Redis的内存回收与内存淘汰策略
对于redis这样的内存型数据库而言,如何删除已过期的数据以及如何在内存满时回收内存是一项很重要的工作。
常见的redis内存回收的工作主要分为两个方面:
- 清理过期的key
- 在内存不足时回收到足够的内存用以存储新的key
清理过期的key
我们很少在redis中使用不带时间戳的key,因为那意味着这个key在不久之后有可能会成为死key,不为人所知,但是又占用了存储空间,这样又引出了另一个问题,不能由redis直接的去扫描过期的key并删除,这样在key的数量达到十万乃至百万级的时候,redis就会因为频繁的扫描key而陷入高CPU的不可用状态。
为了清除过期的key,redis设置特殊的策略:
- 惰性删除:如其名称,这种策略不会主动去删除过期的key,而是在客户端试图访问过期的key的时候进行删除
- 定期清除:redis有一个定时的策略会不断的抽取部分key来检查是否过期,过期的key会被清除
惰性删除
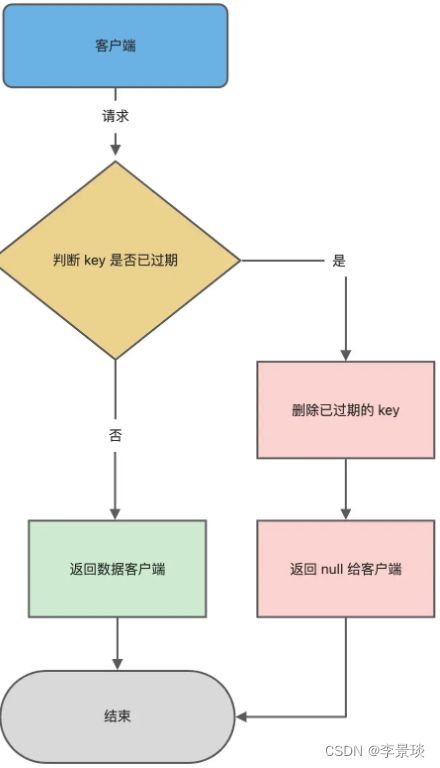
惰性删除是一个降低CPU的有效方法,将触发点放到key被访问的时候,当key被访问时,会触发一个特殊的方法expireIfNeeded,这个方法的主要内容如下所示,它的作用在于如果key过期,那么会在本次访问之后被删除。
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}大致流程如下:
- 客户端访问带时间戳的key
- 服务端检查key是否已经过期,如果已经过期,那么执行删除操作,是否是同步删除取决于参数lazyfree_lazy_expire。
- 返回客户端null
- 如果没有过期,返回客户端正常的value值。
定期清除
我们不能期望过期的key总是能够被访问到的,我们需要主动清理key的手段。但为了减少清除带来的损耗,我们不能直接扫描所有的key,redis选择随机抽取一部分key,检查是否已经过期,如果已经过期了,那么就删除掉。
redis有两种模式用于调用特定方法清理过期的key:
- 定期清理:也就是slow模式,我们将主要介绍的模式,它会定期清理过期的key,同时为了减少影响会限制每次执行的总的时间,我们可以通过配置hz参数来提高扫描频率,默认情况下值为10,即每100ms扫描一次。
- 快速清理模式:fast模式通过方法beforeSleep执行清理方法
快速清理模式
Fast模式通过于beforeSleep方法执行,当满足以下条件之一时,将通过Fast模式清理内存中的过期key,降低内存压力
- 上一次任务不是因为超时而退出,且已过期键占比近似值server.stat_expired_stale_perc小于可容忍上限config_cycle_acceptable_stale。
- 距离上一次FAST时间,未超过指定的时间间隔,默认是2000us。
定期清理
其中,随机删除的方法是activeExpireCycle,位于文件expire.c中,随机抽取的key的数量由变量config_keys_per_loop定义,它是ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP(它本身的值为20),通过特定公式计算得出,计算公式如下:
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*efforteffort(值的范围是0~9,默认为0)参数由active_expire_effort得到,它表示在抽取key的时候的力度,这个值越大意味着每次遍历时抽取的key的数量就越多,同样的,性能损耗也就越大。
大致流程如下所示:
- 从头遍历所有的库
- 对每一个库先抽取桶,再对桶中的key进行遍历,如果key已经过期,那么删除它,同时计数。
- 如果时间已经超过限制,直接结束循环
- 如果循环的key的数量已经超过了限制,那么继续抽取当前库,直至时间达到限制或者过期率降低至期望以下
这个特定值表示在当前数据库中需要抽取的key的数量,config_cycle_acceptable_stale的值的大小由公式:
config_cycle_acceptable_stale=ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE - effort计算得到,其中ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE的值为10,在代码中写死。
再根据下面的公式:
do {
//抽取key并删除过期key
...
} while (sampled == 0 || (expired*100/sampled) > config_cycle_acceptable_stale);我们不难发现,默认情况下,当实际抽取的桶的数量和被释放的key的数量的比值大于10的时候,就会认定为当前数据库的过期key的数量过多,从而触发再一次的回收。
这里的回收也并不是没有时间限制的,为了减少对用户的影响,当执行时间超过某个特定值时,会直接退出本次收集,这个时间由参数timelimit确定,这个参数的计算公式为config_cycle_slow_time_perc*1000000/server.hz/100,单位为us,其中hz由参数CONFIG_DEFAULT_HZ和配置文件共同确定,默认为10,config_cycle_slow_time_perc由下面的公式确定,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC参数用于确定最大的CPU占比,默认为25
即默认情况下,一次定期扫描不允许超过25ms。
内存已满时淘汰key以回收内存
我们知道,如果对redis需要的内存预估错误,那么需要写入的时候就有可能会将redis的内存打满,我们可以通过配置特定的策略来处理当redis内存满的时候应当怎么做。
可选的策略有以下几种:
- noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外),试图写入新数据时会产生OOM异常
- allkeys-lru:从所有key中使用LRU算法进行淘汰
- volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰
- allkeys-random:从所有key中随机淘汰数据
- volatile-random:从设置了过期时间的key中随机淘汰
- volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
不淘汰-只产生异常
这是默认的选项,使用这种策略意味着不会对任意的key进行淘汰,但由于内存已满也无法再写入任何新的数据。
看上去会产生一定的异常,但是它有它优势,它的优势在于,不会产生任何意料之外的淘汰操作,从而避免热点key意外被淘汰,导致出现缓存击穿的现象。
淘汰key回收内存
对于需要淘汰的数据,我们可以从数据范围和筛选数据的方法方面选择需要淘汰的key进行淘汰:
从数据范围讲,根据key是否带时间戳可以分为:
- 从设置了过期时间的key中挑选需要淘汰的key
- 从所有的key中挑选需要淘汰的key
从筛选方法方面,根据算法的不同可以分为:
- 随机淘汰key
- 通过LRU算法进行淘汰
- 通过LFU算法进行淘汰
需要注意的是,不论是哪种淘汰方法,需要淘汰的key的数量都是可以配置的
随机淘汰没什么好说的,就是从数据范围中随机取出N个key淘汰掉
近似LRU
严格的LRU算法是需要将所有需要管控的数据都纳入到一个链表中,每当有访问的就移动到最前面,总是淘汰链表末尾的数据
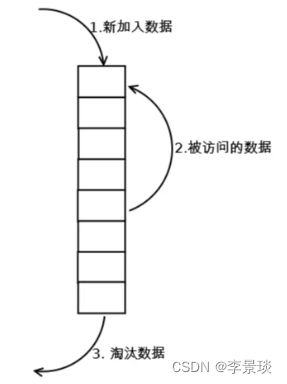
但是传统的LRU算法也有它的问题:
- 需要用链表管理所有的缓存数据,这会带来额外的空间开销;
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
redis选用近似的LRU算法,放弃了链表式的结构以此来最大限度的减少算法执行过程中的性能损耗。
redis对象内部维护了一个特殊的字段,针对不同的回收策略会有不同的用处,对于LRU来讲,它是一个24位的时钟,记录对象保存到redis的时间,对于LFU算法而言,它是用来保存访问时间以及频率的字段。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;因为不维护字段,所以对于需要淘汰的key的选拔是通过在数据范围内,随机筛选出N(可配置)个key,选择最旧的一个数据淘汰掉,这样做的优势在于能够节省在损耗过程中的性能损耗。
对比严格LRU算法,它的优势在于:
- 节省了保存链表的空间
- 降低了频繁移动表节点带来的CPU的损耗
它的问题在于,近似始终是近似,在效果上必然不如严格LRU算法那么精确。
如下图所示,在选取数为10的情况下,可以看到是大多数古老的key是已经被淘汰的,同时对新的key影响也比较低,与严格LRU效果已经接近,已经足够满足我们的需求。
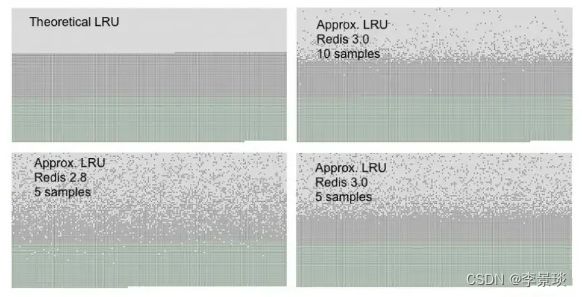
近似LFU算法也有LFU算法的固有问题,就是LFU实际上只有时间的概念,它是没有热度这个说法的,也就是说,我们在淘汰过程中很可能会淘汰掉一个热点key,或者在大批新的数据写入时,会影响对旧数据的判断。
LFU算法
我们之前提到,redis的对象中维护了一个字段,在回收算法是LFU的时候,这个字段的作用在于记录最近访问时间以及频率,这是一个24位的字段,它的前16位用于记录时间,后8位则记录频率。

增长策略
counter并不是简单的访问一次就+1,而是采用了一个0-1之间的p因子控制增长。counter最大值为255。取一个0-1之间的随机数r与p比较,当r 既然与热度相关,那么自然就会有降低的策略,下降的周期也可以通过参数配置,配置的含义在于每过多久下降1,这样下次计算时可以通过时间差直接计算出当前的key下降后的热度。 下面是LFU算法的热度增长代码: 可以看到,对于任意的key,它的热度越高,计算得到的允许热度上涨的p就越小,热度上升就需要更多次的访问,同时还可以通过lfu_log_factor参数来控制增长速率,它的值越大,增长速度就越小。降低策略
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}