数据仓库表设计理论
数据仓库表设计理论
数仓顾名思义是数据仓库,其数据来源大多来自于业务数据(例如:关系型数据库),当设计数仓中表类型时(拉链表、增量表、全量表、流水表、切片表)时,应先观察业务数据的特点再设计数仓表结构
首先业务数据是会不断增长的-即增量,而在不断增长的前提下业务数据又可以分为两类:
- 增量更新数据源:数据源允许新增、修改和删除操作的数据源
- 增量非更新数据源:数据源只允许新增数据,不允许对历史数据进行修改的数据源
业务数据中的这两种数据源类型直接决定了数仓中的表设计的选择
一、增量更新数据源
增量更新数据源是指允许新增、修改和删除操作的数据源。这种数据源的主要特点是:
- 数据可修改:可以对历史数据进行修改、覆盖,以反映数据的变更。
- 实时性高:由于数据可以随时更新,具有很强的实时性和即时性。
常见的增量更新数据源包括关系型数据库、NoSQL数据库、文件系统等,它们都支持对数据进行新增、修改和删除操作。
示例:关系型数据库中的用户表,其手机号字段经常会出现修改
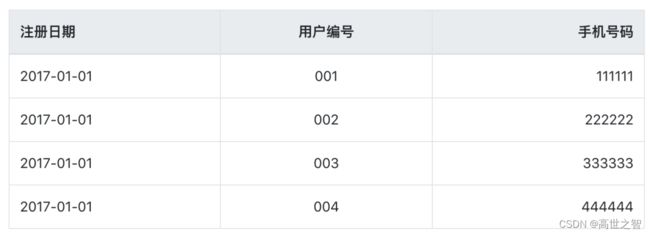
在2017-01-02这一天表中的数据是, 用户002和004资料进行了修改,005是新增用户:
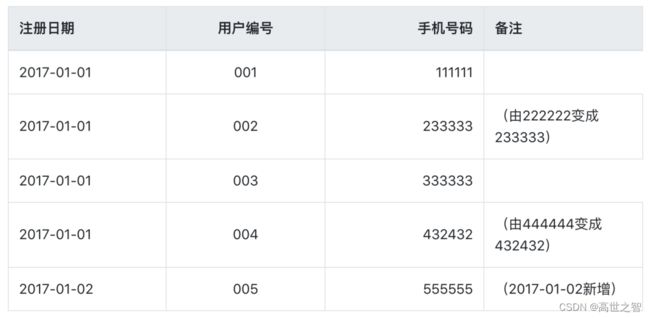
针对这类数据源,我们将分别阐述下数仓中的各种类型的表设计
1.1、全量表
全量表就是存储了全部数据的表,没有分区之分,可以理解为总共就一个分区。
全量表中存储了截至目前为止最新状态的全部记录,这就表示会存在历史状态的更新。
1.1.1、场景
以业务数据-用户表为例,2020-06-01有三个用户注册,表如下:

2020-06-02有一名用户注册,即新增了一名用户(标红),此时数仓中全量表更新后会记录全量的数据,此时数据表如下:

1.1.2、实现方式
全量表的实现方式又分为两种:
- 全量替换:直接获取全表业务数据替换昨日全量单表
- join替换:通过合并:每日增改数据的临时表 或 流水表,重写后得到全新全量表
1.1.2.1、全量替换
-- 创建一张新的全量单表
CREATE TABLE new_table (col1 STRING, col2 INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/hive/warehouse/new_table';
-- 将全部的业务数据导入至全量单表, 过程不赘述
insert into new_table ..........
-- 将新表名替换为旧表名
ALTER TABLE old_table RENAME TO old_table_backup;
ALTER TABLE new_table RENAME TO old_table;
-- 删除昨日全量单表
DROP TABLE old_table_backup;
1.1.2.2、join替换
注意:业务数据需要有唯一的ID 和 upadte_time,否则无法使用join替换。
-- 创建一张新的临时增量表
CREATE TABLE incremental_table (id INT, column1 STRING, column2 STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/hive/warehouse/incremental_table';
-- 将增量数据加载到一个临时表中,一般是通过业务数据的update_time来区分哪些是增量数据
insert into incremental_table xxxx
-- 使用LEFT JOIN语句将原表和增量数据合并
SELECT COALESCE(i.id, o.id) as id,
COALESCE(i.column1, o.column1) as column1,
COALESCE(i.column2, o.column2) as column2,
...
FROM original_table o
LEFT JOIN incremental_table i
ON o.id = i.id;
-- 这将生成一个包含原表和增量数据的JOIN结果。在上面的例子中,我们使用了COALESCE函数来选择非空值,以便我们可以从原表和增量数据中选择最新的值。
-- 最后,我们可以使用INSERT OVERWRITE语句将合并后的数据插入到原表中
INSERT OVERWRITE TABLE original_table
SELECT COALESCE(i.id, o.id) as id,
COALESCE(i.column1, o.column1) as column1,
COALESCE(i.column2, o.column2) as column2,
...
FROM original_table o
LEFT JOIN incremental_table i
ON o.id = i.id;
总结:全量表设计的优势是不会占用太多磁盘空间;弊端也很明显-不支持历史记录溯源
1.2、增量表
增量表是指只负责追加新的数据记录,而不负责历史数据更改记录,新的数据记录保存在新分区中,历史分区中的数据记录不发生变化。
增量表并不适用增量更新数据源,只适用于增量非更新数据源。
1.3、快照表
快照表是用来存储某个时间点的所有数据-通常粒度是天,相当于是对每天的业务数据做了一次快照,存储当天的全量数据!
- 例如:快照表中某个分区内的数据是历史到此分区前一天的所有数据,如12号分区中的数据是从历史到11号的所有数据,13号分区中的数据是从历史到12号的所有数据,其他的以此类推。
1.3.1、场景
也可以理解为:每天将业务数据的全量数据存储至数仓-快照分区表的当天分区内,这里假设分区的粒度是天
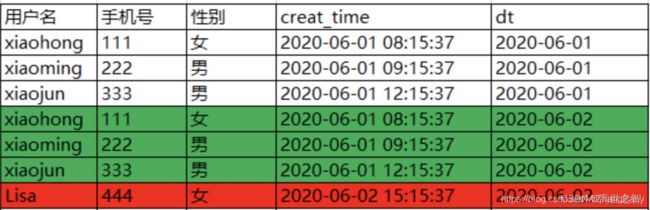
以业务数据-用户表为例,2020-06-01有三个用户注册,表如下:

2020-06-02有一名用户注册,即新增了一名用户(标红),此时数仓中快照分区表更新后2020-06-02分区内会记录全量的数据,包括2020-06-01的用户数据(标绿),此时快照表如下:
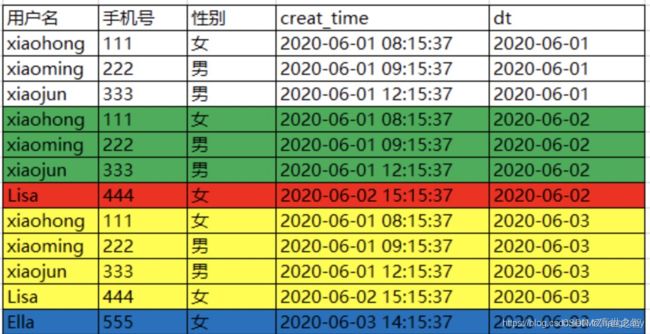
同理,2020-06-03又有2名用户注册,即新增了1名用户(标蓝),此时数仓中快照分区表更新后2020-06-03分区内会记录全量数据,即包含2020-06-02的用户数据(标黄),此时快照表如下:
1.3.2、实现
先将业务数据全部同步至hive临时表中,随后将hive临时表的业务数据放置在快照分区表的今日分区内:
-- 创建一个新hive临时表,存放当日业务的全量数据
CREATE TABLE temp_table (col1 STRING, col2 INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/hive/warehouse/temp_table';
-- 将全部的业务数据导入至hive临时表, 过程不赘述
insert into temp_table ..........
-- 使用INSERT INTO语句将临时表中的数据插入到全量分区表的目标分区中:
INSERT INTO original_table PARTITION (date='2023-05-08')
SELECT * FROM temp_table;
-- 删除hive临时表
DROP TABLE temp_table;
总结:此方式便是快照表,该设计的弊端很明显:会大量占用磁盘空间,故并不推荐使用
1.4、流水表
流水表是用于记录数据变更的表,理论上是对于表的每一个修改都会记录,但在实际应用中通常按天为粒度划分,例如流水表中的2017-01-02分区只记录这一天新增和修改的业务数据,这样可以方便地追溯、计算和分析历史数据,同时也提供了可靠的数据源供其他表和报告使用。
1.4.1、场景
还是用user用户数据举例,2017-01-01这一天表中的数据是:
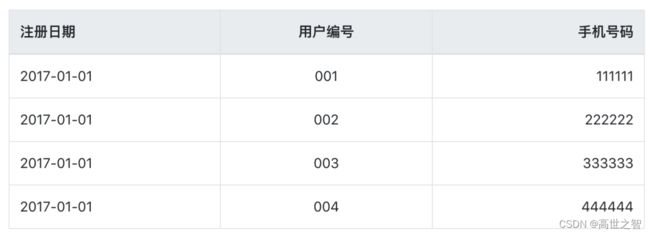
此时流水表的数据为:
| 注册日期 | 用户编号 | 手机号码 | dt-时间分区字段 |
|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 |
在2017-01-02这一天表中的数据是, 用户002和004资料进行了修改,005是新增用户:
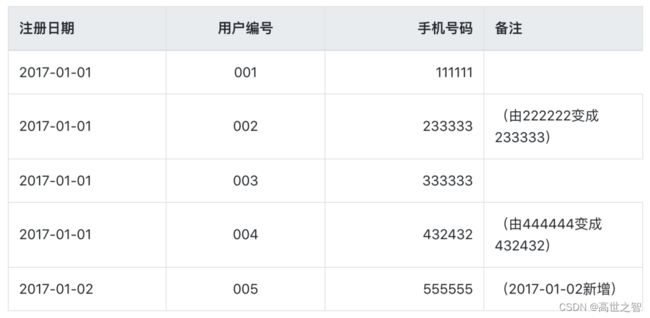
此时流水表的数据为:
| 注册日期 | 用户编号 | 手机号码 | dt-时间分区字段 |
|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 |
| 2017-01-01 | 002 | 233333 | 2017-01-02 |
| 2017-01-01 | 004 | 432432 | 2017-01-02 |
| 2017-01-02 | 005 | 555555 | 2017-01-02 |
1.4.2、实现
-- 创建一个user_update_temp临时表,用于存放当日业务的增量数据
CREATE EXTERNAL TABLE ods.user_update_temp (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期'
)
COMMENT '每日用户资料更新表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/ods/user_update';
-- 创建一张流水表,用来存储每天变化数据
CREATE EXTERNAL TABLE dws.user_stream (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期'
)
COMMENT '用户流水表'
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/dws/orders';
-- 通过业务字段update_time将2017-01-02变化的业务数据导入至user_update_temp临时表,过程不赘述
INSERT OVERWRITE ods.user_update_temp .........
-- 使用INSERT INTO语句将ods.user_update中的数据插入到流水表中2017-01-02分区中:
INSERT INTO dws.user_stream PARTITION (dt='2017-01-02')
SELECT * FROM ods.user_update_temp;
注意:流水表很容易和增量表的概念混淆,这里再强调一下:增量表只适用于增量非更新数据源,只负责新增数据,对于历史数据的修改并不记录;而流水表通常用于记录数据变更,包括新增、修改和删除等操作,以便跟踪每个事实或维度的历史变化。为了方便管理和查询,通常将流水表按时间分区。
1.5、拉链表
拉链表是一种维护历史状态以及最新状态数据的表。与快照表类似,算是在快照表的基础上去除了重复状态的数据,也就是一些不变的信息在快照表中每个分区都存储一份,使用拉链表在更新频率和比例不是很大的情况下会十分节省存储。
1.5.1、场景
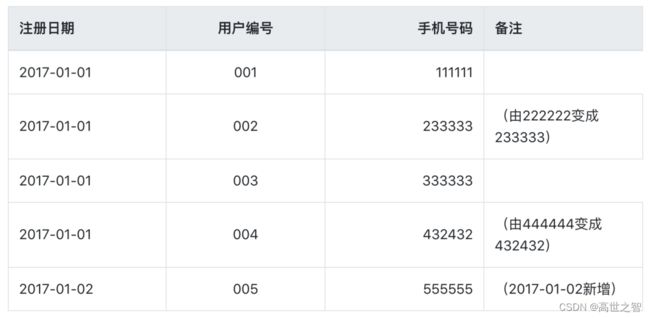
现在以用户的拉链表来说明2017-01-01这一天表中的数据是:

在2017-01-02这一天表中的数据是, 用户002和004资料进行了修改,005是新增用户:
在2017-01-03这一天表中的数据是, 用户004和005资料进行了修改,006是新增用户:
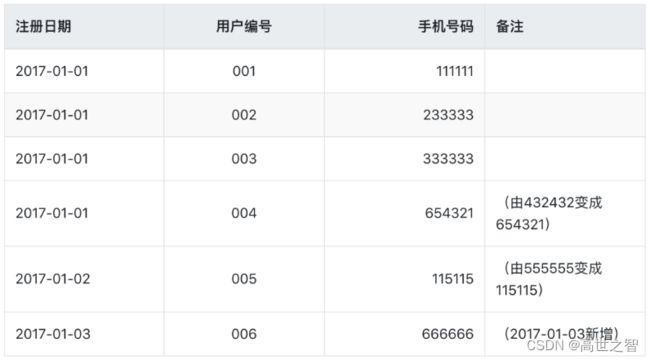
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表,这是最新一天(即2017-01-03)的数据:
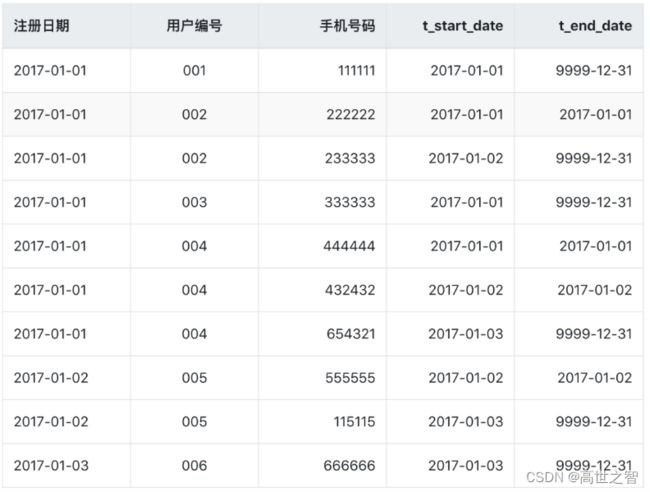
说明
- t_start_date表示该条记录的生命周期开始时间,t_end_date表示该条记录的生命周期结束时间
- t_end_date = '9999-12-31’表示该条记录目前处于有效状态
- t_end_date = '2017-01-02’表示该条记录在2017-01-02当日是有效的,在当前日期是无效的
- 如果查询当前所有有效的记录,则select * from user where t_end_date = ‘9999-12-31’
- 如果查询2017-01-02的历史快照,则select * from user where t_start_date <= ‘2017-01-02’ and t_end_date >= ‘2017-01-02’。(此处要好好理解,是拉链表比较重要的一块)
- 解释上一条sql:需求是要查2017-01-02的历史快照,t_start_date是代表这条记录的开始时间,并非是原始数据的时间,例如001用户数据在2017-01-02也有效,故t_start_date <= ‘2017-01-02’;而t_end_date = '2017-01-02’表示该条记录在2017-01-02当日是有效的,又因为t_end_date = '9999-12-31’表示该条记录目前处于有效状态,所以t_end_date >= ‘2017-01-02’
该sql查询结果如下:
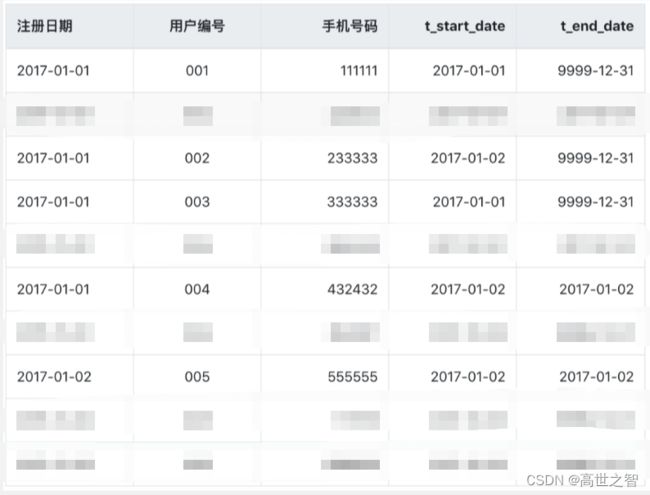
和下图2017-01-02的业务数据比较,结果完全一致:

1.5.2、实现
创建拉链表的前提是先根据全量数据表创建初始拉链表,然后再根据每天的增改数据进行合并更新拉链表;
还是以上面的用户表为例,我们要实现用户的拉链表,在实现它之前,我们需要先确定一下我们有哪些数据源可以用。
- 我们需要一张ODS层的用户全量表。至少需要用它来初始化。
- 流水表-记录每日增改数据。
建表语句:
-- 先创建一张全量表用于初始化
CREATE EXTERNAL TABLE ods.user (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期'
) COMMENT '用户资料表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/ods/user';
-- 最后我们创建一张拉链表:
CREATE EXTERNAL TABLE dws.user_his (
user_num STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
reg_date STRING COMMENT '注册日期',
t_start_date STRING COMMENT '资料开始日期',
t_end_date STRING COMMENT '资料结束日期'
) COMMENT '用户资料拉链表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/dws/user_his';
数据初始化:我们以2017-01-01的数据作为初始化数据
-- 假设ods.user表已经存储了2017-01-01的全量数据,此时拉链表的初始化sql:
INSERT OVERWRITE TABLE dws.user_his
SELECT user_num, mobile, reg_date, '2017-01-01', '9999-12-31'
FROM ods.user;
初始化后的拉链表数据如下:
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
|---|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 | 9999-12-31 |
数据更新:我们以2017-01-02的数据更新拉链表;
2017-01-02日的流水表数据如下:
| 注册日期 | 用户编号 | 手机号码 | dt-时间分区字段 |
|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 |
| 2017-01-01 | 002 | 233333 | 2017-01-02 |
| 2017-01-01 | 004 | 432432 | 2017-01-02 |
| 2017-01-02 | 005 | 555555 | 2017-01-02 |
-- 2017-01-02拉链表更新sql:
INSERT OVERWRITE TABLE dws.user_his
SELECT *
FROM
(
SELECT A.user_num,
A.mobile,
A.reg_date,
A.t_start_date,
CASE
WHEN A.t_end_date = '9999-12-31' AND B.user_num IS NOT NULL THEN '2017-01-01'
ELSE A.t_end_date
END AS t_end_date
FROM dws.user_his AS A
LEFT JOIN dws.user_stream AS B WHERE dt = '2017-01-02'
ON A.user_num = B.user_num
UNION
SELECT C.user_num,
C.mobile,
C.reg_date,
'2017-01-02' AS t_start_date,
'9999-12-31' AS t_end_date
FROM dws.user_stream AS C WHERE dt = '2017-01-02'
) AS T;
更新后的拉链表数据如下:
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
|---|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 | 2017-01-01 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 | 2017-01-01 |
| 2017-01-01 | 002 | 233333 | 2017-01-02 | 9999-12-31 |
| 2017-01-01 | 004 | 432432 | 2017-01-02 | 9999-12-31 |
| 2017-01-02 | 005 | 55555 | 2017-01-02 | 9999-12-31 |
-- 查询有效数据:
select * from dws.user_his where t_end_date = '9999-12-31'
查询有效数据结果:
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
|---|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 002 | 233333 | 2017-01-02 | 9999-12-31 |
| 2017-01-01 | 004 | 432432 | 2017-01-02 | 9999-12-31 |
| 2017-01-02 | 005 | 55555 | 2017-01-02 | 9999-12-31 |
-- 查询2017-01-01历史数据:
select * from dws.user_his where t_start_date <= '2017-01-01' and t_end_date >= '2017-01-01'
2017-01-01历史数据:
| 注册日期 | 用户编号 | 手机号码 | t_start_date | t_end_date |
|---|---|---|---|---|
| 2017-01-01 | 001 | 111111 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 002 | 222222 | 2017-01-01 | 2017-01-01 |
| 2017-01-01 | 003 | 333333 | 2017-01-01 | 9999-12-31 |
| 2017-01-01 | 004 | 444444 | 2017-01-01 | 2017-01-01 |
1.6、切片表
切片表根据基础表,往往只反映某一个维度的相应数据。其表结构与基础表结构相同,但数据往往只有某一维度,或者某一个事实条件的数据;切片表以某个维度或者一些特定的条件对事实进行汇总计算,并展示为一个交叉分析的表格。与事实表相比,切片表的数据更加聚合,只包含某些维度或者满足某些特定条件的数据。
1.6.1、场景
假设我们有一个基础表(也称为事实表),记录了一家公司的销售订单信息。该表包含以下字段:订单ID、客户ID、产品ID、销售日期、销售数量和销售额等。
| 订单ID | 客户ID | 产品ID | 销售日期 | 销售数量 | 销售额 |
|---|---|---|---|---|---|
| 1 | 1001 | 2001 | 2022-01-01 | 3 | 150 |
| 2 | 1002 | 2002 | 2022-01-02 | 2 | 80 |
| 3 | 1003 | 2001 | 2022-01-03 | 1 | 50 |
| 4 | 1001 | 2003 | 2022-01-04 | 5 | 250 |
| 5 | 1002 | 2002 | 2022-01-05 | 4 | 160 |
在这张表中,客户端ID、产品ID、销售日期是维度,而销售数量、销售额是事实。
现在我们希望按照客户维度创建一个切片表,以便分析每个客户的销售情况。
具体来说,我们需要选择客户维度,并对销售数量和销售额这两个度量进行聚合计算,通过多维分析工具或者SQL查询,可以生成如下的切片表:
| 客户ID | 销售数量总计 | 销售额总计 |
|---|---|---|
| 1001 | 8 | 400 |
| 1002 | 6 | 240 |
| 1003 | 1 | 50 |
在这个切片表中,我们只选择了客户维度,然后,我们使用SUM函数对每个客户的销售数量和销售额进行聚合计算,以便更好地分析不同客户之间的销售情况。
1.6.2、实现
在数据仓库中,切片表的存储方式可以根据不同的需求和性能要求而定,一般来说有以下两种常用的存储方式:
- 全量替换:每次运行ETL作业时,都会重新生成整个切片表,并将其覆盖原有的数据。这种方式适用于数据量较小、更新频率低的场景,或者需要保证数据完整性和一致性的场景。
- 按照天的粒度进行划分:将切片表按照时间维度(如日、周、月等)进行分区,每个分区存储一段时间内的数据。这种方式适用于数据量较大、更新频率高的场景,或者需要快速查询历史数据的场景。
无论采用哪种存储方式,都需要考虑切片表的设计问题。具体来说,以下是一些设计上的注意点:
- 维度表的设计:维度表应该是离线化的静态数据,它们应该是变化不大并且计算时被缓存在内存中,以便提高查询性能。因此,在设计维度表时,应该尽可能地避免经常变化的属性。
- 表结构的优化:为了提高查询效率,应该尽可能地减少JOIN操作,尽量将不同维度的数据存储在同一个表中。如果必须进行JOIN操作,则应该尽可能地使用分区表或者基于列存储的数据库,以便提高查询性能。
- 时间分区:如果采用按照天的粒度进行划分的方式,那么需要将切片表按照时间维度进行分区,并且使用分区键作为查询条件。这样可以大大提高查询性能,同时也方便进行数据备份和恢复。
总之,在设计和实现切片表时,需要考虑不同的因素,包括数据量、更新频率、查询性能、数据一致性等等,以便得出最优的解决方案。
这里以全量替换举例:
-- 按照上面的例子,假设有一个名为sales_order的基础表
CREATE TABLE sales_order (
order_id int,
customer_id int,
product_id int,
sale_date date,
quantity int,
amount double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 我们可以将原始数据加载到sales_order表中
LOAD DATA INPATH 'path/to/sales.csv' OVERWRITE INTO TABLE sales_order;
-- 接下来,我们可以使用INSERT INTO SELECT语句来创建切片表customer_sales,并将数据按照客户维度进行聚合计算:
CREATE TABLE customer_sales (
customer_id int,
total_quantity int,
total_amount double
)
AS
SELECT
customer_id,
SUM(quantity) as total_quantity,
SUM(amount) as total_amount
FROM sales_order
GROUP BY customer_id;
-- 这里采用了全量替换的方式,每次重新运行上面的SQL语句都会完全替换customer_sales表中的数据。
二、增量非更新数据源
当数据源只允许新增数据,不允许对历史数据进行修改时,我们称之为增量不更新数据源。这种数据源的主要特点是:
- 数据只能增长:无法对历史数据进行修改、删除或覆盖,只能追加新的数据。
- 数据变更历史保留:由于数据源只追加新的数据,因此可以完整地保留数据的变更历史,便于后续的分析和回溯。
- 数据量大:由于数据只能增长,因此数据量通常会随着时间的推移而不断增加。
- 实时性高:由于数据是实时生成的,具有很强的实时性和即时性。
常见的增量不更新数据源包括:
- 日志数据:日志数据是指记录了系统或应用程序操作的信息的数据。由于日志数据一般是只追加不修改,所以可以视为增量不更新数据源。
- 传感器数据:传感器数据是指由各种传感器采集的环境、设备或系统状态数据等。这些数据也是只追加不修改的,因此可以视为增量不更新数据源。
- 消息系统数据:消息系统数据是指通过消息队列、主题或流处理框架等收集的异步消息数据。与日志数据和传感器数据类似,这些数据也是只追加不修改的。
- 用户活动数据:用户活动数据是指记录了用户在应用程序中进行的各种操作和行为的数据。由于这些数据通常无法修改,因此也可以视为增量不更新数据源。
在设计数据模型和存储方案时,需要考虑到数据源的特点,以便满足快速查询和分析的需求,一般来说,可以采用以下策略:
- 使用列式存储:由于增量不更新数据源的数据一般只用于查询和分析,因此可以采用列式存储方式,以提高查询性能。
- 考虑分区:根据数据源的特点,可以将数据按照时间、地理位置等因素进行分区,以便更快地查询历史数据。
- 超大表设计:由于增量不更新数据源的数据量很大,因此需要考虑超大表的设计问题。例如,可以使用分区表、分布式存储等技术来支持数据的高效存储和查询。
2.1、全量表
对于增量不更新数据源,使用全量表进行处理可能会导致性能问题和资源浪费,因为全量表需要重新加载所有数据,并进行完全替换,这将消耗大量的计算资源和时间。
相反,使用增量表可以更有效地处理增量不更新数据源,因为增量表只包含最近追加的数据,并且每次只需要更新最新的增量数据即可。这样,可以避免重复加载和处理历史数据,从而提高处理效率和减少资源消耗。
2.2、增量表
增量表可以高效地处理增量不更新数据源,因为增量表只包含最新的新增数据,并且每次只需要更新最新的增量数据即可。这样,可以避免重复加载和处理历史数据,从而提高处理效率和减少资源消耗。
增量表通常按天为粒度
2.2.1、场景
假设我们有一个传感器监测系统,每个传感器会在固定时间间隔内生成一些数据。这些数据在产生后不会被更改。我们需要设计一个增量表来处理这些传感器数据,并按天分区管理数据。
原始数据格式展示:
| 字段名称 | 数据类型 | 说明 |
|---|---|---|
| sensor_id | INT | 传感器ID |
| timestamp | TIMESTAMP | 时间戳 |
| value | FLOAT | 数据值 |
14号原始数据:
| sensor_id | timestamp | value |
|---|---|---|
| 1 | 2023-05-14 10:00:00 | 23.5 |
| 2 | 2023-05-14 10:00:00 | 18.2 |
| 3 | 2023-05-14 10:00:00 | 25.0 |
| 4 | 2023-05-14 11:00:00 | 24.0 |
| 5 | 2023-05-14 11:00:00 | 18.4 |
此时我们设计一个名为sensors_incremental的增量表,用于存储每天新增的传感器数据,并按照日期进行分区。该表包含了四个字段:sensor_id、timestamp、value和dt(时间分区字段)。
增量表初始数据展示如下:
| sensor_id | timestamp | value | dt(时间分区字段) |
|---|---|---|---|
| 1 | 2023-05-14 10:00:00 | 23.5 | 2023-05-14 |
| 2 | 2023-05-14 10:00:00 | 18.2 | 2023-05-14 |
| 3 | 2023-05-14 10:00:00 | 25.0 | 2023-05-14 |
| 4 | 2023-05-14 11:00:00 | 24.0 | 2023-05-14 |
| 5 | 2023-05-14 11:00:00 | 18.4 | 2023-05-14 |
第二天原始数据如下:
| sensor_id | timestamp | value |
|---|---|---|
| 1 | 2023-05-14 10:00:00 | 23.5 |
| 2 | 2023-05-14 10:00:00 | 18.2 |
| 3 | 2023-05-14 10:00:00 | 25.0 |
| 3 | 2023-05-14 11:00:00 | 24.0 |
| 5 | 2023-05-14 11:00:00 | 18.4 |
| 6 | 2023-05-15 11:00:00 | 25.2 |
| 7 | 2023-05-15 12:00:00 | 23.8 |
| 8 | 2023-05-15 12:00:00 | 18.6 |
| 9 | 2023-05-15 12:00:00 | 25.5 |
第二天增量表sensors_incremental数据:
| sensor_id | timestamp | value | dt(时间分区字段) |
|---|---|---|---|
| 1 | 2023-05-14 10:00:00 | 23.5 | 2023-05-14 |
| 2 | 2023-05-14 10:00:00 | 18.2 | 2023-05-14 |
| 3 | 2023-05-14 10:00:00 | 25.0 | 2023-05-14 |
| 4 | 2023-05-14 11:00:00 | 24.0 | 2023-05-14 |
| 5 | 2023-05-14 11:00:00 | 18.4 | 2023-05-14 |
| 6 | 2023-05-15 1100:00 | 25.2 | 2023-05-15 |
| 7 | 2023-05-15 12:00:00 | 23.8 | 2023-05-15 |
| 8 | 2023-05-15 12:00:00 | 18.6 | 2023-05-15 |
| 9 | 2023-05-15 12:00:00 | 25.5 | 2023-05-15 |
2.2.2、实现
-- 创建增量表
CREATE TABLE sensors_incremental (
sensor_id INT,
timestamp TIMESTAMP,
value FLOAT
)
PARTITIONED BY (day DATE)
STORED AS PARQUET;
-- 将原始数据加载到sensors_temp临时表中
LOAD DATA INPATH 'path/to/sensors.csv' OVERWRITE INTO TABLE sensors_temp;
-- 将临时表数据初始化加载进增量表
INSERT INTO sensors_incremental PARTITION (date='2023-05-14') SELECT * FROM sensors_temp;
-- 第二天将15号临时表数据加载进增量表
INSERT INTO sensors_incremental PARTITION (date='2023-05-15') SELECT * FROM sensors_temp;
通过使用以上增量表设计和相应的SQL语句,我们可以有效地处理传感器数据,并实现按天分区的管理和查询。
2.3、快照表
快照表同样适用于增量非更新数据源,快照表是用来存储某个时间点的所有数据-通常粒度是天,相当于是对每天的业务数据做了一次快照,存储当天的全量数据!
其设计和实现与增量更新数据源保持一致,详细参考:1.1.3、快照表
2.4、流水表
流水表同样适用于增量不更新数据源,流水表是用于记录数据变更的表,流水表如果是按天为粒度划分,那和增量表几乎一模一样,因为不涉及到数据的修改,故增量非更新数据源下的流水表和增量表的数据几乎保持一致。
其设计和实现与增量更新数据源保持一致,详细参考:1.1.4、流水表
2.5、拉链表
拉链表同样适用于增量不更新数据源,其设计和实现与增量更新数据源保持一致,详细参考:1.1.5、拉链表
2.6、切片表
切片表是根据事实数据生成的维度表,故同样适用于增量不更新数据源,其设计和实现与增量更新数据源保持一致,详细参考:1.1.6、切片表
三、总结
增量表、全量表、快照表、拉链表、切片表和流水表都是常用的数据表格设计方式,每种表格设计方式都有自己的优劣势和适用场景。
- 增量表:只记录新增或更改操作的数据表,可以减少存储和处理开销,适用于高频产生新增事件的情况。
- 全量表:记录所有数据的完整表格,可以提供准确的数据,但无法提供历史溯源记录
- 快照表:记录某个时间点的部分或全部数据,可用于数据快照和查询。通常使用在查询性质的报表系统中。
- 拉链表:记录数据变化的时间范围。适用于需要准确跟踪数据变化的场景,例如会计系统。
- 切片表:记录具有多维度属性的实体,例如客户、产品等,适用于类似于分析型场景。
- 流水表:记录所有事件(包括新增、删除、修改等),可以追溯完整的历史信息,适用于审计和数据分析以及为其他类型的表提供数据源
总体而言,以上的表格设计方式都有其自身的优缺点以及适用场景,应根据具体的业务需求进行合理选择。