣链接
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “[email protected]” 是 无效 IP 地址。
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 ‘.’ 来形成。你不能重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
示例 1:
输入:s = “25525511135”
输出:[“255.255.11.135”,“255.255.111.35”]
示例 2:
输入:s = “0000”
输出:[“0.0.0.0”]
示例 3:
输入:s = “1111”
输出:[“1.1.1.1”]
示例 4:
输入:s = “010010”
输出:[“0.10.0.10”,“0.100.1.0”]
示例 5:
输入:s = “101023”
输出:[“1.0.10.23”,“1.0.102.3”,“10.1.0.23”,“10.10.2.3”,“101.0.2.3”]
提示:
0 <= s.length <= 20
s 仅由数字组成
解法1:回溯
思路:
(1)这是切割问题,切割问题就可以使用回溯搜索法把所有可能性搜出来,和刚做过的131.分割回文串 (opens new window)就十分类似了。
切割问题可以抽象为树型结构,如图:
_第31张图片](http://img.e-com-net.com/image/info8/07406a73e8884484abbd1fff77c9a80f.jpg)
(2)回溯三部曲
2.1.递归参数
在131.分割回文串 (opens new window)中我们就提到切割问题类似组合问题。startIndex一定是需要的,因为不能重复分割,记录下一层递归分割的起始位置。
本题我们还需要一个变量pointNum,记录添加逗点的数量。
所以代码如下:
vector result;// 记录结果
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
void backtracking(string& s, int startIndex, int pointNum) {
2.2.递归终止条件
终止条件和131.分割回文串 (opens new window)情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。然后验证一下第四段是否合法,如果合法就加入到结果集里
代码如下:
if (pointNum == 3) { // 逗点数量为3时,分隔结束
// 判断第四段子字符串是否合法,如果合法就放进result中
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
2.3.单层搜索的逻辑
在131.分割回文串 (opens new window)中已经讲过在循环遍历中如何截取子串。在for (int i = startIndex; i < s.size(); i++)循环中 [startIndex, i]这个区间就是截取的子串,需要判断这个子串是否合法。
如果合法就在字符串后面加上符号.表示已经分割。
如果不合法就结束本层循环,如图中剪掉的分支:
_第32张图片](http://img.e-com-net.com/image/info8/ebd92f2e6f004687b3ad3c423604e511.jpg)
然后就是递归和回溯的过程:
递归调用时,下一层递归的startIndex要从i+2开始(因为需要在字符串中加入了分隔符.),同时记录分割符的数量pointNum 要 +1。
回溯的时候,就将刚刚加入的分隔符. 删掉就可以了,pointNum也要-1。
代码如下:
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
pointNum++;
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
pointNum--; // 回溯
s.erase(s.begin() + i + 1); // 回溯删掉逗点
} else break; // 不合法,直接结束本层循环
}
(3)判断子串是否合法
最后就是在写一个判断段位是否是有效段位了。主要考虑到如下三点:
段位以0为开头的数字不合法
段位里有非正整数字符不合法
段位如果大于255了不合法
代码如下:
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
代码:
class Solution {
public:
bool isValid(string& s, int start, int end){
if(start>end) return false;
if(s[start] == '0' && start!=end) return false;
int num = 0;
for(int i = start;i<=end;i++){
num = num*10 + s[i]-'0';
if (num > 255) return false;
}
return true;
}
vector<string> result;
void backTracking(string& s, int startIndex, int pointNum){
if(pointNum == 3){
// 判断第四段子字符串是否合法,如果合法就放进result中
if(isValid(s,startIndex,s.size()-1)) result.push_back(s);
return;
}
for(int i = startIndex;i<s.size();i++){
if(isValid(s,startIndex,i)){
s.insert(s.begin()+i+1,'.');
pointNum++;
backTracking(s,i+2,pointNum);
s.erase(s.begin()+i+1);
pointNum--;
}else break;
}
}
vector<string> restoreIpAddresses(string s) {
backTracking(s,0,0);
return result;
}
};
复杂度分析:
我们用SEG_COUNT=4 表示 IP 地址的段数。
时间复杂度:O(3 **SEG_COUNT)。由于 IP 地址的每一段的位数不会超过 3,因此在递归的每一层,我们最多只会深入到下一层的 3 种情况。由于SEG_COUNT=4,对应着递归的最大层数,所以递归本身的时间复杂度为 O(3 **SEG_COUNT)。
相关题目:468. 验证IP地址
力扣
编写一个函数来验证输入的字符串是否是有效的 IPv4 或 IPv6 地址。
如果是有效的 IPv4 地址,返回 “IPv4” ;
如果是有效的 IPv6 地址,返回 “IPv6” ;
如果不是上述类型的 IP 地址,返回 “Neither” 。
IPv4 地址由十进制数和点来表示,每个地址包含 4 个十进制数,其范围为 0 - 255, 用(“.”)分割。比如,172.16.254.1;
同时,IPv4 地址内的数不会以 0 开头。比如,地址 172.16.254.01 是不合法的。
IPv6 地址由 8 组 16 进制的数字来表示,每组表示 16 比特。这些组数字通过 (“:”)分割。比如, 2001:0db8:85a3:0000:0000:8a2e:0370:7334 是一个有效的地址。而且,我们可以加入一些以 0 开头的数字,字母可以使用大写,也可以是小写。所以, 2001:db8:85a3:0:0:8A2E:0370:7334 也是一个有效的 IPv6 address地址 (即,忽略 0 开头,忽略大小写)。
然而,我们不能因为某个组的值为 0,而使用一个空的组,以至于出现 (: 的情况。 比如, 2001:0db8:85a3::8A2E:0370:7334 是无效的 IPv6 地址。
同时,在 IPv6 地址中,多余的 0 也是不被允许的。比如, 02001:0db8:85a3:0000:0000:8a2e:0370:7334 是无效的。
示例 1:
输入:IP = “172.16.254.1”
输出:“IPv4”
解释:有效的 IPv4 地址,返回 “IPv4”
示例 2:
输入:IP = “2001:0db8:85a3:0:0:8A2E:0370:7334”
输出:“IPv6”
解释:有效的 IPv6 地址,返回 “IPv6”
示例 3:
输入:IP = “256.256.256.256”
输出:“Neither”
解释:既不是 IPv4 地址,又不是 IPv6 地址
示例 4:
输入:IP = “2001:0db8:85a3:0:0:8A2E:0370:7334:”
输出:“Neither”
示例 5:
输入:IP = “1e1.4.5.6”
输出:“Neither”
提示:
IP 仅由英文字母,数字,字符 ‘.’ 和 ‘:’ 组成。
解法1:字符串
代码:
class Solution {
public:
string validIPAddress(string queryIP) {
if(isIP4(queryIP)) return "IPv4";
if(isIP6(queryIP)) return "IPv6";
return "Neither";
}
void split(string IP, vector<string>& vecS, const char spearator){
string tempStr;
for(int i = 0;i<IP.size();i++){
if(IP[i] == spearator){
vecS.push_back(tempStr);
tempStr.clear();
}else{
tempStr += IP[i];
}
}
vecS.push_back(tempStr);
}
bool isIP4(string IP){
vector<string> vecIp;
split(IP,vecIp,'.');
if(vecIp.size() != 4) return false;
for(string s:vecIp){
if(s.size()==0||(s.size()>1&&s[0]=='0'||s.size()>3)) return false;
for(char c:s){
if(!(c<='9' && c>='0')) return false;
}
int digit = stoi(s);
if(digit < 0|| digit>255) return false;
}
return true;
}
bool isIP6(string IP){
vector<string> vecIp;
split(IP,vecIp,':');
if(vecIp.size() != 8) return false;
for(string s:vecIp){
if(s.size() == 0 || s.size()>4) return false;
for(char c:s){
if((c<'0' || c>'9') && (c<'a' || c>'f') && (c<'A' || c>'F') ) return false;
}
}
return true;
}
};
306. 累加数
力扣链接
累加数 是一个字符串,组成它的数字可以形成累加序列。
一个有效的 累加序列 必须 至少 包含 3 个数。除了最开始的两个数以外,字符串中的其他数都等于它之前两个数相加的和。
给你一个只包含数字 ‘0’-‘9’ 的字符串,编写一个算法来判断给定输入是否是 累加数 。如果是,返回 true ;否则,返回 false 。
说明:累加序列里的数,除数字 0 之外,不会 以 0 开头,所以不会出现 1, 2, 03 或者 1, 02, 3 的情况。
示例 1:
输入:“112358”
输出:true
解释:累加序列为: 1, 1, 2, 3, 5, 8 。1 + 1 = 2, 1 + 2 = 3, 2 + 3 = 5, 3 + 5 = 8
示例 2:
输入:“199100199”
输出:true
解释:累加序列为: 1, 99, 100, 199。1 + 99 = 100, 99 + 100 = 199
提示:
1 <= num.length <= 35
num 仅由数字(0 - 9)组成
解法1:回溯+字符串
思路:
今天这道题注意几个条件:
1.一个有效的累加序列至少包含 3 个数;
2.除了前两个数以外,其余数等于前面两数之和;
3.不会出现前导 0,但是,0 可以单独做为一个数来使用,比如 “101”,可以拆分成 1 + 0 = 1,所以,它是累加数。
代码:
class Solution {
public:
vector<double> path;
bool backtracking(string num,int startIndex) {
int n = path.size();
//终止条件
if(n>=3 && path[n-1] != path[n-2]+path[n-3]) return false;
// 如果起始位置已经大于num的大小,说明已经找到了一组分割方案了
if(startIndex >= num.size() && n>=3) return true;
for(int i = startIndex;i<num.size();i++){
string cur = num.substr(startIndex,i-startIndex+1);
if(cur[0] == '0' && cur.size() != 1) return false;
path.push_back(stod(cur));
if(backtracking(num,i+1)) return true;
path.pop_back();
}
return false;
}
bool isAdditiveNumber(string num) {
return backtracking(num,0);
}
};
698. 划分为k个相等的子集
力扣链接
给定一个整数数组 nums 和一个正整数 k,找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。
示例 1:
输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4
输出: True
说明: 有可能将其分成 4 个子集(5),(1,4),(2,3),(2,3)等于总和。
示例 2:
输入: nums = [1,2,3,4], k = 3
输出: false
提示:
1 <= k <= len(nums) <= 16
0 < nums[i] < 10000
每个元素的频率在 [1,4] 范围内
解法1:回溯
思路:
(1)k个桶,理解为单桶,找k个,只有有一个找不到,就fasle,
(2)为什么要排序呢,其实不排序这道题也能做对,但是由于时间的关系就t了。排序就是为了优化时间,怎么优化呢?我们从nums中最大的数开始找,如果最大的数比子集和都要大,或者装下它后没到子集和的大小但是装不下nums中最小的值了,那么这个nums绝对是false,因为有一个这么大的数在nums里,你把它放在哪个子集里都不合适。
从大到小遍历,这有点类似贪心的思想。比如,我们为了凑一定数量的钱,我们肯定先选择面额比较大的,最后再选面额小的。这样凑出来更快。再举个例子——组合【4】要达到5只需要找值为1的元素,而【1】要达到5则要把遇到的2,3,4都试一遍。
(3)递归——相当于一条路,走到黑,不撞南墙不回头.
回溯——返回上一个状态(通常都在递归结束后).
剪枝——使递归提前结束,降低时间复杂度
代码:
class Solution {
public:
bool canPartitionKSubsets(vector<int>& nums, int k) {
int sum = 0;
for(int num : nums) sum += num;
if(sum % k) return false;
int target = sum / k, n = nums.size();
//sort(nums.begin(), nums.end());
sort(nums.begin(),nums.end(),greater<int>());
if(nums.back() > target || target < nums[0]) return false;
vector<bool> visited(n,false);
return backtracking(nums,visited,0,0,target,k);
}
bool backtracking(vector<int>& nums, vector<bool>& visited, int startIndex, int curSum, int target,int k){
if(k == 0) return true;
if(curSum == target) return backtracking(nums,visited,0,0,target,k-1);
for(int i = startIndex;i<nums.size();i++){
if(visited[i] || (i > 0 && nums[i] == nums[i-1] && visited[i-1] == false)) continue;
if(curSum + nums[i] > target) continue;
visited[i] = true;
curSum += nums[i];
if(backtracking(nums,visited,i+1,curSum,target,k)) return true;
curSum -= nums[i];
visited[i] = false;
}
return false;
}
};
相似题目:473. 火柴拼正方形
力扣链接
你将得到一个整数数组 matchsticks ,其中 matchsticks[i] 是第 i 个火柴棒的长度。你要用 所有的火柴棍 拼成一个正方形。你 不能折断 任何一根火柴棒,但你可以把它们连在一起,而且每根火柴棒必须 使用一次 。
如果你能使这个正方形,则返回 true ,否则返回 false 。
示例 1:
_第33张图片](http://img.e-com-net.com/image/info8/cc4bc488ecd74e31a11305597c94771c.jpg)
输入: matchsticks = [1,1,2,2,2]
输出: true
解释: 能拼成一个边长为2的正方形,每边两根火柴。
示例 2:
输入: matchsticks = [3,3,3,3,4]
输出: false
解释: 不能用所有火柴拼成一个正方形。
提示:
1 <= matchsticks.length <= 15
1 <= matchsticks[i] <= 108
解法1:回溯
思路:
**分析:**要想组成正方形,需要四条边都等于总和的1/4,因此需要将火柴分成四组,使得每一个火柴都属于其中的一组。因此可以考虑回溯,将四条边想象成四个桶,如果将当前的边加入到一个桶中没有违背条件,则在此基础上继续回溯。如果回溯到最后也无法满足,或者如果某个边加入后就超出理应的边长了,就剪枝。
优化的策略:
如果火柴杆的总和不是4的倍数,直接返回false即可。
将火柴杆从大到小排序,优先选用大的边可以令不成功的情况更快的返回。
代码:
class Solution {
public:
bool makesquare(vector<int>& matchsticks) {
int sum = 0;
for(int& num:matchsticks) sum += num;
if(sum % 4) return false;
int target = sum / 4, n = matchsticks.size();
vector<bool> visited(n,false);
sort(matchsticks.begin(),matchsticks.end(),greater<int>());
if(target < matchsticks[0] || target < matchsticks.back()) return false;
return backtracking(matchsticks,visited,4,target,0,0);
}
bool backtracking(vector<int>& matchsticks,vector<bool>& visited, int k, int target, int curSum, int startIndex){
if(k == 0) return true;
if(curSum == target) return backtracking(matchsticks,visited,k-1,target,0,0);
for(int i = startIndex;i<matchsticks.size();i++){
if(visited[i] || (i>0 && matchsticks[i] == matchsticks[i-1] && visited[i-1] == false)) continue;
if(curSum + matchsticks[i] > target) continue;
curSum += matchsticks[i];
visited[i] = true;
if(backtracking(matchsticks,visited,k,target,curSum,i+1)) return true;
curSum -= matchsticks[i];
visited[i] = false;
}
return false;
}
};
相似题目: 416. 分割等和子集
力扣链接
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。
提示:
1 <= nums.length <= 200
1 <= nums[i] <= 100
解法1:动态规划
这道题目初步看,是如下两题几乎是一样的,大家可以用回溯法,解决如下两题
698.划分为k个相等的子集
473.火柴拼正方形
这道题目是要找是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
那么只要找到集合里能够出现 sum / 2 的子集总和,就算是可以分割成两个相同元素和子集了。
本题是可以用回溯暴力搜索出所有答案的,但最后超时了,也不想再优化了,放弃回溯,直接上01背包。
(1) 01背包问题
背包问题,大家都知道,有N件物品和一个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
背包问题有多种背包方式,常见的有:01背包、完全背包、多重背包、分组背包和混合背包等等。
要注意题目描述中商品是不是可以重复放入。
即一个商品如果可以重复多次放入是完全背包,而只能放入一次是01背包,写法还是不一样的。
要明确本题中我们要使用的是01背包,因为元素我们只能用一次。
回归主题:首先,本题要求集合里能否出现总和为 sum / 2 的子集。
那么来一一对应一下本题,看看背包问题如果来解决。
只有确定了如下四点,才能把01背包问题套到本题上来。
- 背包的体积为sum / 2
- 背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
- 背包如果正好装满,说明找到了总和为 sum / 2 的子集。
- 背包中每一个元素是不可重复放入。
动规五部曲分析如下:
1.确定dp数组以及下标的含义
01背包中,dp[j] 表示: 容量为j的背包,所背的物品价值可以最大为dp[j]。
套到本题,dp[j]表示 背包总容量是j,最大可以凑成的子集总和为dp[j]。
- 确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
本题,相当于背包里放入数值,那么物品i的重量是nums[i],其价值也是nums[i]。
所以递推公式:dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
3.dp数组如何初始化
在01背包,一维dp如何初始化,已经讲过,
从dp[j]的定义来看,首先dp[0]一定是0。
如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了。
本题题目中 只包含正整数的非空数组,所以非0下标的元素初始化为0就可以了。
代码如下:
// 题目中说:每个数组中的元素不会超过 100,数组的大小不会超过 200
// 总和不会大于20000,背包最大只需要其中一半,所以10001大小就可以了
vector dp(10001, 0);
- 确定遍历顺序
在动态规划:关于01背包问题,你该了解这些!(滚动数组) (opens new window)中就已经说明:如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒序遍历!
代码如下:
// 开始 01背包
for(int i = 0; i < nums.size(); i++) {
for(int j = target; j >= nums[i]; j--) { // 每一个元素一定是不可重复放入,所以从大到小遍历
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
- 举例推导dp数组
dp[i]的数值一定是小于等于i的。
如果dp[i] == i 说明,集合中的子集总和正好可以凑成总和i,理解这一点很重要。
用例1,输入[1,5,11,5] 为例,如图:
_第34张图片](http://img.e-com-net.com/image/info8/bc975809ad624b43a0360146bfb42665.jpg)
最后dp[11] == 11,说明可以将这个数组分割成两个子集,使得两个子集的元素和相等。
代码:
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
for(int i = 0;i<nums.size();i++){
sum += nums[i];
}
if(sum % 2 == 1) return false;
int target = sum / 2;
vector<int> dp(target+1, 0);
for(int i = 0;i<nums.size();i++){//遍历物品
for(int j = target;j>= nums[i];j--){//遍历背包
dp[j] = max(dp[j], dp[j-nums[i]] + nums[i]);
}
}
if(dp[target] == target) return true;
return false;
}
};
解法2:优化动态规划
参考思路:
_第35张图片](http://img.e-com-net.com/image/info8/fce7c25035334791be214b49d9bccb57.jpg)

代码:
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
for(int i = 0;i<nums.size();i++){
sum += nums[i];
}
if(sum % 2 == 1) return false;
int target = sum / 2;
vector<bool> dp(target+1, false);
dp[0] = true;
for(int& num:nums){
for(int j = target;j>=num;j--){
dp[j] = dp[j] || dp[j-num];
}
}
return dp[target];
}
};
\\\\ 回溯:子集问题 \\\\
78. 子集
力扣链接
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同
解法1:回溯
思路:
(1)求子集问题和77.组合 (opens new window)和131.分割回文串 (opens new window)又不一样了。
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
什么时候for可以从0开始呢?求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合。
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
_第36张图片](http://img.e-com-net.com/image/info8/c3981efa4666410dba83247d0eb61502.jpg)
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
(2)回溯三部曲
1.递归函数参数
全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里)
递归函数参数在上面讲到了,需要startIndex。
代码如下:
vector> result;
vector path;
void backtracking(vector& nums, int startIndex) {
2.递归终止条件
从图中可以看出:
_第37张图片](http://img.e-com-net.com/image/info8/ae79caff20e0474e9a983f72d0799e2f.jpg)
剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
if (startIndex >= nums.size()) {
return;
}
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
3.单层搜索逻辑
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
那么单层递归逻辑代码如下:
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]); // 子集收集元素
backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取
path.pop_back(); // 回溯
}
代码:
根据关于回溯算法,你该了解这些! (opens new window)给出的回溯算法模板:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
要清楚子集问题和组合问题、分割问题的的区别,子集是收集树形结构中树的所有节点的结果。
而组合问题、分割问题是收集树形结构中叶子节点的结果。
复杂度分析:
时间复杂度:O(n×2^n)。一共 2^n个状态,每种状态需要 O(n)的时间来构造子集。
空间复杂度:O(n)。
90. 子集 II
力扣链接
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
解法1:回溯
思路:
这道题目和78.子集 (opens new window)区别就是集合里有重复元素了,而且求取的子集要去重。
那么关于回溯算法中的去重问题,在40.组合总和II (opens new window)中已经详细讲解过了,和本题是一个套路。
剧透一下,后期要讲解的排列问题里去重也是这个套路,所以理解**“树层去重”和“树枝去重”非常重要。**
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)
_第38张图片](http://img.e-com-net.com/image/info8/7231e61adcb246db8ff34f82a6fd224b.jpg)
从图中可以看出,同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
本题就是其实就是回溯算法:求子集问题! (opens new window)的基础上加上了去重,
代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
// 而我们要对同一树层使用过的元素进行跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, i + 1, used);
used[i] = false;
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0, used);
return result;
}
};
本题也可以不使用used数组来去重,因为递归的时候下一个startIndex是i+1而不是0。
如果要是全排列的话,每次要从0开始遍历,为了跳过已入栈的元素,需要使用used。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
// 而我们要对同一树层使用过的元素进行跳过
if (i > startIndex && nums[i] == nums[i - 1] ) { // 注意这里使用i > startIndex
continue;
}
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 去重需要排序
backtracking(nums, 0);
return result;
}
};
_第39张图片](http://img.e-com-net.com/image/info8/c7d6153eb24649b7bb3cdebd1695d36b.jpg)
491. 递增子序列
力扣链接
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。
数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
示例 1:
输入:nums = [4,6,7,7]
输出:[[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]
示例 2:
输入:nums = [4,4,3,2,1]
输出:[[4,4]]
提示:
1 <= nums.length <= 15
-100 <= nums[i] <= 100
解法1:回溯
思路
_第40张图片](http://img.e-com-net.com/image/info8/20295a428c624ed28833913b03db05f6.jpg)
_第41张图片](http://img.e-com-net.com/image/info8/846963b0f72c4c51b1fda4319df0c416.jpg)
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void dfs(vector<int>& nums, int startIndex){
if(path.size()>1) res.push_back(path);// 注意这里不要加return,要取树上的节点
if(startIndex >= nums.size()) return;
unordered_set<int> uset;// 使用set对本层元素进行去重
for(int i = startIndex;i<nums.size();i++){
if((!path.empty()&&nums[i]<path.back()) || uset.find(nums[i]) != uset.end()) continue;
uset.insert(nums[i]);// 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
dfs(nums,i+1);
path.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
dfs(nums,0);
return res;
}
};
\\\\ 回溯:排列问题 \\\\
相关题目:31. 下一个排列
力扣链接
实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列(即,组合出下一个更大的整数)。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须 原地 修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3]
输出:[1,3,2]
示例 2:
输入:nums = [3,2,1]
输出:[1,2,3]
示例 3:
输入:nums = [1,1,5]
输出:[1,5,1]
示例 4:
输入:nums = [1]
输出:[1]
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 100
解法1:双指针
思路:
1.先找出最大的索引 k 满足 nums[k] < nums[k+1],如果不存在,就翻转整个数组;
2.再找出另一个最大索引 l 满足 nums[l] > nums[k];
3.交换 nums[l] 和 nums[k];
4.最后翻转 nums[k+1:]。
_第42张图片](http://img.e-com-net.com/image/info8/68e95f84d1014a62b53f0cd6954ba43f.jpg)
举个例子:
比如 nums = [1,2,7,4,3,1],下一个排列是什么?
我们找到第一个最大索引是 nums[1] = 2
再找到第二个最大索引是 nums[4] = 3
交换,nums = [1,3,7,4,2,1];
翻转,nums = [1,3,1,2,4,7]
代码:
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int firstIndex = -1;
for(int i = nums.size()-2;i>=0;i--){
if(nums[i]<nums[i+1]){
firstIndex = i;
break;
}
}
if(firstIndex == -1){
reverse(nums.begin(),nums.end());
return;
}
int secondIndex = -1;
for(int i = nums.size()-1;i>=0;i--){
if(nums[i]>nums[firstIndex]){
secondIndex = i;
break;
}
}
swap(nums[firstIndex],nums[secondIndex]);
reverse(nums.begin() + firstIndex + 1,nums.end());
return;
}
};
优化:
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int i = nums.size()-2;
while(i>=0 && nums[i]>=nums[i+1]) i--;
int firstIndex = i;
if(firstIndex == -1){
reverse(nums.begin(),nums.end());
return;
}
int j = nums.size()-1;
while(j>=0 && nums[j]<=nums[firstIndex]) j--;
int secondIndex = j;
swap(nums[firstIndex],nums[secondIndex]);
reverse(nums.begin() + firstIndex + 1,nums.end());
return;
}
};
_第43张图片](http://img.e-com-net.com/image/info8/c055620671d140389cd324b5567a3934.jpg)
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(1)
相关题目:60. 排列序列
力扣链接
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一 一标记,当 n = 3 时, 所有排列如下:
“123”
“132”
“213”
“231”
“312”
“321”
给定 n 和 k,返回第 k 个排列。
示例 1:
输入:n = 3, k = 3
输出:“213”
示例 2:
输入:n = 4, k = 9
输出:“2314”
示例 3:
输入:n = 3, k = 1
输出:“123”
提示:
1 <= n <= 9
1 <= k <= n!
解法1:双指针
注意:回溯求全排列超时
思路:
利用31.下一个排列解题
代码:
class Solution {
public:
string getPermutation(int n, int k) {
string result;
for(int i = 1;i<=n;i++) result+= i+'0';
k--;
while(k--){
nextPermutation(result);
}
return result;
}
void nextPermutation(string& nums) {
int i = nums.size()-2;
while(i>=0 && nums[i]>=nums[i+1]) i--;
int firstIndex = i;
if(firstIndex >=0 ){
int j = nums.size()-1;
while(j>=0 && nums[j]<=nums[firstIndex]) j--;
int secondIndex = j;
swap(nums[firstIndex],nums[secondIndex]);
}
reverse(nums.begin() + firstIndex + 1,nums.end());
return;
}
};
复杂度分析:
时间复杂度:O(n^2)。
空间复杂度:O(n)。
46. 全排列
力扣链接
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
提示:
1 <= nums.length <= 6
-10 <= nums[i] <= 10
nums 中的所有整数 互不相同
解法1:回溯
思路
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示:
_第44张图片](http://img.e-com-net.com/image/info8/452508a06be248ef93c14ddaa5a75633.jpg)
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& used){
if(path.size() == nums.size()){
res.push_back(path);
return;
}
for(int i = 0;i<nums.size();i++){
if(used[i] == true) continue;
used[i] = true;
path.push_back(nums[i]);
dfs(nums,used);
used[i] = false;
path.pop_back();
}
}
vector<vector<int>> permute(vector<int>& nums) {
int n = nums.size();
vector<bool> used(n,false);
dfs(nums,used);
return res;
}
};
_第45张图片](http://img.e-com-net.com/image/info8/ced0f411d2bd44868aa28064133a0a67.jpg)
47. 全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8
-10 <= nums[i] <= 10
解法1:回溯
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& used){
if(path.size() >= nums.size()){
res.push_back(path);
return;
}
for(int i = 0;i<nums.size();i++){
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == false) continue;
if(used[i] == false){
used[i] = true;
path.push_back(nums[i]);
dfs(nums,used);
path.pop_back();
used[i] = false;
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
//回溯
sort(nums.begin(),nums.end());
int n = nums.size();
vector<bool> used(n,false);
dfs(nums,used);
return res;
}
};
\\\\ 回溯:棋盘问题 \\\\
51. N 皇后
力扣链接
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
示例 1:
_第46张图片](http://img.e-com-net.com/image/info8/7c968ae5292a49e188712e047b1ba70b.jpg)
输入:n = 4
输出:[[“.Q…”,“…Q”,“Q…”,“…Q.”],[“…Q.”,“Q…”,“…Q”,“.Q…”]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1
输出:[[“Q”]]
提示:
1 <= n <= 9
解法1:回溯
思路:
(1)都知道n皇后问题是回溯算法解决的经典问题,但是用回溯解决多了组合、切割、子集、排列问题之后,遇到这种二维矩阵还会有点不知所措。
首先来看一下皇后们的约束条件:
不能同行
不能同列
不能同斜线
确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。
下面我用一个 3 * 3 的棋盘,将搜索过程抽象为一棵树,如图:
_第47张图片](http://img.e-com-net.com/image/info8/14e6695d87384f219945c6da9553c6f1.jpg)
从图中,可以看出,二维矩阵中矩阵的高就是这棵树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
那么我们用皇后们的约束条件,来回溯搜索这棵树,只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
(2)回溯三部曲
按照我总结的如下回溯模板,我们来依次分析:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
- 递归函数参数
我依然是定义全局变量二维数组result来记录最终结果。
参数n是棋盘的大小,然后用row来记录当前遍历到棋盘的第几层了。
代码如下:
vector> result;
void backtracking(int n, int row, vector& chessboard) {
- 递归终止条件
在如下树形结构中:
_第48张图片](http://img.e-com-net.com/image/info8/673ea802279c4fc0aa3051857942009e.jpg)
可以看出,当递归到棋盘最底层(也就是叶子节点)的时候,就可以收集结果并返回了。
代码如下:
if (row == n) {
result.push_back(chessboard);
return;
}
- 单层搜索的逻辑
递归深度就是row控制棋盘的行,每一层里for循环的col控制棋盘的列,一行一列,确定了放置皇后的位置。
每次都是要从新的一行的起始位置开始搜,所以都是从0开始。
代码如下:
for (int col = 0; col < n; col++) {
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
chessboard[row][col] = 'Q'; // 放置皇后
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.'; // 回溯,撤销皇后
}
}
-
验证棋盘是否合法
按照如下标准去重:不能同行
不能同列
不能同斜线 (45度和135度角)
代码如下:bool isValid(int row, int col, vector& chessboard, int n) {
int count = 0;
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessboard[i][col] == ‘Q’) {
return false;
}
}
// 检查 45度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i–, j–) {
if (chessboard[i][j] == ‘Q’) {
return false;
}
}
// 检查 135度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i–, j++) {
if (chessboard[i][j] == ‘Q’) {
return false;
}
}
return true;
}
在这份代码中,细心的同学可以发现为什么没有在同行进行检查呢?
因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
那么按照这个模板不难写出如下C++代码:
class Solution {
private:
vector<vector<string>> result;
// n 为输入的棋盘大小
// row 是当前递归到棋盘的第几行了
void backtracking(int n, int row, vector<string>& chessboard) {
if (row == n) {
result.push_back(chessboard);
return;
}
for (int col = 0; col < n; col++) {
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
chessboard[row][col] = 'Q'; // 放置皇后
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.'; // 回溯,撤销皇后
}
}
}
bool isValid(int row, int col, vector<string>& chessboard, int n) {
int count = 0;
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessboard[i][col] == 'Q') {
return false;
}
}
// 检查 45度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
// 检查 135度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
public:
vector<vector<string>> solveNQueens(int n) {
result.clear();
std::vector<std::string> chessboard(n, std::string(n, '.'));
backtracking(n, 0, chessboard);
return result;
}
};
代码:
class Solution {
public:
vector<vector<string>> result;
void backtracking(int n, int row, vector<string>& board){
if(row == n){
result.push_back(board);
return;
}
for(int col = 0;col < n;col++){//遍历
if(isValid(row, col, board, n)){
board[row][col] = 'Q';
backtracking(n, row+1, board);//递归
board[row][col] = '.';//回溯
}
}
}
bool isValid(int row, int col, vector<string>& board, int n){
for(int i = 0;i<row;i++){
if(board[i][col] == 'Q') return false;
}
for(int i = row - 1, j = col - 1;i>=0 && j>=0;i--,j--){
if(board[i][j] == 'Q') return false;
}
for(int i = row - 1, j = col + 1;i>=0 && j<n;i--,j++){
if(board[i][j] == 'Q') return false;
}
return true;
}
vector<vector<string>> solveNQueens(int n) {
vector<string> board(n,string(n,'.'));
backtracking(n,0,board);
return result;
}
};
解法2:基于位运算的回溯
思路:
如果利用位运算记录皇后的信息,就可以将记录皇后信息的空间复杂度从 O(N) 降到 O(1)。
解题思路见:回溯+位运算
代码:
class Solution {
public:
vector<vector<string>> result;
void backtracking(int n, int row, vector<string>& board, int up, int upLeft, int upRight){
if(row == n){
result.push_back(board);
return;
}
for(int col = 0;col < n;col++){//遍历
int curLoc = 1 << col;
if(curLoc & up || curLoc & upLeft || curLoc & upRight) continue;
board[row][col] = 'Q';
backtracking(n, row+1, board, up | curLoc, (curLoc | upLeft) >> 1, (curLoc | upRight) << 1);//递归
board[row][col] = '.';//回溯
}
}
vector<vector<string>> solveNQueens(int n) {
vector<string> board(n,string(n,'.'));
backtracking(n,0,board,0,0,0);
return result;
}
};
_第49张图片](http://img.e-com-net.com/image/info8/ac2c87a98f7a45f38cea33542e29db8e.jpg)
相似题目:52. N皇后 II
力扣链接
n 皇后问题 研究的是如何将 n 个皇后放置在 n × n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。
示例 1:
_第50张图片](http://img.e-com-net.com/image/info8/787e9e64f6654cdf91456b7655438d84.jpg)
输入:n = 4
输出:2
解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1
输出:1
提示:
1 <= n <= 9
解法1:回溯
class Solution {
public:
vector<vector<string>> result;
void backtracking(int n, int row, vector<string>& board){
if(row == n){
result.push_back(board);
return;
}
for(int col = 0;col < n;col++){//遍历
if(isValid(row, col, board, n)){
board[row][col] = 'Q';
backtracking(n, row+1, board);//递归
board[row][col] = '.';//回溯
}
}
}
bool isValid(int row, int col, vector<string>& board, int n){
for(int i = 0;i<row;i++){
if(board[i][col] == 'Q') return false;
}
for(int i = row - 1, j = col - 1;i>=0 && j>=0;i--,j--){
if(board[i][j] == 'Q') return false;
}
for(int i = row - 1, j = col + 1;i>=0 && j<n;i--,j++){
if(board[i][j] == 'Q') return false;
}
return true;
}
int totalNQueens(int n) {
vector<string> board(n,string(n,'.'));
backtracking(n,0,board);
return result.size();
}
};
解法2:位运算+回溯
class Solution {
public:
vector<vector<string>> result;
void backtracking(int n, int row, vector<string>& board, int up, int upLeft, int upRight){
if(row == n){
result.push_back(board);
return;
}
for(int col = 0;col < n;col++){//遍历
int curLoc = 1 << col;
if(curLoc & up || curLoc & upLeft || curLoc & upRight) continue;
board[row][col] = 'Q';
backtracking(n, row+1, board, up | curLoc, (curLoc | upLeft) >> 1, (curLoc | upRight) << 1);//递归
board[row][col] = '.';//回溯
}
}
int totalNQueens(int n) {
vector<string> board(n,string(n,'.'));
backtracking(n,0,board,0,0,0);
return result.size();
}
};
37. 解数独
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 ‘.’ 表示。
示例:
_第51张图片](http://img.e-com-net.com/image/info8/fc90a86a10204a9ca8ccf2fbdbca626c.png)
_第52张图片](http://img.e-com-net.com/image/info8/14edc820c05842a5b7a4a8846686d74b.png)
_第53张图片](http://img.e-com-net.com/image/info8/78409ca0e89a43c6a00d3c78689d90b2.jpg)
提示:
board.length == 9
board[i].length == 9
board[i][j] 是一位数字或者 ‘.’
题目数据 保证 输入数独仅有一个解
解法1:回溯法
思路:
(1)棋盘搜索问题可以使用回溯法暴力搜索,只不过这次我们要做的是二维递归。
怎么做二维递归呢?如下回溯法题目,例如:77.组合(组合问题) (opens new window),131.分割回文串(分割问题) (opens new window),78.子集(子集问题) (opens new window),46.全排列(排列问题) (opens new window),以及51.N皇后(N皇后问题) (opens new window),其实这些题目都是一维递归。
**N皇后问题 (opens new window)**是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。本题就不一样了,本题中棋盘的每一个位置都要放一个数字,并检查数字是否合法,解数独的树形结构要比N皇后更宽更深。
因为这个树形结构太大了,我抽取一部分,如图所示:
_第54张图片](http://img.e-com-net.com/image/info8/111dd6c1cae64965bda761a272328751.jpg)
(2)回溯三部曲
2.1.递归函数以及参数
递归函数的返回值需要是bool类型,为什么呢?
因为解数独找到一个符合的条件(就在树的叶子节点上)立刻就返回,相当于找从根节点到叶子节点一条唯一路径,所以需要使用bool返回值,这一点在回溯算法:N皇后问题 (opens new window)中已经介绍过了,一样的道理。
代码如下:
bool backtracking(vector>& board)
2.2.递归终止条件
本题递归不用终止条件,解数独是要遍历整个树形结构寻找可能的叶子节点就立刻返回。 不用终止条件会不会死循环?递归的下一层的棋盘一定比上一层的棋盘多一个数,等数填满了棋盘自然就终止(填满当然好了,说明找到结果了),所以不需要终止条件!
那么有没有永远填不满的情况呢?这个问题在递归单层搜索逻辑里讲!
2.3.递归单层搜索逻辑
_第55张图片](http://img.e-com-net.com/image/info8/14f38f0ad61142dc8ea64a212757ad04.jpg)
在树形图中可以看出我们需要的是一个二维的递归(也就是两个for循环嵌套着递归)。一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!
代码如下:(详细看注释)
bool backtracking(vector<vector<char>>& board) {
for (int i = 0; i < board.size(); i++) { // 遍历行
for (int j = 0; j < board[0].size(); j++) { // 遍历列
if (board[i][j] != '.') continue;
for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适
if (isValid(i, j, k, board)) {
board[i][j] = k; // 放置k
if (backtracking(board)) return true; // 如果找到合适一组立刻返回
board[i][j] = '.'; // 回溯,撤销k
}
}
return false; // 9个数都试完了,都不行,那么就返回false
}
}
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
}
注意这里return false的地方,这里放return false 是有讲究的。因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!
那么会直接返回, 这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!
(3)判断棋盘是否合法
判断棋盘是否合法有如下三个维度:
同行是否重复
同列是否重复
9宫格里是否重复
代码如下:
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
for (int i = 0; i < 9; i++) { // 判断行里是否重复
if (board[row][i] == val) {
return false;
}
}
for (int j = 0; j < 9; j++) { // 判断列里是否重复
if (board[j][col] == val) {
return false;
}
}
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val ) {
return false;
}
}
}
return true;
}
代码:
class Solution {
public:
// 回溯
bool backtracking(vector<vector<char>>& board){
for (int i = 0;i<board.size();i++){
for(int j = 0;j<board[0].size();j++){
if(board[i][j] != '.') continue;
// (i, j) 这个位置放k是否合适
for (char k='1';k<='9';k++){
if(isValid(i,j,k,board)){
board[i][j] = k;
if (backtracking(board)) return true;//递归
board[i][j] = '.';//回溯
}
}
return false;
}
}
return true;// 遍历完没有返回false,说明找到了合适棋盘位置了
}
bool isValid(int row,int col ,char val,vector<vector<char>>& board){
// 判断行里是否重复
for(int i = 0;i<9;i++){
if(board[row][i] == val) return false;
}
// 判断列里是否重复
for(int i = 0;i<9;i++){
if(board[i][col] == val) return false;
}
// 判断box里是否重复
int startRow = (row/3)*3;
int startCol = (col/3)*3;
for(int i = startRow;i<startRow+3;i++){
for (int j = startCol;j<startCol+3;j++){
if(board[i][j] == val) return false;
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};
复杂度分析: 同36题
\\\\ 回溯:其他 \\\\
95. 不同的二叉搜索树 II
力扣链接
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。
示例 1:
_第56张图片](http://img.e-com-net.com/image/info8/efe922980830473c8c0cc78f1f0cda82.jpg)
输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
1 <= n <= 8
解法1:回溯+二叉搜索树
思路:
_第57张图片](http://img.e-com-net.com/image/info8/80c646ab9db846429bd678a817495127.jpg)
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<TreeNode*> generateTrees(int n) {
vector<TreeNode*> res;
res = helper(1,n);
return res;
}
vector<TreeNode*> helper(int start, int end){
vector<TreeNode*> res;
if(start > end) res.push_back(nullptr);
// 枚举可行根节点
for(int i = start;i<=end;i++) {
// 获得所有可行的左子树集合
vector<TreeNode*> l = helper(start,i-1);
// 获得所有可行的you子树集合
vector<TreeNode*> r = helper(i+1,end);
// 从左子树集合中选出一棵左子树,从右子树集合中选出一棵右子树,拼接到根节点上
for(auto& ll:l){
for(auto& rr : r){
TreeNode* root = new TreeNode(i);
root->left = ll;
root->right = rr;
res.push_back(root);
}
}
}
return res;
}
};
相似题目:241. 为运算表达式设计优先级
力扣链接
给你一个由数字和运算符组成的字符串 expression ,按不同优先级组合数字和运算符,计算并返回所有可能组合的结果。你可以 按任意顺序 返回答案。
示例 1:
输入:expression = “2-1-1”
输出:[0,2]
解释:
((2-1)-1) = 0
(2-(1-1)) = 2
示例 2:
输入:expression = “23-45”
输出:[-34,-14,-10,-10,10]
解释:
(2*(3-(45))) = -34
((23)-(45)) = -14
((2(3-4))5) = -10
(2((3-4)5)) = -10
(((23)-4)*5) = 10
提示:
1 <= expression.length <= 20
expression 由数字和算符 ‘+’、‘-’ 和 ‘*’ 组成。
输入表达式中的所有整数值在范围 [0, 99]
解法1:回溯+分治
思路:
_第58张图片](http://img.e-com-net.com/image/info8/b526627511d942b7921e67dc9b7acad5.jpg)
代码:
class Solution {
public:
vector<int> diffWaysToCompute(string expression) {
vector<int> res;
for(int i = 0;i<expression.size();i++){
if(expression[i] == '+' || expression[i] == '-' ||expression[i] == '*'){
vector<int> l = diffWaysToCompute(expression.substr(0,i));
vector<int> r = diffWaysToCompute(expression.substr(i+1));
for(int ll:l){
for(int rr:r){
if(expression[i] == '+') res.push_back(ll+rr);
else if(expression[i] == '-') res.push_back(ll-rr);
else if(expression[i] == '*') res.push_back(ll*rr);
}
}
}
}
if(res.empty()){
res.push_back(stoi(expression));
}
return res;
}
};