基于动态规划DTW算法加速衡量两个不同的时间序列的相似性
什么是DTW?
DTW算法采用了动态规划DP(dynamic programming)的方法来进行时间规整的计算,可以说,动态规划方法在时间规整问题上的应用就是DTW。
为什么需要DTW算法
当两个序列按照时间步t完全对齐的时候,我们可以直接使用ED算法(或者其它距离计算)来评估两个算法的相似度。但是有些时候两个序列并未完全对其,如果我们将某一序列进行压缩处理,此时会有信息损失。那么是否可以将两个长度不一样的序列进行对齐,然后再进行距离计算,DTW算法可以完成这个任务。
如图所示,这两个序列整体上波形很相似,但是在时间轴上确实对不齐的,所以这样如果按照时间步t对应来求距离显然会出问题。
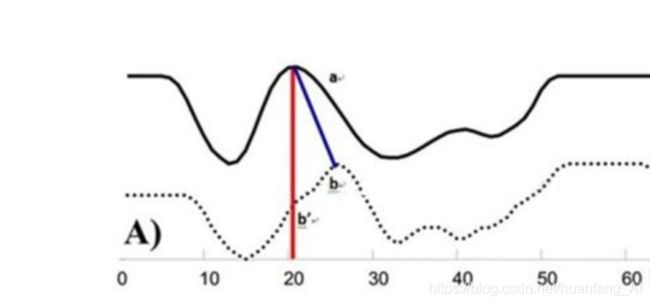
为了解决这个问题,我们需要进行对齐操作:
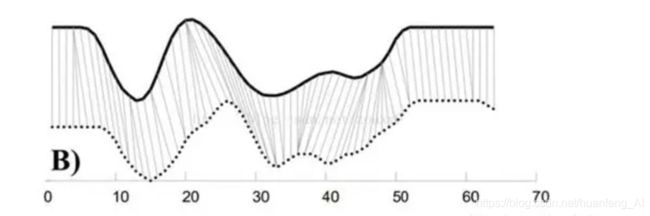
如图所示,就是应用DTW算法之后的对齐之后的效果图,那么此时我们对两个序列的对应点之间计算距离,此时才是这两个序列的真实距离。
DTW的核心问题?
DTW核心是将两个不同的序列按照最好的方式对齐,而如何才是最好对齐呢?对齐的方式有很多,最好的对齐方式就是两个序列的距离最小,同时这个最小的距离就是这两个序列的距离。
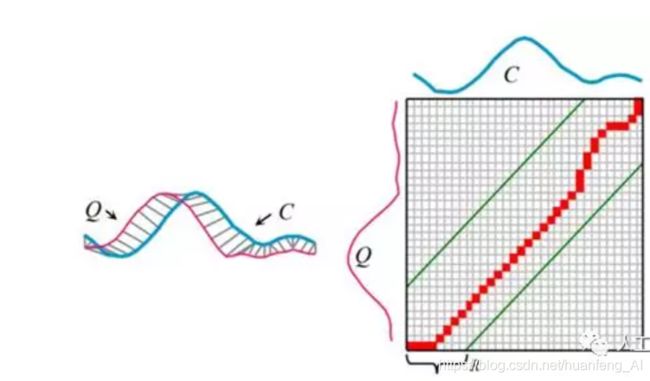
如图所示,两条完全不同的序列Q,C,如何才能对齐呢?
假设Q的序列长度为n,而C的序列长度为m,那么我们需要构建一个n*m的矩阵,其中矩阵元素(i,j)表示Qi和Cj之间的距离。每个矩阵元素表示Qi和Cj对齐,那么从矩阵左下角到右上角可以找到很多路径(为什么是从左下角到右上角,因为两个不同的序列无论长短,它们的起始点和终止点肯定是对应的),这个矩阵包含了所有的对齐路径,DP算法就是要找到一条最短的路径。
路径的性质
首先这条路径需要满足一定的性质,它可以帮助算法对路径进行规范。
-
边界条件:必须从矩阵的左上角到矩阵的右上角
-
连续性:路径需要是连续的,不能跨越某点去匹配,(跨越其实也行,这样会有信息损失)
-
单调性:路径必须随着时间单调进行,这样路径不会出现相交的情况。
连续性和单调性决定了路径中每一个格点只有三个方向,如果当前格点为(i,j),那么下一个格点只能是下面的三种情况(i+1,j)、(i,j+1)、(i+1,j+1)

当然如果连续性中考虑跨越的情况,那么可能来自五个方向,此时从(m-2,n-1)到(m,n)会有信息损失
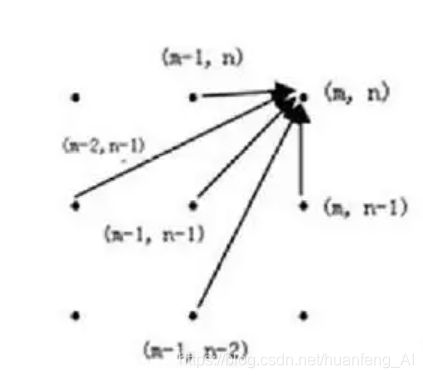
本文中我们只考虑三种方向的情况。
动态规划关系表达式
现在我们已经知道了路径的规范条件了,那么这个问题的动态规划关系表达式为:
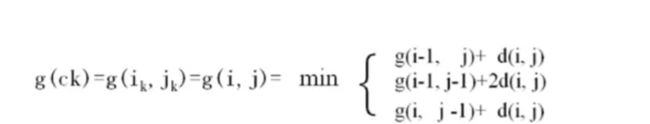
我们拿g(i,j)=g(i-1,j)+d(i,j)来举例,g(i-1,j)我们可以认为是起点到g(i-1,j)的最短距离,然后d(i,j)表示Qi与Cj之间的距离。
为什么有d还有2d呢?
这个可以理解为人为设定的,我们这里设定当路径横着走还有竖着走的时候,就是d,当路径斜着走的时候就是2d,也就是此时我们设定斜着走的时候损失大一些,d可以认为是损失。

现在有两个序列R和T,现在我们构建了一个矩阵,我们要找到从左下角到右上角的最短路径,每个格子中数字表示Ri和Tj的距离,右上角表示总距离。我们来看一下B2是如何计算的:
如果只能从三个方向来走的话,B2可以认为来自B1、A1、A2,通过上面的动态规划关系式可以算出来
A1+2B2=4+24=12
B1+B2=7+4=11
A2+B2=5+4=9
所以从起点到B2的最短距离就是9,我们可以通过这种方式计算出格子的所有的点,那么最终我们可以算出从起点到F4的最短距离就是26,这就是动态规划,而动态规划在时间序列的应用就是DTW算法。
但是这里就有一个问题了?以上仅仅比较两条路径就要计算这么多,如果多条路径C与Q进行匹配,那么这个计算量就太大了,也就是说时间复杂度太高了,需要进行算法的改进。所以人们在使用DTW算法的时候就会使用一些技巧,以次来提高计算速度。
一些技巧
去根号计算
当使用DTW算法的时候,需要计算Q与C之间不同i,j之间的距离,那么往往需要较大的计算量
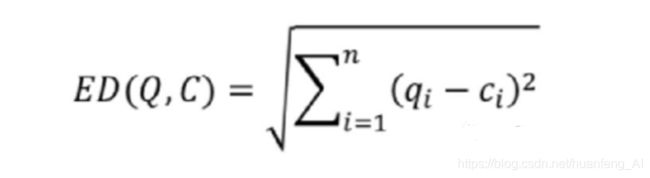
我们可以看到我们的目的是为了寻找最小的计算量,而去掉根号不影响其大小的比较,而根号的计算需要耗费较多时间,所以一个技巧就是去掉根号。
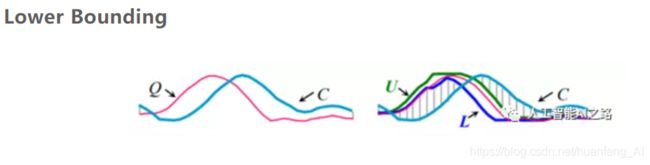
Lower Bounding

如果正常的计算Q和C之间的DTW距离,这样计算量很大,我们可以为Q设置上下界(U和L),然后使用U和L和C进行距离计算(C和U、L之间直接通过对应时间步计算,不用对齐),这个距离属于估算,如果估算出来的这个距离大于设置阈值,我们就认为Q和C之间的差距太大了,二者不匹配。Lower Bounding存在两个算法变种:LB-kim和LB-koegh
LB-kim:
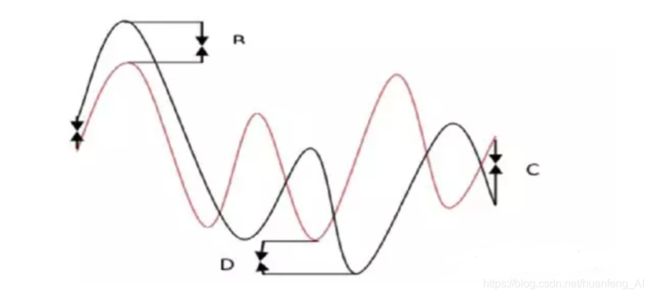
直接找到Q和C的四个对应的点,起始点,终点,最高点,最低点,计算这四个点的距离和,如果超过阈值,那么我们就认为这个Q和C不匹配。
LB-koegh:
直接找到Q和C的两个对应的点,最高点和最低点,如果超过阈值我们就认为这个Q和C不匹配。
我们可以看出来这两种方式计算的点比较少,所以计算量极少,速度会很快,但是会有问题,就是不精确,仅仅通过几个点就确定了序列的匹配程度,这样会有误差的。
Early Abandoning of ED and LB_Keogh
这个是将ED和LB进行结合,因为ED计算(DTW)比较精确,但是计算量大,而LB比较粗略,但计算量小,我们将二者结合,如图所示,我们将k=11之前使用DTW计算,K=11之后我们使用LB来计算,此时我们将二者加起来,如果这个超过阈值,我们就可以认为Q和C不匹配
一些新的技巧总结

Early Abandoning Z-Normalization
我们在使用DTW算法的时候,往往需要对数据进行归一化操作,这样可以提高效率
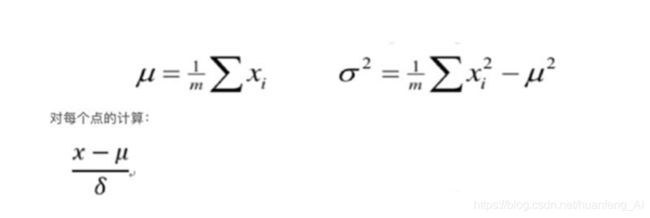
归一化操作
那么如果先进行归一化再进行动态规划,这样的问题就是一旦Q和C不匹配,那么就对C白白归一化了,那么我们可以这样的,每标准化一点就对这点进行ED计算,如果计算过程中总距离一旦超过阈值,就立即停止计算,以后的也不用进行归一化了,这样后面的点就不用归一化了,这样计算量就减少了。
Reordering Early Abandoning
DTW计算的时候,一般从序列匹配的起点开始计算,我们发现当计算到第9个时间步的时候,那么就发现它超过了阈值,我们就认为二者是不匹配的,就停止计算了
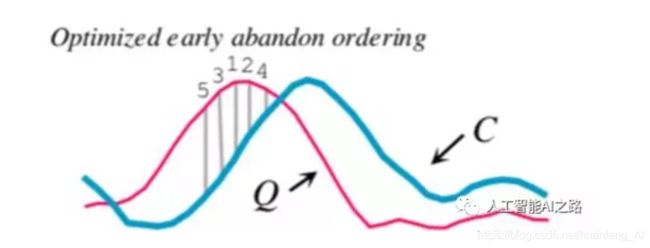
现在我们计算的时候不从起点开始计算,比如我们可以从中间的某个特殊的时间步(一般是Q中距离均值0比较远的序列段,用这段来和C进行距离计算,这个序列段再标准化的过程中就可以找到)计算。论文中的reorder early abounding 这部分的做法是对Q序列进行norm处理,然后对所有时间点元素值取绝对值,最后进行降序排列,以此来找到异常点?
这样,我们只计算(直接按照时间步计算距离,估算)了五个时间步就发现,Q和C距离超过阈值,二者是不匹配的,这样就直接停止计算。
以Q为基础的LB和以C为基础的LB

我们使用LB的方法都是对Q来使用的,然也可以对C来使用,这样的好处是对Q使用可以过滤掉一部分不匹配的序列,对C使用又可以过滤掉一批不匹配的序列
多种LB方式综合使用
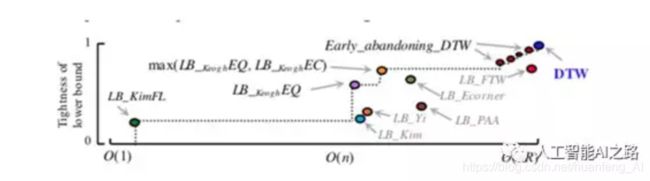
我们可以看到横轴表示时间复杂度,纵轴表示可靠性,我们可以认为越靠近左上角的算法是越好的。
总结
我们需要找到与Q距离最短的C,当序列很长和C数量很多的时候,一个很重要的问题就是过滤,也就是及时停止距离计算,上面的技巧就是在做这个工作,通过各种方式,只要发现Q和C的距离计算超过阈值就抛弃C,因为计算Q和C之间的DTW真的很费时间。
参考论文:Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping