python-数据分析(9-Pandas)
Pandas
9 Pandas
9.1 介绍与安装
Pandas介绍与安装
为什么会有Pandas?
Pandas支持大部分Numpy语言风格,尤其是数组函数与广播机制的各种数据处理。但是Numpy更适合处理同质型的数据。而Pandas的设计就是用来处理表格型或异质型数据的,高效的清洗、处理数据。
Pandas是什么?
Pandas是基于Numpy的一种工具,提供了高性能矩阵的运算,该工具是为了解决数据分析任务而创建的。也是贯穿整个Python数据分析非常核心的工具。
Pandas涉及内容
Pandas安装
直接在dos命令行中pip install pandas 即可。
9.2 Pandas数据结构介绍
Series是一种一维的数组型对象,它包含了一个值序列(values),并且包含了数据标签,称为索引(index)。
Series创建
pd.Series(data=None,index=None,dtype=None,name=None,copy=False)
- data:创建数组的数据,可为array-like, dict, or scalar value
- index:指定索引
- dtype:数组数据类型
- name:数组名称
- copy:是否拷贝
mport pandas as pd
pd.Series([1,2,3,4,5]) # data为iterable
索引默认为range(0,n) 可以通过index指定索引
pd.Series([1,2,3,4,5],index=list("abcde"))
数据类型根据data自动调整,但是也可以通过dtype指定
pd.Series(np.random.randint(1,10,size=5),dtype="float")
使用name参数设置数组名称
pd.Series(np.random.randint(1,10,size=3),index=list("abc"),name="ji")
-------------------------------------------
a 7
b 6
c 6
Name: ji, dtype: int32
除此之外,Pandas可以使用Numpy的数组函数。
- s.dtype # 查看数据类型
- s.astype() # 修改数据类型
- s.head(n) # 预览数据前5条
- s.tail(n) # 预览数据后5条
但是如果需要显示所有数据,则需以下代码。但并不建议使用
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
series的索引与值
- s.index # 查看索引
- s.values # 查看值序列
- s.reset_index(drop=False) # 重置索引
- drop # 是否删除原索引 默认为否
注意
- 索引对象是不可变的,所以不能单个修改索引
Series索引与切片
- s[‘标签’] # 通过标签 (标签取值是双闭合区间)
- s[‘索引’] # 通过索引
- s.loc(标签) # 通过标签
- s.iloc(索引) # 通过索引
举例
A = pd.Series(np.arange(1,5),index=list("abcd"))
# 查看"a","d"
#通过标签
A[["a","d"]]
#通过索引
A[[0,3]]
----------------------------
a 1
d 4
dtype: int32
#取a-c的数据
A["a":"c"]
--------------------
a 1
b 2
c 3
dtype: int32
Series运算
- 共同索引对应为运算,其它填充NaN
s1 = pd.Series(range(1,3),index=range(2))
s2 = pd.Series(range(2,6),index=range(4))
s1+s2
-----------------------------------
0 3.0
1 5.0
2 NaN
3 NaN
dtype: float64
- 没有共同索引时,则全部为NaN
9.3 DataFrame
DataFrame介绍
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型(数值,字符串,布尔值)。在DataFrame中,数据被存储为一个以上的二维块。
DataFrame创建
pd.DataFrame(data=None,index=None,columns=None,dtype=None,copy=False)
- data:创建数组的数据,可为ndarray, dict
- index:指定索引
- dtype:数组数据类型
- copy:是否拷贝
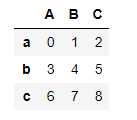
df = pd.DataFrame(np.arange(9).reshape(3,3),index=list("abc"),columns=list("ABC"))
df
---------------------------------------
重置索引
除了创建时可以指定,我们创建后还可以通过df.reindex()进行重置索引。
- df.reindex(index=None, columns=None, axis=None,fill_value=nan)
#重置行索引
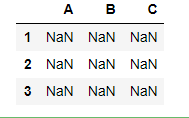
df.reindex(index=[1,2,3]) #如果行索引与指定的索引无关 则全部填充nan
#列索引也是一样
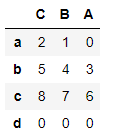
#可以同时重置行索引和列索引
#若有不一致的,则默认填充nan,但是可以指定fill_value填充值
df.reindex(index=list("abcd"),columns=list("CBA"),fill_value=0)
DataFrame基础操作
- df.shape # 查看数组形状,返回值为元组
- df.dtypes # 查看列数据类型
- df.ndim # 数据维度,返回为整数
- df.index # 行索引
- df.columns # 列索引
- df.values # 值
- df.head(n) # 显示头部几行,默认前5行
- df.tail(n) # 显示末尾几行,默认后5行
- df.info() # 相关信息概述
data = [
{"name":"amy","age":18,"tel":10086},
{"name":"bob","age":18},
{"name":"james","tel":10086},
{"name":"zs","tel":10086},
{"name":"james","tel":10086},
{"name":"ls","tel":10086},
]
d2 = pd.DataFrame(data)
d2.head()
d2.tail()
d2.info()
| 类型 | 描述 |
|---|---|
| df[:索引]或df[:“标签”] | 表示对行操作 |
| df[“列标签”]或 df[[“列标签”,“列标签”]] | 表示对列进行操作 |
使用loc及iloc查询数据:
- df.loc[] 通过轴标签选择数据
- df.iloc[] 通过整数索引选择数据
具体使用如下
| 类型 | 描述 |
|---|---|
| df.loc[val] | 根据标签索引选择DataFrame的单行或多行 |
| df.loc[:,val] | 根据标签索引选择DataFrame的单列或多列 |
| df.loc[val1,val2] | 同时选择行和列中的一部分 |
| df.iloc[where] | 根据位置索引选择DataFrame的单行或多行 |
| df.iloc[:,where] | 根据位置索引选择DataFrame的单列或多列 |
| df.iloc[where_i,where_j] | 根据位置索引选择行和列 |
DataFrame修改数据
修改数据主要遵循以下两点:
- 查询数据
- 再赋值
注意
Pandas中可以直接赋值np.nan,且赋值当前列数据会自动转为浮点类型。而不是整个数组都转,这主要是因为Pandas数据可以是异质性。
DataFrame新增数据
新增列: df[“新的列标签”] = 值
注意:添加列,则新添加的值的长度必须与其它列的长度保持一致,否则会报错。
插入列:如果需要在数据中插入列,则使用 df.insert(loc, column, value)
• loc 为插入列的位置
• column 为插入列的标签
• value 为插入列的值
添加行: df.loc[“新的行标签”,:] = 值
除此之外,我们还可以通过 df.append(df2) 方法添加行,但类似于数组与数组的堆叠拼接。所以df2的列索引必须同df一致。
DataFrame删除数据
法1:del df[“列标签”]
法2:df.drop(axis=0,index=None,columns=None, inplace=False) (inplace默认为False,drop不更改原数据)
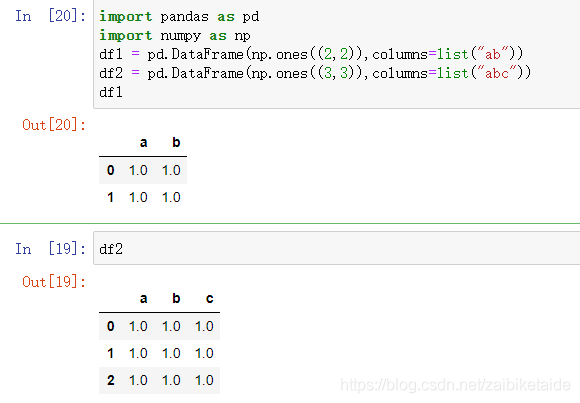
DataFrame算术
实际上,通过 + - * / // ** 等符号可以直接对DataFrame与DataFrame之间或者DataFrame以及Series之间进行运算。但秉承的原则就是对应索引运算,存在索引不同时,返回结果为索引对的并集。
但是实际操作会发现,当存在索引不同时,返回的值自动填充NaN。
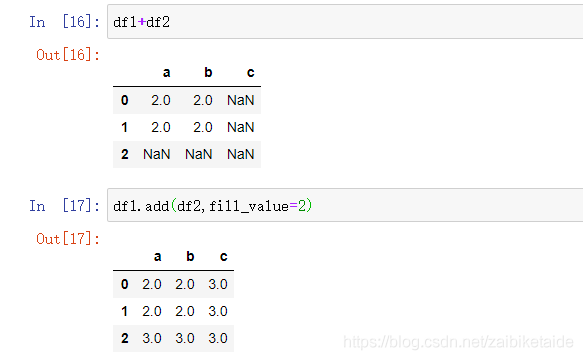
使用填充值的算术方法
| 方法 | 描述 |
|---|---|
| add | 加法(+) |
| sub | 减法(-) |
| div | 除法(/) |
| floordiv | 整除(//) |
| mul | 乘法(*) |
| pow | 幂次方(**) |
用函数和正常的加减法结果一样,但是多了一点可以填充nan的数值
注意
- Series使用算术方法,不支持指定填充值
函数应用于映射
- df.apply(func, axis=0) # 通过 apply 将函数运用到列 或者 行
- df.applymap(func) # applymap将函数应用到每个数据上
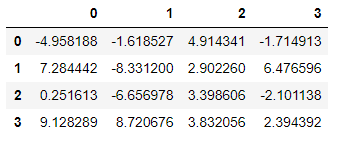
#举例 生成4*4的服从均匀分布的数组
#需求1:取出组中每行的最大值
df = pd.DataFrame(np.random.uniform(-10,10,size=(4,4)))
df
#方法1
df.max(axis=1)
#方法2
f = lambda x:x.max()
df.apply(f,axis=1)

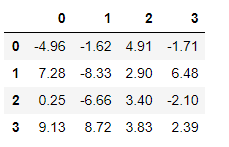
# 需求2 每个元素只保留两位小数
f2 = lambda x:"%.2f"%x
df.applymap(f2)
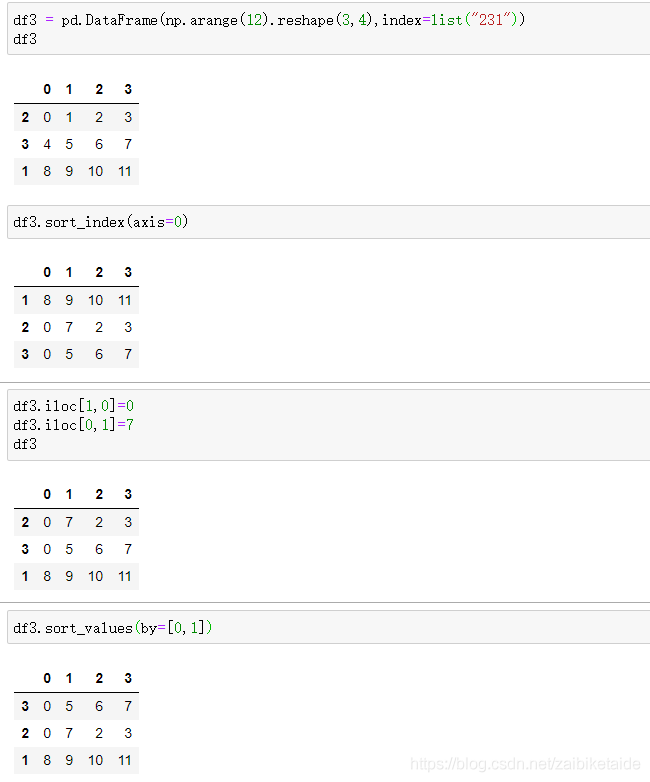
DataFrame排序
- df.sort_index(axis=0,ascending=True) # 索引排序
- axis指定轴,默认为0轴
- ascending为排序方式,默认为True表示升序
- df.sort_values(by) # 值排序
- by指定一列或多列作为排序键
注意
- by = [col1,col2] 是先给col1排序 当col1有相同值时,col2中按排序顺序再排序
描述性统计的概述和计算
| 方法 | 描述 |
|---|---|
| count | 非NA值的个数 |
| min,max | 最小值,最大值 |
| idxmin,idxmax | 最小值,最大值的标签索引 |
| sum | 求和(默认跳过nan) |
| mean | 平均值 |
| median | 中位数 |
| var | 方差 |
| std | 标准差 |
| cumsum | 累计值 |
| cummin,cummax | 累计值的最小值或最大值 |
| cumprod | 值的累计积 |
| diff | 计算第一个算术差值(时间序列,后一日减前一日) |
| pct_change | 百分比(增长率) |
| corr | 按索引对其的值的相关性 |
| cov | 协方差 |