数据治理设计理论
数据治理设计理论
一、数据治理基本概念
1、数据治理介绍
数据治理是一种综合性的、系统性的数据管理过程,旨在确保组织内的数据质量、安全性、可用性和合规性。数据治理的目标是建立健康的数据管理体系,使组织能够更好地管理、维护和利用数据资源。
数据治理是一个很广泛的概念,不仅仅局限于数据本身,深入探究还涉及开发人员与业务人员的岗位分工是否合理等问题;
碍于篇幅,本文主要讲述数据仓库领域(Hive)数据治理。
2、数仓数据治理方向(重要)
在数仓数据治理中,通常包括以下几个关键方向:
- 数仓分层:数据仓库分层是将数据仓库架构划分为不同的层级,如ODS、DWD、DIM、DWS、ADS等,每个层级承担不同的功能和任务,以便更好地处理和管理数据。
- 数据建模:数据建模是数据仓库设计的基础,它涉及选择业务过程、声明粒度、确认维度和确认事实等步骤,以确定数据仓库中的数据结构和关系模式。
- 表设计:表设计是在数据建模的基础上,选择全量表、增量表、流水表、拉链表等类型,考虑存储和查询效率、灵活性和可扩展性。
- 血缘关系:血缘关系是指数据在不同层级之间的关系,通常跨越了数据仓库中的各个数据层。血缘关系记录了数据从源头到目的地的流动路径,包括数据的加工过程、转换和传递,以及它们在不同层级的映射关系。
- 数据安全与权限:确保数据的安全性和隐私保护,包括数据访问权限的控制和身份验证等措施。
- 数据质量检测:数据质量检测是指通过一系列的规则和标准,对数据进行验证、监控和评估,以确保数据的质量符合预期的要求。
- 数据规范与标准:建立数据的规范和标准,如日期字段、更新字段、浮点字段规范等,确保数据的一致性和统一性,便于数据交互和共享。
- 预警:数据治理中的预警是一项重要的措施,预警可以涵盖多个方面,包括资源预警、服务预警和数据预警等。
- 元数据管理:记录数据的定义、来源、用途、变更历史等信息,帮助用户理解和使用数据,同时也是血缘关系的重要组成部分。
数据治理的目标是建立一个可靠、安全、高效的数据环境,确保数据质量,支持企业的决策和发展。综合考虑以上各个方面,能够有效地管理和维护数据仓库,并为企业提供可信赖的数据支持。
二、数据治理各步骤方法论
2.1、数仓分层
数仓分层可直接参考这一篇:数据仓库设计理论,其中有各层详细介绍。
2.2、数据建模
数仓建模同样可直接参考这一篇:数据仓库设计理论,其中有建模详细步骤。
2.3、表设计
表设计可直接参考这一篇:数据仓库表设计理论,其中有各种类型表的详细介绍。
2.4、血缘关系
2.4.1、介绍
血缘关系对数据治理非常重要,它提供了数据的全生命周期视图,有助于数据追溯、数据质量监控、风险评估等方面。在数据仓库中,血缘关系主要包括以下内容:
- 数据来源:标识数据的原始来源,可以是数据库、文件、API接口等。
- 数据传输:记录数据在不同层级之间的传输路径,例如从ODS层到DWD层、从DWD层到DWS层等。
- 数据映射:记录不同层级中表之间的映射关系,比如维度表和事实表之间的关联。
- 数据变更:追踪数据的变更历史,包括数据更新、删除、插入等操作。
通过建立和维护血缘关系,数据仓库团队可以更好地理解数据的流动情况,及时发现数据质量问题和潜在的风险,并确保数据在整个数据仓库生命周期中的可靠性和一致性。血缘关系是数据治理的重要组成部分,对于数据仓库的建设和管理都具有重要意义。
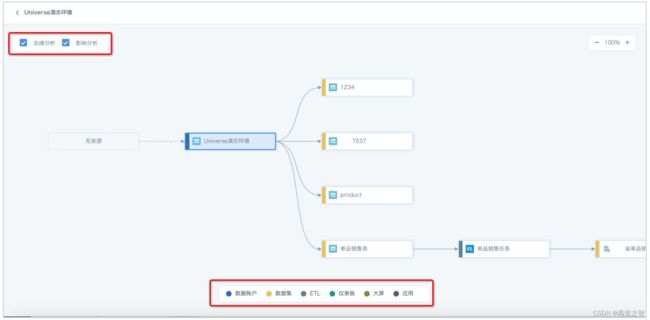
2.4.2、示例
通常血缘关系的依赖是由调度系统进行管理,例如A -> B -> C 这类血缘关系应存储在调度系统元数据中。
在企业内部血缘关系展示通常以图形化的方式呈现,可以通过调度系统的界面或其他数据管理工具进行查看和分析。这样的展示方式使得数据关系更加直观和易于理解,也方便数据治理和数据监控工作的开展,如下图:
2.5、数据安全与权限
2.5.1、介绍
数据仓库的数据安全与权限需要在不同层面进行管理,一方面是数仓本身的权限管理(Hive),一方面是应用级别的访问权限
2.5.2、数仓本身的权限管理(Hive)
在Hive中,可以使用Hive的权限管理功能来控制用户对表、数据库和列的访问权限。Hive支持基于角色的访问控制,可以为不同的角色分配不同的权限。通常,管理员会创建不同的角色,并将用户分配给相应的角色,然后在角色级别定义访问权限。
- 创建角色:管理员可以根据业务需求创建不同的角色,如管理员角色、数据分析师角色等。
- 授权角色:将不同的角色授予不同的数据库和表的访问权限,包括SELECT、INSERT、UPDATE、DELETE等权限。
- 分配角色:将用户分配给相应的角色,从而继承该角色的权限。
注意:Hive的权限管理主要是基于Hive操作层面的,而HDFS本身也有一套自己的权限管理机制。如果用户有足够的权限直接访问HDFS上的文件,那么即使被限制了Hive的权限,用户依然可以绕过Hive直接查看或修改HDFS上的数据文件。因此,在设计数据仓库的权限管理时,除了配置Hive的权限,还需要确保HDFS的权限设置也是安全和可靠的,以防止绕过Hive的情况发生。综合使用Hive权限和HDFS权限,可以提高数据的安全性和隐私保护。
2.5.3、应用级别的访问权限(平台)
在数据仓库应用中,可以一步定义应用级别的访问权限,这里的应用一般是指企业自研的大数据平台;平台负责控制用户在应用中的操作权限,如查看特定报表、创建数据集、修改数据等。这可以通过应用的用户认证和授权系统来实现。
- 用户认证:确保只有经过认证的用户可以访问应用,并根据用户的身份分配相应的权限。
- 角色权限:在应用中定义不同角色的权限,如管理员角色、普通用户角色等,然后将用户分配给相应的角色。
- 权限控制:根据角色和功能模块,定义不同角色的操作权限,如查看、新增、编辑、删除等。
2.5.4、示例
2.6、数据规范与标准(Hive)
2.6.1、介绍
在数据仓库(Hive)中,数据规范与标准通常分为以下几块:
- 命名规范:定义数据仓库中对象(如表、列、视图、文件等)的命名规则,确保命名统一、规范、易于理解和维护。
- 数据类型规范:确定数据仓库中各个字段的数据类型,例如日期字段、数值字段、字符字段等的定义和约束。
- 数据格式规范:规定数据的输入和输出格式,确保数据的一致性和兼容性。
- 编码规范:定义字符集和编码方式,以确保不同系统之间数据交换的正确性。
- 时间维度规范:规定数据仓库中时间维度的字段名称(update_time, create_time等),以及日期格式、时间粒度标准化。
- 数据安全规范:明确敏感数据的处理方式、加密策略等,确保数据安全和隐私保护。
- 数据管理规范:规定数据生命周期、数据备份和恢复策略、数据归档等数据管理相关的标准。
通过制定这些数据规范与标准,保证数据的一致性、准确性和可靠性,降低数据处理的复杂性,提高数据仓库的可维护性和可扩展性,接下来依次介绍以上7点内容。
2.6.2、命名规范
当设计命名规范时,确保其实际可行并能够适用于Hive数据仓库是非常重要的。
- 表名和列名:选择简洁、具有描述性的表名和列名,避免使用过长或过于复杂的命名,推荐使用小写字母和下划线(snake_case)的组合,表名前缀要加上当前数据所处分层,例如:ods_order_info, dwd_order_date, dws_order_date。
- 数据库名:选择简洁、易于理解的数据库名,避免使用过长或过于复杂的命名。推荐使用小写字母和下划线(snake_case)的组合,库名前缀要加上当前数据分层,例如:ods_sales_data。
- 分区字段:对于分区表通常推荐使用日期字段,需要注意的是时间分区字段格式统一为:yyyy-MM-dd。
- 视图:如果使用了视图,也要遵循表名和列名的命名规范,并在命名中体现出视图的含义,例如:dm_daily_sales_view。
- 文件命名:对于Hive外部表,文件命名也应该遵循命名规范,确保文件名能够清晰地表达数据内容,例如:ods_sales_data_2023-07-01.csv。
- 注释(重要):为表、列、视图等对象添加注释,用于解释其含义和用途,便于其他团队成员理解和使用。
- 避免关键字:避免使用Hive或SQL的关键字作为命名的一部分,以免引起冲突。
- 保持一致性:在整个数据仓库中保持命名的一致性,遵循相同的规范和约定,以减少混淆和错误。
以上建议是通用的Hive数据仓库命名规范,可以根据实际情况进行调整和补充。
2.6.3、数据类型规范
以下是一些建议的数据类型规范,以确保数据存储合理、高效且易于查询:
- 推荐使用STRING类型存储文本数据:对于不确定长度或格式的文本数据,使用STRING类型是最常见的选择。
- 推荐使用BOOLEAN类型存储布尔值:用于存储真值(true/false)的字段,使用BOOLEAN类型可以节省存储空间,并且更直观。
- 推荐使用INT或BIGINT存储整数:对于整数类型的字段,根据数值范围选择合适的数据类型。INT通常用于较小的整数,而BIGINT适用于更大范围的整数。
- 推荐使用DECIMAL存储小数:对于浮点数或小数类型的字段,DECIMAL适用于需要精确计算的场景。
- 推荐使用TIMESTAMP存储日期和时间:如果需要存储日期和时间信息,可以使用TIMESTAMP类型。TIMESTAMP包含了年月日时分秒,适用于需要精确到秒级的时间信息。
- 避免使用VARCHAR和FLOAT:虽然Hive支持VARCHAR和FLOAT类型,但在数据仓库中使用时需要谨慎。VARCHAR类型可能会导致存储不一致的问题,而FLOAT类型在精度方面可能会引发计算错误。
- 避免使用过于复杂的数据类型: 尽量避免使用Hive不常用或过于复杂的数据类型,除非业务需求确实需要。复杂数据类型可能导致查询性能下降和维护困难。
以上规范可以确保Hive数据仓库中的表具有较高的性能、存储效率和数据准确性,同时也方便数据查询和维护工作。
2.6.4、数据格式规范
以下是一些建议的数据格式规范,以确保数据存储合理、高效且易于查询:
- 空值处理规范:对于可能存在空值的字段,使用NULL值来表示。Hive支持NULL值,并且可以在表设计时指定字段是否可以为空。
- 压缩格式规范:考虑使用压缩格式(如Snappy、Gzip等)来减少数据存储空间,提高查询性能。在创建表时,可以指定表的压缩格式,推荐使用Snappy。
- 存储格式规范:推荐Parquet是一种高效的列式存储格式,它能够压缩数据并提供快速的读取性能。Parquet适用于大规模数据仓库,特别是在查询大量列时表现优异。同时,Parquet还支持谓词下推,即只读取查询涉及的列,从而减少了IO操作,提高了查询性能。
- 日期格式规范: 对于日期类型的字段,使用标准的日期格式(例如YYYY-MM-DD)来存储日期信息。避免使用非标准的日期格式,以确保日期数据的一致性和可读性。
- 日期时间格式规范: 对于日期时间类型的字段,使用标准的日期时间格式(例如YYYY-MM-DD HH:MM:SS)来存储日期和时间信息。
2.6.5、编码规范
Hive默认使用UTF-8编码,这通常适用于大多数情况;如果你的数据涉及多语言或特殊字符,可以考虑使用其他编码方式,如UTF-16或UTF-32等;在创建表时,你可以通过在CREATE TABLE语句中使用ROW FORMAT DELIMITED FIELDS TERMINATED BY子句来指定数据的编码方式。
例如,如果要设置表的编码为UTF-16,可以这样创建表:
CREATE TABLE my_table (
col1 STRING,
col2 INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
WITH SERDEPROPERTIES ('serialization.encoding'='UTF-16');
要根据具体的业务需求和数据特性来选择合适的编码方式,以确保数据能够正确地存储和处理。
2.6.6、时间维度规范
Hive中时间维度规范的确是为了在数据仓库中处理增量数据而设计的。
在数据仓库中,经常会使用增量表来存储每天、每周或每月的新增数据,以避免重复存储全部数据。为了方便处理增量数据,通常会有一些时间维度规范,比如:
- 日期字段命名: 为了方便识别和使用日期字段,可以使用一些通用的日期字段命名,如create_time表示数据创建时间,update_time表示数据更新时间,date表示日期等。
- 当前日期字段: 在一些场景中,可能需要在表中加入当前日期字段,以便跟踪数据更新的时间。可以使用current_date或current_timestamp等函数获取当前日期或时间,并插入到相应字段中。
- 日期格式规范: 在创建表时,可以使用date或者timestamp类型存储日期和时间。选择合适的数据类型可以节省存储空间,并确保数据的正确性和一致性。
注意:在 Hive 中,没有类似于数据库中的自动更新时间戳(Automatic Update Timestamp)的内置功能。在数据库中,可以通过设置默认值或触发器来实现自动更新时间戳,但在 Hive 中,这个功能并不直接支持;不过可以使用 Hive 的内置函数 current_timestamp 获取当前时间后再插入到update_time字段中即可。
2.6.7、数据安全规范
在 Hive 中确保数据安全和隐私保护是非常重要的,特别是涉及到敏感数据时。以下是一些有效的发暗方法和策略,用于处理敏感数据:
- 数据静态脱敏(Data Masking):对敏感数据进行脱敏处理,以保护真实数据。例如,可以对手机号码只展示前几位数字,或者对身份证号码只展示前几位或后几位,该操作通常是前端应用 。
- 数据动态加密(Data Encryption):对敏感数据进行加密,确保只有授权的用户能够解密查看原始数据。可以使用 常见的加密算法有对称加密和非对称加密,如AES、RSA等,在Hive查询中执行加密或解密操作,可以使用用户自定义函数(UDF)将加密和解密功能集成到Hive查询中。
2.6.8、数据管理规范
Hive数据管理规范通常涵盖以下三个方面:
- 数据源备份(HDFS副本):Hive通常是构建在Hadoop分布式文件系统(HDFS)之上的,HDFS本身提供了数据冗余和容错的功能。在HDFS中,数据会根据配置的副本数(通常为3)进行备份。这些副本分布在不同的节点上,以确保数据的高可用性和容错性。
- 表备份(分层):数据仓库中通常包含多个层次的表,例如原始数据层(ODS)、数据清洗层(DWD)、维度层(DIM)、汇总层(DWS)和应用层(ADS)等。每个层次的表都具有不同的数据处理和加工程度。为了确保数据安全,通常会保留ODS层原始数据。
- 删除备份(HDFS垃圾桶):在HDFS中,当文件被删除时,并不会立即从磁盘上删除,而是移动到HDFS垃圾桶中。这个垃圾桶可以被配置为保存一段时间,以便在需要时可以恢复误删的数据。这个特性可以提供数据的安全保障,防止误删除导致的数据丢失。
2.7、数据质量检测
2.7.1、介绍
数据质量检测可以分为两个层面:
- 数仓服务自身的检测: 这一层面主要涉及Hive数仓本身的数据质量检测,包括对数据的完整性、一致性、准确性等进行检测。通过编写Hive脚本、使用Hive内置函数、调度任务等方式,可以实现对数据质量的基本检测。例如,使用COUNT函数来检测表中是否有空值或重复值,使用MIN和MAX函数来检测数据范围,使用REGEXP函数来检测数据格式等。
- 平台定义检测规则: 这一层面是针对业务需求和用户特定的数据质量规则进行检测。平台可以提供一个可配置的数据质量管理系统,允许用户定义自定义的数据质量规则和阈值。用户可以根据业务场景和数据特点,创建适合自己的数据质量规则。这样,用户可以根据自己的业务需求,实现更加灵活和精细化的数据质量检测。
在实际应用中,更推荐平台定义规则检测,形成一个完整的数据质量管理体系。这样能够确保数据质量的全面性和准确性,同时提供更灵活的检测方式,满足不同用户的需求。
2.7.2、平台定义检测规则(重要)
平台定义检测规则又分为两块:
- 基本规则预设: 平台可以预设一些基本的数据质量规则,这些规则通常是通用的、适用于大部分业务场景的规则。例如,检测某个字段是否为空、数值是否超过范围、日期格式是否正确等。这些基本规则是平台提供的默认规则,用户可以直接使用,无需重新定义。
- 用户自定义规则: 平台还应该提供一个灵活的接口,允许用户根据自己的业务需求和数据特点,自定义数据质量规则。这些规则可以根据具体的业务场景而定,例如检测业务规则的合法性、特定字段的特殊要求等。用户可以根据自己的需求和数据情况,创建适合自己的数据质量规则,并将其应用于数据质量检测。
通过基本规则预设和用户自定义规则的结合,平台可以实现更加灵活和全面的数据质量检测。基本规则预设可以帮助用户快速开始数据质量检测,而用户自定义规则可以满足不同业务场景的特殊需求。
2.7.2.1、基本规则预设
平台可以预设一些基本的数据质量规则,这些规则通常是通用的、适用于大部分业务场景的规则,如下:
- 空值检测: 检测字段中是否存在空值。阈值可以设置为允许的空值个数或比例。
- 数据范围检测: 检测字段中的数据是否在合理的范围内,比如金额字段不能为负数。阈值可以设置为最小值和最大值。
- 唯一性检测: 检测字段中是否存在重复值,防止重复数据的产生。
- 格式检测: 检测字段中数据的格式是否符合要求,比如日期字段是否为指定格式,手机号是否符合手机号格式等。
- 异常值检测: 检测数据中是否存在异常值,比如极大值或极小值。
- 关联性检测: 检测关联字段之间的数据是否匹配,比如订单表中的订单号是否与订单详情表中的订单号匹配。
- 数据完整性检测: 检测是否有缺失数据,比如某些必填字段是否为空。
2.7.2.2、用户自定义规则
当平台允许用户自定义数据质量规则时,用户可以根据自己的业务需求和数据特点,创建适合自己的数据质量规则。以下是一些思路和示例:
- 业务规则检测: 用户可以根据业务需求定义特定字段的业务规则。例如,在电商数据中,用户可以定义销售额字段不得小于0,或者订单状态字段必须属于特定的取值集合。
- 范围检测: 用户可以定义字段的取值范围规则。例如,年龄字段必须在18岁到60岁之间,或者商品价格字段必须在特定的价格范围内。
- 格式检测: 用户可以定义字段的格式规则,确保数据符合特定的格式要求。例如,日期字段必须符合特定的日期格式,或者手机号字段必须是11位数字。
2.7.3、用户自定义检测规则设计思路
平台可以提供一个用户友好的界面,用户自定义规则时可以使用SQL语句的方式来定义数据质量检测规则。SQL是一种通用且强大的查询语言,适用于大多数数据仓库和数据库系统,包括Hive。通过SQL,用户可以灵活地定义各种数据质量规则,并利用SQL的聚合和过滤功能来实现数据质量检测。
例如,在Hive中,用户可以使用SQL语句来定义各种数据质量规则:
- 检测订单表中销售额小于0的异常数据:
SELECT *
FROM orders
WHERE sales_amount < 0;
- 检测用户表中年龄字段不在合理范围内的数据:
SELECT *
FROM users
WHERE age < 18 OR age > 60;
- 检测订单表中订单状态字段不属于特定取值集合的数据:
SELECT *
FROM orders
WHERE order_status NOT IN ('Pending', 'Processing', 'Completed');
用户定义的SQL规则可以根据具体需求包含不同的查询条件、聚合函数和逻辑操作,以实现各种数据质量检测目标。平台可以提供一个用户友好的界面,让用户在该界面上输入SQL规则,并将这些规则保存在元数据中,然后在后台周期性地执行这些SQL规则来进行数据质量检测,并将检测结果展示给用户,或者通过预警系统发送预警信息。
通过使用SQL方式定义数据质量规则,用户可以更加灵活地自定义各种复杂的规则,适应不同的数据质量检测场景,同时利用Hive强大的查询功能来高效地进行数据质量检测。
2.8、预警
2.8.1、介绍
在Hive数仓中,数据治理中的预警是一项重要的措施,预警可以涵盖多个方面,包括资源预警、服务预警和数据预警等。以下是对这些预警方面的简要介绍:
- 资源预警:资源预警主要关注Hive数仓所使用的硬件资源和系统资源,包括CPU利用率、内存利用率、磁盘空间等。当资源利用率超过预设的阈值时,系统会发出预警通知,以便及时扩容或优化资源配置,避免资源不足导致性能下降或任务失败。
- 服务预警:服务预警关注Hive数仓的服务状态和运行情况,包括Hive Server服务、元数据存储服务(如MySQL)、调度服务以及平台应用服务等。如果服务出现异常或故障,预警系统会立即发出通知,以便及时采取措施修复服务问题,确保系统的稳定运行。
- 数据预警:数据预警关注Hive数仓中的数据质量和数据异常情况。例如,可以监控数据加载过程中的错误记录数,或者对业务数据进行监测,发现数据异常或不一致时及时预警,以便进行数据修复或数据清洗。
- 性能预警:性能预警关注Hive查询的执行性能,如查询响应时间、执行计划、任务失败率等。当查询性能低于预设阈值或出现性能异常时,预警系统会发出通知,以便及时优化查询语句或调整调度策略。
- 安全预警:安全预警关注Hive数仓的安全风险和安全事件,如异常登录、权限变更等。预警系统会及时通知安全管理员,确保安全事件得到及时处理和应对。
2.8.2、资源预警
数仓的资源预警可以通过多种方式来实现,具体取决于集群的架构和数据治理策略。以下是两种常见的资源预警方式:
- 集群管理工具:大数据集群管理工具(例如CDH、Hortonworks、Hadoop等)通常会提供监控和预警功能,可以实时监测集群中的资源利用率。这些工具通常会提供用户界面,显示集群的资源使用情况,包括CPU利用率、内存利用率、磁盘空间等。同时,它们也会提供设置预警阈值的功能,一旦资源利用率超过预设的阈值,就会触发预警通知,如邮件、短信或钉钉消息等,提醒管理员及时采取措施。
- 监控系统:除了集群管理工具自带的预警功能,还可以借助第三方监控系统来实现资源预警。例如,Prometheus是一种开源的监控系统,可以与Hive集成,监测Hive集群的资源利用率,并通过AlertManager发送预警通知。通过Prometheus和Grafana等工具,您可以更加灵活地设置预警规则和监控指标,以满足不同的数据治理需求。
总的来说,资源预警是大数据集群管理中至关重要的一环,它可以帮助管理员及时发现集群资源瓶颈和性能问题,防止资源耗尽和任务失败。通过选择合适的集群管理工具或监控系统,并合理设置预警阈值,可以有效提升集群的稳定性和可用性。
2.8.3、服务预警
在数据治理中,服务预警包括了数仓本身服务以及平台应用服务,需要综合考虑以下几个方面来进行预警:
- 数仓本身服务预警:针对数仓的各个组件和服务,可以通过集群管理工具、监控系统或自定义监控脚本来进行预警。监控指标包括但不限于Hive服务状态、HDFS存储空间、YARN资源利用率、HBase表存储情况等。在设置预警规则时,可以根据历史数据和性能指标,定义合理的阈值,并在指标超过预设阈值时触发预警通知,以便及时发现和解决问题。
- 平台应用服务预警:除了数仓本身服务,还需要关注数仓平台上运行的应用服务,例如ETL作业、报表服务、数据可视化等。这些应用服务对于数仓数据的处理和展示至关重要,若发生故障或性能异常,可能影响数据准确性和时效性。因此,需要定期监控这些应用服务的运行状态、作业执行情况、数据处理成功率等,并设置相应的预警规则。
2.8.4、数据预警
数据预警需要结合"2.7、数据质量检测" 进行预警,以确保数据的准确性和完整性。预警方式可以与上述服务预警类似,将预警信息接入到公司内部的预警系统,如Prometheus或其他监控系统。
2.8.5、性能预警
性能预警关注数仓查询的执行性能,如查询响应时间、执行计划、任务失败率等,以下是一些实施性能预警的方法:
1. 监控Hive执行性能:
- 使用性能监控工具,如Ganglia、Ambari、Prometheus等,监控Hive查询的响应时间、资源使用情况等指标。
- 设置合理的查询性能指标阈值,当性能指标超过阈值时触发预警。
2. 监控任务失败率:
- 监控Hive任务的失败率,包括查询失败、任务超时等情况。
- 当任务失败率超过一定阈值时触发预警,及时发现问题并处理。
3. 监控队列:
- 检测队列管理工具,如YARN队列,检测队列使用率。
- 检测调度系统的任务队列,根据任务的优先级和资源需求,合理分配队列资源,确保关键任务优先执行。
4. 自动化任务管理:
- 实现自动化任务管理,对于长时间运行的任务或耗费大量资源的查询,进行自动终止或调度。
性能预警的目标是及时发现性能问题,优化Hive查询和任务的执行效率,提高数据仓库的整体性能和响应能力。通过合理设置预警规则和及时响应预警信息,可以有效保障数据仓库的稳定性和可靠性。
2.8.6、安全预警
安全预警在数据治理中是非常重要的一环。它包含两个方面的预警:
1. Hive数仓自身的安全预警:
- 监控Hive元数据变更:监控Hive元数据的修改、删除等操作,以便及时发现潜在的安全风险和异常操作。
- 记录敏感操作日志:记录Hive数仓中的敏感操作日志,如数据插入、更新、删除等,以便审计和追踪异常操作。
- 异常访问检测:检测异常的数据访问行为,如频繁访问敏感数据、跨越权限范围的数据访问等,及时发出预警。
2. 上层服务的用户操作数据的预警:
- 监控用户行为:监控上层服务用户对数据的操作行为,如查询、下载、导出等,以便发现不当行为或异常操作。
- 访问权限控制:对上层服务的用户访问权限进行细粒度控制,确保用户只能访问其具有权限的数据。
- 异常数据操作检测:检测用户对敏感数据的异常操作,如删除重要数据、篡改数据等,及时触发预警。
安全预警的目的是保障数据的安全性和隐私保护,防范潜在的安全风险和数据泄露。通过实时监控和预警,可以及时发现和应对安全事件,保护数据仓库和上层服务的安全。
2.9、元数据管理
2.9.1、介绍
元数据管理在Hive数据仓库中非常重要,它包含了表的结构、列信息、分区信息、表的属性以及数据存储位置等重要信息,通常存储在关系型数据库(如MySQL)中;为了防止元数据的意外丢失或损坏建议将MySQL部署在多台服务器上实现高可用性(High Availability, HA),其次外部应用通常通过访问HiveMetastore服务、HiveServer2访问元数据和表信息,故在企业应用中常常将这两个服务布置成高可用。
在数据治理角度看元数据管理主要是考虑可用性和可靠性两方面。
2.9.2、Metastore高可用:
Hive Metastore是Hive的元数据存储和管理组件,它负责存储表结构、分区信息、表的属性等元数据。为了确保Metastore的高可用性,可以考虑以下措施:
- 数据库高可用: Hive Metastore通常使用数据库来存储元数据,确保数据库本身具有高可用性和冗余备份,例如使用主从复制或集群方式部署数据库。
- Metastore集群: 将Metastore部署在多台服务器上,构建Metastore集群,实现高可用和故障转移。这样即使一台Metastore服务器出现故障,其他服务器仍然可以继续提供服务,高可用原理如下图:

配置hive-site.xml:
<property>
<name>hive.metastore.urisname>
<value>thrift://node01:9083,thrift://node03:9083value>
property>
2.9.3、HiveServer2高可用
HiveServer2是Hive的服务接口,允许客户端通过JDBC、ODBC等方式连接Hive,并执行查询和数据操作。为了确保HiveServer2的高可用性,可以考虑以下措施:
- HiveServer2集群: 将HiveServer2部署在多台服务器上,构建HiveServer2集群实现高可用和故障转移。这样客户端连接时可以选择任意可用的HiveServer2节点。
- ZooKeeper协调: 可以使用ZooKeeper来实现HiveServer2集群的协调和故障转移。ZooKeeper可以用作分布式协调服务,确保HiveServer2节点的状态和配置信息一致性,如下图:

通过以上措施,可以保证Hive Metastore和HiveServer2的高可用性,提高元数据管理和查询服务的稳定性和可靠性,从而更好地支持数据治理和数据仓库的运营。
注意:如果你在三台服务器上启动Hive Metastore服务,那么这三台服务器都需要安装Hive的相关组件和依赖,包括Hive Metastore本身和Hive的配置文件、依赖的库、数据库驱动等。
三、总结
数据治理涉及多个方面,包括数据所有权、数据访问权限、数据流程管理、数据质量管理、元数据管理、数据安全管理等。在数据治理的实施过程中,需要与各个相关部门密切合作,确保数据治理策略和流程的有效执行。
总的来说,数据治理是企业数据管理的重要组成部分,它帮助企业合理、高效地管理和使用数据,提高数据的质量和价值,为企业决策提供准确、可信的数据支持。