Linux多线程

文章目录
-
- 线程概念
-
- 1.再谈进程地址空间和页表
- 2.什么是线程
- 3.线程的数据属性
- 4.使用POSIX标准的pthread原生线程库创建“线程”
- 5.线程的优缺点
- 6.了解clone
- 7.用户级线程ID
- 线程控制
-
- 1.创建多线程
- 2.线程等待
-
- a.主线程使用pthread_join等待其他线程
- b.线程分离
- 3.线程终止
-
- a.线程执行的函数return就算终止
- b.使用pthread_exit终止线程
- c.使用pthread_cancel取消线程
- 对原生线程库再封装
-
- a.Thread.hpp
- b.main.cpp
线程概念
1.再谈进程地址空间和页表
进程中使用malloc/new都是在虚拟内存中开辟的空间,需要通过页表与物理内存建立联系以后才能拥有真正的物理空间,也就是说一个进程能看到多少资源取决于进程地址空间,但这个资源是否有效则取决于页表是否与物理内存之间建立映射关系,也即是进程地址空间是一个进程的资源窗口,页表决定进程到底有多少资源
页表分为用户级页表和内核级页表,OS为了区分页表的权限就必须要为页表设置属性,因此页表中不但要保存虚拟地址和物理地址还要存放一系列相关属性

页表并不简单,在32位系统下,一共有2^32 个地址(每个地址单位是一字节);如果要为每个地址设立一个页表条目则需要2^32次方个页表条目,而一个页表条目中除了要存放地址之外,还要存放一些相关属性,假设这些总共占用6个字节,那么存放一个页表就需要24GB的空间,因此虚拟地址到物理地址之间的映射并不像我们之前讲的那么简单
首先我们来认识一下物理内存,OS为了方便对物理内存做管理,将其划分成了若干个4KB大小的数据页,并设置了struct Page{}结构体,最后通过数组(struct Page mem[])的方式来管理这些数据页,这些数据页也被称为页框;这就是为什么外设和文件系统进行交互的时候是以4KB为单位的;数据在被加载到内存中之前也早已被划分为一个个4KB大小的块了,这些块也被称为页帧;
管理内存除了要有对应的数据结构以外还要有对应的管理算法,一般Linux当中常用的管理算法就是伙伴系统
其实页表是类似于索引管理的,以32为系统为例,一个地址有32个比特位,以10 10 12的方式构成;最开始的10位比特位是页目录的位置,一共有2^10 个目录;随后的10个比特位就是页表项的位置,一个页目录对应一个页表项,而一个页表项中又有2^10 个栏目,页表项的栏目中存放的就是页框的起始地址,最后的12位就是代表该地址在页框中的偏移量(2^12=4KB,这就是为什么是以4KB为单位的)

CPU中集成了MMU,虚拟到物理的转换,MMU也参与,那么为什么要采用页表+MMU的方式:硬件的速度远快于软件,因为软件要执行首先要被加载到CPU中,还有时间片的限制,但是硬件就没有;不过硬件一旦确定就存在可扩展性差和可维护性低的缺点,所以需要软件来进行灵活管理
2.什么是线程
什么是线程?
线程是进程内部的一个执行流,在Linux下并没有为线程额外创建数据结构来管理,而是通过只建立PCB来模拟实现的;但是在Windows下为了管理线程又创建了TCB内核数据结构来管理;
Linux这种方式一方面是提高了代码的复用率,另一方面也使线程的管理更为简单,而简单的东西就意味着稳定高效;
为什么说只创建一个PCB就可以实现对线程的创建:因为线程是进程内部的执行流,它的资源是从进程中得来的,而进程的资源则是通过地址空间和页表确定的,因此线程就不必再创建地址空间和页表了
在之前我们讨论的都是进程中只有一个线程的情况,当多线程的概念被载入以后,一个进程内可能有多个线程,这些线程共享大部分的资源(这些资源都是来自进程的)

当有了多线程的概念以后,PCB就不是进程的专属内核数据结构了;当然CPU也无法区分这个PCB到底代表是进程还是线程,不过也不用区分,因为喂给CPU的PCB一定小于等于我们过去谈论的PCB;比之前所说的粒度要更细更轻量化,Linux将进程和线程做了一个统一,称之为轻量级进程
我们之前说一个进程的PCB被载入到CPU的运行队列中,那么这个进程就处于运行状态了;今天我们知道PCB所代表的是小于等于进程的,所以CPU的基本调度单位其实不是进程,而是线程;线程的资源是占用进程的,所以进程其实是分配操作系统资源的基本单位
Linux下进程和线程的关系:
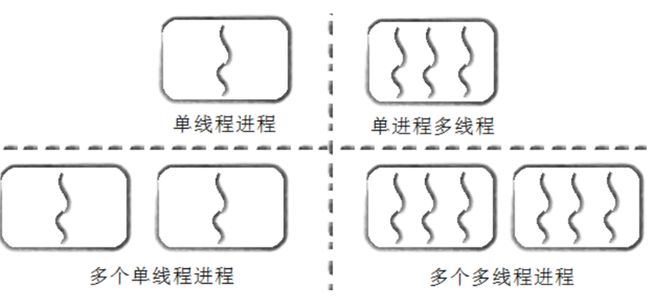
之前我们接触的都是单进程多线程或者多个单线程进程
3.线程的数据属性
一个进程内部的线程共享大部分的资源比如:全局数据、堆空间、加载的的动态库、文件描述符表、每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数) 、当前工作目录、用户id和组id等进程中的大部分资源都是共享的
但线程也必须要有自己的私有数据:除了线程的PCB以外,线程执行产生的临时数据,也就是上下文必须是私有的,为了保证临时数据私有,那么线程需要有自己独立的栈结构;
4.使用POSIX标准的pthread原生线程库创建“线程”
Linux没有真正的线程,所以它没有提供创建线程的系统调用接口,只提供了轻量级进程的接口,所以要创建线程还需要借助原生线程库(pthread),但其实创建的还是轻量级进程,首先来认识一下创建接口
PTHREAD_CREATE(3)
#include #include
要注意,因为该代码中使用了原生线程库中的接口,所以在编译的时候要链接该线程库

此时如果我们使用ps -aL查看系统中的线程:
![]()
就可以发现两个线程使用的是同一个PID,但它们的LWP是不同的,LWP就是轻量级进程,它是内核对线程的高度抽象;其实我们之前使用的kill等命令其实识别的不是PID,而是LWP只是如果一个进程只有一个线程,那么它的PID和LWP是相同的。
![]()
5.线程的优缺点
线程的优点
1.创建一个新线程的代价比创建一个新进程的代价要小(但线程也可以帮我们执行任务)
2.线程的切换远小于进程切换,因为线程切换只需要切换其私有数据即可
进程切换需要切换进程地址空间和页表,上下文数据以及PCB;而线程只需要切换PCB和上下文数据。进程地址空间和页表其实都是PCB通过指针来寻找的,那么切换也就是换指针指向而已,为什么说代价大:其实主要是因为CPU中存在一个cache(高速缓存),OS是层状结构,CPU主要是从cache中读取数据(依托局部性原理,OS会将当前CPU正在访问数据周围的数据也加载到cache中),当一个进程执行一段时间后cache中会存在大量的热点数据,以及预加载的数据,进程一旦被切换,这些数据也要被刷新出去,重新加载新进程的数据;但是线程不同,线程享用的是进程的数据,所以线程切换可能不需要更改cache中的数据
3、线程占用的资源要比进程少很多
4、能充分利用多处理器(多核)的可并行数量
5、在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
6、计算密集型应用(加密、解密、算法等),为了能在多处理器系统上运行,将计算分解到多个线程中实现
7、I/O密集型应用(外设、磁盘、网络等),为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作
当然线程/进程都不是越多越好的,最好和CPU的核数向匹配
线程的缺点
1、性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2、健壮性(鲁棒性)降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。 一个线程异常退出了,操作系统会向该进程对应的所有PCB发送信号,因为该进程中的所有线程的PID均相同,该信号线程人手一份,全部退出,同样的,进程也因为PID及信号的原因,退出。
线程没有异常的概念,异常是进程考虑的事情,线程默认所有操作都是正确成功的,一旦有异常则整个进程直接退出
#include
3、缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4、编程难度提高
编写与调试一个多线程程序比单线程程序困难得多。
6.了解clone
CLONE(2)
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
这个接口并不需要我们显示使用,fork和vfork的底层都调用了这个接口,该接口的第一个参数是指定一个由新进程执行的函数,第二个参数就是给进程或者线程分配堆栈,而flags这个参数就是去描述进程(轻量级进程)需要从父进程继承的资源;因此新创建的到底是进程还是线程主要是由flag参数来决定的
7.用户级线程ID
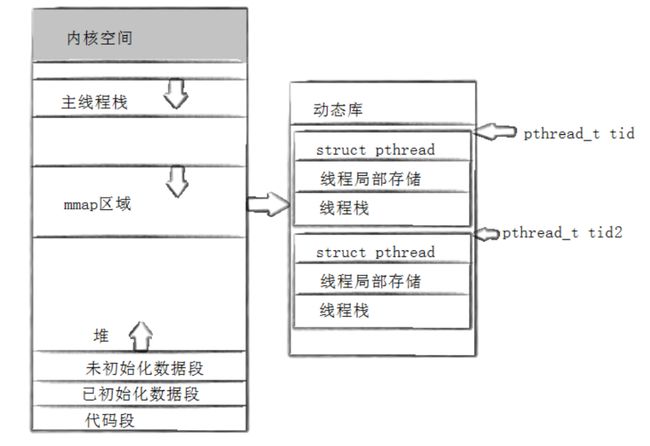
1.每个线程都有自己独立的栈结构,其中主线程使用的栈是进程地址空间的栈,而其他新创建的线程使用的则是在线程库在共享区维护的线程栈(线程当然是要被管理的,只不过是由线程库来进行管理)
2.线程局部性存储:全局变量是所有线程都可见且可修改的,如果在内置类型前加上__thread那么该全局变量则会映射到新线程的线程栈中,此后如果某一个线程修改了该全局变量不会影响到其他线程
线程控制
1.创建多线程
在Linux下连续创建10个线程,将自定义类对象传到新创建的线程中,并将这些自定义类对象用vector保存
#include2.线程等待
线程被创建出来也是帮我们执行任务的,它需要占用进程的资源,所以在线程结束时虽然可以不用关心它的退出信息,但还是要回收线程的资源的;不过线程回收的过程不可见;
a.主线程使用pthread_join等待其他线程
主线程通过调用pthread_join()来实现的,是阻塞式等待
PTHREAD_JOIN(3)
#include #include
能拿到函数返回值106,主要是因为
pthread库中设置了一个变量用于存放线程执行函数的返回值;而pthread_join的第二个参数是一个输出型参数,它可以将pthread库中的数据写到第二个参数中;
b.线程分离
一般来说一个线程是joinabale的,在线程结束后需要通过调用pthread_join来完成资源回收,并且该等待是阻塞式的;如果我们不想等待线程,那么可以通分离线程的方式告知OS,在线程退出时让其自动释放线程资源;线程分离要通过调用pthread_detach来实现
这里要注意的是线程分离不能写在新线程中,因为到底哪个线程是先被执行的这是无法确定的,所以很可能会发生主线程已经在等待了,但是新线程还没开始分离,这就会导致等待成功;但是线程分离会自动释放资源的,等待注定是要失败的,所以这是一种错误的写法,正确的写法应该是由主线程来分离
void* start_routine(void* args)
{
string threadname=static_cast<const char*>(args);
sleep(3);
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,start_routine,(void*)"new thread");
pthread_detach(tid);//创建线程成功时,由主线程进行分离
// int n=pthread_join(tid,nullptr);
// assert(n==0);
return 0;
}
3.线程终止
在进程终止的时候学了一个exit的系统调用,这个不能用来终止线程,因为它会导致整个进程终止
a.线程执行的函数return就算终止
b.使用pthread_exit终止线程
void*start_routine(void*args)
{
newThread* td=static_cast<newThread*> (args);//安全的进行强制类型转换
int cnt=10;
while(cnt--)
{
cout<<td->namebuffer<<endl;
sleep(1);
}
pthread_exit(nullptr);//参数直接设置成空就行
}
pthread_exit主要是用于当线程不在满足某个条件或者遇到某种特殊场景时,用于提前终止线程;需要注意的是线程终止前必须要确定该线程的资源被全部释放,否则会导致资源泄漏的问题
c.使用pthread_cancel取消线程

如果线程被取消了,那么该线程的退出码就是-1;
对原生线程库再封装
a.Thread.hpp
#include ;
typedef std::function<void*(void*)> func_t;
const int num = 1024;
public:
Thread(func_t func, void *args = nullptr, int number = 0): func_(func), args_(args)
{
// name_ = "thread-";
// name_ += std::to_string(number);
char buffer[num];
snprintf(buffer, sizeof buffer, "thread-%d", number);
name_ = buffer;
// 异常 == if: 意料之外用异常或者if判断
// assert: 意料之中用assert,但assert在release下会失效
Context *ctx = new Context();
ctx->this_ = this;
ctx->args_ = args_;
int n = pthread_create(&tid_, nullptr, start_routine, ctx); //TODO
assert(n == 0);
(void)n;
}
// 在类内创建线程,想让线程执行对应的方法,需要将方法设置成为static
static void *start_routine(void *args) //类内成员,有缺省参数!
{
Context *ctx = static_cast<Context *>(args);
void *ret = ctx->this_->run(ctx->args_);
delete ctx;
return ret;
// 静态方法不能调用成员方法或者成员变量
}
void join()
{
int n = pthread_join(tid_, nullptr);
assert(n == 0);
(void)n;
}
void *run(void *args)
{
return func_(args);
}
~Thread()
{
//do nothing
}
private:
std::string name_;
func_t func_;
void *args_;
pthread_t tid_;
};
b.main.cpp
#include