Optuna----超参数调优库使用
optuna能够使用 Python 条件、循环和语法自动搜索最佳超参数。
安装
pip install optuna
官方实例
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()#默认是让返回值最小,direction='maximize'返回值最大
study.optimize(objective, n_trials=100)可以看到自动搜索超参数的代码非常简单
- 首先我们要定义一个训练函数,函数的返回值是我们想训练的结果,在例子中是使(x - 2) ** 2最小。
- 告诉optuna要训练的超参数的范围,x = trial.suggest_float('x', -10, 10)
- 创建学习对象,超参数探索次数为100次
马里奥闯关实例
学习视频:13_用选好超参数的模型去训练_哔哩哔哩_bilibili
首先引入用到的模块,并且确定需要调整的超参数,用optimize_ppo函数来定义需要调整的超参数
import optuna
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
import time
from stable_baselines3 import PPO
from matplotlib import pyplot as plt
from gym.wrappers import GrayScaleObservation
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import VecFrameStack
from stable_baselines3.common.vec_env import DummyVecEnv,SubprocVecEnv
import os
from stable_baselines3.common.results_plotter import load_results, ts2xy
import numpy as np
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.evaluation import evaluate_policy
def optimize_ppo(trial):
return {
'n_steps':trial.suggest_int('n_steps', 2048, 8192),
'gamma':trial.suggest_loguniform('gamma', 0.8, 0.9999),
'learning_rate':trial.suggest_loguniform('learning_rate', 1e-6, 1e-4),
'clip_range':trial.suggest_uniform('clip_range', 0.1, 0.4),
'gae_lambda':trial.suggest_uniform('gae_lambda', 0.8, 0.99),
'batch_size':trial.suggest_int('batch_size', 256, 1024),
}随后定义训练代码,使用evaluate_policy函数来获取一轮训练结果的平均奖励值最为输出,最终目标是最大化平均奖励。将训练马里奥的代码包入异常,可以让一次训练发生错误时让总体训练继续运行。
def optimize_function(trial):
try:
env = gym_super_mario_bros.make('SuperMarioBros-1-2-v0')
env = JoypadSpace(env, SIMPLE_MOVEMENT)
monitor_dir = r'./log/'
os.makedirs(monitor_dir,exist_ok=True)
env = Monitor(env,monitor_dir)
env = GrayScaleObservation(env,keep_dim=True)
env = DummyVecEnv([lambda: env])
env = VecFrameStack(env,4,channels_order='last')
model_params = optimize_ppo(trial)
tensorboard_log = './log/'
model = PPO("CnnPolicy", env, verbose=0,tensorboard_log=tensorboard_log,**model_params)
#model.learn(total_timesteps=1000)
model.learn(total_timesteps=500000)
# mean_reward, _ = evaluate_policy(model, env, n_eval_episodes=5)
mean_reward, _ = evaluate_policy(model, env,n_eval_episodes=4)
env.close()
save_model_dir ='./best_model/'
SAVE_PATH = os.path.join(save_model_dir, 'trial_{}_best_model'.format(trial.number))
model.save(SAVE_PATH)
return mean_reward
except Exception as e:
return -1000设置让学习的平均奖励最大
study = optuna.create_study(direction='maximize')
# study.optimize(optimize_function, n_trials=100)
study.optimize(optimize_function, n_trials=1000)观察参数、可视化
study.best_params
study.best_trial
可以查看最好的超参数,和最好的轮次数据


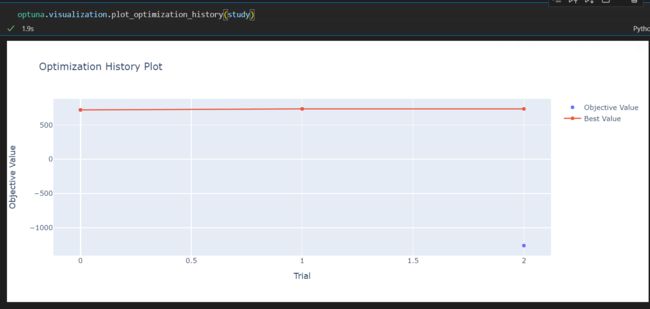
optuna.visualization.plot_optimization_history(study)
查看训练的历史
optuna.visualization.plot_param_importances(study)
打映参数的重要性

optuna.visualization.plot_parallel_coordinate(study)
目前还看不懂这个图
