Python和PostgreSQL,PostGIS,空间数据管理
此文倒叙整理,从下-上为整理顺序
常用空间sql命令
text AddGeometryColumn(varchar table_name, varchar column_name, integer srid, varchar type, integer dimension, boolean use_typmod=true);
text AddGeometryColumn(varchar schema_name, varchar table_name, varchar column_name, integer srid, varchar type, integer dimension, boolean use_typmod=true);
text AddGeometryColumn(varchar catalog_name, varchar schema_name, varchar table_name, varchar column_name, integer srid, varchar type, integer dimension, boolean use_typmod=true);
-- Create schema to hold data
CREATE SCHEMA my_schema;
-- Create a new simple PostgreSQL table
CREATE TABLE my_schema.my_spatial_table (id serial);
-- Add a spatial column to the table
SELECT AddGeometryColumn ('my_spatial_table','geom',4326,'POINT',2);
-- Add a point using the old constraint based behavior
SELECT AddGeometryColumn ('my_spatial_table','geom_c',4326,'POINT',2, false);
-- Add a curvepolygon using old constraint behavior
SELECT AddGeometryColumn ('my_spatial_table','geomcp_c',4326,'CURVEPOLYGON',2, false);
-- 对点的geom赋值
UPDATE my_spatial_table SET geom = ST_SetSRID(ST_MakePoint(longitude, latitude), 4326);应用实例
在点表格中增加一列并update其他栅格数据对应点的值
-- 在表格omso2中增加一列dem_val用来存放之后从dem栅格中匹配的dem值
ALTER TABLE omso2 ADD COLUMN IF NOT EXISTS dem_val decimal;
-- 更新omso2中的dem_val,为了快速验证sql是否可用,限制了omso2.id的范围
-- 理解:1、将omso2与dem的匹配结果定义为mtable
-- 2、根据mtable中的id与omso2的id去用得到的demval的值update表格omso2的的dem_val
WITH mtable AS(
SELECT omso2.*,ST_Value(dem.rast, omso2.geom) AS demval
FROM omso2,dem
WHERE ST_INTERSECTS(omso2.geom,dem.rast) AND omso2.id<10)
UPDATE omso2
SET dem_val = mtable.demval
FROM mtable
WHERE omso2.id = mtable.id;
-- 结果见下图 结果见下图: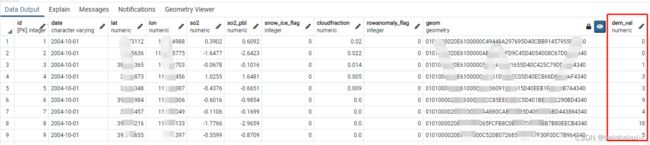
对表A中的日期匹配表B中小于A的日期的最近日期
SELECT tpdate.date AS tpdt,ndvidate.date AS ndvidt
FROM tpdate JOIN ndvidate
ON ndvidate.date=(
SELECT date
FROM ndvidate
WHERE date<=tpdate.date
ORDER BY date DESC LIMIT 1);结果见下图
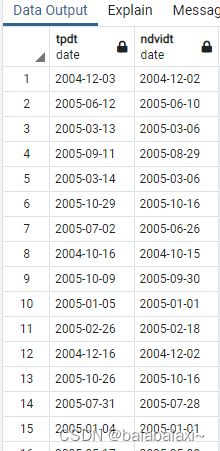
更新表A中的日期为表B中小于A的日期的最近日期
UPDATE tpdate SET ndvidt=ndvidate.date
FROM ndvidate where ndvidate.date=(
SELECT date
FROM ndvidate
WHERE date<=tpdate.date
ORDER BY date DESC LIMIT 1);postgis创建渔网,并按照边界裁剪
drop table if exists fishnet;
SELECT ST_SetSRID(ST_POINT(lon,lat),4326) AS geom
INTO fishnet
FROM generate_series(6,54,0.2) AS lat,generate_series(73,136,0.2) AS lon;
DELETE FROM fishnet WHERE fishnet.geom IN
(SELECT fishnet.geom
FROM fishnet,chinabd
WHERE NOT ST_Intersects(fishnet.geom,chinabd.geom));
SELECT count(*) FROM fishnet;配置查看,中断连接等
--查看配置文件路径
show config_file;
--查看当前活跃的connection
SELECT * FROM pg_stat_activity;
--How to terminate PostgreSQL sessions
--中断connection
--terminate all connections to the specified database
SELECT pg_terminate_backend(procpid) FROM pg_stat_activity WHERE datname = 'wiki'
--terminate all connections tied to a specific user
SELECT pg_terminate_backend(procpid) FROM pg_stat_activity WHERE usename = 'blog'
--terminate all connections but not my own
SELECT pg_terminate_backend(procpid) FROM pg_stat_activity WHERE procpid <> pg_backend_pid()
--use username to filter out permitted connections
SELECT pg_terminate_backend(procpid) FROM pg_stat_activity WHERE username <> current_username
--中断query
--cancel a running query
SELECT pg_cancel_backend(procpid) FROM pg_stat_activity WHERE usename = 'postgres'
日期
1.to_date
reference:PostgreSQL: to_date Function
to_date( string1, format_mask )
--string1: The string that will be converted to a date.
--format_mask: The format that will be used to convert string1 to a date. It can be one of the following and can be used in many combinations.
--例子
SELECT to_date('2014/04/25', 'YYYY/MM/DD');
SELECT to_date('033114', 'MMDDYY');
SELECT to_date('February 08, 2014', 'Month DD, YYYY');
UPDATE ndvi SET date=to_date(substring(filename from 2 for 7),'YYYYDDD');| Parameter | Explanation |
|---|---|
| YYYY | 4-digit year |
| Y,YYY | 4-digit year, with comma |
| YYY YY Y |
Last 3, 2, or 1 digit(s) of year |
| IYYY | 4-digit year based on the ISO standard |
| IYY IY I |
Last 3, 2, or 1 digit(s) of ISO year |
| Q | Quarter of year (1, 2, 3, 4; JAN-MAR = 1). |
| MM | Month (01-12; JAN = 01). |
| MON | Abbreviated name of month in all uppercase |
| Mon | Abbreviated name of month capitalized |
| mon | Abbreviated name of month in all lowercase |
| MONTH | Name of month in all uppercase, padded with blanks to length of 9 characters |
| Month | Name of month capitalized, padded with blanks to length of 9 characters |
| month | Name of month in all lowercase, padded with blanks to length of 9 characters |
| RM | Month in uppercase Roman numerals |
| rm | Month in lowercase Roman numerals |
| WW | Week of year (1-53) where week 1 starts on the first day of the year |
| W | Week of month (1-5) where week 1 starts on the first day of the month |
| IW | Week of year (01-53) based on the ISO standard |
| DAY | Name of day in all uppercase, padded with blanks to length of 9 characters |
| Day | Name of day capitalized, padded with blanks to length of 9 characters |
| day | Name of day in all lowercase, padded with blanks to length of 9 characters |
| DY | Abbreviated name of day in all uppercase |
| Dy | Abbreviated name of day capitalized |
| dy | Abbreviated name of day in all lowercase |
| DDD | Day of year (1-366) |
| IDDD | Day of year based on ISO year |
| DD | Day of month (01-31) |
| D | Day of week (1-7, where 1=Sunday, 7=Saturday) |
| ID | Day of week based on ISO year (1-7, where 1=Monday, 7=Sunday) |
| J | Julian day; the number of days since midnight on November 24, 4714 BC |
| HH | Hour of day (01-12) |
| HH12 | Hour of day (01-12) |
| HH24 | Hour of day (00-23) |
| MI | Minute (00-59) |
| SS | Second (00-59) |
| MS | Millisecond (000-999) |
| US | Microsecond (000000-999999) |
| SSSS | Seconds past midnight (0-86399) |
| am, AM, pm, or PM | Meridian indicator |
| a.m., A.M., p.m., or P.M. | Meridian indicator |
| ad, AD, a.d., or A.D | AD indicator |
| bc, BC, b.c., or B.C. | BC indicator |
| TZ | Name of time zone in uppercase |
| tz | Name of time zone in lowercase |
| CC | 2-digit century |
2.获取当前日期
SELECT CURRENT_DATE ;ALTER用法
ALTER TABLE table_name ADD COLUMN IF NOT EXISTS column_name DATA_TYPEUPDATE用法
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
UPDATE table1
SET table1.col1 = expression
FROM table2
WHERE table1.col2 = table2.col2;sql嵌套
Deleting points outside polygon with PostGIS [closed]
DELETE FROM points_table WHERE
points_table.id IN (
SELECT a.id FROM
points_table a, polygon_table b
WHERE NOT ST_Intersects(a.geom, b.geom)
);将多个同结构的表格合并成一个新的表格
-- 方法一
CREATE TABLE merged (id serial primary key, attrib1 integer, attrib2 varchar(15),....);
SELECT AddGeometryColumn('my_spatial_table','geom',4326,'POINT',2);
INSERT INTO merged (attrib1, attrib2,geom) SELECT attribA, attribB,geom FROM table_1;
INSERT INTO merged (attrib1, attrib2,geom) SELECT attribA, attribB,geom FROM table_2;
-- 方法二
CREATE TABLE merged AS(SELECT attribA, attribB,geom FROM table_1 UNION
SELECT attribA, attribB,geom FROM table_2 UNION
SELECT attribA, attribB,geom FROM table_3);
SELECT Populate_Geometry_Columns('merged'::regclass);insert into ... select .. from和select into
insert into...select 需要提前创建好table,可以对table的部分列进行insert
-- insert into...select...例子
CREATE TABLE merged (id serial primary key, attrib1 integer, attrib2 varchar(15),....);
SELECT AddGeometryColumn('my_spatial_table','geom',4326,'POINT',2);
INSERT INTO merged (attrib1, attrib2,geom) SELECT attribA, attribB,geom FROM table_1;
INSERT INTO merged (attrib1, attrib2,geom) SELECT attribA, attribB,geom FROM table_2;select into是直接将select的结果新建一个table导入进去。官方解释:Create a new table films_recent consisting of only recent entries from the table films:
-- select into例子
SELECT * INTO films_recent FROM films WHERE date_prod >= '2002-01-01';查找空间点对应的栅格数据的值
-- 在DEM数据表中查找点(120,42)所在的栅格值
-- 得到SRID列
SELECT ST_SetSRID(ST_Point(120,42), 4326) FROM dem
-- 得到一列值,其中非正确点位的值为null
SELECT ST_Value(rast, ST_SetSRID(ST_Point(120, 42), 4326)) FROM public.dem;
-- 只得到一个值,正确点位的值
WITH rasvalue AS
(SELECT ST_Value(rast, ST_SetSRID(ST_Point(120, 42), 4326)) AS res
FROM public.ndvi WHERE filename='A2004273.tif')
SELECT * FROM rasvalue WHERE rasvalue.res IS NOT NULL;-- 根据point类型的表提取dem栅格值
SELECT omso2.*,ST_Value(dem.rast, omso2.geom) AS val
FROM omso2,dem
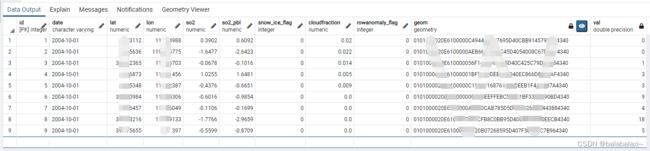
WHERE ST_INTERSECTS(omso2.geom,dem.rast) AND omso2.id<10;查询结果如下
常用sql命令(基础)
--创建数据库
CREATE DATABASE dbname;
--创建空间数据库(需要安装postgis)
CREATE DATABASE interpolationdata TEMPLATE=postgis_32_sample;
--删除数据库
DROP DATABASE [ IF EXISTS ] name
--创建表格
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( 一个或多个列 )
);
--删除表格
DROP TABLE [IF EXISTS] table_name;
--创建模式SCHEME,并在视图下创建数据表
--scheme的优势:
--允许多个用户使用一个数据库并且不会互相干扰。
--将数据库对象组织成逻辑组以便更容易管理。
--第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
create schema myschema;
create table myschema.company(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
-- insert into
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
-- select from
SELECT column1, column2,...columnN FROM table_name;
SELECT column1, column2,...columnN FROM table_name WHERE [condition];
SELECT * FROM table_name;
SELECT * FROM table_name WHERE [condition];
SELECT column1, column2, columnN
FROM table_name
WHERE [CONDITION | EXPRESSION];
SELECT column1, column2, columnN
FROM table_name
WHERE SINGLE VALUE MATCHTING EXPRESSION;
SELECT * FROM COMPANY WHERE SALARY = 10000;
SELECT (17 + 6) AS ADDITION ;
SELECT COUNT(*) AS "RECORDS" FROM COMPANY;
SELECT CURRENT_TIMESTAMP;
-- where
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
-- where 子查询
SELECT AGE FROM COMPANY
WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
SELECT * FROM COMPANY
WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
-- AND
SELECT column1, column2, columnN
FROM table_name
WHERE [condition1] AND [condition2]...AND [conditionN];
-- OR
SELECT column1, column2, columnN
FROM table_name
WHERE [condition1] OR [condition2]...OR [conditionN]
-- UPDATE
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
-- DELETE
DELETE FROM table_name WHERE [condition];
DELETE FROM COMPANY WHERE ID = 2;
-- LIKE
-- 在 LIKE 子句中,通常与通配符结合使用,通配符表示任意字符
-- 在 PostgreSQL 中,主要有以下两种通配符:百分号 % 和 下划线 _
-- 如果没有使用以上两种通配符,LIKE 子句和等号 = 得到的结果是一样的。
SELECT FROM table_name WHERE column LIKE 'XXXX%';
SELECT FROM table_name WHERE column LIKE '%XXXX%';
SELECT FROM table_name WHERE column LIKE 'XXXX_';
SELECT FROM table_name WHERE column LIKE '_XXXX';
SELECT FROM table_name WHERE column LIKE '_XXXX_';
-- 实例 描述
WHERE SALARY::text LIKE '200%' --找出 SALARY 字段中以 200 开头的数据。
WHERE SALARY::text LIKE '%200%' --找出 SALARY 字段中含有 200 字符的数据。
WHERE SALARY::text LIKE '_00%' --找出 SALARY 字段中在第二和第三个位置上有 00 的数据。
WHERE SALARY::text LIKE '2_%_%' --找出 SALARY 字段中以 2 开头的字符长度大于 3 的数据。
WHERE SALARY::text LIKE '%2' --找出 SALARY 字段中以 2 结尾的数据
WHERE SALARY::text LIKE '_2%3' --找出 SALARY 字段中 2 在第二个位置上并且以 3 结尾的数据
WHERE SALARY::text LIKE '2___3' --找出 SALARY 字段中以 2 开头,3 结尾并且是 5 位数的数据
-- LIMIT
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows]
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]
SELECT * FROM COMPANY LIMIT 4;
SELECT * FROM COMPANY LIMIT 3 OFFSET 2; --从第三条开始提取3条记录
-- ORDER BY
-- ASC 升序, DESC 降序
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
SELECT * FROM COMPANY ORDER BY NAME DESC;
-- GROUP BY
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
-- WITH
WITH
name_for_summary_data AS (
SELECT Statement)
SELECT columns
FROM name_for_summary_data
WHERE conditions <=> (
SELECT column
FROM name_for_summary_data)
[ORDER BY columns]
With CTE AS
(Select ID, NAME, AGE, ADDRESS, SALARYFROM COMPANY )
Select * From CTE;
--下面我们建立一张和 COMPANY 表相似的 COMPANY1 表,使用 DELETE 语句和 WITH 子句删除 COMPANY 表中 SALARY(工资) 字段大于等于 30000 的数据,并将删除的数据插入 COMPANY1 表,实现将 COMPANY 表数据转移到 COMPANY1 表中
WITH moved_rows AS (
DELETE FROM COMPANY
WHERE
SALARY >= 30000
RETURNING *
)
INSERT INTO COMPANY1 (SELECT * FROM moved_rows);
-- HAVING
-- HAVING 子句可以让我们筛选分组后的各组数据。
-- WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。
-- HAVING 子句必须放置于 GROUP BY 子句后面,ORDER BY 子句前面,下面是 HAVING 子句在 SELECT 语句中基础语法
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
-- DISTINCT
-- 在 PostgreSQL 中,DISTINCT 关键字与 SELECT 语句一起使用,用于去除重复记录,只获取唯一的记录。
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
SELECT DISTINCT name FROM COMPANY;清理空间vacuum
reference: Vacuum 和 Vacuum Full 的处理过程_weixin_34038652的博客-CSDN博客
| vacuum | vacuum full |
| 只是把表中的dead tuples进行删除标记,并没有真正物理删除;vacuum过程中,可以正常访问数据表 |
物理删除表中的dead tuples,释放空间给操作系统;vacuum full过程中,表被锁定,不允许访问 |
使用数据库
1.打开数据库
pg_ctl -D C:\PostgreSQL14\pgdata start
psql -h 127.0.0.1 -U postgres2.创建空间数据库
--创建database
CREATE DATABASE interpolationdata TEMPLATE=postgis_32_sample;
3.导入空间数据
3.1 导入栅格数据 raster2pgsql
链接:Chapter 11. Raster Data Management, Queries, and Applications
%开启服务%
pg_ctl -D C:\PostgreSQL14\pgdata start
%把创建栅格数据的sql语句%
raster2pgsql -s 4326 -I -C -M E:\dem.tif -F public.dem -t 100x100 > E:\dem.sql
%导入%
psql -d <数据库名称> -U <用户名比如postgres> -f E:\dem.sql
%psql命令%
psql是PostgreSQL 的交互式客户端工具。
使用方法:
psql [选项]... [数据库名称 [用户名称]]
通用选项:
-c, --command=命令 执行单一命令(SQL或内部指令)然后结束
-d, --dbname=DBNAME 指定要连接的数据库 (默认:"11931")
-f, --file=文件名 从文件中执行命令然后退出
-l, --list 列出所有可用的数据库,然后退出
-v, --set=, --variable=NAME=VALUE
设置psql变量NAME为VALUE
(例如,-v ON_ERROR_STOP=1)
-V, --version 输出版本信息, 然后退出
-X, --no-psqlrc 不读取启动文档(~/.psqlrc)
-1 ("one"), --single-transaction
作为一个单一事务来执行命令文件(如果是非交互型的)
-?, --help[=options] 显示此帮助,然后退出
--help=commands 列出反斜线命令,然后退出
--help=variables 列出特殊变量,然后退出
输入和输出选项:
-a, --echo-all 显示所有来自于脚本的输入
-b, --echo-errors 回显失败的命令
-e, --echo-queries 显示发送给服务器的命令
-E, --echo-hidden 显示内部命令产生的查询
-L, --log-file=文件名 将会话日志写入文件
-n, --no-readline 禁用增强命令行编辑功能(readline)
-o, --output=FILENAME 将查询结果写入文件(或 |管道)
-q, --quiet 以沉默模式运行(不显示消息,只有查询结果)
-s, --single-step 单步模式 (确认每个查询)
-S, --single-line 单行模式 (一行就是一条 SQL 命令)
输出格式选项 :
-A, --no-align 使用非对齐表格输出模式
--csv CSV(逗号分隔值)表输出模式
-F, --field-separator=STRING
为字段设置分隔符,用于不整齐的输出(默认:"|")
-H, --html HTML 表格输出模式
-P, --pset=变量[=参数] 设置将变量打印到参数的选项(查阅 \pset 命令)
-R, --record-separator=STRING
为不整齐的输出设置字录的分隔符(默认:换行符号)
-t, --tuples-only 只打印记录i
-T, --table-attr=文本 设定 HTML 表格标记属性(例如,宽度,边界)
-x, --expanded 打开扩展表格输出
-z, --field-separator-zero
为不整齐的输出设置字段分隔符为字节0
-0, --record-separator-zero
为不整齐的输出设置记录分隔符为字节0
联接选项:
-h, --host=主机名 数据库服务器主机或socket目录(默认:"本地接口")
-p, --port=端口 数据库服务器的端口(默认:"5432")
-U, --username=用户名 指定数据库用户名(默认:"11931")
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
更多信息,请在psql中输入"\?"(用于内部指令)或者 "\help"(用于SQL命令),
或者参考PostgreSQL文档中的psql章节.
臭虫报告至.
PostgreSQL 主页: 3.2 导入矢量数据 shp2pgsql
RELEASE: 3.2.1 (3.2.1)
USAGE: shp2pgsql [] [[.]]
OPTIONS:
-s [:] Set the SRID field. Defaults to 0.
Optionally reprojects from given SRID.
(-d|a|c|p) These are mutually exclusive options:
-d Drops the table, then recreates it and populates
it with current shape file data.
-a Appends shape file into current table, must be
exactly the same table schema.
-c Creates a new table and populates it, this is the
default if you do not specify any options.
-p Prepare mode, only creates the table.
-g Specify the name of the geometry/geography column
(mostly useful in append mode).
-D Use postgresql dump format (defaults to SQL insert statements).
-e Execute each statement individually, do not use a transaction.
Not compatible with -D.
-G Use geography type (requires lon/lat data or -s to reproject).
-k Keep postgresql identifiers case.
-i Use int4 type for all integer dbf fields.
-I Create a spatial index on the geocolumn.
-m Specify a file containing a set of mappings of (long) column
names to 10 character DBF column names. The content of the file is one or
more lines of two names separated by white space and no trailing or
leading space. For example:
COLUMNNAME DBFFIELD1
AVERYLONGCOLUMNNAME DBFFIELD2
-S Generate simple geometries instead of MULTI geometries.
-t Force geometry to be one of '2D', '3DZ', '3DM', or '4D'
-w Output WKT instead of WKB. Note that this can result in
coordinate drift.
-W Specify the character encoding of Shape's
attribute column. (default: "UTF-8")
-N NULL geometries handling policy (insert*,skip,abort).
-n Only import DBF file.
-T Specify the tablespace for the new table.
Note that indexes will still use the default tablespace unless the
-X flag is also used.
-X Specify the tablespace for the table's indexes.
This applies to the primary key, and the spatial index if
the -I flag is used.
-Z Prevent tables from being analyzed.
-? Display this help screen.
4.导入导出csv文件,执行命令
# 导入 copy from
PGPASSWORD=123456 psql -h 127.0.0.1 -p 5432 -d db_name -U postgres -c "\copy tab_name FROM './test.csv' WITH csv header delimiter ',' encoding 'UTF8'";
# 指定字段
PGPASSWORD=123456 psql -h 127.0.0.1 -p 5432 -d db_name -U postgres -c "\copy tab_name(id,name,age) FROM './test.csv' WITH csv header delimiter ',' encoding 'UTF8'";
# 导出 copy to
PGPASSWORD=123456 psql -h 127.0.0.1 -p 5432 -d db_name -U postgres -c "\copy (SELECT * FROM tab_name ) to './test.csv' WITH csv header delimiter ',' encoding 'UTF8'";
5.python操作数据库
documentation: https://www.psycopg.org/docs/cursor.html#cursor.copy_expert
5.1 连接数据库和sql执行
#!/usr/bin/python3
#导入依赖包
import psycopg2
#创建连接对象
conn=psycopg2.connect(database="postgres",user="postgres",password="123456",host="localhost",port="5432")
conn.autocommit = True # 自动提交事务
cur=conn.cursor() #创建指针对象
# 创建表
cur.execute("CREATE TABLE student(id integer,name varchar,sex varchar);")
# 插入数据,按照sql语句执行
cur.execute("INSERT INTO student(id,name,sex)VALUES(%s,%s,%s)",(1,'Aspirin','M'))
cur.execute("INSERT INTO student(id,name,sex)VALUES(%s,%s,%s)",(2,'Taxol','F'))
cur.execute("INSERT INTO student(id,name,sex)VALUES(%s,%s,%s)",(3,'Dixheral','M'))
# 获取结果
cur.execute('SELECT * FROM student')
results=cur.fetchall()
print(results)
# 提交事务,
# conn.commit()
# 关闭与数据库的连接
cur.close()
conn.close()
5.2 csv导入(python cur.copy_expert)
Parameters
-
sql – the COPY statement to execute.
-
file – a file-like object to read or write (according to sql).
-
size – size of the read buffer to be used in COPY FROM.
#/usr/bin/env python
# -*- coding: utf-8 -*-
import psycopg2
#创建连接对象
conn=psycopg2.connect(database="postgres",user="postgres",password="123456",host="localhost",port="5432")
conn.autocommit = True # 自动提交事务
cur = conn.cursor() #创建指针对象
my_file = open('d:/test.csv') #This is only a test file, not all the directory
# sql语句,可以根据需要修改,替换testtable为希望导入的数据表
sql = "COPY testtable FROM stdin DELIMITER \',\' CSV header;"
# 执行
cur.copy_expert(sql, my_file)
# sql语句,仅导入数据库的某几个字段时
sql = "COPY testtable(name,age,score) FROM stdin DELIMITER \',\' CSV header;"
# 执行
cur.copy_expert(sql, my_file)
cur.close()
conn.close()
5.3 (1) dataframe导入
reference: https://www.geeksforgeeks.org/how-to-insert-a-pandas-dataframe-to-an-existing-postgresql-table/
#/usr/bin/env python
# -*- coding: utf-8 -*-
import psycopg2
import pandas as pd
from sqlalchemy import create_engine
# 连接数据库
# engine = create_engine('dialect+driver://username:password@host:port/database')
engine = 'postgresql://postgres:654321@localhost/interpolationdata'
db = create_engine(engine)
conn = db.connect()
# dataframe
data = {'Name': ['Tom', 'dick', 'harry'],
'Age': [22, 21, 24]}
df = pd.DataFrame(data)
# 将dataframe导入数据库
df.to_sql('data', con=conn, if_exists='replace',index=False)
conn.close()
5.3 (2) create_engine连接数据库
reference: [1024]python sqlalchemy中create_engine用法_周小董的博客-CSDN博客_create_engine
# 基本用法
engine = create_engine('dialect+driver://username:password@host:port/database')
# dialect:数据库类型
# driver:数据库驱动选择
# username:数据库用户名
# password: 用户密码
# host:服务器地址
# port:端口
# database:数据库
# 例子
# PostgreSQL
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
# MySQL
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')
# OurSQL
engine = create_engine('mysql+oursql://scott:tiger@localhost/foo')
# Oracle
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
# Microsoft SQL Server
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')
# SQLite
engine = create_engine('sqlite:///foo.db')
engine = create_engine('sqlite:absolute/path/to/foo.db')
5.4 查询数据
#/usr/bin/env python
# -*- coding: utf-8 -*-
import psycopg2
# 查询data数据表
conn=psycopg2.connect(database="interpolationdata",user="postgres",password="654321",host="localhost",port="5432")
conn.autocommit = True # 自动提交事务
cur = conn.cursor() #创建指针对象
# 查询结果
cur.execute('SELECT * FROM data')
results=cur.fetchall()
print(results)
# 关闭
cur.close()
conn.close()
POSTGIS与Python GDAL的proj.db冲突的问题
1. 报错信息
ERROR 1: PROJ: proj_create_from_database: C:\PostgreSQL14\pgsql\share\contrib\postgis-3.2\proj\proj.db contains DATABASE.LAYOUT.VERSION.MINOR = 0 whereas a number >= 2 is expected. It comes from another PROJ installation.
2. 错误原因分析
部署好postgis时,postgis会自动创建几个环境变量,其中PROJ_LIB环境变量的值(如下)会导致GDAL找不到proj.db而报错,而GDAL的proj.db可能跟pyproj有关
PROJ_LIB=C:\PostgreSQL14\pgsql\share\contrib\postgis-3.2\proj
3. 办法一:手动处理PROJ_LIB
使用postgis之前设置PROJ_LIB,使用python GDAL而不使用postgis时删除PROJ_LIB。
4. 办法二:代码中设置环境变量值
保证pyproj已安装,在python代码前面加入下面代码
import os
os.environ['PROJ_LIB'] = r'C:\Python39\envs\proj\Lib\site-packages\pyproj\proj_dir\share\proj'
# 可采用下文的方法查找PROJ_LIB的路径
未使用anaconda创建虚拟环境情况下,参考以下路径:
C:\Python39\Lib\site-packages\pyproj\proj_dir\share\proj
在创建的虚拟环境情况下,参考以下路径:
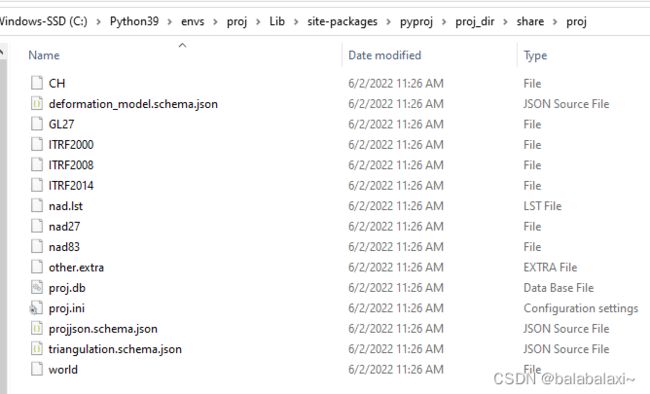
C:\Python39\envs\proj\Lib\site-packages\pyproj\proj_dir\share\proj
找到后可以看到proj.db
PostgreSQL下载安装
Reference:
starting postgresql and pgadmin in windows without installation - Stack Overflow
Short Version:
1.Download the ZIP ARCHIVE file from PostgreSQL: Windows installers
2.Unzip the archive into a directory of your choice (the archive is created such that unzipping it, it will create a directory pgsql with everything else below that)
3.Run initdb (this can be found in the subdirectory pgsql\bin)
initdb -D C:\PostgreSQL11\pgdata -U postgres -W -E UTF8 -A md5
4.To start Postgres, run:
pg_ctl -D C:\PostgreSQL11\pgdata start
5.To shutdown Postgres, run:
pg_ctl -D C:\PostgreSQL11\pgdata stop
6.psql.exe (the command line client) is located in the bin directory. Starting with Postgres 9.6 the pgAdmin executable pgAdmin4.exe is located in the sub-directory "pgAdmin 4\bin".
(optional) 7. create C:\PostgreSQL\pg11\pgsql\pgAdmin 4\pgAdmin4.bat. write:
pg_ctl -D C:\PostgreSQL\pg11\pgdata start
cd C:\PostgreSQL\pg11\pgsql\pgAdmin 4\bin\
pgAdmin4.exe
(optional) 8. send to desktop shorcut and change the picture.
pgAdmin连接PostgreSQL server
1.servers->register->server
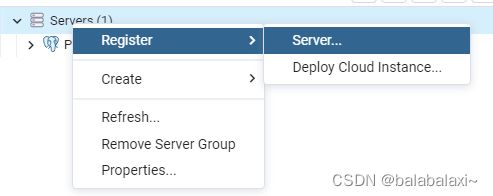
2.general->name
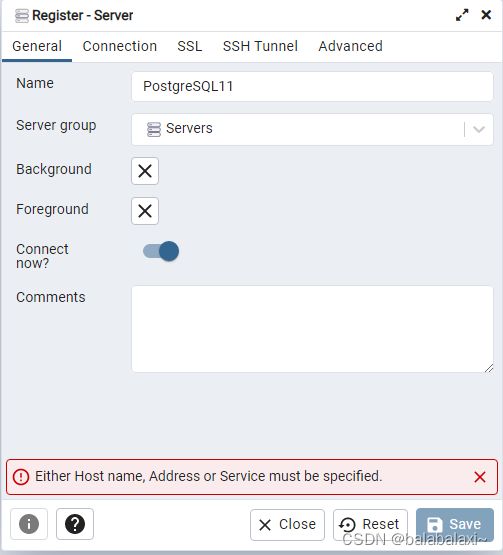
3.connection->host name
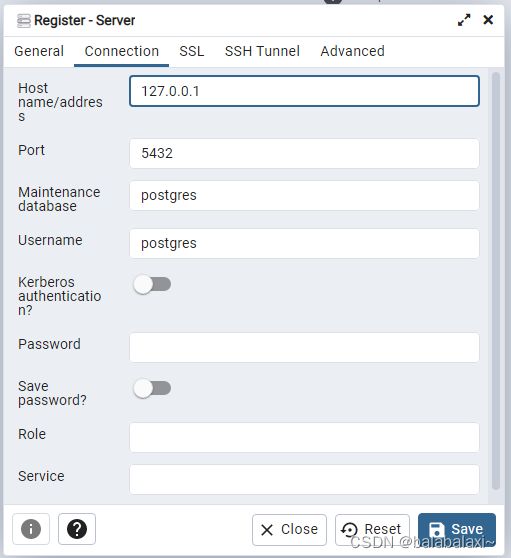
PostGIS下载安装
Reference: PostGIS 3.2.2dev Manual
1.下载exe文件,网址:Installation | PostGIS
Index of /postgis/windows/
2.开启数据库服务
3.双击exe文件安装
安装目录:C:\PostgreSQL14\pgsql #必须在postgresql安装目录下
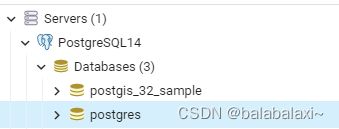
4.安装完成后在pgAdmin可以看到一个postgis_32_sample的数据库
你可能感兴趣的:(python,PostgreSQL,and,PostGIS,postgresql,数据库,database)