机器学习之特征选择
特征选择
特征选择是机器学习任务中的关键步骤。下面将看到一些常用的特征选择方法。
什么是特征选择?
在机器学习中,feature selection用于选择相关特征(变量、预测变量等)的子集以用于模型构建。这是机器学习项目过程中的重要一步,也是特征工程feature engineering. 这很重要,原因如下:
- 以减少训练时间。训练时间和特征空间是正相关的。
- 避免维度灾难。
- 使模型更容易。
- 提高泛化能力,减少过拟合。
- 减少共线性并增强可解释性。
当得到一个数据集(类似表格的数据)时,每一列都是一个特征,但并不是所有的列都是有用的或相关的。最好花一些时间在特征选择上。使用特征选择技术的中心前提是数据包含一些冗余或不相关的特征,因此可以删除而不会导致大量信息丢失。
有很多方法可以进行特征选择。sklearn提供了许多功能来做到这一点,下面进行介绍。
删除低方差的特征
特征的方差为零是什么意思?这意味着该特征只有一个值,并且所有实例在该特征上共享相同的值。换句话说,这个特征没有任何信息,对目标的预测没有任何贡献。同样,那些具有低方差的特征几乎没有关于目标的信息,可以在不怎么降低模型性能的情况下删除它们。

sklearn提供VarianceThreshold去除低方差特征。同时,threshold允许我们控制方差阈值。
import sklearn.feature_selection as fs
# X is you feature matrix
var = fs.VarianceThreshold(threshold=0.2)
var.fit(X)
X_trans = var.transform(X)
可以尝试下面的代码示例。第一个特征都是相同的,因此删除了第一列。
import sklearn.feature_selection as fs
import numpy as np
X = np.array([[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1,
1]])
var = fs.VarianceThreshold(threshold=0.2)
var.fit(X)
X_trans = var.transform(X)
print("The original data")
print(X)
print("The processed data by variance threshold")
print(X_trans)
按低方差选择特征
line 3创建一个大小为六行三列的矩阵。line 6使用VarianceThreshold参数创建一个方差阈值对象threshold=0.2,这意味着方差小于 0.2 的列将被删除。- 可以在
line 12处将原始矩阵与新矩阵进行比较。
选择 K-best 特征
sklearn提供了一个通用功能SelectKBest,可以k根据某些指标选择最佳特征,只需要提供一个评分函数来定义指标即可。幸运的是,sklearn提供了一些预定义的评分函数。以下是一些预定义的可调用评分函数。
f_classif:分类任务的标签/特征之间的方差分析 F 值。mutual_info_classif:离散目标的相互信息。chi2:分类任务的非负特征的卡方统计。f_regression:回归任务的标签/特征之间的 F 值。mutual_info_regression: 连续目标的相互信息。SelectFpr:根据误报率测试选择特征。
这里的核心思想是计算目标和每个特征之间的一些度量,对它们进行排序,然后选择K最好的特征。
在下面的示例中,选择 f_classif作为指标,并且K是设置为3。
import sklearn.datasets as datasets
X, y = datasets.make_classification(n_samples=300, n_features=10, n_informative=4)
# choose the f_classif as the metric and K is 3
bk = fs.SelectKBest(fs.f_classif, 3)
bk.fit(X, y)
X_trans = bk.transform(X)
一个重要的问题是模型的性能如何受到减少特征数量的影响。在下面的示例中,我们比较逻辑回归与不同K最佳特征的性能。
从下图中可以看出,如果仅删除一些特征,该指标不会发生太大变化。
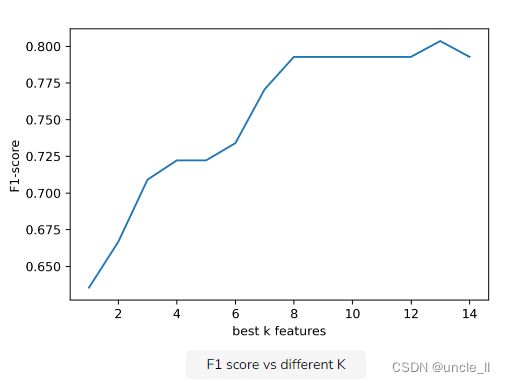
也可以试试不同的K看看效果如何,只需在创建新数据集时更改特征数量,或更改K
import sklearn.feature_selection as fs
import sklearn.datasets as datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
X, y = datasets.make_classification(n_samples=500,
n_features=20,
n_informative=8,
random_state=42)
f1_list = []
for k in range(1, 15):
bk = fs.SelectKBest(fs.f_classif, k)
bk.fit(X, y)
X_trans = bk.transform(X)
train_x, test_x, train_y, test_y = train_test_split(X_trans,
y,
test_size=0.2,
random_state=42)
lr = LogisticRegression()
lr.fit(train_x, train_y)
y_pred = lr.predict(test_x)
f1 = metrics.f1_score(test_y, y_pred)
f1_list.append(f1)
fig, axe = plt.subplots(dpi = 300)
axe.plot(range(1, 15), f1_list)
axe.set_xlabel("best k features")
axe.set_ylabel("F1-score")
fig.savefig("output/img.png")
plt.close(fig)
选择最佳 K 特征
- 首先,在
line 8使用时创建一个分类数据集make_classification。 line 14到line 26是一个循环for k in range(1, 15)。在此循环的每次迭代中,K都会将不同的值传递给SelectKBest. 我们想看看不同的值如何K影响模型的性能。使用所选特征在循环的每次迭代(从line 22到line 25)中构建、拟合和评估逻辑回归模型。K该指标存储在一个列表中,f1_list。在这个演示中,使用f1-score作为指标。- 从
line 28到line 33,绘制那些K和它们对应的 f1 分数。
按其他模型选择特征
SelectFromModel是一个元转换器,可以与任何在拟合后具有coef_或feature_importances_属性的估计器一起使用。但是,这里只想关注基于树的模型。可能还记得,树是由单个特征上的某个度量分割的。根据这个指标,就可能知道不同特征的重要性。这是树模型的一个属性;所以通过树模型,能够知道不同特征对模型的不同贡献。
sklearn提供SelectFromModel进行特征选择。从下面的代码中,可能会注意到第一个参数gb。它是一个GBDT模型,用于通过使用来选择特征feature_importances_。树模型非常适合特征选择。
import sklearn.feature_selection as fs
model = fs.SelectFromModel(gb, prefit=True)
# X is your feature matrix, X_trans is the new feature matrix.
X_trans = model.transform(X)
import sklearn.feature_selection as fs
import sklearn.datasets as datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
import sklearn.metrics as metrics
X, y = datasets.make_classification(n_samples=500,
n_features=20,
n_informative=6,
random_state=21)
gb = GradientBoostingClassifier(n_estimators=20)
gb.fit(X, y)
print("The feature importances of GBDT")
print(gb.feature_importances_)
model = fs.SelectFromModel(gb, prefit=True)
X_trans = model.transform(X)
print("The shape of original data is {}".format(X.shape))
print("The shape of transformed data is {}".format(X_trans.shape))
The feature importances of GBDT
[0.00000000e+00 4.35611629e-03 0.00000000e+00 2.37301143e-02
0.00000000e+00 1.35731571e-01 1.93024194e-01 0.00000000e+00
0.00000000e+00 4.83477430e-02 3.84429422e-02 6.80747372e-02
2.11790637e-02 0.00000000e+00 1.60274532e-02 2.79721758e-04
4.50188188e-01 0.00000000e+00 0.00000000e+00 6.18155685e-04]
The shape of original data is (500, 20)
The shape of transformed data is (500, 4)
按其他型号选择特征
- 数据集创建于
line 7。 - 然后在from和at
GBDT创建一个对象。line 12``GradientBoostingClassifier``fit``line 13 line 15输出显示了不同特征的重要性;数字越大,重要性越高。line 17显示如何使用另一个模型来选择一个特征SelectFromModel。所要做的就是传递GBDT对象。这prefit=True意味着该模型已经拟合完毕。
参考
- hands on machine learning with scikit learn
- https://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_selection