python 爬虫遇到验证码如何解决
1.安装对应的库
安装tesseract https://digi.bib.uni-mannheim.de/tesseract/,其中文件名中带有dev的为开发版本,不带dev的为稳定版本,可以选择下载不带dev的版本,例如可以选择下载tesseract-ocr-setup-3.05.02.exe,配置环境变量。配置完成后在命令行输入tesseract -v,如果出现如下图所示,说明环境变量配置成功
pip install pytesseract 导入第三方库
2.验证过程出现的问题
优化验证码图片的步骤有时间在补,方法有很多,例如机器学习的方法等.
我在验证过程中出现了很多问题,在调试界面输入了正确的验证码,返回提示验证还是错误.

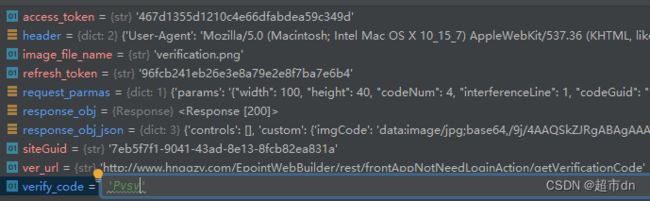
然后我用postman跑了一遍,在跑postman时,经过多次尝试发现验证码只能用一次,所以只需要两个页面的url,一个是验证码页(getVerificationCode),一个就是我们要获取内容的列表页(getPageInfoListNewYzm),我还发现在获取列表页内容的时候返回了一个cookie

这时候我猜测,这个sid是由python同种方法uuid.uuid4生成的,于是我尝试用自己的方法来进行仿写sid并填入cookie.
'sid=' + "".join(str(uuid.uuid4()).split('-')).upper()
添加验证了还是错误,由于postman已经跑通了,那就代表流程对了,我着重观察了一下postman里请求头有哪些
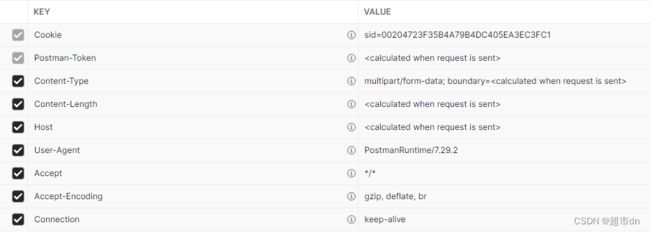
没啥特殊要添加的…
浏览器访问需要验证码的列表页,用Fiddler抓包看看
![]()
在这里插入图片描述
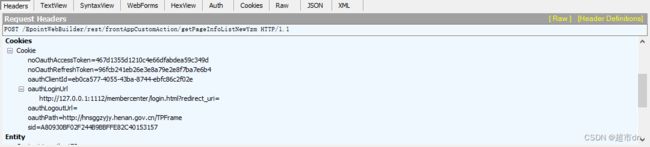
将Cookie里面的内容组装完全,accesstoken和refreshtoken是请求一个token页面得到的,请求几次发现得到的是一致的,直接写死就好.
再post请求验证码页输入对应的url
在response = request.post(url)中查看一下response.headers,返回一个字典
print('???????', response.headers, '........', response.cookies.items())
得到结果:
??????? {'Server': 'TencentWAF', 'Date': 'Mon, 12 Dec 2022 05:10:29 GMT', 'Content-Type': 'text/html;charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'X-Frame-Options': 'SAMEORIGIN', 'Set-Cookie': 'sid=AFD4284C6056490ABCF4EC274F9082E0; Path=/EpointWebBuilder/; HttpOnly', 'Content-Encoding': 'gzip', 'vary': 'accept-encoding'} ........ [('sid', 'AFD4284C6056490ABCF4EC274F9082E0')]
response.headers[‘Set-Cookie’]得到sid,添加到post访问列表页的headers里,即
header = {
"User-Agent":'',
"Cookie": response_obj.headers['Set-Cookie'] + '; oauthClientId=eb0ca577-4055-43ba-8744-ebfc86c2f02e; oauthPath=http://hnsggzyjy.henan.gov.cn/TPFrame; oauthLoginUrl=http://127.0.0.1:1112/membercenter/login.html?redirect_uri=; oauthLogoutUrl=; noOauthRefreshToken=' + refresh_token + '; noOauthAccessToken=' + access_token
}
再去访问就可以成功得到列表页的信息了.