ChatGLM2-6B 服务器部署
准备工作
- 申请阿里云GPU免费
- 或者自己在autoDL买GPU,挺便宜
部署GLM2
chatGLM-6B的Github地址:https://github.com/THUDM/ChatGLM-6B
chatGLM-6B的模型地址:https://huggingface.co/THUDM/chatglm-6b
- 更新git 、安装lfs,用来load大文件的一个工具
apt-get updata
apt-get install git-lfs
git init
git lfs install
- 下载glm2 代码、和模型文件
连接不稳定,可能需要多clone几次,或者直接本机download然后上传(ps 还是自己upload万无一失)
git clone https://github.com/THUDM/ChatGLM-6B
#model文件最好像我这样放置
cd ChatGLM-6B
mkdir model
cd model
git clone https://huggingface.co/THUDM/chatglm2-6b
模型文件耐心等待!!
- python conda配置虚拟环境
https://github.com/THUDM/ChatGLM2-6B/tree/main 参考官方github配置过程、安装虚拟环境依赖
注意:如果在windos安装 这里的torch安装比较特殊,自动装的torch和这里的文件名不一样,少了cu118,pypi默认下载的是cpu版本的torch,不支持cuda,我们用wheel文件安装,
懒人包:百度:https://pan.baidu.com/s/1mxM-tdTiNxRGBzHzI7rlcw?pwd=plz9
提取码:plz9
一定要新一点点python版本! 比如3.10 不如install依赖容易出问题卡
- 修改配置
修改模型路径 两处

gradio中 设置share=True可以生成公网访问url、也可以配置端口

- 运行web_demo.py没问题~
微调
ptuning ChatGLM2-6B
文案生成式
- 一文搞懂ptuning是什么东西? https://zhuanlan.zhihu.com/p/583022692
- 视频参考 https://www.bilibili.com/video/BV15s4y1c7QW/?spm_id_from=333.999.0.0&vd_source=1fef0ac13db9fd03e4b2ae788361b5c4
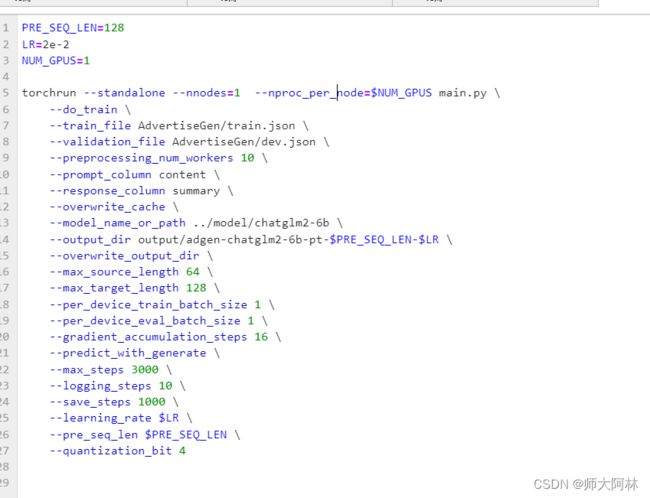
我们从giihub 下载时有一个ptuning文件夹,就是官方推荐的微调工具箱

加载大模型后会加载我们的小问题,我们的微调的模型路径如下 ,我用的是gihub提供的example数据,商品推荐的例子,把step改为了300 ,save per step也是100 (会每100个step保存我们的参数bin文件 )测试一下即可,大概30分钟跑完
- 启动模型 在ptuning文件夹下的web_demo.py
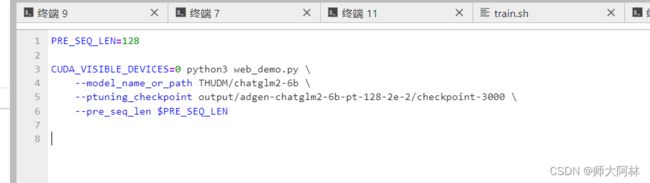
修改我们的原先的chatglm2路径、和我们的checkpoint-300 路径
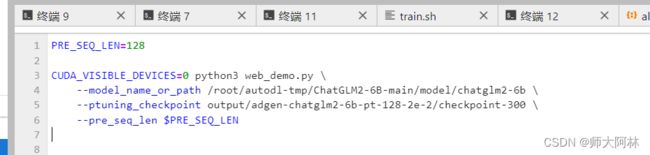
多轮对话式
看github官方,需要构建好你的多轮对话训练数据,利用train_chat.sh来做
ptuning ChatGLM2-6B
常见问题
1.问题1
报错
ModuleNotFoundError: No module named ‘pandas._libs.interval’
解决方法:更新pandas
pip install -U pandas
2.问题2
报错
AssertionError: Torch not compiled with CUDA enabled
解决方法:重新安装torch2.0.1及cuda118
pip uninstall torch
pip cache purge
pip install torch -f https://download.pytorch.org/whl/torch_stable.html
3.问题3
报错
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.00 MiB (GPU 0; 8.00 GiB total capacity; 7.25 GiB already allocated; 0 bytes free; 7.25 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解决方法:同样需要使用模型量化
model = AutoModel.from_pretrained(“D:\ChatGLM2-6B”, trust_remote_code=True).quantize(
(base) root@autodl-container-9d3911a33c-68e4ad7e:~/autodl-tmp/ChatGLM2-6B-main/ptuning# bash train.sh
usage: torchrun [-h] [–nnodes NNODES] [–nproc_per_node NPROC_PER_NODE] [–rdzv_backend RDZV_BACKEND] [–rdzv_endpoint RDZV_ENDPOINT] [–rdzv_id RDZV_ID]
[–rdzv_conf RDZV_CONF] [–standalone] [–max_restarts MAX_RESTARTS] [–monitor_interval MONITOR_INTERVAL] [–start_method {spawn,fork,forkserver}]
[–role ROLE] [-m] [–no_python] [–run_path] [–log_dir LOG_DIR] [-r REDIRECTS] [-t TEE] [–node_rank NODE_RANK] [–master_addr MASTER_ADDR]
[–master_port MASTER_PORT]
training_script …
torchrun: error: unrecognized arguments: --nproc-per-node=1
参数名称错!应该是下划线–nproc_per_node 不知道被谁该了23333
在运行ptuning后的web_demo.sh报错:
(chatglm) root@autodl-container-9d3911a33c-68e4ad7e:~/autodl-tmp/ChatGLM2-6B-main/ptuning# bash web_demo.sh
/root/autodl-tmp/ChatGLM2-6B-main/ptuning/web_demo.py:101: GradioDeprecationWarning: Thestylemethod is deprecated. Please set these arguments in the constructor instead.
user_input = gr.Textbox(show_label=False, placeholder=“Input…”, lines=10).style(
Traceback (most recent call last):
File “/root/autodl-tmp/ChatGLM2-6B-main/ptuning/web_demo.py”, line 167, in
main()
File “/root/autodl-tmp/ChatGLM2-6B-main/ptuning/web_demo.py”, line 133, in main
tokenizer = AutoTokenizer.from_pretrained(
File “/root/miniconda3/envs/chatglm/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py”, line 643, in from_pretrained
tokenizer_config = get_tokenizer_config(pretrained_model_name_or_path, **kwargs)
File “/root/miniconda3/envs/chatglm/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py”, line 487, in get_tokenizer_config
resolved_config_file = cached_file(
File “/root/miniconda3/envs/chatglm/lib/python3.10/site-packages/transformers/utils/hub.py”, line 417, in cached_file
resolved_file = hf_hub_download(
File “/root/miniconda3/envs/chatglm/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py”, line 110, in _inner_fn
validate_repo_id(arg_value)
File “/root/miniconda3/envs/chatglm/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py”, line 158, in validate_repo_id
raise HFValidationError(
huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form ‘repo_name’ or ‘namespace/repo_name’: ‘…/root/chatglm2-6b’. Userepo_typeargument if needed.
第一个是方法被弃用,没事,迭戈是路径问题,改为绝对你路径,而不是相对路径…/
参考博文
- https://zhuanlan.zhihu.com/p/639837766 chatglm2部署
- https://zhuanlan.zhihu.com/p/618498001 官方ptuning教程 知乎