GPU数据传输概览
在机器学习训练过程中,大家往往会发现IO成为制约训练速度提升的瓶颈。
提升训练速度,数据传输是绕不开的话题。那么GPU机器中,数据传输是如何做的呢?
同机的CPU和GPU之间数据如何传输?
同机的多卡之间数据如何传输?
多机的卡之间数据如何传输?
1、CPU和GPU之间
1)CPU->GPU
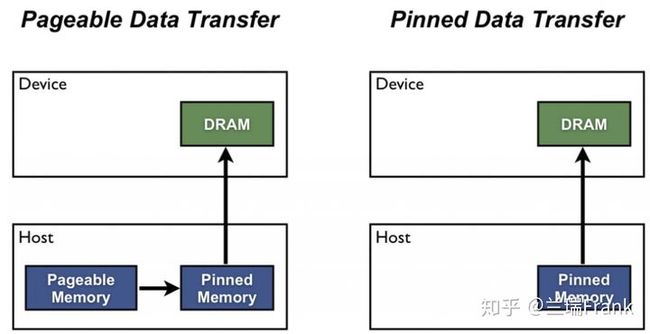
图1 锁页内存
从CPU向GPU传输数据,最为人熟知的就是cudaMemcpy了。
默认情况下,数据是从系统的分页内存先到锁页内存,然后再到GPU显存。因此如果显式指定使用锁页内存,是可以加快数据传输速度的。
(锁页内存,在cuda编程里使用CudaHostMalloc分配。实质上和linux的mlock系统调用一样,就是给内存页打上标记,不让操作系统将其从物理内存交换到硬盘)
至于为什么cuda要这样设计,个人理解是为了实现的方便。因为操作系统已经处理了硬盘和物理内存间的页交换等情况,显卡驱动只需要实现物理内存到GPU显存这一种数据传输即可,不需要把操作系统内存管理的事情再做一遍。
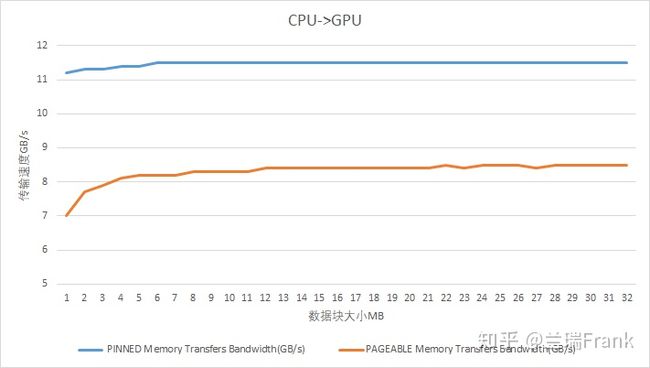
图2 G9机型(P40卡)上系统内存向显存拷贝速度
2) GPU->CPU
GPU向CPU拷贝数据时,锁页内存同样比分页内存快

图3 G9机型(P40卡)上显存向系统内存拷贝速度
值得一提的是,适当使用pinned memory显然可以加快IO速度。但是并不是越多越好,因为锁页内存是完全独占住了物理内存,操作系统无法调度,可能会影响系统整体性能。
3)同一张GPU卡内部
同一张卡内两块显存对拷,实测P40上高达~285GB/s。也比较接近于GPU卡本身的访存速度

图4 摘自P40 whitepaper
4)数据拷贝的overhead
在上面的测试数据中,可以看到传输数据量从1M->32M增长的过程中,测得的传输带宽是有逐渐增加的。
这是因为每次调用cuda api进行数据传输都有overhead,在数据量小的时候这个overhead在数据传输时间中的占比就显得很高。这也提示我们尽量合并小数据的传输
2、同机的GPU之间
一般可以通过cudaMemcpyPeer/cudaMemcpyPeerAsync函数进行显存拷贝
1)cudaMemcpyPeer withoutP2P
/********代码示例*******/
cudaSetDevice(1);
cudaMalloc((int**)&dest, bytes);
cudaSetDevice(2);
cudaMalloc((int**)&dsrc, bytes);
cudaMemcpyPeer(dest, 1, dsrc, 2, bytes);
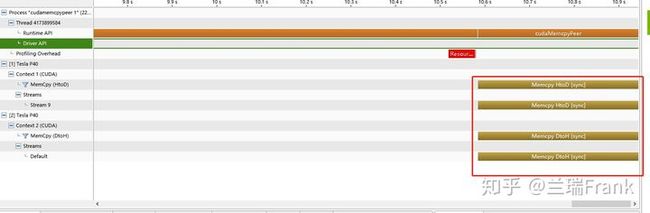
图5 GPU2向GPU1显存拷贝
通过nvprof+nvpp可以看到:禁用GPU P2P时,数据是先从GPU2拷贝到系统内存(DtoH),然后再从系统内存拷贝到GPU1(HtoD)
当然,这里是在一个进程内做GPU之间的数据拷贝。如果是2个进程分别运行在GPU1和GPU2上,那在CPU上这2个进程间可以通过共享内存或者socket通信来完成数据的拷贝。
2)cudaMemcpyPeer withP2P
/********代码示例*******/
cudaSetDevice(1);
cudaMalloc((int**)&dest, bytes);
cudaSetDevice(2);
cudaMalloc((int**)&dsrc, bytes);
cudaDeviceEnablePeerAccess(1,0);
cudaDeviceEnablePeerAccess(2,0);
cudaMemcpyPeer(dest, 1, dsrc, 2, bytes);

图6 GPU2向GPU1通过P2P进行显存拷贝
启用GPU P2P时,数据直接从GPU2拷贝到了GPU1,不再经过系统内存。
3)通过变量赋值方式传输数据
深度学习中,卡之间传递的数据其实很多都是参数数值,因此也可以直接用一个GPU内的变量给另一个GPU上的变量赋值来进行数据传输
/********代码示例*******/
cudaOccupancyMaxPotentialBlockSize(&numBlocks, &blockSize, copyp2p_float);
copyp2p_float<<
(float *)dest, (float *)src, num_elems);
__global__ void copyp2p_float(float *__restrict__ dest, float const *__restrict__ src,
size_t num_elems) {
size_t globalId = blockIdx.x * blockDim.x + threadIdx.x;
size_t gridSize = blockDim.x * gridDim.x;
#pragma unroll(5)
for (size_t i = globalId; i < num_elems; i += gridSize) {
dest[i] = src[i];
}
}
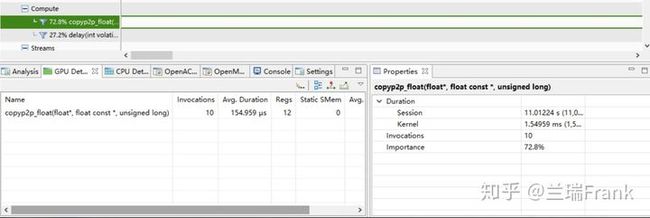
图7 GPU2向GPU1进行变量赋值
4)GPU->GPU速度测试

图8 G9机型(P40卡)上GPU to GPU显存拷贝

图9 G9机型(P40卡)上GPU to GPU变量赋值
5)GPU机器架构
使用P40卡的公司某现役型号服务器拓扑结构如下
显而易见,同一个PCIe Switch下的卡之间的数据传输 和 跨PCIe Switch的卡之间数据传输存在差异,
具体这两种情况下数据的传输路径有何不同,如何影响到传输速度,机智团队会在后续文章中结合GPU架构演进进行分析。
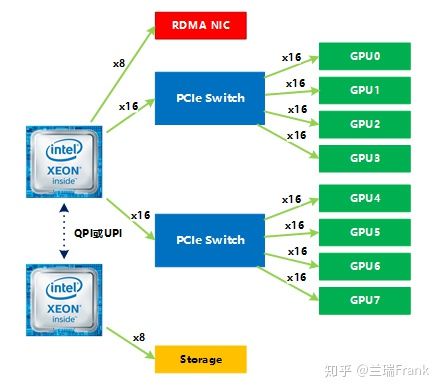
图10 某机型架构
3、多机的GPU之间

图11 两机GPU通信示意
1) NCCL性能参数
跨节点的GPU之间,数据传输当然要通过网络。除了传统的socket通信,还有GDR(GPU Direct RDMA)。关于GDR的原理,本文不赘述,可参考相关资料。
Nvidia提供了NCCL库来方便基于GPU的集合通信,这也是目前分布式GPU训练必备的工具之一。目前最新的版本是NCCL_2.4.7,相比于之前版本,2.4提供了对通信方式更细粒度的控制。对性能有影响的参数主要包括:
- NCCL_IB_DISABLE为1时禁止使用ib设备
- NCCL_P2P_LEVEL 0~5 控制在何种情况下GPU卡之间可以使用P2P
- NCCL_P2P_DISABLE=1 相当于设置NCCL_P2P_LEVEL=0,并且会被NCCL_P2P_LEVEL的值所覆盖
- NCCL_NET_GDR_LEVEL 0~5 控制在何种情况下,跨节点的GPU卡之间可以使用GDR
- NCCL_NET_GDR_READ=0 会强制在发送数据时不使用GDR;而在为1的时候,根据NCCL_NET_GDR_LEVEL来决定发送数据时是否使用GDR。接收数据时是否使用GDR完全由距离决定,和NCCL_NET_GDR_READ无关(参见nccl源码transport/http://net.cc中netGetGdrSupport函数)。
- NCCL_SHM_DISABLE 在P2P不能生效的情况下,是否使用cpu的共享内存来传输数据。如果禁用,则使用socket通信
因为nccl里面以enum{ "PIX", "PXB", "PHB", "NODE", "SYS" }来描述设备(包括GPU卡和网卡)之间的”距离”,所以NCCL_P2P_LEVEL和NCCL_NET_GDR_LEVEL都有0~5这6种取值,来细粒度控制何种情况下可以使用P2P或者GDR。
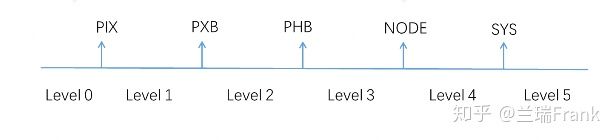
图12 LEVEL和distance的关系
对于图10中机型来说,通过参考nccl源码里的pciDistance和netDistance函数,我们可以很轻松地写出程序来输出各GPU卡和网卡之间的”距离”。

表1 p2p_level用到的pciDistance
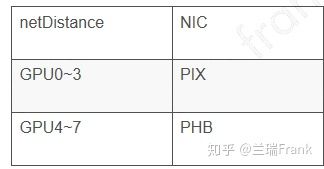
表2 net_gdr_level用到的netDistance
2)性能数据
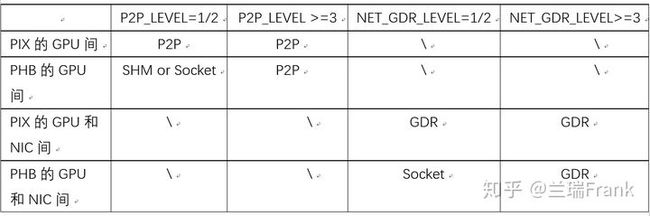
表3 多机通信时,GPU/NIC间的通信方式

表4 不同配置下通信速度对比(以2机16张P40卡nccl_broadcast为例,两机间RoCEv2+100Gbps互联)

图13 不同传输方式对多机通信速度影响巨大
以上通过一些代码分析和测试数据,介绍了实际开发中值得注意的影响GPU机器数据传输的因素。希望对从事分布式训练的同学们有一些帮助
参考资料
[1]https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/
[2]https://devblogs.nvidia.com/how-optimize-data-transfers-cuda-cc/