在自定义数据集上微调Alpaca和LLaMA
本文将介绍使用LoRa在本地机器上微调Alpaca和LLaMA,我们将介绍在特定数据集上对Alpaca LoRa进行微调的整个过程,本文将涵盖数据处理、模型训练和使用流行的自然语言处理库(如Transformers和hugs Face)进行评估。此外还将介绍如何使用grado应用程序部署和测试模型。

配置
首先,alpaca-lora1 GitHub存储库提供了一个脚本(finetune.py)来训练模型。在本文中,我们将利用这些代码并使其在Google Colab环境中无缝地工作。
首先安装必要的依赖:
!pip install -U pip
!pip install accelerate==0.18.0
!pip install appdirs==1.4.4
!pip install bitsandbytes==0.37.2
!pip install datasets==2.10.1
!pip install fire==0.5.0
!pip install git+https://github.com/huggingface/peft.git
!pip install git+https://github.com/huggingface/transformers.git
!pip install torch==2.0.0
!pip install sentencepiece==0.1.97
!pip install tensorboardX==2.6
!pip install gradio==3.23.0
安装完依赖项后,继续导入所有必要的库,并为matplotlib绘图配置设置:
import transformers
import textwrap
from transformers import LlamaTokenizer, LlamaForCausalLM
import os
import sys
from typing import List
from peft import (
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
)
import fire
import torch
from datasets import load_dataset
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
from pylab import rcParams
%matplotlib inline
sns.set(rc={'figure.figsize':(10, 7)})
sns.set(rc={'figure.dpi':100})
sns.set(style='white', palette='muted', font_scale=1.2)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DEVICE
数据
我们这里使用BTC Tweets Sentiment dataset4,该数据可在Kaggle上获得,包含大约50,000条与比特币相关的tweet。为了清理数据,删除了所有以“转发”开头或包含链接的推文。
使用Pandas来加载CSV:
df = pd.read_csv("bitcoin-sentiment-tweets.csv")
df.head()
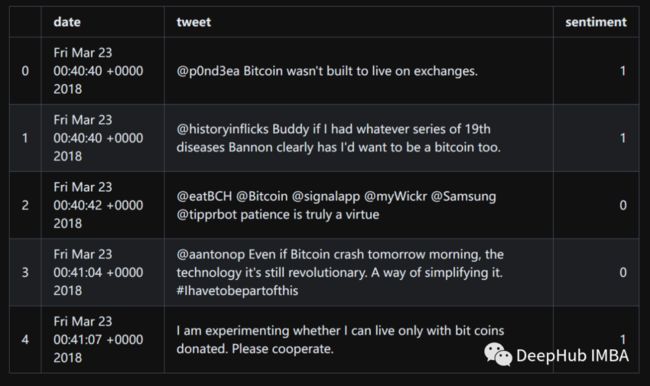
通过清理的数据集有大约1900条推文。
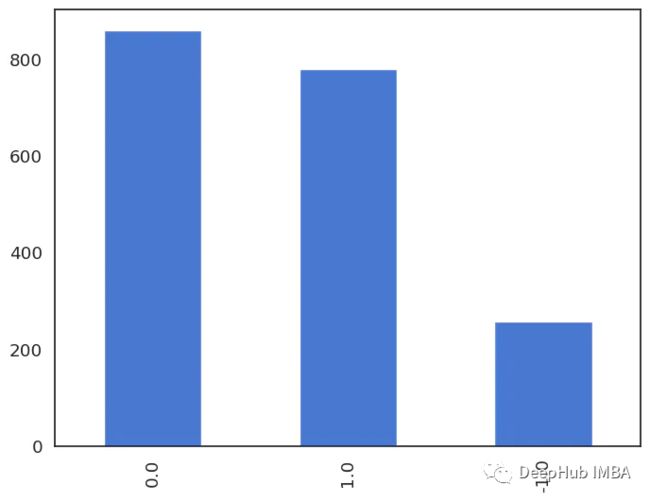
情绪标签用数字表示,其中-1表示消极情绪,0表示中性情绪,1表示积极情绪。让我们看看它们的分布:
df.sentiment.value_counts()
# 0.0 860
# 1.0 779
# -1.0 258
# Name: sentiment, dtype: int64
数据量差不多,虽然负面评论较少,但是可以简单的当成平衡数据来对待:
df.sentiment.value_counts().plot(kind='bar');
构建JSON数据集
原始Alpaca存储库中的dataset5格式由一个JSON文件组成,该文件具有具有指令、输入和输出字符串的对象列表。
让我们将Pandas的DF转换为一个JSON文件,该文件遵循原始Alpaca存储库中的格式:
def sentiment_score_to_name(score: float):
if score > 0:
return "Positive"
elif score < 0:
return "Negative"
return "Neutral"
dataset_data = [
{
"instruction": "Detect the sentiment of the tweet.",
"input": row_dict["tweet"],
"output": sentiment_score_to_name(row_dict["sentiment"])
}
for row_dict in df.to_dict(orient="records")
]
dataset_data[0]
结果如下:
{
"instruction": "Detect the sentiment of the tweet.",
"input": "@p0nd3ea Bitcoin wasn't built to live on exchanges.",
"output": "Positive"
}
然后就是保存生成的JSON文件,以便稍后使用它来训练模型:
import json
with open("alpaca-bitcoin-sentiment-dataset.json", "w") as f:
json.dump(dataset_data, f)
模型权重
虽然原始的Llama模型权重不可用,但它们被泄露并随后被改编用于HuggingFace Transformers库。我们将使用decapoda-research6:
BASE_MODEL = "decapoda-research/llama-7b-hf"
model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
tokenizer.pad_token_id = (
0 # unk. we want this to be different from the eos token
)
tokenizer.padding_side = "left"
这段代码使用来自Transformers库的LlamaForCausalLM类加载预训练的Llama 模型。load_in_8bit=True参数使用8位量化加载模型,以减少内存使用并提高推理速度。
代码还使用LlamaTokenizer类为同一个Llama模型加载标记器,并为填充标记设置一些附加属性。具体来说,它将pad_token_id设置为0以表示未知的令牌,并将padding_side设置为“left”以填充左侧的序列。
数据集加载
现在我们已经加载了模型和标记器,下一步就是加载之前保存的JSON文件,使用HuggingFace数据集库中的load_dataset()函数:
data = load_dataset("json", data_files="alpaca-bitcoin-sentiment-dataset.json")
data["train"]
结果如下:
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 1897
})
接下来,我们需要从加载的数据集中创建提示并标记它们:
def generate_prompt(data_point):
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. # noqa: E501
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:
{data_point["output"]}"""
def tokenize(prompt, add_eos_token=True):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
return_tensors=None,
)
if (
result["input_ids"][-1] != tokenizer.eos_token_id
and len(result["input_ids"]) < CUTOFF_LEN
and add_eos_token
):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(data_point)
tokenized_full_prompt = tokenize(full_prompt)
return tokenized_full_prompt
第一个函数generate_prompt从数据集中获取一个数据点,并通过组合指令、输入和输出值来生成提示。第二个函数tokenize接收生成的提示,并使用前面定义的标记器对其进行标记。它还向输入序列添加序列结束标记,并将标签设置为与输入序列相同。第三个函数generate_and_tokenize_prompt结合了前两个函数,生成并标记提示。
数据准备的最后一步是将数据集分成单独的训练集和验证集:
train_val = data["train"].train_test_split(
test_size=200, shuffle=True, seed=42
)
train_data = (
train_val["train"].map(generate_and_tokenize_prompt)
)
val_data = (
train_val["test"].map(generate_and_tokenize_prompt)
)
我们还需要数据进行打乱,并且获取200个样本作为验证集。generate_and_tokenize_prompt()函数应用于训练和验证集中的每个示例,生成标记化的提示。
训练
训练过程需要几个参数,这些参数主要来自原始存储库中的微调脚本:
LORA_R = 8
LORA_ALPHA = 16
LORA_DROPOUT= 0.05
LORA_TARGET_MODULES = [
"q_proj",
"v_proj",
]
BATCH_SIZE = 128
MICRO_BATCH_SIZE = 4
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
LEARNING_RATE = 3e-4
TRAIN_STEPS = 300
OUTPUT_DIR = "experiments"
下面就可以为训练准备模型了:
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=LORA_TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
#trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
我们使用LORA算法初始化并准备模型进行训练,通过量化可以减少模型大小和内存使用,而不会显着降低准确性。
LoraConfig7是一个为LORA算法指定超参数的类,例如正则化强度(lora_alpha)、dropout概率(lora_dropout)和要压缩的目标模块(target_modules)。
然后就可以直接使用Transformers库进行训练:
training_arguments = transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
warmup_steps=100,
max_steps=TRAIN_STEPS,
learning_rate=LEARNING_RATE,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=50,
save_steps=50,
output_dir=OUTPUT_DIR,
save_total_limit=3,
load_best_model_at_end=True,
report_to="tensorboard"
)
这段代码创建了一个TrainingArguments对象,该对象指定用于训练模型的各种设置和超参数。这些包括:
- gradient_accumulation_steps:在执行向后/更新之前累积梯度的更新步数。
- warmup_steps:优化器的预热步数。
- max_steps:要执行的训练总数。
- learning_rate:学习率。
- fp16:使用16位精度进行训练。
DataCollatorForSeq2Seq是transformer库中的一个类,它为序列到序列(seq2seq)模型创建一批输入/输出序列。在这段代码中,DataCollatorForSeq2Seq对象用以下参数实例化:
data_collator = transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
)
pad_to_multiple_of:表示最大序列长度的整数,四舍五入到最接近该值的倍数。
padding:一个布尔值,指示是否将序列填充到指定的最大长度。
以上就是训练的所有代码准备,下面就是训练了
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=training_arguments,
data_collator=data_collator
)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(
self, old_state_dict()
)
).__get__(model, type(model))
model = torch.compile(model)
trainer.train()
model.save_pretrained(OUTPUT_DIR)
在实例化训练器之后,代码在模型的配置中将use_cache设置为False,并使用get_peft_model_state_dict()函数为模型创建一个state_dict,该函数为使用低精度算法进行训练的模型做准备。
然后在模型上调用torch.compile()函数,该函数编译模型的计算图并准备使用PyTorch 2进行训练。
训练过程在A100上持续了大约2个小时。我们看一下Tensorboard上的结果:

训练损失和评估损失呈稳步下降趋势。看来我们的微调是有效的。
如果你想将模型上传到Hugging Face上,可以使用下面代码,
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("curiousily/alpaca-bitcoin-tweets-sentiment", use_auth_token=True)
推理
我们可以使用generate.py脚本来测试模型:
!git clone https://github.com/tloen/alpaca-lora.git
%cd alpaca-lora
!git checkout a48d947
我们的脚本启动的gradio应用程序
!python generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'curiousily/alpaca-bitcoin-tweets-sentiment' \
--share_gradio
简单的界面如下:

总结
我们已经成功地使用LoRa方法对Llama 模型进行了微调,还演示了如何在Gradio应用程序中使用它。
如果你对本文感兴趣,请看原文:
https://avoid.overfit.cn/post/34b6eaf7097a4929b9aab7809f3cfeaa